(點選上方公眾號,可快速關註)
來源:Grant_Ward
blog.csdn.net/bhneo/article/details/83339402
對於資料科學的藝術,統計學可以說是一個強大的工具。從高層次的角度來看,統計是利用數學對資料進行技術分析。一個基本的視覺化,如條形圖,可以給你提供一些高階的資訊,但是透過統計學,我們可以以一種更加以資訊驅動和更有針對性的方式來運算元據。所用到的數學方法能幫助我們對資料形成具體的結論,而不是去靠猜測。
透過使用統計學,我們可以更深入、更細緻地瞭解我們的資料到底是如何構造的,並基於這種結構,我們如何最佳地應用其他資料科學技術來獲取更多的資訊。現在,我們來看看資料科學家們需要知道的5個基本統計概念,以及如何才能最有效地應用它們!
統計特徵
統計特徵可能是資料科學中最常用的統計概念。這通常是你在研究資料集時應用的第一種統計技術,包括偏差、方差、平均值、中位數、百分位數等。這一切都相當容易理解併在程式碼中實現!看看下麵的圖表。

一個簡單的箱型圖
中間的那條線是資料的中位數。由於中位數對離群值的魯棒性更強,因此中位數比平均值用得更多。第一個四分位數本質上是第25百分位數,表示資料中25%的點低於這個值。第三個四分位數是第75百分位數,表示資料中75%的點都低於這個值。最小值和最大值表示資料範圍的上、下端。
一個箱型圖完美地闡述了我們能用基本統計特徵做什麼:
-
當框圖很短時,它意味著許多資料點是相似的,因為在小範圍內有許多值
-
當框圖很長時,它意味著許多資料點是完全不同的,因為這些值分佈在一個較廣的範圍內
-
如果中值更接近底部,那麼我們知道大多數資料的值更低。如果中值更接近頂部,那麼我們知道大多數資料都有更高的值。基本上,如果中值線不在方框中間,那麼它就表示資料有偏斜。
-
是否有長尾?這意味著你的資料有很高的標準差和方差,說明這些值是分散的,高度不同。如果你在盒子的一邊有長尾而在另一邊沒有,那麼你的資料可能只在一個方向上有很大的變化。
所有這些資訊都來自一些簡單的統計特徵,並且很容易計算!當你需要對資料進行快速而有效的檢視時,請嘗試這些方法。
機率分佈
我們可以將機率定義為某個事件發生的機率百分比。在資料科學中,通常在0到1之間進行量化,0表示我們確信不會發生,1表示我們確信它會發生。機率分佈是一個函式,表示實驗中所有可能值的機率。請看下麵的圖表。
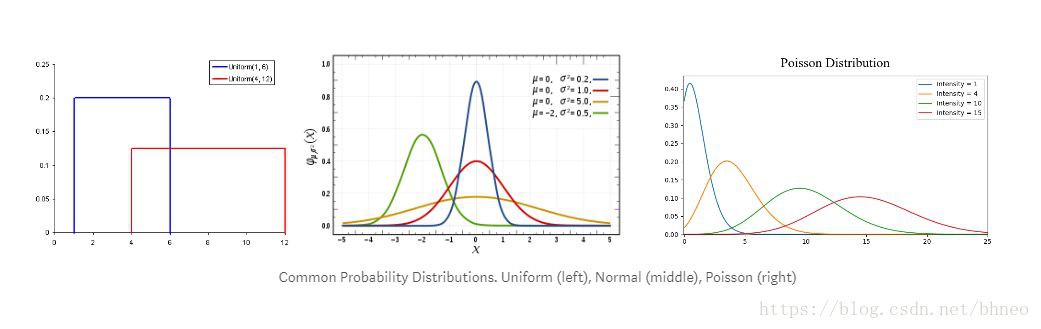
-
均勻分佈是我們在這裡展示的3個分佈中最基本的。它只有一個值,這個值只出現在某個範圍內,而超出這個範圍的任何值都是0。這在很大程度上是一種“開關”分佈。我們也可以把它看作是一個有兩個類別的分類變數:0或其他值。你的分類變數可能有多個非0的值,但我們仍然可以把它想象成多個均勻分佈的分段函式。
-
正態分佈,通常被稱為高斯分佈,由均值和標準差定義。均值在空間上平移分佈,標準差控制分散程度。與其他分佈的重要區別(比如泊松分佈)是,其所有方向上的標準差都是一樣的。因此,對於高斯分佈,我們知道資料集的平均值以及資料的發散程度(例如,它是廣泛分佈的還是高度集中在少數幾個值)。
-
泊松分佈與正態分佈相似,但增加了偏斜因子。在偏態值較低的情況下,泊松分佈會像正態分佈一樣向各個方向均勻發散。但當偏度值較大時,我們的資料在不同方向的發散會不同;在一個方向,它將非常分散,在另一個方向,它將高度集中。
雖然有很多的分佈可以深入研究,但這3個已經給我們帶來了很多價值。我們可以用均勻分佈快速地看到和解釋分類變數。如果我們看到一個高斯分佈便知道有很多演演算法在預設情況下都能很好地處理高斯分佈,所以我們應該這樣做。有了泊松分佈,我們會發現必須特別小心選擇一種對空間發散的變化具有魯棒性的演演算法。
降維
降維這個術語很容易理解。我們有一個資料集,希望減少它的維數。在資料科學中,它是特徵變數的數量。請看下麵的圖表。
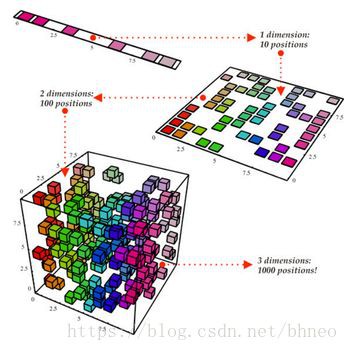
降維
立方體代表我們的資料集,它有三個維度,總共有1000個點。雖然1000個點的計算在今天很容易處理,但是對於更大的範圍我們仍然會遇到問題。然而,僅僅從二維的角度來看我們的資料,例如從立方體的一邊,我們可以看到,從這個角度劃分所有的顏色是很容易的。透過降維,我們可以將三維資料投射到二維平面上。這有效地將我們需要計算的點數減少了100,大大節省了計算量!
另一種降維方法是特徵剪枝。有了特徵剪枝,我們可以刪除對分析不重要的任何特徵。例如,在研究資料集之後,我們可能會發現,在10個特性中,有7個特性與輸出的相關性很高,而其他3個特性的相關性很低。那麼,這3個低相關特性可能不值得計算,不過我們只能根據分析在不影響輸出的情況下將它們刪除。
當前用於降維的最常見的技術是PCA,它本質上是建立了特徵的向量表示,顯示它們對輸出有多重要,比如他們的相關性。PCA可以用於上面討論的兩種降維方式。在此教程中可以瞭解到更多資訊。
過取樣與欠取樣
過取樣和欠取樣是用於分類問題的技術。有時,我們的分類資料集可能會嚴重傾斜到一邊。例如,類1有2000個樣本,但類2只有200個。這將對很多我們常用於建模並預測的機器學習技術帶來影響!但過取樣和欠取樣可以與之對抗。請看下麵的圖表。

欠取樣與過取樣
在上圖的左邊和右邊,我們的藍色類比橙色類擁有更多的樣本。在這種情況下,有兩個預處理選項可以幫助我們的機器學習模型的訓練。
欠取樣意味著我們將只從多數類中選擇一部分資料,只使用與少數類樣本數相同的數量。這個方案應當保證取樣後類別的機率分佈與之前相同。操作很容易,我們只是透過取更少的樣本來平衡資料集!
過取樣意味著我們將建立少數類的副本,以便擁有與多數類相同的樣本。建立副本時應當保證少數類的分佈不變。這個方案中,我們只是把我們的資料集變得更均衡,並沒有得到更多的資料!
貝葉斯統計
為了充分理解為什麼我們要使用貝葉斯統計,需要首先瞭解頻率統計不足的地方。頻率統計是大多數人聽到“機率”這個詞時會想到的統計方法。它應用數學來分析某些事件發生的機率,具體來說,我們使用的資料都是先驗的。

我們看一個例子。假設給你一個骰子然後問你擲出6的機率是多少,大多數人會說1 / 6。確實,如果我們做頻率分析,會透過一些資料比如某人擲骰子10000次,然後計算每個數字出現的頻率;大概是1 / 6!
但如果有人告訴你,給你的那個骰子是被改造過的並且落地後總會是6的那面朝上呢?頻率分析只考慮了先驗的資料,並沒有考慮骰子被改造過這個因素。
貝葉斯統計確實考慮到了這個問題,可以用貝葉定理來說明這一點:
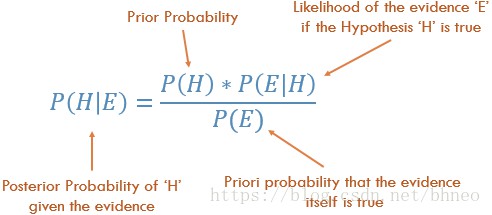
貝葉斯定律
方程中的機率P(H)基本上就是頻率分析;表示根據之前的先驗資料,事件發生的機率是多少。方程中的P(E|H)被稱為似然,本質上是根據頻率分析得到的資訊的條件下,我們得到的結論是正確的機率。例如,滾動骰子10000次,而前1000次全部得到6,你會開始肯定,骰子是被改造過的!P(E)是實際結論成立的機率。如果我告訴你,骰子是改造過的,你能相信我並說它是真的嗎?
如果我們的頻率分析很好那麼就會有一定的權重說明:是的,我們對6的猜測是正確的。與此同時,我們考慮了改造骰子的事實,它是否為真,同時基於它自己的先驗和頻率分析。從方程的佈局可以看出,貝葉斯統計考慮了所有的因素。當你覺得之前的資料不能很好地代表未來的資料和結果時,就使用它。
推薦閱讀
(點選標題可跳轉閱讀)
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

