本文共3400字,建議閱讀10分鐘。
本文透過基線模型、LSTMs和Facebook的Prophet模型來預測每天的電子郵箱負荷,並詳細解析了生成訓練資料集的過程以及相應程式碼。
時間序列預測為資料科學演演算法提供了一個極好的訓練場。
畢竟,如果一個人能夠預測未來,那該有多牛逼啊!通常用來演示預測演演算法的典型資料集是股票圖表、銷售和氣象資料。在這裡,我們將嘗試一些與每個使用者更相關的東西,即你將收到的電子郵件的數量。根據一份電子郵件統計報告,2014年上半年,上班族平均每天收到85封電子郵件(http:/www.Radati.com/wp/wp-content/upploads/2014/01/Email-Statistics-Report-2014-2018-Executive-Summary.pdf)。
我們想嘗試根據歷史收件資料做出準確的預測。為此,我們將探索運用LSTMs和Facebook的Prophet。這裡的標的是如何為不同的演演算法準備資料,並提供定性的概述,而不是精細化。預測結果將根據歷史收到的電子郵件數量以及所準備的訓練資料而有很大的不同。
收集資料
在IBM imapclient sql包的幫助下,我們從使用自己的收件箱建立資料集開始。
關於Automatetheboringstuff.com/Chapter16/,可以在Automatetheboringstuff.com一章地址:https:/Automatetheboringstuff.com/中找到很好的介紹。
我們將載入過去三年(從2016年1月1日開始)的所有電子郵件,並獲取主題和日期。我們會使用Pandas將其轉換為一個資料檔案(Dataframe)。
Code:
import imapclient
import pandas as pd
import getpass
youremail = input()
yourpassword = getpass.getpass()
# Replace ‘imap.gmail.com’ with provider of choice
imapObj = imapclient.IMAPClient(“imap.gmail.com”, ssl=True)
imapObj.login(youremail, yourpassword)
imapObj.select_folder(“INBOX”, readonly=True)
UIDs = imapObj.search(‘(SINCE “01-Jan-2016”)’)
mails = []
for msgid, data in imapObj.fetch(UIDs, [“ENVELOPE”]).items():
envelope = data[b”ENVELOPE”]
date = envelope.date
if envelope.subject is not None:
subject = envelope.subject.decode()
else:
subject = None
mails.append((subject, date))
mail_df = pd.DataFrame(mails)
mail_df.columns = [“Subject”, “Date”]
mail_df[“Date”] = pd.to_datetime(mail_df[“Date”])
mail_df = mail_df.set_index(“Date”)
print(“A total of {} e-mails loaded.”.format(len(mail_df)))
郵箱負載:總計12738封郵件
我們現在得到了12738封用於訓練的電子郵件。請註意,上面的程式碼是針對一個裝滿電子郵件的收件箱。如果你已將電子郵件放在不同的檔案夾中,請相應地調整程式碼。包括我在內的一些人會立即刪除那些不重要的電子郵件。然後,模型輸出的是重要郵件的數量,而不是實際收到的電子郵件數量。還要註意的是,一些電子郵件提供商(如Google)會阻止這個連線,因為他們不允許“不太安全”的應用程式連線到他們的服務。你可以在其設定中啟用此功能。原則上,你還可以檢驗(簽出)本地郵箱。檢驗(簽出)統一郵箱程式包可能是個好的開始。
資料探索
現在,讓我們首先做一些視覺化的資料探索和圖表,每小時和每天的電子郵件數量。對於這一點,我們將使用pandas及重新取樣的groubpy 函式(聚合分組運算)。透過使用sum()和count()引數,我們可以對每個時間間隔進行標準化。另外,我們還使用了seaborn函式來實現視覺化。
Code:
import calendar
import seaborn as sns
import matplotlib.pyplot as plt
weekdays = [calendar.day_name[i] for i in range(7)]
# E-Mails per Hour
per_hour = pd.DataFrame(mail_df[“Subject”].resample(“h”).count())
per_hour_day = (
per_hour.groupby([per_hour.index.hour]).sum()
/ per_hour.groupby([per_hour.index.hour]).count()
)
per_hour_day.reset_index(inplace=True)
per_hour_day.columns = [“Hour”, “Count”]
# E-Mails per day
per_day = pd.DataFrame(mail_df[“Subject”].resample(“d”).count())
per_day_week = (
per_day.groupby([per_day.index.weekday]).sum()
/ per_day.groupby([per_day.index.weekday]).count()
)
per_day_week.reset_index(inplace=True)
per_day_week.columns = [“Weekday”, “Count”]
per_day_week[“Weekday”] = weekdays
def return_cmap(data):
# Function to create a colormap
v = data[“Count”].values
colors = plt.cm.RdBu_r((v – v.min()) / (v.max() – v.min()))
return colors
plt.figure(figsize=(12, 10), dpi=600)
plt.subplot(2, 1, 1)
cmap = return_cmap(per_hour_day)
sns.barplot(x=”Hour”, y=”Count”, data=per_hour_day, palette=cmap)
plt.title(“Emails per hour”)
plt.subplot(2, 1, 2)
cmap = return_cmap(per_day_week)
sns.barplot(x=”Weekday”, y=”Count”, data=per_day_week, palette=cmap)
plt.title(“Emails per weekday”)
plt.show()
print(
“Average number of emails per day: {:.2f}”.format(
per_hour_day.sum()[“Count”]
)
)
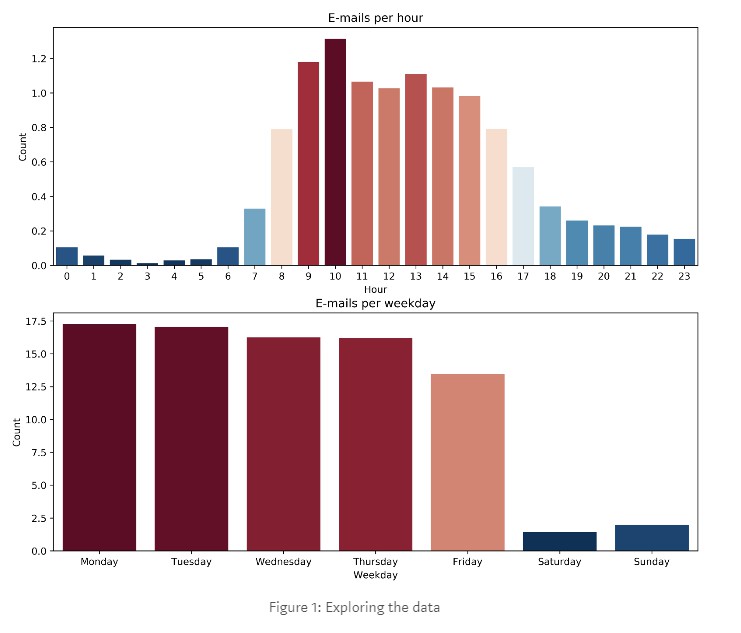
圖1:探索資料(圖)
從資料中我們可以看到一個明顯的規律,即分發遵循一個典型樣式,從星期一至星期五早9-晚5的時間表,其中上午10點收到的郵件最多。由於每小時電子郵件的最大值僅略高於1,因此對每小時進行預測是沒有意義的。我們將嘗試預測每天的電子郵件工作量。
初步考慮:預測不可預測的
在深入研究我們的模型之前,有必要考慮一下這個問題的相關假設。接收電子郵件的時間在某種程度上是隨機的,因此無法預測。在大多數情況下,傳送方互相不認識,因此可以假設它們在統計上是獨立的。另外,我們可以將收件近似為泊松過程(Poissonian),它的標準偏差等於平均值。由於分佈是隨機的,12封電子郵件的期望的RMSE值至少為3.5(sqrt(11.95)~3.461)。
如果你想進一步閱讀,我建議閱讀有關DB2Erlang發行版
(https:/en.wikipea.org/wiki/Erlang_Distributions)的內容,研究該發行版是為了檢驗在某一時期內的電話撥出的數量。(https:/en.wikipea.org/wiki/erlang_Distributions)
計算基準線
為了建立基線模型,我們可以使用歷史資料中的查詢表。對於任意的某一天,計算在一天之前收到的電子郵件數量。為了對模型進行基準測試,我使用一個移動視窗來建立查詢表,並計算到第二天的預測差異值。
Code:
from sklearn.metrics import mean_squared_error
import numpy as np
data = per_day.copy()
test_split = int(len(data) * 0.8)
pred_base = []
for i in range(len(data) – test_split):
train_data = data[i : test_split + i]
test_data = data.iloc[test_split + i]
train_data_week = (
train_data.groupby([train_data.index.weekday]).sum()
/ train_data.groupby([train_data.index.weekday]).count()
)
baseline_prediction = train_data_week.loc[test_data.name.weekday()]
pred_base.append(baseline_prediction.values)
test_data = data[test_split:]
mse_baseline = mean_squared_error(test_data.values, pred_base)
print(“RMSE for BASELINE {:.2f}”.format(np.sqrt(mse_baseline)))
RMSE 基線 7.39
基線模型得到的RMSE為7.39 ,相對於3.5的預期值,這個結果還不錯。
使用LSTM進行預測
作為進階模型,我們將使用長短時記憶(LSTM)神經網路。在這裡可以找到對LSTM的很好的介紹(https:/machinelearningmaster ery.com/time-Series-prediction-lstm-rrurn-neuro-network-python-keras/)。
在這裡,我們將視窗設定為6天,並讓模型預測第7天。
Code:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
def get_window_data(data, window):
# Get window data and scale
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data.reshape(-1, 1))
X = []
y = []
for i in range(len(data) – window – 1):
X.append(data[i : i + window])
y.append(data[i + window + 1])
X = np.asarray(X)
y = np.asarray(y)
return X, y, scaler
window_size = 6
X, y, scaler = get_window_data(per_day[“Subject”].values, window_size)
X_train = X[:test_split]
X_test = X[test_split:]
y_train = y[:test_split]
y_test = y[test_split:]
model = Sequential()
model.add(LSTM(50, input_shape=(window_size, 1)))
model.add(Dropout(0.2))
model.add(Dense(1))
model.add(Activation(“linear”))
model.compile(loss=”mse”, optimizer=”adam”)
history = model.fit(
X_train,
y_train,
epochs=20,
batch_size=1,
validation_data=(X_test, y_test),
verbose=2,
shuffle=False,
)
# plot history
plt.figure(figsize=(6, 5), dpi=600)
plt.plot(history.history[“loss”], ‘darkred’, label=”Train”)
plt.plot(history.history[“val_loss”], ‘darkblue’, label=”Test”)
plt.title(“Loss over epoch”)
plt.xlabel(‘Epoch’)
plt.ylabel(‘Loss’)
plt.legend()
plt.show()
mse_lstm = mean_squared_error(
scaler.inverse_transform(y_test),
scaler.inverse_transform(model.predict(X_test)),
)
print(“RMSE for LSTM {:.2f}”.format(np.sqrt(mse_lstm)))
LSTM為7.26RMSE
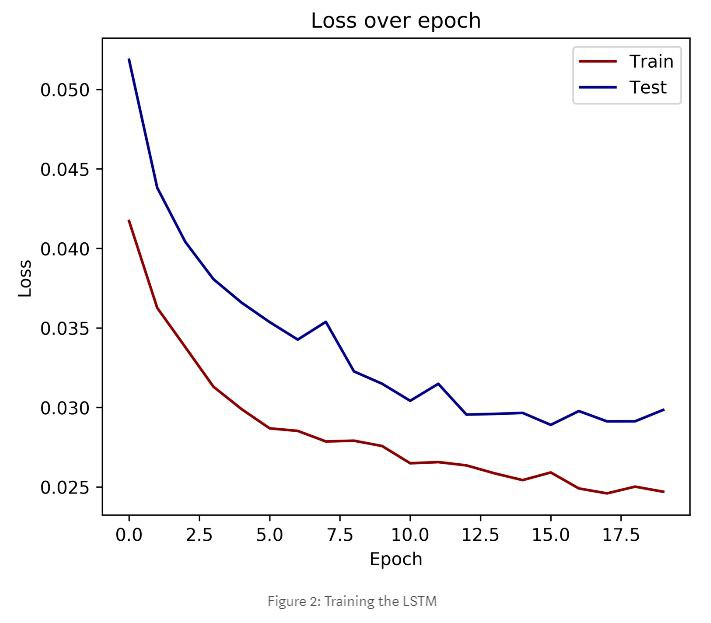
圖2:訓練LSTM
透過觀察損失函式,我們可以看到LSTM網路透過迭代學習更好地預測了未來。它的RMSE比基線模型要好一些,但也並沒有好多少。這一結果表明,LSTM網路能夠學習週末和工作日的結構,週末收到的電子郵件更少。另外值得一提的是,我們不能直接將基線的RMSE與LSTM進行比較。因為LSTM實際上只用到了80%的訓練資料。我們也可以使用全部資料來訓練LSTM,然而從計算上來說,這樣做的代價要高得多。
使用Prophet進行預測
接下來,我們將使用facebook的Prophet庫(https://github.com/facebook/prophet)。它是一個加性模型,我們可以用年、周和日的季節性來擬合非線性趨勢。同樣地,我們將把資料分成訓練集和測試集,並計算RMSE值。
Code:
from fbprophet import Prophet
from tqdm import tqdm
prophet_data = data.reset_index()
prophet_data[“ds”] = prophet_data[“Date”]
prophet_data[“y”] = prophet_data[“Subject”]
pred = []
for i in tqdm(range(len(data) – test_split)):
data_to_fit = prophet_data[: (test_split + i)]
prophet_model = Prophet(interval_width=0.95)
prophet_model.fit(data_to_fit)
prophet_forecast = prophet_model.make_future_dataframe(periods=1, freq=”d”)
prophet_forecast = prophet_model.predict(prophet_forecast)
pred.append(prophet_forecast[“yhat”].iloc[-1])
mse_prophet = mean_squared_error(test_data.values, pred)
print(“RMSE for PROPHET {:.2f}”.format(np.sqrt(mse_prophet)))
PROPHET為6.96RMSE
從RMSE來看,Prophet模型實現了最佳效能。現在讓我們研究一下這是為什麼。為此,我們繪製模型的各個構成部分,以便更好地理解模型所做的工作。這隻需要使用效能指標函式就可以輸出結果。
(輸出)
from fbprophet.diagnostics import performance_metricsprophet_model.plot_components(prophet_forecast)
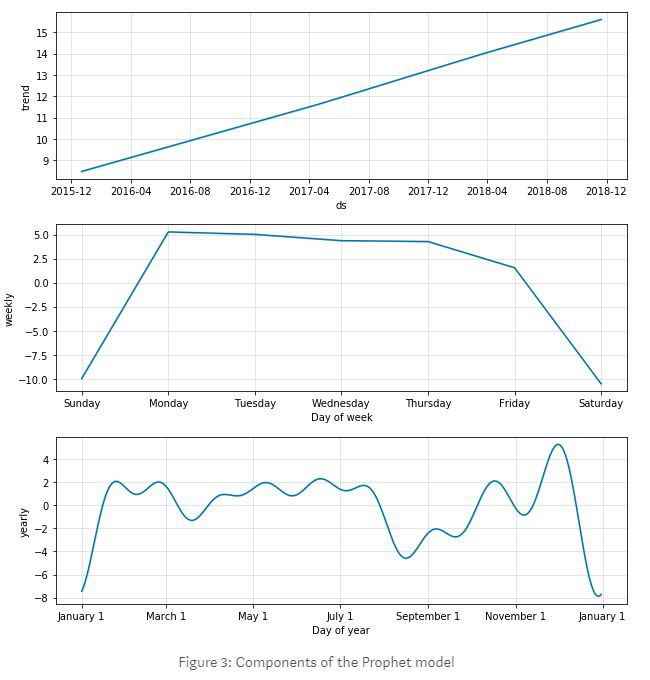
圖3:Prophet模型的構成
透過檢查Prophet模型的構成,我們可以看到它識別出了資料中的關鍵趨勢。總趨勢表明郵件數量在整體上不斷增加。每週的季節性準確地描繪了工作日/週末的時間波動。每年的季節性顯示主要節日,即新年電子郵件很少,但在聖誕節前有所增加,而低點在9月份。
總結:預測郵件數量。
最後,我們使用Prophet模型作為我們的預測工具。為此,我們再次登入到IMAP伺服器,並使用自2016年1月1日以來的所有歷史資料來訓練我們的預測模型。訓練完畢後,我們繪製了前一週的歷史資料和下一週的預測情況。
Code:
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
from fbprophet import Prophet
import imapclient
import pandas as pd
import getpass
youremail = input()
yourpassword = getpass.getpass()
imapObj = imapclient.IMAPClient(“imap.gmail.com”, ssl=True)
imapObj.login(youremail, yourpassword)
imapObj.select_folder(“INBOX”, readonly=True)
UIDs = imapObj.search(‘(SINCE “01-Jan-2016”)’)
mails = []
for msgid, data in imapObj.fetch(UIDs, [“ENVELOPE”]).items():
envelope = data[b”ENVELOPE”]
date = envelope.date
if envelope.subject is not None:
subject = envelope.subject.decode()
else:
subject = None
mails.append((subject, date))
mail_df = pd.DataFrame(mails)
mail_df.columns = [“Subject”, “Date”]
mail_df[“Date”] = pd.to_datetime(mail_df[“Date”])
mail_df = mail_df.set_index(“Date”)
data = pd.DataFrame(mail_df[“Subject”].resample(“d”).count())
prophet_model = Prophet(interval_width=0.95)
prophet_data = data.reset_index()
prophet_data[“ds”] = prophet_data[“Date”]
prophet_data[“y”] = prophet_data[“Subject”]
prophet_model.fit(prophet_data)
prophet_forecast = prophet_model.make_future_dataframe(periods=7, freq=”d”)
prophet_forecast = prophet_model.predict(prophet_forecast)
fig1 = prophet_model.plot(prophet_forecast)
datenow = datetime.now()
dateend = datenow + timedelta(days=7)
datestart = dateend – timedelta(days=14)
plt.xlim([datestart, dateend])
plt.title(“Email forecast”, fontsize=20)
plt.xlabel(“Day”, fontsize=20)
plt.ylabel(“Emails expected”, fontsize=20)
plt.axvline(datenow, color=”k”, linestyle=”:”)
plt.show()
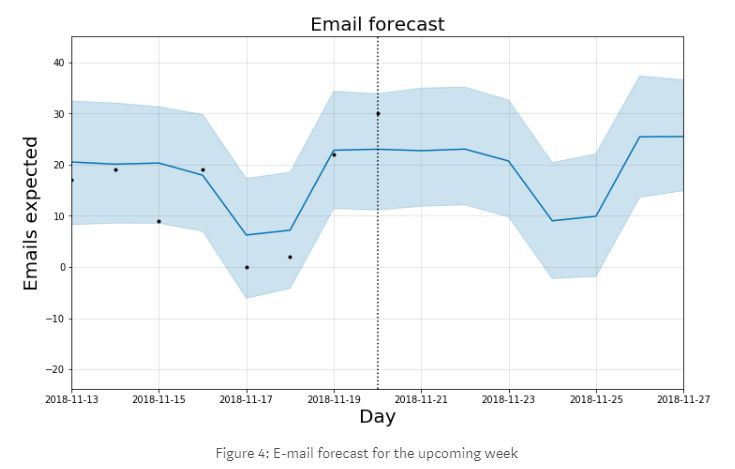
圖4:即將到來一週的郵件預測
討論
LSTMS和Facebook的Prophet模型提供了一種簡單易懂的方法來預測電子郵件數量,而且具有相當好的準確性。考慮到模型的基本機制,這一結果是可以理解的。LSTM預測是基於一組最後的值,因此不太容易考慮到季節差異。相比之下,Prophet模型發現並顯示了季節性。
該模型可以對規劃未來的工作量或人員配置提供參考。
這類問題的一個關鍵挑戰是,如果只有零星的偶發事件,那麼內在趨勢是不可預測的。
最後別忘了,我們的基線模型的表現就很不錯,所以你不一定總是需要複雜的機器學習演演算法來搭建你的預測模型。
原文地址:
https://towardsdatascience.com/time-series-forecasting-with-lstms-and-prophet-predict-your-email-workload-48bf9cdb1580
譯者簡介:笪潔瓊,中南財大MBA在讀,目前研究方向:金融大資料。
「完」
