墨墨導讀:最近電子工業出版社博文視點出版了《PostgreSQL指南:內幕探索》,日前「資料和雲」公眾號推薦了這本書並贈送了五本,百多位使用者參與,幾十條留言未能放出,為了讓大家更好地學習開源資料PostgreSQL,經出版社官方授權,刊載本書部分章節內容以饗讀者,本文節選了第五章《併發控制》5.1 -5.2。
此外,我們也成立PostgreSQL學習社群,技術探討、資料分享、大牛解答,歡迎加入一起進步,入群方式見文末。
之前,我們分享了解讀年度資料庫PostgreSQL:基礎備份與時間點恢復(上),解讀年度資料庫PostgreSQL:基礎備份與時間恢復(下)
當多個事務同時在資料庫中執行時,併發控制是一種用於維持一致性與隔離性的技術,一致性與隔離性是ACID的兩個屬性。
譯者註:ACID指資料庫事務正確執行的四個基本要素的縮寫,包含原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、永續性(Durability)。
從寬泛的意義上來講,有三種併發控制技術,分別是多版本併發控制(Multi-Version Concurrency Control,MVCC)、嚴格兩階段鎖定(Strict Two-Phase Locking,S2PL)和樂觀併發控制(Optimistic Concurrency Control,OCC),每種技術都有多種變體。在MVCC中,每個寫操作都會建立一個新版本的資料項,並保留其舊版本。當事務讀取資料物件時,系統會選擇其中的一個版本,透過這種方式來確保各個事務間相互隔離。MVCC的主要優勢在於“讀不會阻塞寫,寫也不會阻塞讀”,相反的例子是,基於S2PL的系統在寫操作發生時會阻塞相應物件上的讀操作,因為寫入者獲取了物件上的排他鎖。PostgreSQL和一些關係型資料庫使用一種MVCC的變體,叫作快照隔離(Snapshot Isolation,SI)。
一些關係型資料庫(例如Oracle)使用回滾段來實現快照隔離SI。當寫入新資料物件時,舊版本物件先被寫入回滾段,隨後用新物件覆寫至資料區域。PostgreSQL使用更簡單的方法,即新資料物件被直接插入相關表頁中。讀取物件時,PostgreSQL根據可見性檢查規則,為每個事務選擇合適的物件版本作為響應。
SI中不會出現在ANSI SQL-92標準中定義的三種異常,分別是臟讀、不可重覆讀和幻讀。但SI無法實現真正的可序列化,因為在SI中可能會出現序列化異常,例如寫偏差和只讀事務偏差。需要註意的是,ANSI SQL-92標準中可序列化的定義與現代理論中的定義並不相同。為瞭解決這個問題,PostgreSQL從9.1版本之後添加了可序列化快照隔離(Serializable Snapshot Isolation,SSI),SSI可以檢測序列化異常,並解決這種異常導致的衝突。因此,9.1版本之後的PostgreSQL提供了真正的SERIALIZABLE隔離等級(SQL Server也使用SSI,而Oracle仍然使用SI)。
併發控制包含著很多主題,本章重點介紹PostgreSQL獨有的內容。故此處省略了鎖樣式與死鎖處理的內容(相關資訊請參閱官方檔案)。
PostgreSQL中的事務隔離等級
PostgreSQL實現的事務隔離等級如下表所示:
|
隔離等級 |
臟 讀 |
不可重覆讀 |
幻 讀 |
序列化異常 |
|
讀已提交 |
不可能 |
可能 |
可能 |
可能 |
|
可重覆讀[1] |
不可能 |
不可能 |
PG中不可能,見第5.7.2小節,但ANSI SQL中可能 |
可能 |
|
可序列化 |
不可能 |
不可能 |
不可能 |
不可能 |
[1]:在9.0及更低版本中,該級別被當作SERIALIZABLE,因為它不會出現ANSI SQL-92標準中定義的三種異常。但9.1版中SSI的實現引入了真正的SERIALIZABLE級別,該級別已被改稱為REPEATABLE READ。
PostgreSQL對DML(SELECT、UPDATE、INSERT、DELETE等命令)使用SSI,對DDL(CREATE TABLE等命令)使用2PL。
5.1 事務標識
每當事務開始時,事務管理器就會為其分配一個稱為事務標識(transaction id,txid)的唯一識別符號。PostgreSQL的txid是一個32位無符號整數,取值空間大小約為42億。在事務啟動後執行內建的txid_current()函式,即可獲取當前事務的txid,如下所示。
testdb=# BEGIN;BEGINtestdb=# SELECT txid_current();txid_current--------------100(1 row)
PostgreSQL保留以下三個特殊txid:
- 0表示無效的txid。
- 1表示初始啟動的txid,僅用於資料庫叢集的初始化過程。
- 2表示凍結的txid,詳情參考第5.10節。
txid可以相互比較大小。例如對於txid=100的事務,大於100的txid屬於“未來”,且對於txid=100的事務而言都是不可見的,小於100的txid屬於“過去”,且對該事務可見,如圖5.1(1)所示。
因為txid在邏輯上是無限的,而實際系統中的txid空間不足(4B整型的取值空間大小約42億),因此PostgreSQL將txid空間視為一個環。對於某個特定的txid,其前約21億個txid屬於過去,其後約21億個txid屬於未來,如圖5.1(2)所示。
txid回捲問題將在第5.10節中介紹。
註意,txid並非是在BEGIN命令執行時分配的。在PostgreSQL中,當執行BEGIN命令後的第一條命令時,事務管理器才會分配txid,並真正啟動其事務。
圖5.1 PostgreSQL中的事務標識
5.2 元組結構
我們可以將表頁中的堆元組分為普通資料元組與TOAST元組兩類。本節只介紹普通元組。
堆元組由三個部分組成,即HeapTupleHeaderData結構、空值點陣圖及使用者資料,如圖5.2所示。
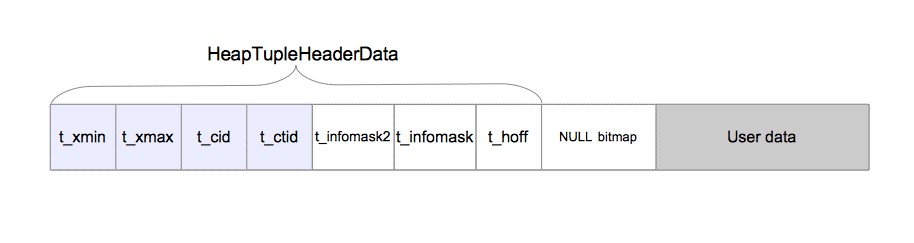
圖5.2 元組結構
HeapTupleHeaderData結構在src/include/access/htup_details.h中定義。
typedef struct HeapTupleFields{TransactionId t_xmin; /* 插入事務的ID */TransactionId t_xmax; /* 刪除或鎖定事務的ID */union{CommandId t_cid; /* 插入或刪除的命令ID */TransactionId t_xvac; /* 老式VACUUM FULL的事務ID */} t_field3;} HeapTupleFields;typedef struct DatumTupleFields{int32 datum_len_; /* 可變首部的長度*/int32 datum_typmod; /* -1或者是記錄型別的標識 */Oid datum_typeid; /* 複雜型別的oid或記錄ID */} DatumTupleFields;typedef struct HeapTupleHeaderData{union{HeapTupleFields t_heap;DatumTupleFields t_datum;} t_choice;ItemPointerData t_ctid; /* 當前元組或更新元組的TID *//* 下麵的欄位必須與結構MinimalTupleData相匹配 */uint16 t_infomask2; /* 屬性與標記位 */uint16 t_infomask; /* 很多標記位 */uint8 t_hoff; /* 首部+點陣圖+填充的長度 *//* ^ - 23 bytes - ^ */bits8 t_bits[1]; /* NULL值的點陣圖——變長的 *//* 本結構後面還有更多資料 */} HeapTupleHeaderData;typedef HeapTupleHeaderData *HeapTupleHeader;
雖然HeapTupleHeaderData結構包含7個欄位,但是後續部分中只需要瞭解4個欄位即可。
- t_xmin儲存插入此元組的事務的txid。
- t_xmax儲存刪除或更新此元組的事務的txid。如果尚未刪除或更新此元組,則t_xmax設定為0,即無效。
- t_cid儲存命令標識(command id,cid),cid的意思是在當前事務中,執行當前命令之前執行了多少SQL命令,從零開始計數。例如,假設我們在單個事務中執行了3條INSERT命令BEGIN;INSERT;INSERT;INSERT;COMMIT;。如果第一條命令插入此元組,則該元組的t_cid會被設定為0。如果第二條命令插入此元組,則其t_cid會被設定為1,以此類推。
- t_ctid儲存著指向自身或新元組的元組識別符號(tid)。如第1.3節中所述,tid用於標識表中的元組。在更新該元組時,t_ctid會指向新版本的元組,否則t_ctid會指向自己。
朋友會在“發現-看一看”看到你“在看”的內容