
導讀:動漫《工作細胞》在b站上評分高達9.7。除了口碑之外,熱度也居高不下,更值得關註的是連很多平時不關註動漫的小夥伴也加入了追番大軍。這次我們的標的是爬取b站上的所有短評進行分析,用資料說明為什麼這部動漫會如此受歡迎。
作者:量化小白H
來源:量化小白上分記(ID:quanthzp)
01 工作細胞
《工作細胞》改編自清水茜老師的同名漫畫,由David Production製作。眾所周知,日本ACG作品向來信奉著“萬物皆可萌”的原則。前有《黑塔利亞》,後有《艦隊Collection》和《獸娘動物園》,分別講述了將國家,戰艦和動物擬人化後的故事。而在《工作細胞》裡擬人的物件則輪到了我們的細胞。

這是一個發生在人體內的故事:
人的細胞數量,約為37兆2千億個。
其中包括了我們的女主角:一個副業是運輸氧氣,主業是迷路的紅血球。

男主角:一個作者懶得塗色但武力值max的白血球。兩人一見面就並肩戰鬥,分別的時候更是滿天粉紅氣泡。

雖然嘴上說著:不會,我只是千千萬萬個白細胞中的一員。身體卻很誠實,從第一集偶遇女主到最後一集,每一集都充滿了狗糧的味道。37兆分之一的緣分果然妙不可言。
除了男女主角,配角們的人氣也都很高。連反派boss癌細胞都有人喜歡,主要還是因為身世感人+臉長得好。當然人氣最!最!最!高的還是我們奶聲奶氣的血小板。

據宅男們反映:“看了這麼多番。只有這一部的老婆是大家真正擁有的。”不僅有,還有很多。
除了新穎的科普形式,這部番令人感觸最深的是:我們每一個人都不是孤獨的個體,有37兆個只屬於我們的細胞和我們一同工作不息。每當頹唐和失意的時候,為了那些為了保護你而戰鬥不止的免疫細胞,為了萌萌的老婆們也要振作起來啊。
《工作細胞》的成功並不是一個偶然,而是眾多因素共同作用的結果。下麵從資料的角度分析它成為今年7月播放冠軍的原因。
02 爬蟲
首先要做的是爬取b站的所有短評,包括評論使用者名稱、評論時間、星級(評分)、評論內容、點贊數等內容,本部分內容為爬蟲程式碼的說明,不感興趣的讀者可以直接跳過,閱讀下一部分的分析。

爬的過程寫了很久,b站短評不需要登陸直接就可以爬,剛開始用類似之前爬豆瓣的方法,用Selenium+xpath定位爬:

但b站短評用這種方法並不好處理。網站每次最多顯示20條短評,捲軸移動到最下麵才會載入之後的20條,所以剛開始用了每次爬完之後將定位到當前爬的位置的方法,這樣定位到當前載入的最後一條時,就會載入之後的20條短評。
邏輯上是解決了這個問題,但真的爬的時候就出現了問題,一個是爬的慢,20條需要十來秒的樣子,這個沒關係,大不了爬幾個小時,但問題是辛辛苦苦爬了兩千多條之後,就自動斷了,不知道是什麼原因。
雖然之前爬的資料都存下來了,但沒法接著斷開的地方接著爬,又要重新開始,還不知道會不會又突然斷,所以用這種方法基本就無解了。
程式碼附在下麵,雖然是失敗的,但也可以爬一些評論下來,供參考。
1# -*- coding: utf-8 -*-
2"""
3Created on Mon Sep 10 19:36:24 2018
4"""
5from selenium import webdriver
6import pandas as pd
7from datetime import datetime
8import numpy as np
9import time
10import os
11
12os.chdir('F:\python_study\pachong\工作細胞')
13def gethtml(url):
14
15 browser = webdriver.PhantomJS()
16 browser.get(url)
17 browser.implicitly_wait(10)
18 return(browser)
19
20def getComment(url):
21
22 browser = gethtml(url)
23 i = 1
24 AllArticle = pd.DataFrame(columns = ['id','author','comment','stars1','stars2','stars3','stars4','stars5','unlike','like'])
25 print('連線成功,開始爬取資料')
26 while True:
27
28 xpath1 = '//*[@id="app"]/div[2]/div[2]/div/div[1]/div/div/div[4]/div/div/ul/li[{}]'.format(i)
29 try:
30 target = browser.find_element_by_xpath(xpath1)
31 except:
32 print('全部爬完')
33 break
34
35 author = target.find_element_by_xpath('div[1]/div[2]').text
36 comment = target.find_element_by_xpath('div[2]/div').text
37 stars1 = target.find_element_by_xpath('div[1]/div[3]/span/i[1]').get_attribute('class')
38 stars2 = target.find_element_by_xpath('div[1]/div[3]/span/i[2]').get_attribute('class')
39 stars3 = target.find_element_by_xpath('div[1]/div[3]/span/i[3]').get_attribute('class')
40 stars4 = target.find_element_by_xpath('div[1]/div[3]/span/i[4]').get_attribute('class')
41 stars5 = target.find_element_by_xpath('div[1]/div[3]/span/i[5]').get_attribute('class')
42 date = target.find_element_by_xpath('div[1]/div[4]').text
43 like = target.find_element_by_xpath('div[3]/div[1]').text
44 unlike = target.find_element_by_xpath('div[3]/div[2]').text
45
46
47 comments = pd.DataFrame([i,author,comment,stars1,stars2,stars3,stars4,stars5,like,unlike]).T
48 comments.columns = ['id','author','comment','stars1','stars2','stars3','stars4','stars5','unlike','like']
49 AllArticle = pd.concat([AllArticle,comments],axis = 0)
50 browser.execute_script("arguments[0].scrollIntoView();", target)
51 i = i + 1
52 if i%100 == 0:
53 print('已爬取{}條'.format(i))
54 AllArticle = AllArticle.reset_index(drop = True)
55 return AllArticle
56
57url = 'https://www.bilibili.com/bangumi/media/md102392/?from=search&seid;=8935536260089373525#short'
58result = getComment(url)
59#result.to_csv('工作細胞爬蟲.csv',index = False)這種方法爬取失敗之後,一直不知道該怎麼處理,剛好最近看到網上有大神爬貓眼評論的文章,照葫蘆畫瓢嘗試了一下,居然成功了,而且爬的速度也很快,十來分鐘就全爬完了,思路是找到評論對應的Json檔案,然後獲取Json中的資料,過程如下。
在Google瀏覽器中按F12開啟卡發者工具後,選擇Network:

往下滑動,會發現過一段時間,會出現一個fetch,右鍵開啟後發現,裡面就是20條記錄,有所有我們需要的內容,json格式。

所以現在需要做的就是去找這些json檔案的路徑的規律。多看幾條之後,就發現了規律:
第一個json:
https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded;=0&page;_size=20&sort;=0
第二個json:
https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded;=0&page;_size=20&sort;=0&cursor;=76553500953424
第三個json:
https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded;=0&page;_size=20&sort;=0&cursor;=76549205971454
顯然所有的json路徑的前半部分都是一樣,都是在第一條json之後加上不同的cursor = xxxxx,所以只要能找到cursor值的規律,就可以用迴圈的辦法,爬完所有的json,這個值看上去沒什麼規律,最後發現,每一個json路徑中cursor值就藏在前一個json的最後一條評論中。

在python中可以直接把json轉成字典,cursor值就是最後一條評論中鍵cursor的值,簡直不要太容易。
所以爬的思路就很清晰了,從一個json開始,爬完20條評論後,獲取最後一個評論中的cursor值,更改路徑之後獲取第二個json,重覆上面的過程,直到爬完所有的json。
至於如何知道爬完了所有json,也很容易,每個json中一個total鍵,表示了當前一共有多少條評論,所以只需要寫一個while迴圈,當爬到的評論數達到total值時停止。
爬的過程中還發現,有些json中的評論數不夠20條,如果每次用20去定位,中間會報錯停止,需要註意一下。所以又加了一行程式碼,每次獲得json後,透過len()函式得到當前json中一共包含多少條評論,cursor在最後一個評論中。
以上是整個爬的思路,我們最終爬到以下資訊:
1
作者
author
2
評分/星級
score
3
不喜歡
disliked
4
點贊
likes
5
這個全0,沒用
liked
6
時間
ctime
7
評論
content
8
cursor
cursor
9
狀態
last_ep_index
需要說明的地方,一個是liked按照字面意思應該是使用者的點贊數,但爬完才發現全是0,沒有用。另一個是關於時間,裡面有ctime和mtime兩個跟時間有關的值,看了幾個,基本都是一樣的,有個別不太一樣,差的不多,就只取了ctime。
我猜可能一個是點選進去的時間,一個是評論提交時間,但沒法驗證,就隨便取一個算了。
ctime的編碼很奇怪,比如某一個是ctime = 1540001677,渣渣之前沒有見過這種編碼方式,請教了大佬之後知道,這個是Linux系統上的時間表示方式,是1970年1月1日0時0分0秒到當時時點的秒數,python中可以直接用time.gmtime()函式轉化成年月日小時分鐘秒的格式。
還有last_ep_index裡面存的是使用者當前的看劇狀態,比如看至第13話,第6話之類的,但後來發現很不準,絕大多數使用者沒有last_ep_index值,所以也沒有分析這個變數。
程式碼如下:
1import requests
2from fake_useragent import UserAgent
3import json
4import pandas as pd
5import time
6import datetime
7essay-headers = { "User-Agent": UserAgent(verify_ssl=False).random}
8comment_api = 'https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded;=0&page;_size=20&sort;=0'
9
10# 傳送get請求
11response_comment = requests.get(comment_api,essay-headers = essay-headers)
12json_comment = response_comment.text
13json_comment = json.loads(json_comment)
14
15total = json_comment['result']['total']
16
17cols = ['author','score','disliked','likes','liked','ctime','score','content','last_ep_index','cursor']
18dataall = pd.DataFrame(index = range(total),columns = cols)
19
20
21j = 0
22while j
24 for i in range(n):
25 dataall.loc[j,'author'] = json_comment['result']['list'][i]['author']['uname']
26 dataall.loc[j,'score'] = json_comment['result']['list'][i]['user_rating']['score']
27 dataall.loc[j,'disliked'] = json_comment['result']['list'][i]['disliked']
28 dataall.loc[j,'likes'] = json_comment['result']['list'][i]['likes']
29 dataall.loc[j,'liked'] = json_comment['result']['list'][i]['liked']
30 dataall.loc[j,'ctime'] = json_comment['result']['list'][i]['ctime']
31 dataall.loc[j,'content'] = json_comment['result']['list'][i]['content']
32 dataall.loc[j,'cursor'] = json_comment['result']['list'][n-1]['cursor']
33 j+= 1
34 try:
35 dataall.loc[j,'last_ep_index'] = json_comment['result']['list'][i]['user_season']['last_ep_index']
36 except:
37 pass
38
39 comment_api1 = comment_api + '&cursor;=' + dataall.loc[j-1,'cursor']
40 response_comment = requests.get(comment_api1,essay-headers = essay-headers)
41 json_comment = response_comment.text
42 json_comment = json.loads(json_comment)
43
44 if j % 50 ==0:
45 print('已完成 {}% !'.format(round(j/total*100,2)))
46 time.sleep(0.5)
47
48
49
50dataall = dataall.fillna(0)
51
52def getDate(x):
53 x = time.gmtime(x)
54 return(pd.Timestamp(datetime.datetime(x[0],x[1],x[2],x[3],x[4],x[5])))
55
56dataall['date'] = dataall.ctime.apply(lambda x:getDate(x))
57
58dataall.to_csv('bilibilib_gongzuoxibao.xlsx',index = False)03 影評分析
最終一共爬到了17398條影評資料。裡面的date是用ctime轉過來的,接下來對資料進行一些分析,資料分析透過python3.6完成,程式碼後臺回覆工作細胞可得。

1. 評分分佈
評分取值範圍為2、4、6、8、10分,對應1-5顆星
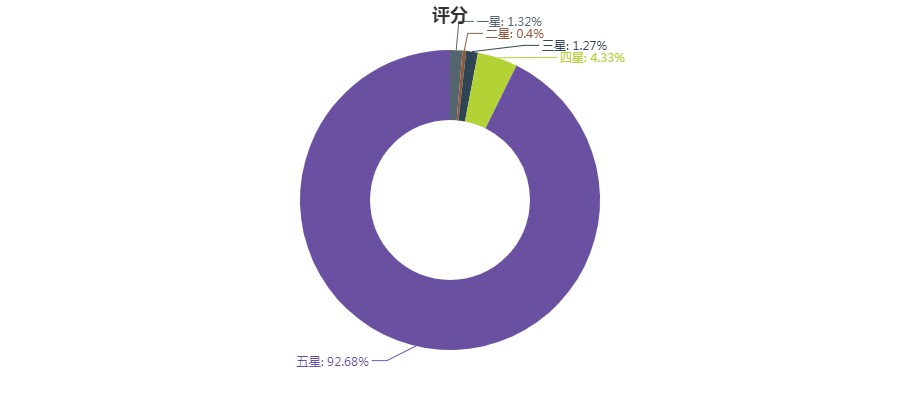
可以看出,幾乎所有的使用者都給了這部動漫五星好評,影響力可見一斑。
2. 評分時間分佈
將這部動漫從上線至今所有的評分按日進行平均,觀察評分隨時間的變化情況:
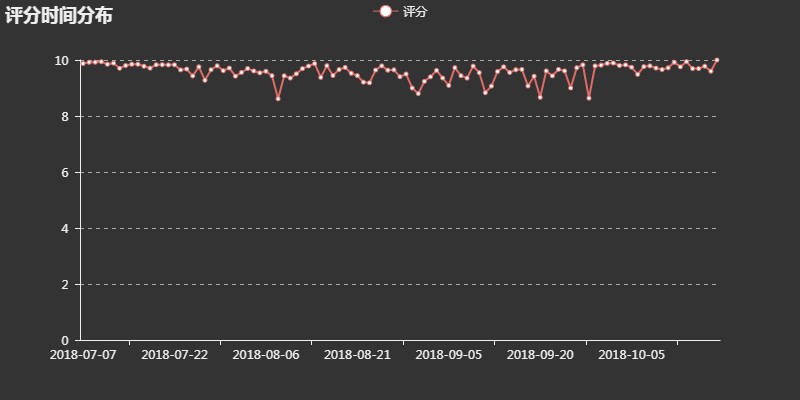
可以看出,評分一直居高不下,尤其起始和結束時都接近滿分,足見這是一部良好開端、圓滿結束的良心作品。
3. 每日評論數
看完評分之後,再看看評論相關的資料,我最感興趣的是,這些評論的時間分佈是怎麼樣的,統計了每一日的評論數之後,得到了評論數的分佈圖:

基本上是每出了新的一話,大家看完後就會在短評中分享自己的感受,當然同樣是起始和結束階段的評論數最多,對比同期的百度指數:

4. 評論日內分佈
除了每日的評論數,也想分析一下評論的日內趨勢,使用者都喜歡在每日的什麼時間進行評論?將評論分24個小時求和彙總後,得到了下圖:

不過這個結果就不是很理想了,橫軸是時間,縱軸是評論數,中午到下午的趨勢上升可以理解,晚上七八點沒有人評論反倒是凌晨三四點評論數最多,這個就很反常了,可能是評論在系統中上線的時間有一定偏差?
5. 好評字數
此外還想分析一下,是否點贊數多的,一定是寫的字數越多的?因為文章中大部分的評論是沒有點贊的,所以這裡中統計了有點贊(likes>0)的評論點贊數和評論字數的資料。由於有一條評論字點贊數太多,嚴重偏離整體趨勢,所以做了對數圖進行觀察。
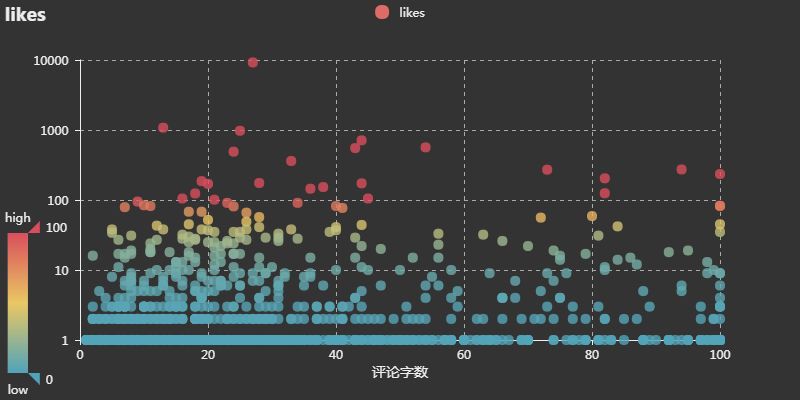
整體來看,似乎沒什麼關係,大量字數1-100不等的,點贊數都為1,點贊數大於5的部分有一定的正相關性,說明評論不僅要看數量,還要看質量,寫出了大家的心聲,大家才會使勁點贊。
6. 評論分析TF-IDF
分析完基礎資料後,想更深入挖掘一下評論資訊,大家都說了些什麼?為什麼這部劇這麼受歡迎?也許都能在評論中找到答案。
jieba分詞、去除停止詞、計算詞頻和TF-IDF的過程不表,與之前兩篇文章類似。我們提取了重要性前500的詞,這裡展示部分

血小板高居首位,畢竟大家對萌萌噠事物都是沒什麼抵抗力的。
詞語中也存在一些意義不大的詞,前期處理不太到位。不過從這些詞雲中還是可以看出很多東西,為什麼這部劇如此受歡迎?這裡透過分詞可以得到以下三個解釋:
(1) 題材好:科普類動漫,老少皆宜
評論中提到了科普、生物、題材等詞,還有各種細胞。區別於一般科普向動漫受眾低幼的問題,這部番的受眾年齡比較廣泛。因為所涉及到的知識並不算過於常識。
動漫中,每一話,身體的主人都會生一場病,每次出現新的細胞和病毒出現時,都會對他們的身份有比較詳細和準確的介紹:

這種形式寓教於樂,同時戰鬥的過程也充分地體現了每種細胞的特性。例如,前期因為戰鬥力弱而被別的細胞瞧不起的嗜酸性粒細胞,在遇到寄生蟲的時候大放異彩。可以說,每一種細胞爆種都爆得都有理有據。
(2) 人設好
這部番把幾乎人體所有的細胞擬人化:紅細胞、白細胞、血小板、巨噬細胞等。每一種細胞都有比較獨特的設定,從御姐到蘿莉,從高冷到話癆。十幾個出場的主要人物都各自有立得住的萌點。滿足各種口味的需求。

(3) 製作精良
這一點是毋庸置疑的,好的人設好的題材,如果沒有好的製作,都是白談,評論中也有很多人提到了“聲優”、“配音”等。
當然一部劇能夠火,不僅僅是這麼簡單的原因,這裡所說的,只是從資料可以看出的,觀眾的直觀感受。
最後我們以萌萌噠血小板詞雲作為文章的結尾。

註:原始碼在公眾號後臺對話方塊回覆工作細胞可得,喜歡請點贊![]()
關於作者:量化小白一枚,上財研究生在讀,偏向資料分析與量化投資,個人公眾號 量化小白上分記。PS:謝謝宇哥對部分內容的貢獻。

據統計,99%的大咖都完成了這個神操作
▼
福利時間

2018 AI開發者大會2天通票抽獎贈送中
(中獎後請在小程式中留下姓名+手機號+郵箱)
價值5499元
時間:11月8日-9日
地點:北京
會議詳情請戳這裡
更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 你最近在追什麼動漫?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視
