前言
這篇文章的主題是記錄一次Python程式的效能最佳化,在最佳化的過程中遇到的問題,以及如何去解決的。為大家提供一個最佳化的思路,首先要宣告的一點是,我的方式不是唯一的,大家在效能最佳化之路上遇到的問題都絕對不止一個解決方案。
如何最佳化
首先大家要明確的一點是,脫離需求談最佳化都是耍流氓,所以有誰跟你說在xx機器上實現了百萬併發,基本上可以認為是不懂裝懂了,單純的併發數完全是無意義的。其次,我們最佳化之前必須要有一個標的,需要最佳化到什麼程度,沒有明確標的的最佳化是不可控的。再然後,我們必須明確的找出效能瓶頸在哪裡,而不能漫無目的的一通亂搞。
需求描述
這個專案是我在上家公司負責一個單獨的模組,本來是整合在主站程式碼中的,後來因為併發太大,為了防止出現問題後拖累主站服務,所有由我一個人負責拆分出來。對這個模組的拆分要求是,壓力測試QPS不能低於3萬,資料庫負載不能超過50%,伺服器負載不能超過70%, 單次請求時長不能超過70ms,錯誤率不能超過5%。
環境的配置如下:
伺服器:4核8G記憶體,centos7系統,ssd硬碟
資料庫:Mysql5.7,最大連線數800
快取: redis, 1G容量。
以上環境都是購買自騰訊雲的服務。
壓測工具:locust,使用騰訊的彈性伸縮實現分散式的壓測。
需求描述如下:
使用者進入首頁,從資料庫中查詢是否有合適的彈窗配置,如果沒有,則繼續等待下一次請求、如果有合適的配置,則傳回給前端。這裡開始則有多個條件分支,如果使用者點選了彈窗,則記錄使用者點選,並且在配置的時間內不再傳回配置,如果使用者未點選,則24小時後繼續傳回本次配置,如果使用者點選了,但是後續沒有配置了,則接著等待下一次。
重點分析
根據需求,我們知道了有幾個重要的點,1、需要找出合適使用者的彈窗配置,2、需要記錄使用者下一次傳回配置的時間並記錄到資料庫中,3、需要記錄使用者對傳回的配置執行了什麼操作並記錄到資料庫中。
調優
我們可以看到,上述三個重點都存在資料庫的操作,不只有讀庫,還有寫庫操作。從這裡我們可以看到如果不加快取的話,所有的請求都壓到資料庫,勢必會佔滿全部連線數,出現拒絕訪問的錯誤,同時因為sql執行過慢,導致請求無法及時傳回。所以,我們首先要做的就是講寫庫操作剝離開來,提升每一次請求響應速度,最佳化資料庫連線。整個系統的架構圖如下:
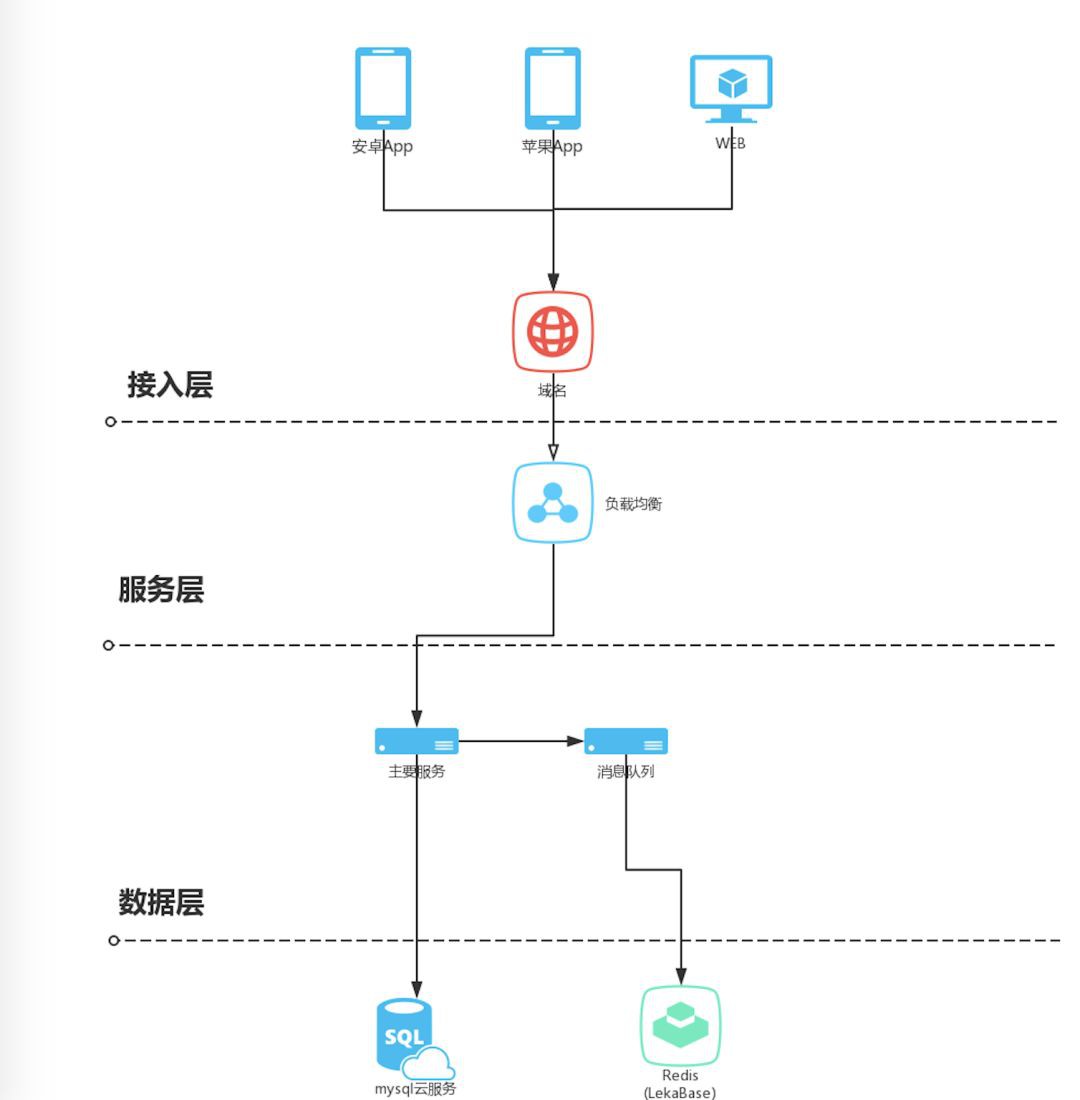
將寫庫操作放到一個先進先出的訊息佇列中來做,為了減少複雜度,使用了redis的list來做這個訊息佇列。
然後進行壓測,結果如下:
QPS在6000左右502錯誤大幅上升至30%,伺服器cpu在60%-70%之間來回跳動,資料庫連線數被佔滿tcp連線數為6000左右,很明顯,問題還是出在資料庫,經過排查sql陳述句,查詢到原因就是找出合適使用者的配置操作時每次請求都要讀取資料庫所導致的連線數被用完。因為我們的連線數只有800,一旦請求過多,勢必會導致資料庫瓶頸。好了,問題找到了,我們繼續最佳化,更新的架構如下
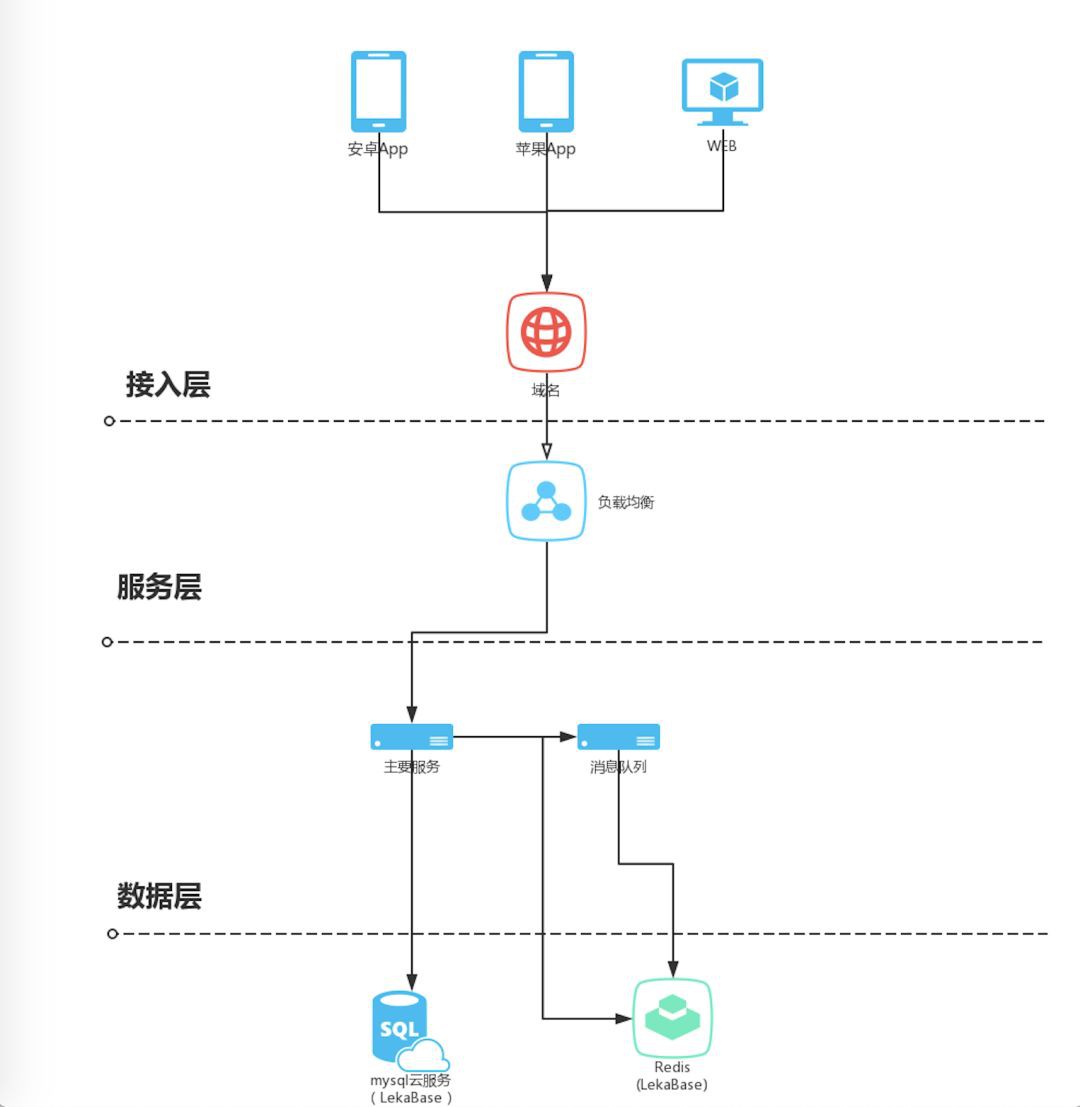
我們將全部的配置都載入到快取中,只有在快取中沒有配置的時候才會去讀取資料庫。
接下來我們再次壓測,結果如下:
QPS壓到2萬左右的時候就上不去了,伺服器cpu在60%-80%之間跳動,資料庫連線數為300個左右,每秒tpc連線數為1.5萬左右。
這個問題是困擾我比較久的一個問題,因為我們可以看到,我們2萬的QPS,但是tcp連線數卻並沒有達到2萬,我猜測,tcp連線數就是引發瓶頸的問題,但是因為什麼原因所引發的暫時無法找出來。
這個時候猜測,既然是無法建立tcp連線,是否有可能是伺服器限制了socket連線數,驗證猜測,我們看一下,在終端輸入ulimit -n命令,顯示的結果為65535,看到這裡,覺得socket連線數並不是限制我們的原因,為了驗證猜測,將socket連線數調大為100001.
再次進行壓測,結果如下:
QPS壓到2.2萬左右的時候就上不去了,伺服器cpu在60%-80%之間跳動,資料庫連線數為300個左右,每秒tpc連線數為1.7萬左右。
雖然有一點提升,但是並沒有實質性的變化,接下來的幾天時間,我發現都無法找到最佳化的方案,那幾天確實很難受,找不出來最佳化的方案,過了幾天,再次將問題梳理了一遍,發現,雖然socket連線數足夠,但是並沒有全部被用上,猜測,每次請求過後,tcp連線並沒有立即被釋放,導致socket無法重用。經過查詢資料,找到了問題所在,
tcp連結在經過四次握手結束連線後並不會立即釋放,而是處於timewait狀態,會等待一段時間,以防止客戶端後續的資料未被接收。好了,問題找到了,我們要接著最佳化,首先想到的就是調整tcp連結結束後等待時間,但是linux並沒有提供這一核心引數的調整,如果要改,必須要自己重新編譯核心,幸好還有另一個引數net.ipv4.tcp_max_tw_buckets, timewait 的數量,預設是 180000。我們調整為6000,然後開啟timewait快速回收,和開啟重用,完整的引數最佳化如下
#timewait 的數量,預設是 180000。
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.ip_local_port_range = 1024 65000
#啟用 timewait 快速回收。
net.ipv4.tcp_tw_recycle = 1
#開啟重用。允許將 TIME-WAIT sockets 重新用於新的 TCP 連線。
net.ipv4.tcp_tw_reuse = 1我們再次壓測,結果顯示:
QPS5萬,伺服器cpu70%,資料庫連線正常,tcp連線正常,響應時間平均為60ms,錯誤率為0%。
結語
到此為止,整個服務的開發、調優、和壓測就結束了。回顧這一次調優,得到了很多經驗,最重要的是,深刻理解了web開發不是一個獨立的個體,而是網路、資料庫、程式語言、作業系統等多門學科結合的工程實踐,這就要求web開發人員有牢固的基礎知識,否則出現了問題還不知道怎麼分析查詢。
ps:服務端開啟了 tcp_tw_recycle 和 tcp_tw_reuse是會導致一些問題的,我們為了最佳化選擇犧牲了一部分,獲得另一部分,這也是我們要明確的,具體的問題可以檢視耗子叔的文章TCP 的那些事兒(上)
(完)

