作者:ballwql
連結:https://www.cnblogs.com/ballwql/p/hbase_data_transfer.html
一、前言
HBase資料遷移是很常見的操作,目前業界主要的遷移方式主要分為以下幾類:
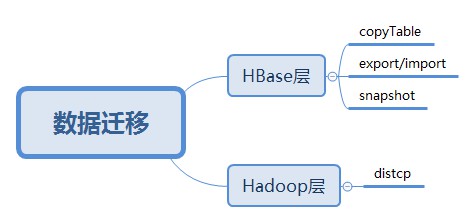
圖1.HBase資料遷移方案
從上面圖中可看出,目前的方案主要有四類,Hadoop層有一類,HBase層有三類。下麵分別介紹一下。
二、Hadoop層資料遷移
2.1 方案介紹
Hadoop層的資料遷移主要用到DistCp(Distributed Copy), 官方描述是:DistCp(分散式複製)是用於大規模叢集內部和叢集之間複製的工具。它使用Map/Reduce實現檔案分發,錯誤處理和恢復,以及報告生成。它把檔案和目錄的串列作為map任務的輸入,每個任務會完成源串列中部分檔案的複製。
我們知道MR程式適合用來處理大批次資料, 其複製本質過程是啟動一個MR作業,不過DisctCp只有map,沒有reducer。在複製時,由於要保證檔案塊的有序性,轉換的最小粒度是一個檔案,而不像其它MR作業一樣可以把檔案拆分成多個塊啟動多個map並行處理。如果同時要複製多個檔案,DisctCp會將檔案分配給多個map,每個檔案單獨一個map任務。我們可以在執行同步時指定-m引數來設定要跑的map數量,預設設定是20。如果是叢集間的資料同步,還需要考慮頻寬問題,所以在跑任務時還需要設定 bandwitdh 引數,以防止一次同步過多的檔案造成頻寬過高影響其它業務。同時,由於我們HBase叢集一般是不會開MR排程的,所以這裡還需要用到單獨的MR叢集來作主備資料同步,即在跑任務時還需要指定mapreduce相關引數。
簡單的distcp引數形式如下:
hadoop distcp hdfs://src-hadoop-address:9000/table_name hdfs://dst-hadoop-address:9000/table_name
如果是獨立的MR叢集來執行distcp,因為資料量很大,一般是按region目錄粒度來傳輸,同時傳輸到標的叢集時,我們先把檔案傳到臨時目錄,最後再目的叢集上load表,我們用到的形式如下:
hadoop distcp \
-Dmapreduce.job.name=distcphbase \
-Dyarn.resourcemanager.webapp.address=mr-master-ip:8088 \
-Dyarn.resourcemanager.resource-tracker.address=mr-master-dns:8093 \
-Dyarn.resourcemanager.scheduler.address=mr-master-dns:8091 \
-Dyarn.resourcemanager.address=mr-master-dns:8090 \
-Dmapreduce.jobhistory.done-dir=/history/done/ \
-Dmapreduce.jobhistory.intermediate-done-dir=/history/log/ \
-Dfs.defaultFS=hdfs://hbase-fs/ \
-Dfs.default.name=hdfs://hbase-fs/ \
-bandwidth 20 \
-m 20 \
hdfs://src-hadoop-address:9000/region-hdfs-path \
hdfs://dst-hadoop-address:9000/tmp/region-hdfs-path在這個過程中,需要註意源端叢集到目的端叢集策略是通的,同時hadoop/hbase版本也要註意是否一致,如果版本不一致,最終load表時會報錯。
2.2 方案實施
遷移方法如下:
第一步,如果是遷移實時寫的表,最好是停止叢集對錶的寫入,遷移歷史表的話就不用了,此處舉例表名為test;
第二步, flush表, 開啟HBase Shell客戶端,執行如下命令:
hbase> flush 'test'
第三步,複製表檔案到目的路徑,檢查源叢集到標的叢集策略、版本等,確認沒問題後,執行如上帶MR引數的命令
第四步, 檢查標的叢集表是否存在,如果不存在需要建立與原叢集相同的表結構
第五步,在標的叢集上,Load表到線上,在官方Load是執行如下命令:
hbase org.jruby.Main add_table.rb /hbase/data/default/test對於我們來說,因我們先把檔案同步到了臨時目錄,並不在原表目錄,所以我們採用的另一種形式的load,即以region的維度來Load資料到線上表,怎麼做呢,這裡用到的是org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles這個類,即以bulkload的形式來load資料。上面同步時我們將檔案同步到了目的叢集的/tmp/region-hdfs-path目錄,那麼我們在Load時,可以用如下命令來Load region檔案:
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles -Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily=1024 hdfs://dst-hadoop-address:9000/tmp/region-hdfs-path/region-name table_name
這裡還用到一個引數hbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily, 這個表示在bulkload過程中,每個region列族的HFile數的上限,這裡我們是限定了1024,也可以指定更少,根據實際需求來定。
第六步,檢查表資料是否OK,看bulkload過程是否有報錯
在同步過程中,我們為加塊同步速度,還會開個多執行緒來併發同步檔案,這個可根據實際資料量和檔案數來決定是否需要使用併發同步。
三、HBase層資料遷移
3.1 copyTable方式
copyTable也是屬於HBase資料遷移的工具之一,以表級別進行資料遷移。copyTable的本質也是利用MapReduce進行同步的,與DistCp不同的時,它是利用MR去scan 原表的資料,然後把scan出來的資料寫入到標的叢集的表。這種方式也有很多侷限,如一個表資料量達到T級,同時又在讀寫的情況下,全量scan表無疑會對叢集效能造成影響。
來看下copyTable的一些使用引數:
Usage: CopyTable [general options] [--starttime=X] [--endtime=Y] [--new.name=NEW] [--peer.adr=ADR]
Options:
rs.class hbase.regionserver.class of the peer cluster
specify if different from current cluster
rs.impl hbase.regionserver.impl of the peer cluster
startrow the start row
stoprow the stop row
starttime beginning of the time range (unixtime in millis)
without endtime means from starttime to forever
endtime end of the time range. Ignored if no starttime specified.
versions number of cell versions to copy
new.name new table's name
peer.adr Address of the peer cluster given in the format
hbase.zookeeer.quorum:hbase.zookeeper.client.port:zookeeper.znode.parent
families comma-separated list of families to copy
To copy from cf1 to cf2, give sourceCfName:destCfName.
To keep the same name, just give "cfName"
all.cells also copy delete markers and deleted cells
Args:
tablename Name of the table to copy
Examples:
To copy 'TestTable' to a cluster that uses replication for a 1 hour window:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1265875194289 --endtime=1265878794289 --peer.adr=server1,server2,server3:2181:/hbase --families=myOldCf:myNewCf,cf2,cf3 TestTable
For performance consider the following general options:
-Dhbase.client.scanner.caching=100
-Dmapred.map.tasks.speculative.execution=false從上面引數,可以看出,copyTable支援設定需要複製的表的時間範圍,cell的版本,也可以指定列簇,設定從叢集的地址,起始/結束行鍵等。引數還是很靈活的。
copyTable支援如下幾個場景:
1、表深度複製:相當於一個快照,不過這個快照是包含原表實際資料的,0.94.x版本之前是不支援snapshot快照命令的,所以用copyTable相當於可以實現對原表的複製, 使用方式如下:
create 'table_snapshot',{NAME=>"i"}
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=tableCopy table_snapshot2、叢集間複製:在叢集之間以表維度同步一個表資料,使用方式如下:
create 'table_test',{NAME=>"i"} #目的叢集上先建立一個與原表結構相同的表
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --peer.adr=zk-addr1,zk-addr2,zk-addr3:2181:/hbase table_test
3、增量備份:增量備份表資料,引數中支援timeRange,指定要備份的時間範圍,使用方式如下:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable ... --starttime=start_timestamp --endtime=end_timestamp
4、部分表備份:只備份其中某幾個列族資料,比如一個表有很多列族,但我只想備份其中幾個列族資料,CopyTable提供了families引數,同時還提供了copy列族到新列族形式,使用方式如下:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable ... --families=srcCf1,srcCf2 #copy cf1,cf2兩個列族,不改變列族名字
hbase org.apache.hadoop.hbase.mapreduce.CopyTable ... --families=srcCf1:dstCf1, srcCf2:dstCf2 #copy srcCf1到標的dstCf1新列族
總的來說,CopyTable支援的範圍還是很多的,但因其涉及的是直接HBase層資料的複製,所以效率上會很低,同樣需要在使用過程中限定掃描原表的速度和傳輸的頻寬,這個工具實際上使用比較少,因為很難控制。
3.2 Export/Import方式
此方式與CopyTable類似,主要是將HBase表資料轉換成Sequence File並dump到HDFS,也涉及Scan表資料,與CopyTable相比,還多支援不同版本資料的複製,同時它複製時不是將HBase資料直接Put到標的叢集表,而是先轉換成檔案,把檔案同步到標的叢集後再透過Import到線上表。主要有兩個階段:
Export階段: 將原叢集表資料Scan並轉換成Sequence File到Hdfs上,因Export也是依賴於MR的,如果用到獨立的MR叢集的話,只要保證在MR叢集上關於HBase的配置和原叢集一樣且能和原叢集策略打通(master®ionserver;策略),就可直接用Export命令,如果沒有獨立MR叢集,則只能在HBase叢集上開MR,若需要同步多個版本資料,可以指定versions引數,否則預設同步最新版本的資料,還可以指定資料起始結束時間,使用如下:
# output_hdfs_path可以直接是標的叢集的hdfs路徑,也可以是原叢集的HDFS路徑,如果需要指定版本號,起始結束時間
hbase org.apache.hadoop.hbase.mapreduce.Export <tableName> <ouput_hdfs_path> <versions> <starttime> <endtime> Import階段: 將原叢集Export出的SequenceFile導到標的叢集對應表,使用如下:
#如果原資料是存在原叢集HDFS,此處input_hdfs_path可以是原叢集的HDFS路徑,如果原資料存在標的叢集HDFS,則為標的叢集的HDFS路徑
hbase org.apache.hadoop.hbase.mapreduce.Import <tableName> <input_hdfs_path>3.3 Snapshot方式
3.3.1 snapshot介紹
此方式與上面幾中方式有所區別,也是目前用得比較多的方案,snapshot字面意思即快照, 傳統關係型資料庫也有快照的概念,HBase中關於快照的概念定義如下:
快照就是一份元資訊的合集,允許管理員恢復到表的先前狀態,快照不是表的複製而是一個檔案名稱串列,因而不會複製資料
因不複製實際的資料,所以整個過程是比較快的,相當於對錶當前元資料狀態作一個克隆,snapshot的流程主要有三個步驟:
加鎖: 加鎖物件是regionserver的memstore,目的是禁止在建立snapshot過程中對資料進行insert,update,delete操作
刷盤:刷盤是針對當前還在memstore中的資料刷到HDFS上,保證快照資料相對完整,此步也不是強制的,如果不刷會,快照中資料有不一致風險
建立指標: snapshot過程不複製資料,但會建立對HDFS檔案的指標,snapshot中儲存的就是這些指標元資料
3.3.2 snapshot內部原理
snapshot實際內部是怎麼做的呢,上面說到,snapshot只是對元資料資訊克隆,不複製實際資料檔案,我們以表test為例,這個表有三個region, 每個region分別有兩個HFile,建立snapshot過程如下:

建立的snapshot放在目錄/hbase/.hbase-snapshot/下, 元資料資訊放在/hbase/.hbase-snapshot/data.manifest中, 如上圖所示,snapshot中也分別包含對原表region HFile的取用,元資料資訊具體包括哪哪些呢:
1. snapshot元資料資訊
2. 表的元資料資訊&schema;,即原表的.tableinfo檔案
3. 對原表Hfile的取用資訊由於我們表的資料在實時變化,涉及region的Hfile合併刪除等操作,對於snapshot而言,這部分資料HBase會怎麼處理呢,實際上,當發現spit/compact等操作時,HBase會將原表發生變化的HFile複製到/hbase/.archive目錄,如上圖中如果Region3的F31&F32;發生變化,則F31和F32會被同步到.archive目錄,這樣發生修改的檔案資料不至於失效,如下圖所示:
圖4.snapshot檔案遷移
快照中還有一個命令就是clone_snapshot, 這個命令也很用,我們可以用它來重新命名錶,恢復表資料等。具體用法如下:
hbase> clone_snapshot 'snapshot_src_table' , 'new_table_name'這個命令也是不涉及實際資料檔案的複製,所以執行起來很快,那複製的是什麼呢,與上面提到的取用檔案不同,它所生成的是linkfile,這個檔案不包含任何內容,和上面取用檔案一樣的是,在發生compact等操作時,會將原檔案copy到/hbase/.archive目錄。
比如我們有一個表test, 有一個region原表資訊如下:
hbaseuser:~> hadoop fs -ls /hbase/data/default/test/d8340c61f5d77345b7fa55e0dfa9b492/*
Found 1 items
-rw-r--r-- 1 hbaseuser supergroup 37 2017-12-01 11:44 /hbase/data/default/test/d8340c61f5d77345b7fa55e0dfa9b492/.regioninfo
Found 1 items
-rw-r--r-- 1 hbaseuser supergroup 983 2017-12-01 12:13 /hbase/data/default/test/d8340c61f5d77345b7fa55e0dfa9b492/i/55c5de40f58f4d07aed767c5d250191在建立一個snapshot之後:snapshot ‘test’, ‘snapshot_test’,在/hbase/.hbase-snapshot目錄資訊如下:
hbaseuser~> hadoop fs -ls /hbase/.hbase-snapshot/snapshot_test
Found 4 items
-rw-r--r-- 1 hbaseuser supergroup 32 2017-12-01 12:13 /hbase/.hbase-snapshot/snapshot_test/.snapshotinfo
drwxr-xr-x - hbaseuser supergroup 0 2017-12-01 12:13 /hbase/.hbase-snapshot/snapshot_test/.tabledesc
drwxr-xr-x - hbaseuser supergroup 0 2017-12-01 12:13 /hbase/.hbase-snapshot/snapshot_test/.tmp
drwxr-xr-x - hbaseuser supergroup 0 2017-12-01 12:13 /hbase/.hbase-snapshot/snapshot_test/d8340c61f5d77345b7fa55e0dfa9b492在clone_snapshot之後:clone_snapshot ‘snapshot_test’,’new_test’,在/hbase/archive/data/default目錄,有對原表的link目錄,目錄名只是在原HFile的檔案名基礎上加了個links-字首,這樣我們可以透過這個來定位到原表的HFile,如下所示:
hbaseuser:~> hadoop fs -ls /hbase/archive/data/default/test/d8340c61f5d77345b7fa55e0dfa9b492/i
Found 1 items
drwxr-xr-x - hbaseuser supergroup 0 2017-12-01 12:34 /hbase/archive/data/default/test/d8340c61f5d77345b7fa55e0dfa9b492/i/.links-55c5de40f58f4d07此時,再執行合併操作:major_compact ‘new_test’,會發現/hbase/archive/data/default/目錄已經變成了實際表的資料檔案,上面圖中/hbase/archive/data/default/test/d8340c61f5d77345b7fa55e0dfa9b492/i/.links-55c5de40f58f4d07這個已經不在了,取而代之的是如下所示檔案:
hbaseuser:~> hadoop fs -ls /hbase/archive/data/default/new_test/7e8636a768cd0c6141a3bb45b4098910/i
Found 1 items
-rw-r--r-- 1 hbaseuser supergroup 0 2017-12-01 12:48 /hbase/archive/data/default/new_test/7e8636a768cd0c6141a3bb45b4098910/i/test=d8340c61f5d77345b7fa55e0dfa9b492-55c5de40f58f4d07aed767c5d250191c在實際的/hbase/data/default/new_test目錄也是實際的原表的資料檔案,這樣完成了表資料的遷移。
3.3.3 snapshot資料遷移
snapshot的應用場景和上面CopyTable描述差不多,我們這裡主要考慮的是資料遷移部分。資料遷移主要有以下幾個步驟:
A.建立快照:在原叢集上,用snapshot命令建立快照,命令如下:
hbase> snapshot 'src_table', 'snapshot_src_table'
#檢視建立的快照,可用list_snapshots命令
hbase> list_snapshots
#如果快照建立有問題,可以先刪除,用delete_snapshot命令
hbase >delete_snapshot 'snapshot_src_table'建立完快照後在/hbase根目錄會產生一個目錄:
/hbase/.hbase-snapshot/snapshot_src_table
#子目錄下有如下幾個檔案
/hbase/.hbase-snapshot/snapshot_src_table/.snapshotinfo
/hbase/.hbase-snapshot/snapshot_src_table/data.manifestB.資料遷移: 在上面建立好快照後,使用ExportSnapshot命令進行資料遷移,ExportSnapshot也是HDFS層的操作,本質還是利用MR進行遷移,這個過程主要涉及IO操作並消耗網路頻寬,在遷移時要指定下map數和頻寬,不然容易造成機房其它業務問題,如果是單獨的MR叢集,可以在MR叢集上使用如下命令:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot snapshot_src_table \
-copy-from hdfs://src-hbase-root-dir/hbase \
-copy-to hdfs://dst-hbase-root-dir/hbase \
-mappers 20 \
-bandwidth 20
上面這些流程網上很多資料都有提到,對於我們業務來說,還有一種場景是要同步的表是正在實時寫的,雖然用上面的也可以解決,但考慮到我們表資料規模很大,幾十個T級別,同時又有實時業務在查的情況下,直接在原表上就算只是複製HFile,也會影響原叢集機器效能,由於我們機器效能IO/記憶體方面本身就比較差,很容易導致機器異常,所以我們採用的其它一種方案,流程圖如下:

圖5.新的snapshot遷移方案
為什麼要採用這種方案呢,主要考慮的是直接對原表snapshot進行Export會影響叢集效能,所以採用折中的方案,即先把老表clone成一個新表,再對新表進行遷移,這樣可以避免直接對原表操作。
四、總結
上文把HBase資料遷移過程中常用的一些方法作了一個大概介紹,總結起來就四點:
DistCp: 檔案層的資料同步,也是我們常用的
CopyTable: 這個涉及對原表資料Scan,然後直接Put到標的表,效率較低
Export/Import: 類似CopyTable, Scan出資料放到檔案,再把檔案傳輸到標的叢集作Import
Snapshot: 比較常用 , 應用靈活,採用快照技術,效率比較高
具體應用時,要結合自身表的特性,考慮資料規模、資料讀寫方式、實時資料&離線資料等方面,再選擇使用哪種。
參考:
1 http://dongxicheng.org/hadoop-hdfs/hadoop-hdfs-distcp-fastcopy/
2 http://www.cnblogs.com/foxmailed/p/3914117.html
3 http://hbasefly.com/2017/09/17/hbase-snapshot/
朋友會在“發現-看一看”看到你“在看”的內容