
深度學習模型強大的學習能力推動了影象、語音、NLP等AI行業技術的進步,但DL模型通常非常複雜,如何方便、快捷、靈活、高效的把學習好的DL模型部署到實際生產環境,一直是工業界頭痛的問題,本文給出了一個Docker和Kubernetes部署深度學習模型的簡單示例,給大家提供一些思路。
同時推薦一門不錯的深度學習實踐課程,需要的朋友自取:
這篇文章展示了一個*Basic*示例,展示瞭如何用Keras構建深度學習模型,用Flask作為REST API來serve模型,並使用Docker和Kubernetes部署模型。
這不是一個健壯的生產例子。僅僅是一本快速指南,針對那些聽說過Kubernetes但還沒有嘗試過的人入門DL模型部署。
為此,我在這個過程的每一步都使用谷歌雲。原因很簡單—我不想在我的Windows 10家庭膝上型電腦上安裝Docker和Kubernetes,谷歌雲非常有效。
額外的好處是可以很容易復現下文描述的步驟,因為你可以使用我所使用的精確的規範來執行所有的事情。
另外,如果你擔心成本,不要擔心。谷歌為新賬戶提供了幾百美元的免費credit,我甚至沒有為我將要向你展示的任何東西耗費多少credit。
為什麼為ML和資料科學設計Kubernetes
Kubernetes,以及更廣泛的新流行詞,cloud-native,正在席捲全球。別擔心——你持懷疑態度是對的。我們都已經看到技術炒作泡沫變成了人工智慧、大資料和雲端計算等等。Kubernetes是否也會出現同樣的情況,目前還不清楚。
但是在你今天在資料科學外行指導下,我對使用Kubernetes的變革性原因既沒有理解,也沒有興趣。我的動機很簡單。我想部署、擴充套件和管理一個REST API,它可以提供模型預測服務。正如你會看到的,Kubernetes讓這變得非常容易。
讓我們開始吧。
目錄
1、使用谷歌雲建立你的環境
2、使用Keras、Flask和Docker構建深度學習模型
3、使用Kubernetes部署所述模型
4、盡情享受你新獲得的知識
步驟1 -使用谷歌雲建立環境
我在Google計算引擎上使用一個小虛擬機器來構建、serve和dockerize一個深度學習模型。沒有要求你也這樣做。我試圖在我的Windows 10膝上型電腦上安裝最新版本的Docker CE (社群版)。但失敗了。我決定花費(僅僅使用免費的谷歌雲Credit)比自己安裝Docker更好地利用我的時間。你可以自己選擇。
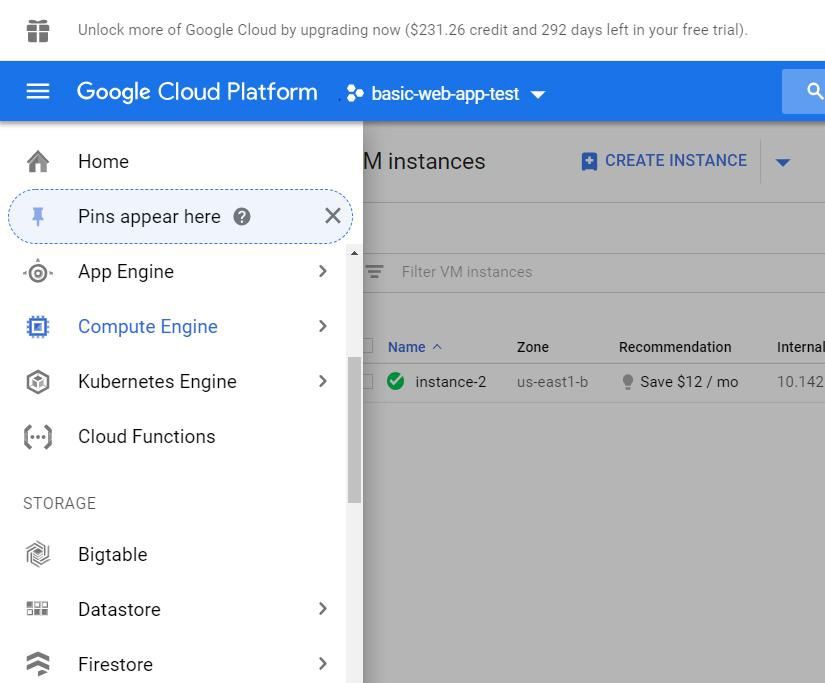
要啟動Google Cloud虛擬機器,請開啟螢幕左側的功能區。選擇計算引擎。
然後選擇“create instance”。你可以在下麵的照片中看到,我已經運行了一個實體。
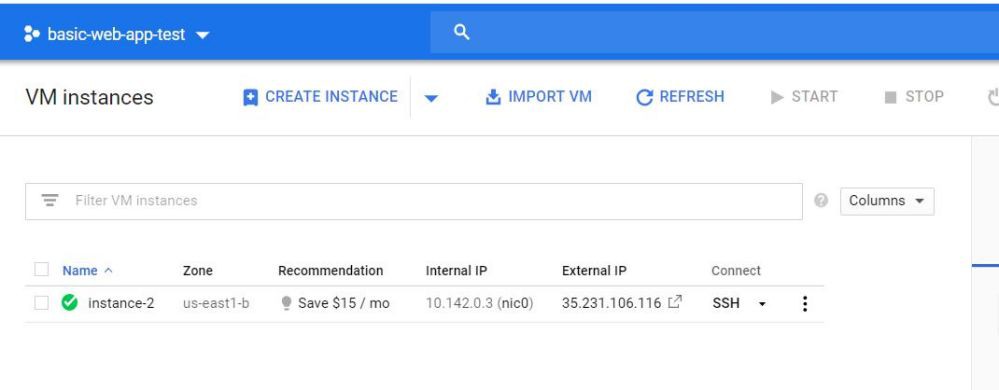
下一步是選擇我們想要使用的計算大小。預設( read :cheapest)設定應該只工作一個小時,但是考慮到我們最多隻需要這個虛擬機器大約1個小時,我選擇了擁有15GB記憶體的4vCPU。
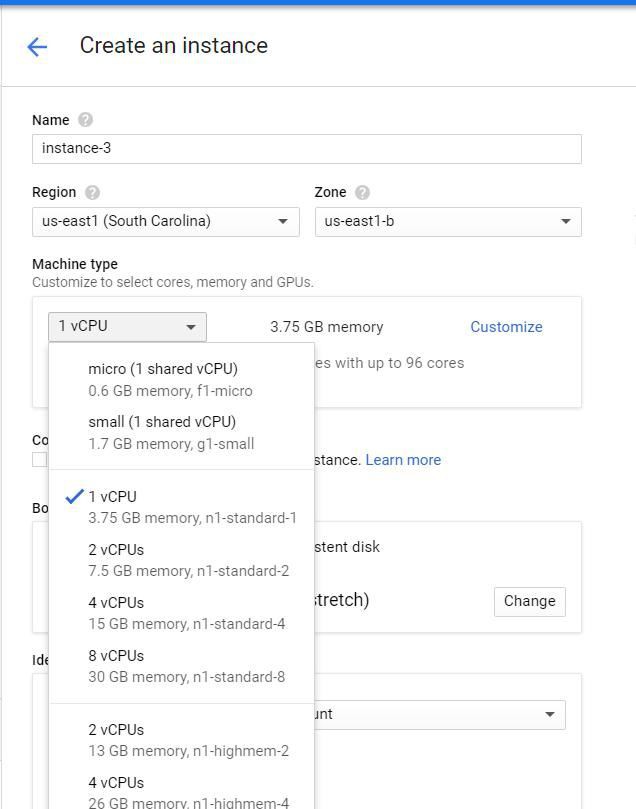
接下來,我選擇要使用的作業系統和磁碟空間。選擇“Boot Disk”編輯預設值。我選擇Centos 7作為我的作業系統,並將磁碟數量從10GB增加到100 GB。我不需要選擇作業系統( Centos )。然而,我建議將磁碟大小增加到超過10gb,因為我們建立的Docker容器每個都是大約1GB。
建立虛擬機器之前的最後一步是設定防火牆規則以允許HTTP / S。完全透明,我不確定是否需要這一步。在我們將虛擬機器部署到Kubernetes之前,我將向你展示如何編輯防火牆設定來測試虛擬機器上的API。所以檢查這些boxes是否足夠—還有更多的工作要做。我只是沒有回去嘗試這個教程而沒有檢查它們。
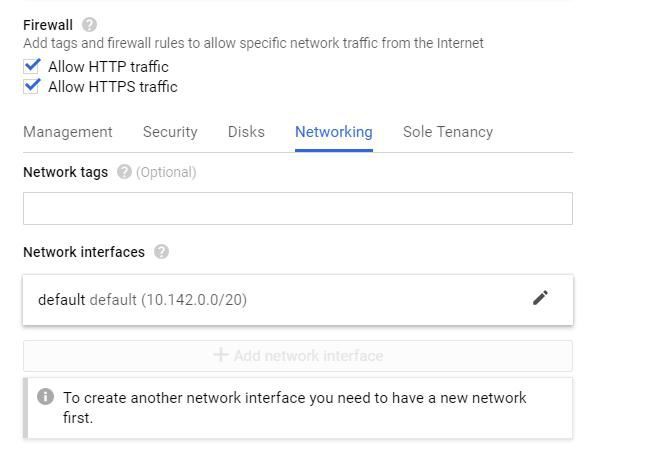
不確定是否需要此步驟
現在點選“Create”。太棒了!困難的部分基本上已經完成了!
步驟2 -使用Keras構建深度學習模型
現在,讓我們將SSH引入我們的虛擬機器,開始構建我們的模型。最簡單的方法就是點選虛擬機器旁邊的SSH圖示(如下所示)。這會在瀏覽器中開啟一個終端。
1、刪除現有版本的Docker

請註意,如果你選擇Centos 7以外的作業系統,這些命令會有所不同。
2、安裝最新版本的Docker
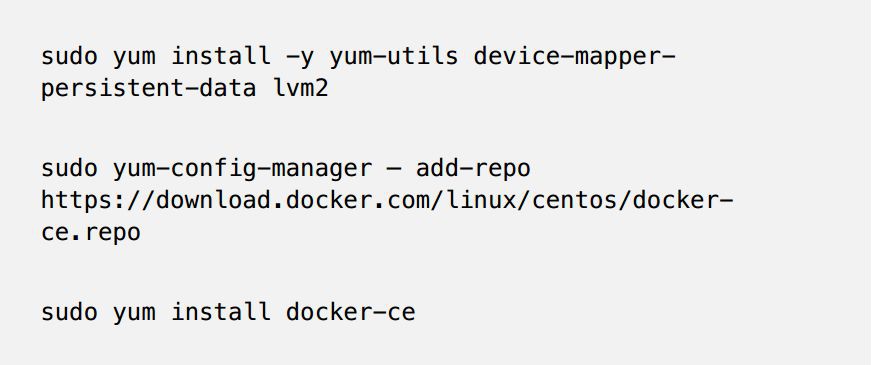
3、啟動Docker並執行測試指令碼

如果你看到一個輸出,看起來像下麵的訊息,就都準備好了。

4、建立我們的深度學習模型
首先,複製Adrian Rosebrock編寫的指令碼。Adrian建立了一個優秀的簡短教程,講述瞭如何用Keras建立深度學習模型,並用Flask來serve模型。你可以深入閱讀該教程:https://blog.keras.io/building-a-simple-keras-deep-learning-rest-api.html。
我們必須對Adrian的指令碼進行兩次關鍵編輯,才能讓它執行。如果你不關心Docker和Tensorflow的具體情況,可以跳過這兩段。
我們需要改的第一件事與Docker有關。本地執行應用程式時,flask在本地主機上預設埠( 127 . 0 . 0…)serve該應用程式。這在執行Docker Container時會引起一些問題。解決辦法很簡單。呼叫app.run ( )時,將URL指定為0.0.0.0,就像app.run一樣( host = ‘ 0.0.0.0 ‘ )。現在,我們的應用程式在本地主機和外部IP上都可用。
下一個問題涉及Tensorflow。當我執行Adrian的原始指令碼時,我無法成功呼叫模型。我閱讀了這個Github問題,並對程式碼進行了更改。

說實話,我不知道這是為什麼。但確實如此。所以讓我們把這個東西執行起來。
首先,讓我們建立一個名為keras-app的新目錄,並移動到該目錄中
mkdir keras-app
cd keras-app
現在,建立一個名為app.py的python檔案。你可以使用自己選擇的文字編輯器。我更喜歡用vim。要建立和開啟應用程式,請鍵入:
vim app.py
點選“i”鍵進入編輯樣式。現在,你可以貼上以下程式碼了。

複製了上述程式碼後,點選“Esc”鍵退出編輯樣式。
然後,透過鍵入: x來儲存和關閉檔案。
5 .創造一個requirements.txt檔案
現在回到正題上。我們將在Docker容器中執行這個程式碼。因此,為了做到這一點,我們需要首先建立一個requirements.txt。這個檔案將包含我們的程式碼執行所一些package,例如flask,keras等等。這樣,無論我們將Docker容器移動到哪裡,底層伺服器都能夠安裝我們的程式碼所需的依賴項。
就像以前一樣,透過vim來建立和編輯requirements . txt的內容。
將以下內容複製到requirements.txt中,並像以前一樣儲存和關閉
keras
tensorflow
flask
gevent
pillow
requests
6、建立Dockerfile
太好了!現在讓我們建立Dockerfile。這是Docker將根據Dockerfile來建立執行環境和執行project。
FROM python:3.6
WORKDIR /app
COPY requirements.txt /app
RUN pip install -r ./requirements.txt
COPY app.py /app
CMD [“python”, “app.py”]~
我們正在做的是:指示Docker下載Python 3的基本image。完成後,要求Docker使用Python包管理器pip安裝requirements . txt中的以來。
之後,我們告訴Docker透過Python應用程式執行我們的指令碼。
7、建造Docker container(容器)
繼續進行下一步。現在,讓我們構建並測試我們的應用程式。
要構建我們的Docker container,請執行:
sudo docker build -t keras-app:latest .
這指示Docker為位於我們當前工作環境目錄keras-app,構建一個容器。
這個命令需要一兩分鐘才能完成。幕後正在發生的事情是Docker正在建立Python 3.6的image,並安裝需求中列出的軟體包。
8、執行Docker container
現在讓我們執行Docker容器來測試我們的應用程式:
sudo docker run -d -p 5000:5000 keras-app
關於數字5000 : 5000的簡短說明—在這裡,我們告訴Docker讓5000埠對外可用,並轉發我們的本地應用到該埠(該埠也在本地5000上執行)
透過執行sudo docker ps -a 來檢查容器的狀態。你應該看到這樣的東西(下麵)
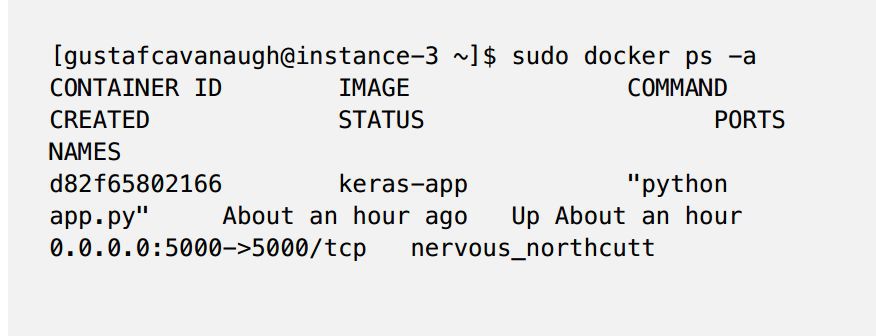
9 、測試我們的模型
隨著我們模型的執行,現在是測試它的時候了。這個模型接受一張狗的照片作為輸入,並傳回狗的品種。在Adrian的報告中,他提供了一個示例影象,我們將使用同樣的影象。

從終端執行:
curl -X POST -F image=@dog.jpg
‘http://localhost:5000/predict’
確保“dog . jpg”在你當前的目錄中(或者提供到該檔案的適當路徑)
你應該會看到這樣的結果:
{“predictions”:
[{“label”:”beagle”,”probability”:0.987775444984436},
{“label”:”pot”,”probability”:0.0020967808086425066},
{“label”:”Cardigan”,”probability”:0.001351703773252666},
{“label”:”Walker_hound”,”probability”:0.0012711131712421775},
{“label”:”Brittany_spaniel”,”probability”:0.0010085132671520114}],”success”:true}
我們可以看到,我們的模型正確地將狗歸類為小獵犬。太棒了!你已經成功地用Keras訓練了一個深度學習模型,用Flask來serve該模型,並用Docker包裝它。艱難的部分結束了。現在,讓我們用Kubernetes來部署這個容器
步驟3—使用Kubernetes部署模型
下一部分講的很快。
1、建立Docker中心賬戶(如果你沒有)
我們做的第一件事就是把我們的模型上傳到Docker Hub。(如果你沒有Docker Hub賬戶,現在就建立一個—別擔心,這是免費的)。我們這樣做的原因是,我們不會將我們的容器實際移動到Kubernetes叢集。相反,我們將指示Kubernetes從集中託管的伺服器(即Docker Hub )安裝我們的容器。
2 .登入你的Docker hub賬戶
建立Docker Hub帳戶後,透過sudo docker login從命令列登入。你需要提供你的使用者名稱和密碼,就像你登入網站一樣。
如果你看到這樣的資訊:
Login Succeeded
然後你成功登入。現在讓我們進入下一步。
3 .給你的容器貼標簽
我們需要在我們的容器上貼標簽,然後才能上傳。把這一步想象成給我們的容器起一個名字。
首先,執行sudo docker images,找到我們keras – app容器的image id。
輸出應該如下所示:
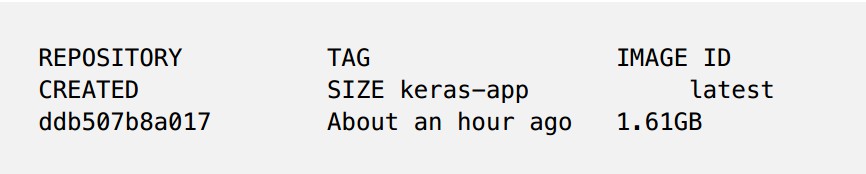
現在,讓我們標記我們的keras – app。請務必遵循我的格式,用你的特殊值替換image id和docker hub id的值。
#Format
sudo docker tag /
#My Exact Command – Make Sure To Use Your Inputs
sudo docker tag ddb507b8a017 gcav66/keras-app
4 .把我們的容器推到Docker hub
現在我們可以推容器了。在shell中執行:
#Format
sudo docker push /
#My exact command
sudo docker push gcav66/keras-app
現在,如果你導航回Docker Hub的網站,你應該會看到你的Keras – App儲存庫。幹得好!我們已經準備好了。
5 .建立Kubernetes叢集
從谷歌雲主螢幕中,選擇Kubernetes引擎
然後建立一個新的Kubernetes叢集
接下來,我們將定製叢集中節點的大小。我選擇了帶15 Gb RAM的4vCPUS。你可以用較小的叢集來嘗試這個。請記住,預設設定增加了3個節點,因此你的群集將擁有你配置資源的3倍,即在我的情況下,45 Gb的RAM。我有點懶,選擇了更大的尺寸,因為我們的Kubernetes叢集不會執行很長時間。
之後,只需單擊“create”。你的叢集需要一兩分鐘才能運轉起來。
現在讓我們連線到叢集。單擊“Run in Cloud Shell”,調出Kubernetes叢集的控制檯。請註意,這是一個獨立於虛擬機器的shell環境,你在這裡建立並測試了Docker容器。我們可以在虛擬機器上安裝Kubernetes,但是谷歌的Kubernetes服務會自動為我們安裝。
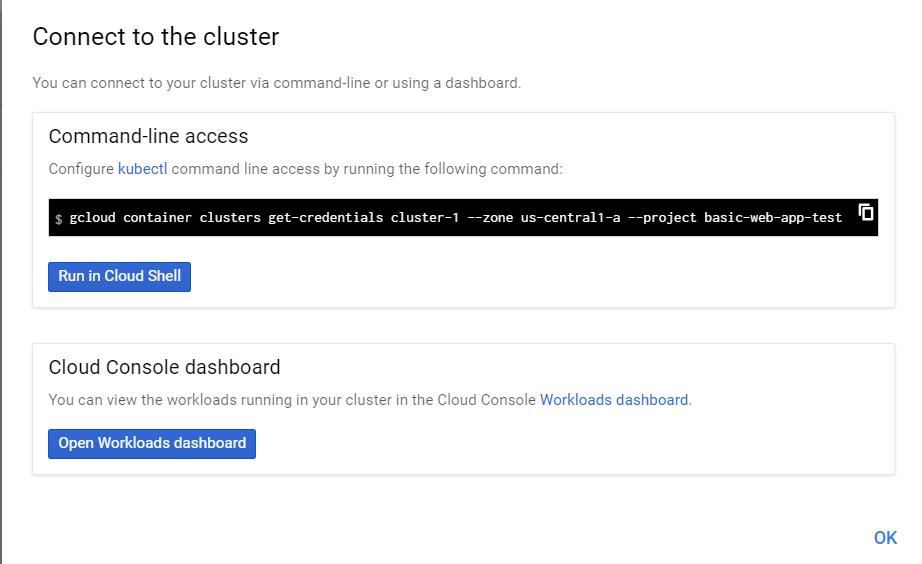
現在我們在Kubernetes執行Docker container。請註意,影象標簽只是指向我們在Docker Hub上託管的Docker image。此外,我們將使用- Port指定我們希望在Port 5000上執行我們的應用程式。
kubectl run keras-app –image=gcav66/keras-app –port 5000
在Kubernetes,容器都在豆莢(pods)裡執行。我們可以透過鍵入kubictl get pod來驗證我們的pod正在執行。如果你在下麵看到這樣的東西,說明已經準備好了。
gustafcavanaugh@cloudshell:~ (basic-web-app-test)$ kubectl get pods
NAME READY STATUS RESTARTS AGE
keras-app-79568b5f57-5qxqk 1/1 Running 0 1m
既然我們的pod還活著並且正在執行,我們需要將我們的pod透過80埠暴露給外界訪問。這意味著任何訪問我們部署的IP地址的人都可以訪問我們的API。這也意味著我們不必像以前一樣在我們的URL之後指定討厭的埠號(告別: 5000 )。
kubectl expose deployment keras-app —
type=LoadBalancer –port 80 –target-port 5000
我們快要接近成功了!現在,我們透過執行kubicl get服務來確定我們服務的部署狀態(以及我們需要呼叫API的URL )。同樣,如果這個命令的輸出看起來像我下麵的一樣,說明成功了。
gustafcavanaugh@cloudshell:~ (basic-web-app-test)$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP
PORT(S) AGE
keras-app LoadBalancer 10.11.250.71
35.225.226.94 80:30271/TCP 4m
kubernetes ClusterIP 10.11.240.1
443/TCP 18m
牢記你的keras應用程式的叢集IP,因為現在是關鍵時刻。開啟你的本地終端(或者你手邊有dog image的地方),執行以下命令呼叫API:
curl -X POST -F image=@dog.jpg ‘http:///predict’
盡情享受結果吧!
如下所示,API正確傳回了圖片的Beagle標簽。
$ curl -X POST -F image=@dog.jpg ‘http://35.225.226.94/predict’
{“predictions”: [{“label”:”beagle”,”probability”:0.987775444984436},
{“label”:”pot”,”probability”:0.0020967808086425066},
{“label”:”Cardigan”,”probability”:0.001351703773252666},
{“label”:”Walker_hound”,”probability”:0.0012711131712421775},
{“label”:”Brittany_spaniel”,”probability”:0.0010085132671520114}],”success”:true}
步驟4 -結束
在本教程中,我們使用Keras和Flask訓練並提供了一個深度學習模型作為REST API。然後,我們將該應用程式放入Docker容器中,將容器上傳到Docker Hub,並將其與Kubernetes一起部署。
Kubernetes只用了兩個命令就部署了我們的應用程式,並向世界展示了它。拍拍自己的背——你應該感到自豪。
現在,我們可以對這個專案做出許多改進。首先,我們應該將執行flask應用程式的python web伺服器從本地python伺服器更改為類似gunicorn的生產級伺服器。我們還應該探索Kubernetes的擴充套件和管理特性,我們幾乎沒有提到這一點。最後,可以嘗試從頭開始構建Kubernetes環境。
