
過去幾年發表於各大 AI 頂會論文提出的 400 多種演演算法中,公開演演算法程式碼的僅佔 6%,其中三分之一的論文作者分享了測試資料,約 54% 的分享包含“偽程式碼”。這是今年 AAAI 會議上一個嚴峻的報告。 人工智慧這個蓬勃發展的領域正面臨著實驗重現的危機,就像實驗重現問題過去十年來一直困擾著心理學、醫學以及其他領域一樣。最根本的問題是研究人員通常不共享他們的原始碼。
可驗證的知識是科學的基礎,它事關理解。隨著人工智慧領域的發展,打破不可復現性將是必要的。為此,PaperWeekly 聯手百度 PaddlePaddle 共同發起了本次論文有獎復現,我們希望和來自學界、工業界的研究者一起接力,為 AI 行業帶來良性迴圈。
作者丨文永明
學校丨中山大學
研究方向丨計算機視覺,樣式識別
最近筆者復現了 Wasserstein GAN,簡稱 WGAN。Wasserstein GAN 這篇論文來自 Martin Arjovsky 等人,發表於 2017 年 1 月。


論文作者用了兩篇論文來闡述 Goodfellow 提出的原始 GAN 所存在的問題,第一篇是 WGAN 前作 Towards Principled Methods for Training Generative Adversarial Networks,從根本上分析 GAN 存在的問題。隨後,作者又在 Wasserstein GAN 中引入了 Wasserstein 距離,提出改進的方向,並且給出了改進的演演算法實現流程。
原始GAN存在的問題
原始的 GAN 很難訓練,訓練過程通常是啟髮式的,需要精心設計的網路架構,不具有通用性,並且生成器和判別器的 loss 無法指示訓練行程,還存在生成樣本缺乏多樣性等問題。
在 WGAN 前作中,論文作者分析出原始 GAN 兩種形式各自存在的問題,其中一種形式等價於在最優判別器下,最小化生成分佈與真實分佈之間的 JS 散度。但是對於兩個分佈:真實分佈 Pr 和生成分佈 Pg,如果它們不重合,或者重合的部分可以忽略,則它們的 JS 距離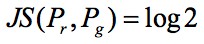 是常數,梯度下降時,會產生的梯度消失。
是常數,梯度下降時,會產生的梯度消失。
而在 GAN 的訓練中,兩個分佈不重合,或者重合可忽略的情況幾乎總是出現,交叉熵(JS 散度)不適合衡量具有不相交部分的分佈之間的距離,因此導致 GAN 的訓練困難。
另一種形式等價於在最優判別器下,既要最小化生成分佈與真實分佈之間的 KL 散度,又要最大化其 JS 散度,最佳化標的不合理,導致出現梯度不穩定現象,而且 KL 散度的不對稱性也使得出現了 collapse mode 現象,也就是生成器寧可喪失多樣性也不願喪失準確性,生成樣本因此缺失多樣性。
在 WGAN 前作中,論文作者提出過渡解決方案,透過對真實分佈和生成分佈增加噪聲使得兩個分佈存在不可忽略的重疊,從理論上解決訓練不穩定的問題,但是沒有改變本質,治標不治本。
Wasserstein距離
在 WGAN 中論文作者引入了 Wasserstein 距離來替代 JS 散度和 KL 散度,並將其作為最佳化標的。基於 Wasserstein 距離相對於 KL 散度與 JS 散度具有優越的平滑特性,從根本上解決了原始 GAN 的梯度消失問題。
Wasserstein 距離又叫 Earth-Mover(EM)距離,論文中定義如下:

其中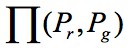 是指 Pr 和 Pg 組合所有可能的聯合分佈 γ 的集合,中的每個分佈的邊緣分佈都是 Pr 和 Pg。具體直觀地來講,就是 γ(x,y) 指出需要多少“質量”才能把分佈 Pg 挪向 Pr 分佈,EM 距離就是路線規劃的最優消耗。
是指 Pr 和 Pg 組合所有可能的聯合分佈 γ 的集合,中的每個分佈的邊緣分佈都是 Pr 和 Pg。具體直觀地來講,就是 γ(x,y) 指出需要多少“質量”才能把分佈 Pg 挪向 Pr 分佈,EM 距離就是路線規劃的最優消耗。
論文作者提出一個簡單直觀的例子,在這種情況下使用 EM 距離可以收斂但是其他距離下無法收斂,體現出 Wasserstein 距離的優越性。
考慮如下二維空間中 ,令 Z~U[0,1] ,存在兩個分佈 P0 和 Pθ,在透過原點垂直於 x 軸的線段 α 上均勻分佈即 (0,Z),令 Pθ 線上段 β 上均勻分佈且垂直於 x 軸,即 (θ,Z),透過控制引數 θ 可以控制著兩個分佈的距離遠近,但是兩個分佈沒有重疊的部分。

很容易得到以下結論:

作者用下圖詳細表達了在上面這個簡單例子下的 EM 距離(左圖)和 JS 散度(右圖)。

當![]() ,只有 EM 距離是平滑連續的,
,只有 EM 距離是平滑連續的,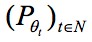 在 EM 距離下收斂於 P0,而其他距離是突變的,無法收斂。因此 EM 距離可以在兩個分佈沒有重疊部分的情況下提供有意義的梯度,而其他距離不可以。
在 EM 距離下收斂於 P0,而其他距離是突變的,無法收斂。因此 EM 距離可以在兩個分佈沒有重疊部分的情況下提供有意義的梯度,而其他距離不可以。
Wasserstein GAN演演算法流程
論文作者寫到,可以把 EM 距離用一個式子表示出來:
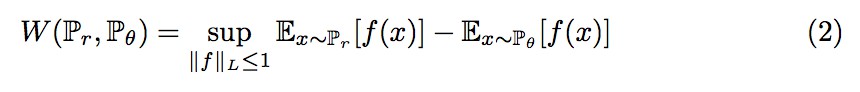
其中公式 1-Lipschitz 表示函式集。當 f 是一個 Lipschitz 函式時,滿足 。當 K=1 時,這個函式就是 1-Lipschitz 函式。
。當 K=1 時,這個函式就是 1-Lipschitz 函式。
特別地,我們用一組引數 ω 來定義一系列可能的 f,透過訓練神經網路來最佳化 ω 擬合逼近在一系列可能的 f 組成函式集,其中![]() 符合 K-Lipschitz 只取決於所有權重引數 ω 的取值範圍空間 W,不取決於某個單獨的權重引數ω。
符合 K-Lipschitz 只取決於所有權重引數 ω 的取值範圍空間 W,不取決於某個單獨的權重引數ω。
所以論文作者使用簡單粗暴的方法,對每次更新後的神經網路內的權重的絕對值限制在一個固定的常數內,即例如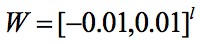 ,就能滿足 Lipschitz 條件了。
,就能滿足 Lipschitz 條件了。
所以問題轉化為,構造一個含引數 ω 判別器神經網路![]() ,為了回歸擬合所有可能的 f 最後一層不能是線性啟用層,並且限制 ω 在一定常數範圍內,最大化
,為了回歸擬合所有可能的 f 最後一層不能是線性啟用層,並且限制 ω 在一定常數範圍內,最大化 ,同時生成器最小化 EM 距離,考慮第一項與生成器無關,所以生成器的損失函式是
,同時生成器最小化 EM 距離,考慮第一項與生成器無關,所以生成器的損失函式是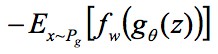 。
。
下麵按照筆者的理解來解釋一下為什麼需要使用 1-Lipschitz 條件,考慮一個簡單直觀的情況,假設我們現在有兩個一維的分佈,x1 和 x2 的距離是 d,顯然他們之間的 EM 距離也是 d:

此時按照問題的轉化,我們需要最大化 ,只需要讓
,只需要讓 ,且
,且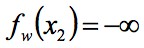 就可以了,也就是說不使用 1-Lipschitz 限制,只需要讓判別器判斷 Pr 為正無窮,Pg 為負無窮就可以了。
就可以了,也就是說不使用 1-Lipschitz 限制,只需要讓判別器判斷 Pr 為正無窮,Pg 為負無窮就可以了。
但是這樣的話判別器分類能力太強,生成器很難訓練得動,很難使得生成分佈向真實分佈靠近。而加上了 1-Lipschitz 限制的話,即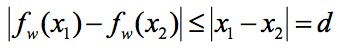 ,最大化 EM 距離,可以讓
,最大化 EM 距離,可以讓 ,且
,且 ,這樣就把判別器在生成分佈和真實分佈上的結果限制在了一定範圍內,得到一個不太好也不太壞的判別器,繼續驅動生成器的生成樣本。
,這樣就把判別器在生成分佈和真實分佈上的結果限制在了一定範圍內,得到一個不太好也不太壞的判別器,繼續驅動生成器的生成樣本。
論文中提到加了限制的好處,原始的 GAN 是最終經過 sigmoid 輸出的神經網路,在靠近真實分佈的附近,函式變化平緩,存在梯度消失現象,而使用了限制的 WGAN 在訓練過程可以無差別地提供有意義的梯度。

論文作者給出瞭如下的完整的 WGAN 演演算法流程,一方面最佳化含引數 ω 判別器![]() ,使用梯度上升的方法更新權重引數 ω,並且更新完 ω 後截斷在 (-c,c) 的範圍內,另一方面最佳化由引數 θ 控制生成樣本的生成器,其中作者發現梯度更新存在不穩定現象,所以不建議使用 Adam 這類基於動量的最佳化演演算法,推薦選擇 RMSProp、SGD 等最佳化方法。
,使用梯度上升的方法更新權重引數 ω,並且更新完 ω 後截斷在 (-c,c) 的範圍內,另一方面最佳化由引數 θ 控制生成樣本的生成器,其中作者發現梯度更新存在不穩定現象,所以不建議使用 Adam 這類基於動量的最佳化演演算法,推薦選擇 RMSProp、SGD 等最佳化方法。

實驗結果和分析
論文作者認為使用 WGAN 主要有兩個優勢:
-
訓練過程中有一個有意義的 loss 值來指示生成器收斂,並且這個數值越小代表 GAN 訓練得越好,代表生成器產生的影象質量越高;
-
改善了最佳化過程的穩定性,解決梯度消失等問題,並且未發現存在生成樣本缺乏多樣性的問題。
作者指出我們可以清晰地發現 Wasserstein 距離越小,錯誤率越低,生成質量越高,因此存在指示訓練過程的意義。

對比與 JS 散度,當模型訓練得越好,JS 散度或高或低,與生成樣本質量之間無關聯,沒有意義。

論文實驗表明 WGAN 和 DCGAN 都能生成的高質量的樣本,左圖 WGAN,右圖 DCGAN。

而如果都不使用批標準化,左圖的 WGAN 生成質量很好,而右圖的 DCGAN 生成的質量很差。

如果 WGAN 和 GAN 都是用 MLP,WGAN 生成質量較好,而 GAN 出現樣本缺乏多樣性的問題。

總結
相比於原始 GAN,WGAN 只需要修改以下四點,就能使得訓練更穩定,生成質量更高:
1. 因為這裡的判別器相當於做回歸任務,所以判別器最後一層去掉 sigmoid;
2. 生成器和判別器的 loss 不取 log;
3. 每次更新判別器的引數之後把它們的絕對值截斷到不超過一個固定常數 c;
4. 論文作者推薦使用 RMSProp 等非基於動量的最佳化演演算法。
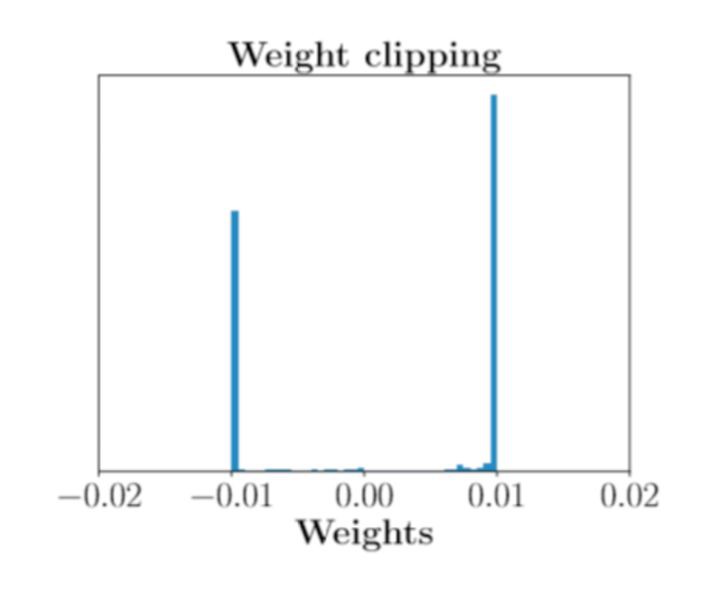
不過,WGAN 還是存在一些問題的:訓練困難、收斂速度慢。這源於 weight clipping 的方法太簡單粗暴了,導致判別器的引數幾乎都集中在最大值和最小值上,相當於一個二值神經網路了,沒有發揮深度神經網路的強大擬合能力。不過論文作者在後續 WGAN-GP 中提出梯度懲罰的方法剋服了這一缺點。
模型復現
論文復現程式碼:
http://aistudio.baidu.com/aistudio/#/projectdetail/29022
註:這裡筆者使用 MNIST 手寫數字資料集進行訓練對比。
# 生成器 Generator
def G(z, name="G"):
with fluid.unique_name.guard(name + "/"):
y = z
y = fluid.layers.fc(y, size=1024, act='tanh')
y = fluid.layers.fc(y, size=128 * 7 * 7)
y = fluid.layers.batch_norm(y, act='tanh')
y = fluid.layers.reshape(y, shape=(-1, 128, 7, 7))
y = fluid.layers.image_resize(y, scale=2)
y = fluid.layers.conv2d(y, num_filters=64, filter_size=5, padding=2, act='tanh')
y = fluid.layers.image_resize(y, scale=2)
y = fluid.layers.conv2d(y, num_filters=1, filter_size=5, padding=2, act='tanh')
return y
def D(images, name="D"):
# define parameters of discriminators
def conv_bn(input, num_filters, filter_size):
# w_param_attrs=fluid.ParamAttr(gradient_clip=fluid.clip.GradientClipByValue(CLIP[0], CLIP[1]))
y = fluid.layers.conv2d(
input,
num_filters=num_filters,
filter_size=filter_size,
padding=0,
stride=1,
bias_attr=False)
y = fluid.layers.batch_norm(y)
y = fluid.layers.leaky_relu(y)
return y
with fluid.unique_name.guard(name + "/"):
y = images
y = conv_bn(y, num_filters=32, filter_size=3)
y = fluid.layers.pool2d(y, pool_size=2, pool_stride=2)
y = conv_bn(y, num_filters=64, filter_size=3)
y = fluid.layers.pool2d(y, pool_size=2, pool_stride=2)
y = conv_bn(y, num_filters=128, filter_size=3)
y = fluid.layers.pool2d(y, pool_size=2, pool_stride=2)
y = fluid.layers.fc(y, size=1)
return y
▲ 生成器和判別器程式碼展示
# 方便顯示結果
def printimg(images, epoch=None): # images.shape = (64, 1, 28, 28)
fig = plt.figure(figsize=(5, 5))
fig.suptitle("Epoch {}".format(epoch))
gs = plt.GridSpec(8, 8)
gs.update(wspace=0.05, hspace=0.05)
for i, image in enumerate(images[:64]):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(image[0], cmap='Greys_r')
plt.show()
batch_size = 128
# MNIST資料集,不使用label
def mnist_reader(reader):
def r():
for img, label in reader():
yield img.reshape(1, 28, 28)
return r
# 噪聲生成
def z_g():
while True:
yield np.random.normal(0.0, 1.0, (z_dim, 1, 1)).astype('float32')
mnist_generator = paddle.batch(
paddle.reader.shuffle(mnist_reader(paddle.dataset.mnist.train()), 1024), batch_size=batch_size)
z_generator = paddle.batch(z_g, batch_size=batch_size)()
place = fluid.CUDAPlace(0) if fluid.core.is_compiled_with_cuda() else fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(startup)
# 測試噪聲z
np.random.seed(0)
noise_z = np.array(next(z_generator))
for epoch in range(10):
epoch_fake_loss = []
epoch_real_loss = []
epoch_g_loss = []
for i, real_image in enumerate(mnist_generator()):
# 訓練D識別G生成的圖片為假圖片
r_fake = exe.run(train_d_fake, fetch_list=[fake_loss], feed={
'z': np.array(next(z_generator))
})
epoch_fake_loss.append(np.mean(r_fake))
# 訓練D識別真實圖片
r_real = exe.run(train_d_real, fetch_list=[real_loss], feed={
'img': np.array(real_image)
})
epoch_real_loss.append(np.mean(r_real))
d_params = get_params(train_d_real, "D")
min_var = fluid.layers.tensor.fill_constant(shape=[1], dtype='float32', value=CLIP[0])
max_var = fluid.layers.tensor.fill_constant(shape=[1], dtype='float32', value=CLIP[1])
# 每次更新判別器的引數之後把它們的絕對值截斷到不超過一個固定常數
for pr in d_params:
fluid.layers.elementwise_max(x=train_d_real.global_block().var(pr),y=min_var,axis=0)
fluid.layers.elementwise_min(x=train_d_real.global_block().var(pr),y=max_var,axis=0)
## 訓練G生成符合D標準的“真實”圖片
r_g = exe.run(train_g, fetch_list=[g_loss], feed={
'z': np.array(next(z_generator))
})
epoch_g_loss.append(np.mean(r_g))
if i % 10 == 0:
print("Epoch {} batch {} fake {} real {} g {}".format(
epoch, i, np.mean(epoch_fake_loss), np.mean(epoch_real_loss), np.mean(epoch_g_loss)
))
# 測試
r_i = exe.run(infer_program, fetch_list=[fake], feed={
'z': noise_z
})
printimg(r_i[0], epoch)
▲ 模型訓練程式碼展示
原始 GAN:

Wasserstein GAN:

可以看出,WGAN 比原始 GAN 效果稍微好一些,生成質量稍微好一些,更穩定。
關於PaddlePaddle
這是筆者第一次使用 PaddlePaddle 這個開源深度學習框架,框架本身具有易學、易用、安全、高效四大特性,很適合作為學習工具,筆者透過平臺的深度學習的影片課程就很快地輕鬆上手了。
不過,筆者在使用過程中發現 PaddlePaddle 的使用檔案比較簡單,很多 API 沒有詳細解釋用法,更多的時候需要檢視 Github 上的原始碼來一層一層地瞭解學習,希望官方的使用檔案中能給到更多簡單使用例子來幫助我們學習理解,也希望 PaddlePaddle 能越來越好,功能越來越強大。
參考文獻
[1] Martin Arjovsky and L´eon Bottou. Towards principled methods for training generative adversarial networks. In International Conference on Learning Representations, 2017. Under review.
[2] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017.
[3] IshaanGulrajani, FarukAhmed1, MartinArjovsky, VincentDumoulin, AaronCourville. Improved Training of Wasserstein GANs. arXiv preprint arXiv:1704.00028, 2017.
[4] https://zhuanlan.zhihu.com/p/25071913

點選標題檢視更多論文復現:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 收藏復現程式碼
