在前面的文章中已經介紹了 Redis 的幾種高可用技術:持久化、主從複製和哨兵,但這些方案仍有不足,其中最主要的問題是儲存能力受單機限制,以及無法實現寫操作的負載均衡。

本文將詳細介紹叢集,主要內容包括:
-
叢集的作用
-
叢集的搭建方法及設計方案
-
叢集的基本原理
-
客戶端訪問叢集的方法
-
實踐須知(叢集伸縮、故障轉移、引數最佳化等)
叢集,即 Redis Cluster,是 Redis 3.0 開始引入的分散式儲存方案。叢集由多個節點(Node)組成,Redis 的資料分佈在這些節點中。
叢集中的節點分為主節點和從節點:只有主節點負責讀寫請求和叢集資訊的維護;從節點只進行主節點資料和狀態資訊的複製。
叢集的作用,可以歸納為兩點:
資料分割槽(或稱資料分片)是叢集最核心的功能。叢集將資料分散到多個節點:
-
一方面突破了 Redis 單機記憶體大小的限制,儲存容量大大增加。
-
另一方面每個主節點都可以對外提供讀服務和寫服務,大大提高了叢集的響應能力。
Redis 單機記憶體大小受限問題,在介紹持久化和主從複製時都有提及。
例如,如果單機記憶體太大,bgsave 和 bgrewriteaof 的 fork 操作可能導致主行程阻塞,主從環境下主機切換時可能導致從節點長時間無法提供服務,全量複製階段主節點的複製緩衝區可能上限溢位。
叢集支援主從複製和主節點的自動故障轉移(與哨兵類似),當任一節點發生故障時,叢集仍然可以對外提供服務。本文內容基於 Redis 3.0.6。
叢集的搭建
我們將搭建一個簡單的叢集:共 6 個節點,3 主 3 從。方便起見,所有節點在同一臺伺服器上,以埠號進行區分,配置從簡。
3個主節點埠號:7000/7001/7002;對應的從節點埠號:8000/8001/8002。
叢集的搭建有兩種方式:
-
手動執行 Redis 命令,一步步完成搭建
-
使用 Ruby 指令碼搭建
兩者搭建的原理是一樣的,只是 Ruby 指令碼將 Redis 命令進行了打包封裝;在實際應用中推薦使用指令碼方式,簡單快捷不容易出錯。下麵分別介紹這兩種方式。
叢集的搭建可以分為四步:
-
啟動節點:將節點以叢集樣式啟動,此時節點是獨立的,並沒有建立聯絡。
-
節點握手:讓獨立的節點連成一個網路。
-
分配槽:將 16384 個槽分配給主節點。
-
指定主從關係:為從節點指定主節點。
實際上,前三步完成後叢集便可以對外提供服務;但指定從節點後,叢集才能夠提供真正高可用的服務。
啟動節點
叢集節點的啟動仍然是使用 redis-server 命令,但需要使用叢集樣式啟動。
下麵是 7000 節點的配置檔案(只列出了節點正常工作關鍵配置,其他配置,如開啟 AOF,可以參照單機節點進行):
#redis-7000.conf
port 7000
cluster-enabled yes
cluster-config-file "node-7000.conf"
logfile "log-7000.log"
dbfilename "dump-7000.rdb"
daemonize yes
其中的 cluster-enabled 和 cluster-config-file 是與叢集相關的配置。
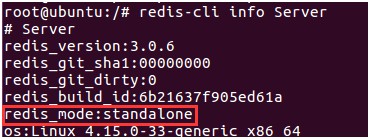
cluster-enabledyes:Redis 實體可以分為單機樣式(standalone)和叢集樣式(cluster);cluster-enabledyes 可以啟動叢集樣式。
在單機樣式下啟動的 Redis 實體,如果執行 info server 命令,可以發現 redis_mode 一項為 standalone,如下圖所示:
叢集樣式下的節點,其 redis_mode 為 cluster,如下圖所示:
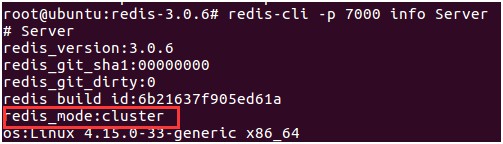
cluster-config-file:該引數指定了叢集配置檔案的位置。每個節點在執行過程中,會維護一份叢集配置檔案。
每當叢集資訊發生變化時(如增減節點),叢集內所有節點會將最新資訊更新到該配置檔案。
當節點重啟後,會重新讀取該配置檔案,獲取叢集資訊,可以方便的重新加入到叢集中。
也就是說,當 Redis 節點以叢集樣式啟動時,會首先尋找是否有叢集配置檔案。
如果有則使用檔案中的配置啟動;如果沒有,則初始化配置並將配置儲存到檔案中。叢集配置檔案由 Redis 節點維護,不需要人工修改。
編輯好配置檔案後,使用 redis-server 命令啟動該節點:
redis-server redis-7000.conf
節點啟動以後,透過 cluster nodes 命令可以檢視節點的情況,如下圖所示:

其中傳回值第一項表示節點 id,由 40 個 16 進位制字串組成,節點 id 與主從複製一文中提到的 runId 不同。
Redis 每次啟動 runId 都會重新建立,但是節點 id 只在叢集初始化時建立一次,然後儲存到叢集配置檔案中,以後節點重新啟動時會直接在叢集配置檔案中讀取。
其他節點使用相同辦法啟動,不再贅述。需要特別註意,在啟動節點階段,節點是沒有主從關係的,因此從節點不需要加 slaveof 配置。
節點握手
節點啟動以後是相互獨立的,並不知道其他節點存在;需要進行節點握手,將獨立的節點組成一個網路。
節點握手使用 cluster meet {ip} {port} 命令實現,例如在 7000 節點中執行 clustermeet 192.168.72.128 7001,可以完成 7000 節點和 7001 節點的握手。
註意:ip 使用的是區域網 ip,而不是 localhost 或 127.0.0.1,是為了其他機器上的節點或客戶端也可以訪問。
此時再使用 cluster nodes 檢視:

在 7001 節點下也可以類似檢視:

同理,在 7000 節點中使用 cluster meet 命令,可以將所有節點加入到叢集,完成節點握手:
cluster meet 192.168.72.128 7002
cluster meet 192.168.72.128 8000
cluster meet 192.168.72.128 8001
cluster meet 192.168.72.128 8002
執行完上述命令後,可以看到 7000 節點已經感知到了所有其他節點:

透過節點之間的通訊,每個節點都可以感知到所有其他節點,以 8000 節點為例:

分配槽
在 Redis 叢集中,藉助槽實現資料分割槽,具體原理後文會介紹。叢集有 16384 個槽,槽是資料管理和遷移的基本單位。
當資料庫中的 16384 個槽都分配了節點時,叢集處於上線狀態(ok);如果有任意一個槽沒有分配節點,則叢集處於下線狀態(fail)。
cluster info 命令可以檢視叢集狀態,分配槽之前狀態為 fail:

分配槽使用 cluster addslots 命令,執行下麵的命令將槽(編號 0-16383)全部分配完畢:
redis-cli -p 7000 cluster addslots {0..5461}
redis-cli -p 7001 cluster addslots {5462..10922}
redis-cli -p 7002 cluster addslots {10923..16383}
此時檢視叢集狀態,顯示所有槽分配完畢,叢集進入上線狀態:

指定主從關係
叢集中指定主從關係不再使用 slaveof 命令,而是使用 cluster replicate 命令;引數使用節點 id。
透過 cluster nodes 獲得幾個主節點的節點 id 後,執行下麵的命令為每個從節點指定主節點:
redis-cli -p 8000 cluster replicate be816eba968bc16c884b963d768c945e86ac51ae
redis-cli -p 8001 cluster replicate 788b361563acb175ce8232569347812a12f1fdb4
redis-cli -p 8002 cluster replicate a26f1624a3da3e5197dde267de683d61bb2dcbf1
此時執行 cluster nodes 檢視各個節點的狀態,可以看到主從關係已經建立:

至此,叢集搭建完畢。
在 {REDIS_HOME}/src 目錄下可以看到 redis-trib.rb 檔案,這是一個 Ruby 指令碼,可以實現自動化的叢集搭建。
①安裝 Ruby 環境
以 Ubuntu 為例,如下操作即可安裝 Ruby 環境:
-
apt-get install ruby # 安裝 Ruby 環境。
-
gem install redis #gem 是 Ruby 的包管理工具,該命令可以安裝 ruby-redis 依賴。
②啟動節點
與第一種方法中的“啟動節點”完全相同。
③搭建叢集
redis-trib.rb 指令碼提供了眾多命令,其中 create 用於搭建叢集,使用方法如下:
./redis-trib.rb create --replicas 1 192.168.72.128:7000192.168.72.128:7001 192.168.72.128:7002 192.168.72.128:8000 192.168.72.128:8001192.168.72.128:8002
其中:–replicas=1 表示每個主節點有 1 個從節點;後面的多個 {ip:port} 表示節點地址,前面的做主節點,後面的做從節點。使用 redis-trib.rb 搭建叢集時,要求節點不能包含任何槽和資料。
執行建立命令後,指令碼會給出建立叢集的計劃,如下圖所示;計劃包括哪些是主節點,哪些是從節點,以及如何分配槽。
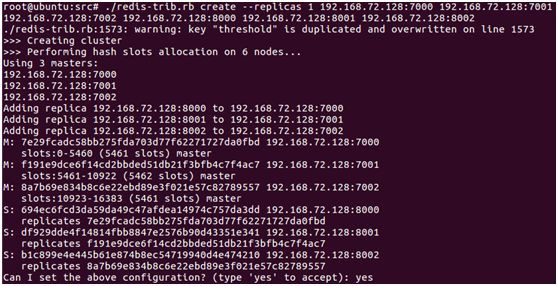
輸入 yes 確認執行計劃,指令碼便開始按照計劃執行,如下圖所示:
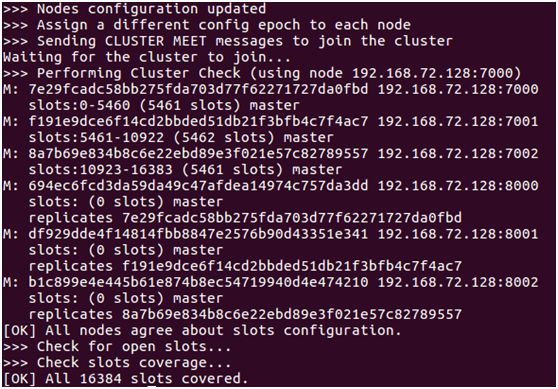
至此,叢集搭建完畢。
設計叢集方案時,至少要考慮以下因素:
-
高可用要求:根據故障轉移的原理,至少需要 3 個主節點才能完成故障轉移,且 3 個主節點不應在同一臺物理機上。
每個主節點至少需要 1 個從節點,且主從節點不應在一臺物理機上;因此高可用叢集至少包含 6 個節點。
-
資料量和訪問量:估算應用需要的資料量和總訪問量(考慮業務發展,留有冗餘),結合每個主節點的容量和能承受的訪問量(可以透過 benchmark 得到較準確估計),計算需要的主節點數量。
-
節點數量限制:Redis 官方給出的節點數量限製為 1000,主要是考慮節點間通訊帶來的消耗。
在實際應用中應儘量避免大叢集,如果節點數量不足以滿足應用對 Redis 資料量和訪問量的要求,可以考慮:①業務分割,大叢集分為多個小叢集;②減少不必要的資料;③調整資料過期策略等。
-
適度冗餘:Redis 可以在不影響叢集服務的情況下增加節點,因此節點數量適當冗餘即可,不用太大。
叢集的基本原理
上面介紹了叢集的搭建方法和設計方案,下麵將進一步深入,介紹叢集的原理。
叢集最核心的功能是資料分割槽,因此:
-
首先介紹資料的分割槽規則。
-
然後介紹叢集實現的細節:通訊機制和資料結構。
-
最後以 cluster meet(節點握手)、cluster addslots(槽分配)為例,說明節點是如何利用上述資料結構和通訊機制實現叢集命令的。
資料分割槽有順序分割槽、雜湊分割槽等,其中雜湊分割槽由於其天然的隨機性,使用廣泛;叢集的分割槽方案便是雜湊分割槽的一種。
雜湊分割槽的基本思路是:對資料的特徵值(如 key)進行雜湊,然後根據雜湊值決定資料落在哪個節點。
常見的雜湊分割槽包括:雜湊取餘分割槽、一致性雜湊分割槽、帶虛擬節點的一致性雜湊分割槽等。
衡量資料分割槽方法好壞的標準有很多,其中比較重要的兩個因素是:
-
資料分佈是否均勻。
-
增加或刪減節點對資料分佈的影響。
由於雜湊的隨機性,雜湊分割槽基本可以保證資料分佈均勻;因此在比較雜湊分割槽方案時,重點要看增減節點對資料分佈的影響。
雜湊取餘分割槽
雜湊取餘分割槽思路非常簡單:計算 key 的 hash 值,然後對節點數量進行取餘,從而決定資料對映到哪個節點上。
該方案最大的問題是,當新增或刪減節點時,節點數量發生變化,系統中所有的資料都需要重新計算對映關係,引發大規模資料遷移。
一致性雜湊分割槽
一致性雜湊演演算法將整個雜湊值空間組織成一個虛擬的圓環,如下圖所示,範圍為 0-2^32-1。
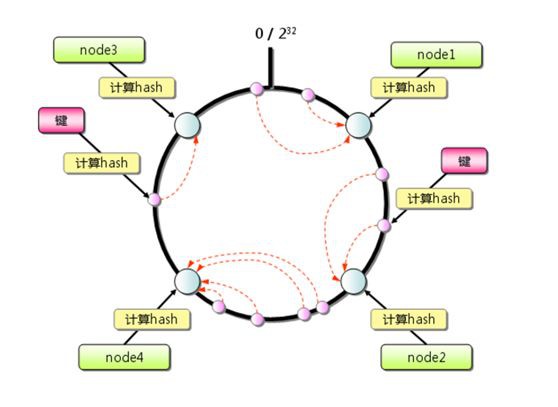
對於每個資料,根據 key 計算 hash 值,確定資料在環上的位置,然後從此位置沿環順時針行走,找到的第一臺伺服器就是其應該對映到的伺服器。
與雜湊取餘分割槽相比,一致性雜湊分割槽將增減節點的影響限制在相鄰節點。
以上圖為例,如果在 node1 和 node2 之間增加 node5,則只有 node2 中的一部分資料會遷移到 node5;如果去掉 node2,則原 node2 中的資料只會遷移到 node4 中,只有 node4 會受影響。
一致性雜湊分割槽的主要問題在於,當節點數量較少時,增加或刪減節點,對單個節點的影響可能很大,造成資料的嚴重不平衡。
還是以上圖為例,如果去掉 node2,node4 中的資料由總資料的 1/4 左右變為 1/2 左右,與其他節點相比負載過高。
帶虛擬節點的一致性雜湊分割槽
該方案在一致性雜湊分割槽的基礎上,引入了虛擬節點的概念。Redis 叢集使用的便是該方案,其中的虛擬節點稱為槽(slot)。
槽是介於資料和實際節點之間的虛擬概念;每個實際節點包含一定數量的槽,每個槽包含雜湊值在一定範圍內的資料。
引入槽以後,資料的對映關係由資料 hash->實際節點,變成了資料 hash->槽->實際節點。
在使用了槽的一致性雜湊分割槽中,槽是資料管理和遷移的基本單位。槽解耦了資料和實際節點之間的關係,增加或刪除節點對系統的影響很小。
仍以上圖為例,系統中有 4 個實際節點,假設為其分配 16 個槽(0-15);槽 0-3 位於 node1,4-7 位於 node2,以此類推。
如果此時刪除 node2,只需要將槽 4-7 重新分配即可,例如槽 4-5 分配給 node1,槽 6 分配給 node3,槽 7 分配給 node4;可以看出刪除 node2 後,資料在其他節點的分佈仍然較為均衡。
槽的數量一般遠小於 2^32,遠大於實際節點的數量;在 Redis 叢集中,槽的數量為 16384。
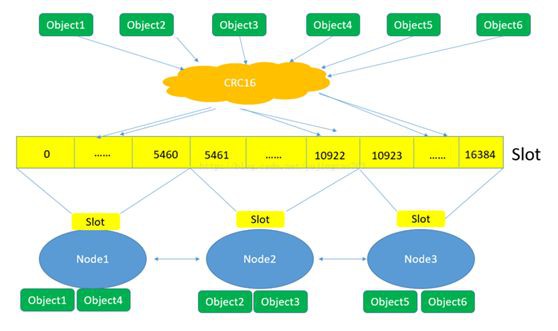
上面這張圖很好的總結了 Redis 叢集將資料對映到實際節點的過程:
-
Redis 對資料的特徵值(一般是key)計算雜湊值,使用的演演算法是 CRC16。
-
根據雜湊值,計算資料屬於哪個槽。
-
根據槽與節點的對映關係,計算資料屬於哪個節點。
叢集要作為一個整體工作,離不開節點之間的通訊。
兩個埠
在哨兵系統中,節點分為資料節點和哨兵節點:前者儲存資料,後者實現額外的控制功能。
在叢集中,沒有資料節點與非資料節點之分:所有的節點都儲存資料,也都參與叢集狀態的維護。
為此,叢集中的每個節點,都提供了兩個 TCP 埠:
-
普通埠:即我們在前面指定的埠(7000 等)。普通埠主要用於為客戶端提供服務(與單機節點類似);但在節點間資料遷移時也會使用。
-
叢集埠:埠號是普通埠+10000(10000 是固定值,無法改變),如 7000 節點的叢集埠為 17000。
叢集埠只用於節點之間的通訊,如搭建叢集、增減節點、故障轉移等操作時節點間的通訊;不要使用客戶端連線叢集介面。為了保證叢集可以正常工作,在配置防火牆時,要同時開啟普通埠和叢集埠。
Gossip 協議
節點間通訊,按照通訊協議可以分為幾種型別:單對單、廣播、Gossip 協議等。重點是廣播和 Gossip 的對比。
廣播是指向叢集內所有節點傳送訊息;優點是叢集的收斂速度快(叢集收斂是指叢集內所有節點獲得的叢集資訊是一致的),缺點是每條訊息都要傳送給所有節點,CPU、頻寬等消耗較大。
Gossip 協議的特點是:在節點數量有限的網路中,每個節點都“隨機”的與部分節點通訊(並不是真正的隨機,而是根據特定的規則選擇通訊的節點),經過一番雜亂無章的通訊,每個節點的狀態很快會達到一致。
Gossip 協議的優點有負載(比廣播)低、去中心化、容錯性高(因為通訊有冗餘)等;缺點主要是叢集的收斂速度慢。
訊息型別
叢集中的節點採用固定頻率(每秒 10 次)的定時任務進行通訊相關的工作:判斷是否需要傳送訊息及訊息型別、確定接收節點、傳送訊息等。
如果叢集狀態發生了變化,如增減節點、槽狀態變更,透過節點間的通訊,所有節點會很快得知整個叢集的狀態,使叢集收斂。
節點間傳送的訊息主要分為 5 種:
-
MEET 訊息
-
PING 訊息
-
PONG 訊息
-
FAIL 訊息
-
PUBLISH 訊息
不同的訊息型別,通訊協議、傳送的頻率和時機、接收節點的選擇等是不同的:
-
MEET 訊息:在節點握手階段,當節點收到客戶端的 cluster meet 命令時,會向新加入的節點傳送 MEET 訊息,請求新節點加入到當前叢集;新節點收到 MEET 訊息後會回覆一個 PONG 訊息。
-
PING 訊息:集群裡每個節點每秒鐘會選擇部分節點傳送 PING 訊息,接收者收到訊息後會回覆一個 PONG 訊息。PING 訊息的內容是自身節點和部分其他節點的狀態資訊;作用是彼此交換資訊,以及檢測節點是否線上。
PING 訊息使用 Gossip 協議傳送,接收節點的選擇兼顧了收斂速度和頻寬成本,具體規則如下:①隨機找 5 個節點,在其中選擇最久沒有通訊的 1 個節點。②掃描節點串列,選擇最近一次收到 PONG 訊息時間大於 cluster_node_timeout/2 的所有節點,防止這些節點長時間未更新。
-
PONG 訊息:PONG 訊息封裝了自身狀態資料。可以分為兩種:第一種是在接到 MEET/PING 訊息後回覆的 PONG 訊息;第二種是指節點向叢集廣播 PONG 訊息。
這樣其他節點可以獲知該節點的最新資訊,例如故障恢復後新的主節點會廣播 PONG 訊息。
-
FAIL 訊息:當一個主節點判斷另一個主節點進入 FAIL 狀態時,會向叢集廣播這一 FAIL 訊息;接收節點會將這一 FAIL 訊息儲存起來,便於後續的判斷。
-
PUBLISH 訊息:節點收到 PUBLISH 命令後,會先執行該命令,然後向叢集廣播這一訊息,接收節點也會執行該 PUBLISH 命令。
節點需要專門的資料結構來儲存叢集的狀態。所謂叢集的狀態,是一個比較大的概念,包括:叢集是否處於上線狀態、叢集中有哪些節點、節點是否可達、節點的主從狀態、槽的分佈……
節點為了儲存叢集狀態而提供的資料結構中,最關鍵的是 clusterNode 和 clusterState 結構:前者記錄了一個節點的狀態,後者記錄了叢集作為一個整體的狀態。
clusterNode
clusterNode 結構儲存了一個節點的當前狀態,包括建立時間、節點 id、ip 和埠號等。
每個節點都會用一個 clusterNode 結構記錄自己的狀態,併為叢集內所有其他節點都建立一個 clusterNode 結構來記錄節點狀態。
下麵列舉了 clusterNode 的部分欄位,並說明瞭欄位的含義和作用:
typedef struct clusterNode {
//節點建立時間
mstime_t ctime;
//節點id
char name[REDIS_CLUSTER_NAMELEN];
//節點的ip和埠號
char ip[REDIS_IP_STR_LEN];
int port;
//節點標識:整型,每個bit都代表了不同狀態,如節點的主從狀態、是否線上、是否在握手等
int flags;
//配置紀元:故障轉移時起作用,類似於哨兵的配置紀元
uint64_t configEpoch;
//槽在該節點中的分佈:佔用16384/8個位元組,16384個位元;每個位元對應一個槽:位元值為1,則該位元對應的槽在節點中;位元值為0,則該位元對應的槽不在節點中
unsigned char slots[16384/8];
//節點中槽的數量
int numslots;
…………
} clusterNode;
除此之外,clusterState 還包括故障轉移、槽遷移等需要的資訊。
這一部分將以 cluster meet(節點握手)、cluster addslots(槽分配)為例,說明節點是如何利用上述資料結構和通訊機制實現叢集命令的。
cluster meet
假設要向 A 節點傳送 cluster meet 命令,將 B 節點加入到 A 所在的叢集,則 A 節點收到命令後,執行的操作如下:
-
A 為 B 建立一個 clusterNode 結構,並將其新增到 clusterState 的 nodes 字典中。
-
A 向 B 傳送 MEET 訊息。
-
B 收到 MEET 訊息後,會為 A 建立一個 clusterNode 結構,並將其新增到 clusterState 的 nodes 字典中。
-
B 回覆 A 一個 PONG 訊息。
-
A 收到 B 的 PONG 訊息後,便知道 B 已經成功接收自己的 MEET 訊息。
-
然後,A 向 B 傳回一個 PING 訊息。
-
B 收到 A 的 PING 訊息後,便知道 A 已經成功接收自己的 PONG 訊息,握手完成。
-
之後,A 透過 Gossip 協議將 B 的資訊廣播給叢集內其他節點,其他節點也會與 B 握手;一段時間後,叢集收斂,B 成為叢集內的一個普通節點。
透過上述過程可以發現,叢集中兩個節點的握手過程與 TCP 類似,都是三次握手:A 向 B 傳送 MEET;B 向 A 傳送 PONG;A 向 B 傳送 PING。
cluster addslots
叢集中槽的分配資訊,儲存在 clusterNode 的 slots 陣列和 clusterState 的 slots 陣列中,兩個陣列的結構前面已做介紹。
二者的區別在於:前者儲存的是該節點中分配了哪些槽,後者儲存的是叢集中所有槽分別分佈在哪個節點。
cluster addslots 命令接收一個槽或多個槽作為引數,例如在 A 節點上執行 cluster addslots {0..10} 命令,是將編號為 0-10 的槽分配給 A 節點。
具體執行過程如下:
-
遍歷輸入槽,檢查它們是否都沒有分配,如果有一個槽已分配,命令執行失敗;方法是檢查輸入槽在 clusterState.slots[] 中對應的值是否為 NULL。
-
遍歷輸入槽,將其分配給節點 A;方法是修改 clusterNode.slots[] 中對應的位元為 1,以及 clusterState.slots[] 中對應的指標指向 A 節點。
-
A 節點執行完成後,透過節點通訊機制通知其他節點,所有節點都會知道 0-10 的槽分配給了 A 節點。
客戶端訪問叢集
在叢集中,資料分佈在不同的節點中,客戶端透過某節點訪問資料時,資料可能不在該節點中;下麵介紹叢集是如何處理這個問題的。
當節點收到 redis-cli 發來的命令(如 set/get)時,過程如下:
①計算 key 屬於哪個槽:CRC16(key) &16383。
叢集提供的 cluster keyslot 命令也是使用上述公式實現,如:

②判斷 key 所在的槽是否在當前節點:假設 key 位於第 i 個槽,clusterState.slots[i] 則指向了槽所在的節點。
如果 clusterState.slots[i]==clusterState.myself,說明槽在當前節點,可以直接在當前節點執行命令。
否則,說明槽不在當前節點,則查詢槽所在節點的地址(clusterState.slots[i].ip/port),並將其包裝到 MOVED 錯誤中傳回給 redis-cli。
③redis-cli 收到 MOVED 錯誤後,根據傳回的 ip 和 port 重新傳送請求。
下麵的例子展示了 redis-cli 和叢集的互動過程:在 7000 節點中操作 key1,但 key1 所在的槽 9189 在節點 7001 中。
因此節點傳回 MOVED 錯誤(包含 7001 節點的 ip 和 port)給 redis-cli,redis-cli 重新向 7001 發起請求。

上例中,redis-cli 透過 -c 指定了叢集樣式,如果沒有指定,redis-cli 無法處理 MOVED 錯誤:

redis-cli 這一類客戶端稱為 Dummy 客戶端,因為它們在執行命令前不知道資料在哪個節點,需要藉助 MOVED 錯誤重新定向。與 Dummy 客戶端相對應的是 Smart 客戶端。
Smart 客戶端(以 Java 的 JedisCluster 為例)的基本原理如下:
①JedisCluster 初始化時,在內部維護 slot->node 的快取,方法是連線任一節點,執行 cluster slots 命令,該命令傳回如下所示:
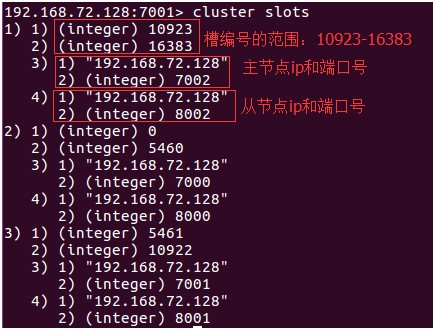
②此外,JedisCluster 為每個節點建立連線池(即 JedisPool)。
③當執行命令時,JedisCluster 根據 key->slot->node 選擇需要連線的節點,傳送命令。
如果成功,則命令執行完畢;如果執行失敗,則會隨機選擇其他節點進行重試,併在出現 MOVED 錯誤時,使用 cluster slots 重新同步 slot->node 的對映關係。
下麵程式碼演示瞭如何使用 JedisCluster 訪問叢集(未考慮資源釋放、異常處理等):
publicstatic void test() {
Setnodes = new HashSet<>();
nodes.add(newHostAndPort("192.168.72.128", 7000));
nodes.add(newHostAndPort("192.168.72.128", 7001));
nodes.add(newHostAndPort("192.168.72.128", 7002));
nodes.add(newHostAndPort("192.168.72.128", 8000));
nodes.add(newHostAndPort("192.168.72.128", 8001));
nodes.add(newHostAndPort("192.168.72.128", 8002));
JedisClustercluster = new JedisCluster(nodes);
System.out.println(cluster.get("key1"));
cluster.close();
}
註意事項如下:
-
JedisCluster 中已經包含所有節點的連線池,因此 JedisCluster 要使用單例。
-
客戶端維護了 slot->node 對映關係以及為每個節點建立了連線池,當節點數量較多時,應註意客戶端記憶體資源和連線資源的消耗。
-
Jedis 較新版本針對 JedisCluster 做了一些效能方面的最佳化,如 cluster slots 快取更新和鎖阻塞等方面的最佳化,應儘量使用 2.8.2 及以上版本的 Jedis。
實踐須知
前面介紹了叢集正常執行和訪問的方法和原理,下麵是一些重要的補充內容。
實踐中常常需要對叢集進行伸縮,如訪問量增大時的擴容操作。Redis 叢集可以在不影響對外服務的情況下實現伸縮;伸縮的核心是槽遷移:修改槽與節點的對應關係,實現槽(即資料)在節點之間的移動。
例如,如果槽均勻分佈在叢集的 3 個節點中,此時增加一個節點,則需要從 3 個節點中分別拿出一部分槽給新節點,從而實現槽在 4 個節點中的均勻分佈。
增加節點
假設要增加 7003 和 8003 節點,其中 8003 是 7003 的從節點,步驟如下:
①啟動節點:方法參見叢集搭建。
②節點握手:可以使用 cluster meet 命令,但在生產環境中建議使用 redis-trib.rb 的 add-node 工具,其原理也是 cluster meet,但它會先檢查新節點是否已加入其他叢集或者存在資料,避免加入到叢集後帶來混亂。
redis-trib.rb add-node 192.168.72.128:7003 192.168.72.1287000
redis-trib.rb add-node 192.168.72.128:8003 192.168.72.1287000
③遷移槽:推薦使用 redis-trib.rb 的 reshard 工具實現。reshard 自動化程度很高,只需要輸入 redis-trib.rb reshard ip:port (ip 和 port 可以是叢集中的任一節點)。
然後按照提示輸入以下資訊,槽遷移會自動完成:
-
待遷移的槽數量:16384 個槽均分給 4 個節點,每個節點 4096 個槽,因此待遷移槽數量為 4096。
-
標的節點 id:7003 節點的 id。
-
源節點的 id:7000/7001/7002 節點的 id。
④指定主從關係:方法參見叢集搭建。
減少節點
假設要下線 7000/8000 節點,可以分為兩步:
-
遷移槽:使用 reshard 將 7000 節點中的槽均勻遷移到 7001/7002/7003 節點。
-
下線節點:使用 redis-trib.rb del-node 工具;應先下線從節點再下線主節點,因為若主節點先下線,從節點會被指向其他主節點,造成不必要的全量複製。
redis-trib.rb del-node 192.168.72.128:7001 {節點8000的id}
redis-trib.rb del-node 192.168.72.128:7001 {節點7000的id}
ASK 錯誤
叢集伸縮的核心是槽遷移。在槽遷移過程中,如果客戶端向源節點傳送命令,源節點執行流程如下:
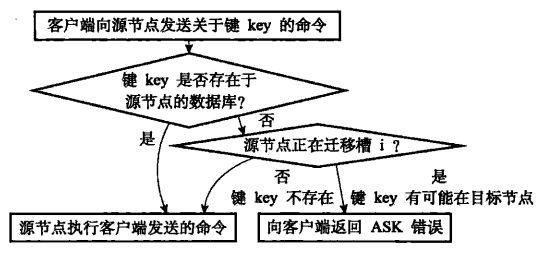
客戶端收到 ASK 錯誤後,從中讀取標的節點的地址資訊,並向標的節點重新傳送請求,就像收到 MOVED 錯誤時一樣。
但是二者有很大區別:ASK 錯誤說明資料正在遷移,不知道何時遷移完成,因此重定向是臨時的,SMART 客戶端不會掃清 slots 快取;MOVED 錯誤重定向則是(相對)永久的,SMART 客戶端會掃清 slots 快取。
在哨兵一文中,介紹了哨兵實現故障發現和故障轉移的原理。
雖然細節上有很大不同,但叢集的實現與哨兵思路類似:透過定時任務傳送 PING 訊息檢測其他節點狀態;節點下線分為主觀下線和客觀下線;客觀下線後選取從節點進行故障轉移。
與哨兵一樣,叢集只實現了主節點的故障轉移;從節點故障時只會被下線,不會進行故障轉移。
因此,使用叢集時,應謹慎使用讀寫分離技術,因為從節點故障會導致讀服務不可用,可用性變差。
這裡不再詳細介紹故障轉移的細節,只對重要事項進行說明:
節點數量:在故障轉移階段,需要由主節點投票選出哪個從節點成為新的主節點;從節點選舉勝出需要的票數為 N/2+1;其中 N 為主節點數量(包括故障主節點),但故障主節點實際上不能投票。
因此為了能夠在故障發生時順利選出從節點,叢集中至少需要 3 個主節點(且部署在不同的物理機上)。
故障轉移時間:從主節點故障發生到完成轉移,所需要的時間主要消耗在主觀下線識別、主觀下線傳播、選舉延遲等幾個環節。
具體時間與引數 cluster-node-timeout 有關,一般來說:
-
故障轉移時間(毫秒) ≤1.5 * cluster-node-timeout + 1000。
-
cluster-node-timeout 的預設值為 15000ms(15 s),因此故障轉移時間會在 20s 量級。
由於叢集中的資料分佈在不同節點中,導致一些功能受限,包括:
-
key 批次操作受限:例如 mget、mset 操作,只有當操作的 key 都位於一個槽時,才能進行。
針對該問題,一種思路是在客戶端記錄槽與 key 的資訊,每次針對特定槽執行 mget/mset;另外一種思路是使用 Hash Tag。
-
keys/flushall 等操作:keys/flushall 等操作可以在任一節點執行,但是結果只針對當前節點,例如 keys 操作只傳回當前節點的所有鍵。
針對該問題,可以在客戶端使用 cluster nodes 獲取所有節點資訊,並對其中的所有主節點執行 keys/flushall 等操作。
-
事務/Lua 指令碼:叢集支援事務及 Lua 指令碼,但前提條件是所涉及的 key 必須在同一個節點。Hash Tag 可以解決該問題。
-
資料庫:單機 Redis 節點可以支援 16 個資料庫,叢集樣式下只支援一個,即 db0。
-
複製結構:只支援一層複製結構,不支援巢狀。
Hash Tag 原理是:當一個 key 包含 {} 的時候,不對整個 key 做 hash,而僅對 {} 包括的字串做 hash。
Hash Tag 可以讓不同的 key 擁有相同的 hash 值,從而分配在同一個槽裡;這樣針對不同 key 的批次操作(mget/mset 等),以及事務、Lua 指令碼等都可以支援。
不過 Hash Tag 可能會帶來資料分配不均的問題,這時需要:
-
調整不同節點中槽的數量,使資料分佈儘量均勻。
-
避免對熱點資料使用 Hash Tag,導致請求分佈不均。
下麵是使用 Hash Tag 的一個例子:透過對 product 加 Hash Tag,可以將所有產品資訊放到同一個槽中,便於操作。
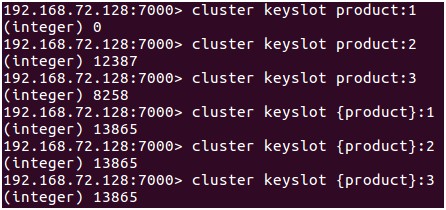
cluster_node_timeout
cluster_node_timeout 引數在前面已經初步介紹;它的預設值是 15s,影響包括:
-
影響 PING 訊息接收節點的選擇:值越大對延遲容忍度越高,選擇的接收節點越少,可以降低頻寬,但會降低收斂速度;應根據頻寬情況和應用要求進行調整。
-
影響故障轉移的判定和時間:值越大,越不容易誤判,但完成轉移消耗時間越長;應根據網路狀況和應用要求進行調整。
cluster-require-full-coverage
前面提到,只有當 16384 個槽全部分配完畢時,叢集才能上線。這樣做是為了保證叢集的完整性。
但同時也帶來了新的問題:當主節點發生故障而故障轉移尚未完成,原主節點中的槽不在任何節點中,此時叢集會處於下線狀態,無法響應客戶端的請求。
cluster-require-full-coverage 引數可以改變這一設定:如果設定為 no,則當槽沒有完全分配時,叢集仍可以上線。
引數預設值為 yes,如果應用對可用性要求較高,可以修改為 no,但需要自己保證槽全部分配。
redis-trib.rb 提供了眾多實用工具:建立叢集、增減節點、槽遷移、檢查完整性、資料重新平衡等;透過 help 命令可以檢視詳細資訊。
在實踐中如果能使用 redis-trib.rb 工具則儘量使用,不但方便快捷,還可以大大降低出錯機率。
參考文獻:
-
《Redis開發與運維》
-
《Redis設計與實現》
-
https://redis.io/topics/cluster-tutorial
-
https://redis.io/topics/cluster-spec
-
https://mp.weixin.qq.com/s/d6hzmk31o7VBsMYaLdQ5mw
-
https://www.cnblogs.com/lpfuture/p/5796398.html
-
http://www.zsythink.net/archives/1182/
-
https://www.cnblogs.com/xxdfly/p/5641719.html
