簡介
Python 是一種高層次的結合瞭解釋性、編譯性、互動性和麵向物件的指令碼語言。Python 由 Guido van Rossum 於 1989 年底在荷蘭國家數學和電腦科學研究所發明,第一個公開發行版發行於 1991 年。
特點
-
易於學習:Python 有相對較少的關鍵字,結構簡單,和一個明確定義的語法,學習起來更加簡單。
-
易於閱讀:Python 程式碼定義的更清晰。
-
易於維護:Python 的成功在於它的原始碼是相當容易維護的。
-
一個廣泛的標準庫:Python 的最大的優勢之一是豐富的庫,跨平臺的,在 UNIX,Windows 和 macOS 相容很好。
-
互動樣式:互動樣式的支援,您可以從終端輸入執行程式碼並獲得結果的語言,互動的測試和除錯程式碼片斷。
-
可移植:基於其開放原始碼的特性,Python 已經被移植(也就是使其工作)到許多平臺。
-
可擴充套件:如果你需要一段執行很快的關鍵程式碼,或者是想要編寫一些不願開放的演演算法,你可以使用 C 或 C++ 完成那部分程式,然後從你的 Python 程式中呼叫。
-
資料庫:Python 提供所有主要的商業資料庫的介面。
-
GUI 程式設計:Python 支援 GUI 可以建立和移植到許多系統呼叫。
-
可嵌入:你可以將 Python 嵌入到 C/C++ 程式,讓你的程式的使用者獲得”指令碼化”的能力。
-
面向物件:Python 是強面向物件的語言,程式中任何內容統稱為物件,包括數字、字串、函式等。
基礎語法
執行 Python
互動式直譯器
在命令列視窗執行python後,進入 Python 的互動式直譯器。exit() 或 Ctrl + D 組合鍵退出互動式直譯器。
命令列指令碼
在命令列視窗執行python script-file.py,以執行 Python 指令碼檔案。
指定直譯器
如果在 Python 指令碼檔案首行輸入#!/usr/bin/env python,那麼可以在命令列視窗中執行/path/to/script-file.py以執行該指令碼檔案。
註:該方法不支援 Windows 環境。
編碼
預設情況下,3.x 原始碼檔案都是 UTF-8 編碼,字串都是 Unicode 字元。也可以手動指定檔案編碼:
# -*- coding: utf-8 -*-
或者
# encoding: utf-8
註意: 該行標註必須位於檔案第一行
識別符號
-
第一個字元必須是英文字母或下劃線 _ 。
-
識別符號的其他的部分由字母、數字和下劃線組成。
-
識別符號對大小寫敏感。
註:從 3.x 開始,非 ASCII 識別符號也是允許的,但不建議。
保留字
保留字即關鍵字,我們不能把它們用作任何識別符號名稱。Python 的標準庫提供了一個 keyword 模組,可以輸出當前版本的所有關鍵字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
註釋
單行註釋採用#,多行註釋採用”’或”””。
# 這是單行註釋
'''
這是多行註釋
這是多行註釋
'''
"""
這也是多行註釋
這也是多行註釋
"""
行與縮排
Python 最具特色的就是使用縮排來表示程式碼塊,不需要使用大括號 {}。 縮排的空格數是可變的,但是同一個程式碼塊的陳述句必須包含相同的縮排空格數。縮排不一致,會導致執行錯誤。
多行陳述句
Python 通常是一行寫完一條陳述句,但如果陳述句很長,我們可以使用反斜槓來實現多行陳述句。
total = item_one +
item_two +
item_three
在 [], {}, 或 () 中的多行陳述句,不需要使用反斜槓。
空行
函式之間或類的方法之間用空行分隔,表示一段新的程式碼的開始。類和函式入口之間也用一行空行分隔,以突出函式入口的開始。
空行與程式碼縮排不同,空行並不是 Python 語法的一部分。書寫時不插入空行,Python 直譯器執行也不會出錯。但是空行的作用在於分隔兩段不同功能或含義的程式碼,便於日後程式碼的維護或重構。
記住:空行也是程式程式碼的一部分。
等待使用者輸入
input函式可以實現等待並接收命令列中的使用者輸入。
content = input("
請輸入點東西並按 Enter 鍵
")
print(content)
同一行寫多條陳述句
Python 可以在同一行中使用多條陳述句,陳述句之間使用分號;分割。
import sys; x = 'hello world'; sys.stdout.write(x + '
')
多個陳述句構成程式碼組
縮排相同的一組陳述句構成一個程式碼塊,我們稱之程式碼組。
像if、while、def和class這樣的複合陳述句,首行以關鍵字開始,以冒號:結束,該行之後的一行或多行程式碼構成程式碼組。
我們將首行及後面的程式碼組稱為一個子句(clause)。
print 輸出
print 預設輸出是換行的,如果要實現不換行需要在變數末尾加上end=””或別的非換行符字串:
print('123') # 預設換行
print('123', end = "") # 不換行
import 與 from…import
在 Python 用 import 或者 from…import 來匯入相應的模組。
將整個模組匯入,格式為:import module_name
從某個模組中匯入某個函式,格式為:from module_name import func1
從某個模組中匯入多個函式,格式為:from module_name import func1, func2, func3
將某個模組中的全部函式匯入,格式為:from module_name import *
運運算元
算術運運算元
運運算元描述+加-減*乘/除%取模**冪//取整除
比較運運算元
運運算元描述==等於!=不等於>大於=大於等於<=小於等於
賦值運運算元
運運算元描述=簡單的賦值運運算元+=加法賦值運運算元-=減法賦值運運算元*=乘法賦值運運算元/=除法賦值運運算元%=取模賦值運運算元**=冪賦值運運算元//=取整除賦值運運算元
位運運算元

邏輯運運算元

成員運運算元

身份運運算元

運運算元優先順序

具有相同優先順序的運運算元將從左至右的方式依次進行。用小括號()可以改變運算順序。
變數
變數在使用前必須先”定義”(即賦予變數一個值),否則會報錯:
>>> name
Traceback (most recent call last):
File "", line 1, in
NameError: name 'name' is not defined
資料型別
布林(bool)
只有 True 和 False 兩個值,表示真或假。
數字(number)
整型(int)
整數值,可正數亦可複數,無小數。 3.x 整型是沒有限制大小的,可以當作 Long 型別使用,所以 3.x 沒有 2.x 的 Long 型別。
浮點型(float)
浮點型由整數部分與小數部分組成,浮點型也可以使用科學計數法表示(2.5e2 = 2.5 x 10^2 = 250)
複數(complex)
複數由實數部分和虛數部分構成,可以用a + bj,或者complex(a,b)表示,複數的實部 a 和虛部 b 都是浮點型。
數字運算
-
不同型別的數字混合運算時會將整數轉換為浮點數
-
在不同的機器上浮點運算的結果可能會不一樣
-
在整數除法中,除法 / 總是傳回一個浮點數,如果只想得到整數的結果,丟棄可能的分數部分,可以使用運運算元 //。
-
// 得到的並不一定是整數型別的數,它與分母分子的資料型別有關係
-
在互動樣式中,最後被輸出的運算式結果被賦值給變數 _,_ 是個只讀變數
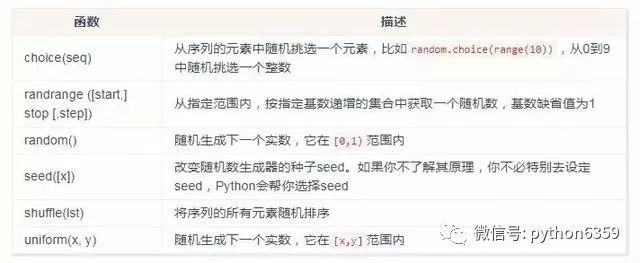
數學函式
註:以下函式的使用,需先匯入 math 包。

隨機數函式
註:以下函式的使用,需先匯入 random 包。
三角函式
註:以下函式的使用,需先匯入 math 包。

數學常量

字串(string)
-
單引號和雙引號使用完全相同
-
使用三引號(”’或”””)可以指定一個多行字串
-
轉義符(反斜槓)可以用來轉義,使用r可以讓反斜槓不發生轉義,如r”this is a line with “,則會顯示,並不是換行
-
按字面意義級聯字串,如”this ” “is ” “string”會被自動轉換為this is string
-
字串可以用 + 運運算元連線在一起,用 * 運運算元重覆
-
字串有兩種索引方式,從左往右以 0 開始,從右往左以 -1 開始
-
字串不能改變
-
沒有單獨的字元型別,一個字元就是長度為 1 的字串
-
字串的擷取的語法格式如下:變數[頭下標:尾下標]
跳脫字元

字串運運算元
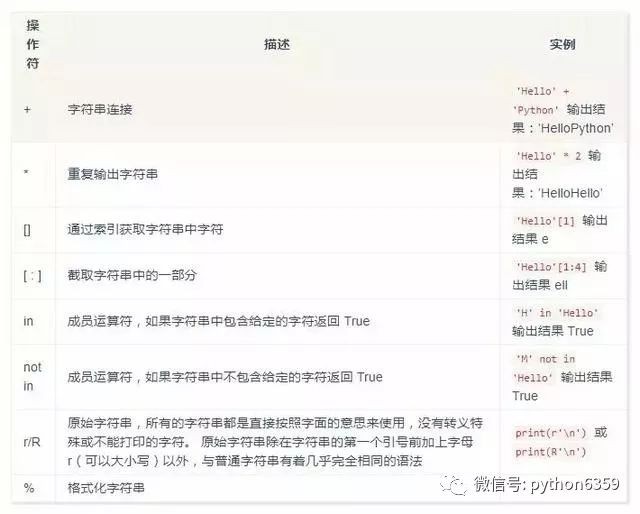
字串格式化
在 Python 中,字串格式化不是 sprintf 函式,而是用 % 符號。例如:
print("我叫%s, 今年 %d 歲!" % ('小明', 10))
// 輸出:
我叫小明, 今年 10 歲!
格式化符號:

輔助指令:

Python 2.6 開始,新增了一種格式化字串的函式 str.format(),它增強了字串格式化的功能。
多行字串
-
用三引號(”’ 或 “””)包裹字串內容
-
多行字串內容支援轉義符,用法與單雙引號一樣
-
三引號包裹的內容,有變數接收或操作即字串,否則就是多行註釋
實體:
string = '''
print( math.fabs(-10))
print(
random.choice(li))
'''
print(string)
輸出:
print( math.fabs(-10))
print(
random.choice(li))
Unicode
在 2.x 中,普通字串是以 8 位 ASCII 碼進行儲存的,而 Unicode 字串則儲存為 16 位 Unicode 字串,這樣能夠表示更多的字符集。使用的語法是在字串前面加上字首 u。
在 3.x 中,所有的字串都是 Unicode 字串。
字串函式

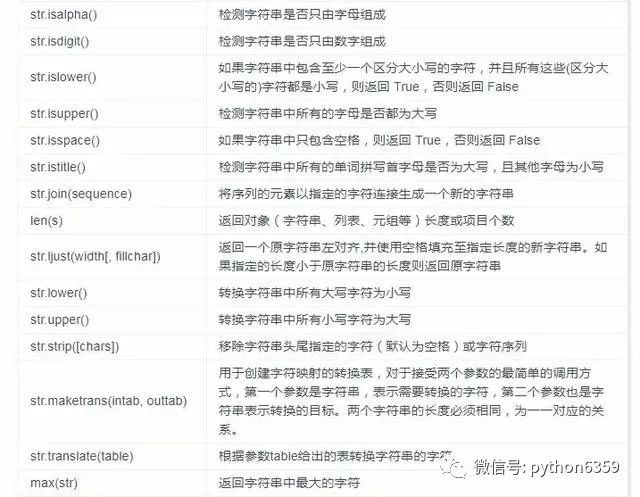

位元組(bytes)
在 3.x 中,字串和二進位制資料完全區分開。文字總是 Unicode,由 str 型別表示,二進位制資料則由 bytes 型別表示。Python 3 不會以任意隱式的方式混用 str 和 bytes,你不能拼接字串和位元組流,也無法在位元組流裡搜尋字串(反之亦然),也不能將字串傳入引數為位元組流的函式(反之亦然)。
-
bytes 型別與 str 型別,二者的方法僅有 encode() 和 decode() 不同。
-
bytes 型別資料需在常規的 str 型別前加個 b 以示區分,例如 b’abc’。
-
只有在需要將 str 編碼(encode)成 bytes 的時候,比如:透過網路傳輸資料;或者需要將 bytes 解碼(decode)成 str 的時候,我們才會關註 str 和 bytes 的區別。
bytes 轉 str:
b'abc'.decode()
str(b'abc')
str(b'abc', encoding='utf-8')
str 轉 bytes:
'中國'.encode()
bytes('中國', encoding='utf-8')
串列(list)
-
串列是一種無序的、可重覆的資料序列,可以隨時新增、刪除其中的元素。
-
串列頁的每個元素都分配一個數字索引,從 0 開始
-
串列使用方括號建立,使用逗號分隔元素
-
串列元素值可以是任意型別,包括變數
-
使用方括號對串列進行元素訪問、切片、修改、刪除等操作,開閉合區間為[)形式
-
串列的元素訪問可以巢狀
-
方括號內可以是任意運算式
建立串列
hello = (1, 2, 3)
li = [1, "2", [3, 'a'], (1, 3), hello]
訪問元素
li = [1, "2", [3, 'a'], (1, 3)]
print(li[3]) # (1, 3)
print(li[-2]) # [3, 'a']
切片訪問
格式: list_name[begin:end:step] begin 表示起始位置(預設為0),end 表示結束位置(預設為最後一個元素),step 表示步長(預設為1)
hello = (1, 2, 3)
li = [1, "2", [3, 'a'], (1, 3), hello]
print(li) # [1, '2', [3, 'a'], (1, 3), (1, 2, 3)]
print(li[1:2]) # ['2']
print(li[:2]) # [1, '2']
print(li[:]) # [1, '2', [3, 'a'], (1, 3), (1, 2, 3)]
print(li[2:]) # [[3, 'a'], (1, 3), (1, 2, 3)]
print(li[1:-1:2]) # ['2', (1, 3)]
訪問內嵌 list 的元素:
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ['a', 'b', 'c']]
print(li[1:-1:2][1:3]) # (3, 5)
print(li[-1][1:3]) # ['b', 'c']
print(li[-1][1]) # b
修改串列
透過使用方括號,可以非常靈活的對串列的元素進行修改、替換、刪除等操作。
li = [0, 1, 2, 3, 4, 5]
li[len(li) - 2] = 22 # 修改 [0, 1, 2, 22, 4, 5]
li[3] = 33 # 修改 [0, 1, 2, 33, 4, 5]
li[1:-1] = [9, 9] # 替換 [0, 9, 9, 5]
li[1:-1] = [] # 刪除 [0, 5]
刪除元素
可以用 del 陳述句來刪除串列的指定範圍的元素。
li = [0, 1, 2, 3, 4, 5]
del li[3] # [0, 1, 2, 4, 5]
del li[2:-1] # [0, 1, 5]
串列運運算元
-
+ 用於合併串列
-
* 用於重覆串列元素
-
in 用於判斷元素是否存在於串列中
-
for … in … 用於遍歷串列元素
[1, 2, 3] + [3, 4, 5] # [1, 2, 3, 3, 4, 5]
[1, 2, 3] * 2 # [1, 2, 3, 1, 2, 3]
3 in [1, 2, 3] # True
for x in [1, 2, 3]: print(x) # 1 2 3
串列函式
-
len(list) 串列元素個數
-
max(list) 串列元素中的最大值
-
min(list) 串列元素中的最小值
-
list(seq) 將元組轉換為串列
li = [0, 1, 5]
max(li) # 5
len(li) # 3
註: 對串列使用 max/min 函式,2.x 中對元素值型別無要求,3.x 則要求元素值型別必須一致。
串列方法
-
list.append(obj)
-
在串列末尾新增新的物件
-
list.count(obj)
-
傳回元素在串列中出現的次數
-
list.extend(seq)
-
在串列末尾一次性追加另一個序列中的多個值
-
list.index(obj)
-
傳回查詢物件的索引位置,如果沒有找到物件則丟擲異常
-
list.insert(index, obj)
-
將指定物件插入串列的指定位置
-
list.pop([index=-1]])
-
移除串列中的一個元素(預設最後一個元素),並且傳回該元素的值
-
list.remove(obj)
-
移除串列中某個值的第一個匹配項
-
list.reverse()
-
反向排序串列的元素
-
list.sort(cmp=None, key=None, reverse=False)
-
對原串列進行排序,如果指定引數,則使用比較函式指定的比較函式
-
list.clear()
-
清空串列 還可以使用 del list[:]、li = [] 等方式實現
-
list.copy()
-
複製串列 預設使用等號賦值給另一個變數,實際上是取用串列變數。如果要實現
串列推導式
串列推導式提供了從序列建立串列的簡單途徑。通常應用程式將一些操作應用於某個序列的每個元素,用其獲得的結果作為生成新串列的元素,或者根據確定的判定條件建立子序列。
每個串列推導式都在 for 之後跟一個運算式,然後有零到多個 for 或 if 子句。傳回結果是一個根據表達從其後的 for 和 if 背景關係環境中生成出來的串列。如果希望運算式推匯出一個元組,就必須使用括號。
將串列中每個數值乘三,獲得一個新的串列:
vec = [2, 4, 6]
[(x, x**2) for x in vec]
# [(2, 4), (4, 16), (6, 36)]
對序列裡每一個元素逐個呼叫某方法:
freshfruit = [' banana', ' loganberry ', 'passion fruit ']
[weapon.strip() for weapon in freshfruit]
# ['banana', 'loganberry', 'passion fruit']
用 if 子句作為過濾器:
vec = [2, 4, 6]
[3*x for x in vec if x > 3]
# [12, 18]
vec1 = [2, 4, 6]
vec2 = [4, 3, -9]
[x*y for x in vec1 for y in vec2]
# [8, 6, -18, 16, 12, -36, 24, 18, -54]
[vec1[i]*vec2[i] for i in range(len(vec1))]
# [8, 12, -54]
串列巢狀解析:
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
new_matrix = [[row[i] for row in matrix] for i in range(len(matrix[0]))]
print(new_matrix)
# [[1, 4, 7], [2, 5, 8], [3, 6, 9]]
元組(tuple)
-
元組與串列類似,不同之處在於元組的元素不能修改
-
元組使用小括號,串列使用方括號
-
元組建立很簡單,只需要在括號中新增元素,並使用逗號隔開即可
-
沒有 append(),insert() 這樣進行修改的方法,其他方法都與串列一樣
-
字典中的鍵必須是唯一的同時不可變的,值則沒有限制
-
元組中只包含一個元素時,需要在元素後面新增逗號,否則括號會被當作運運算元使用
訪問元組
訪問元組的方式與串列是一致的。 元組的元素可以直接賦值給多個變數,但變數數必須與元素數量一致。
a, b, c = (1, 2, 3)
print(a, b, c)
組合元組
元組中的元素值是不允許修改的,但我們可以對元組進行連線組合
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz')
tup3 = tup1 + tup2;
print (tup3)
# (12, 34.56, 'abc', 'xyz')
刪除元組
元組中的元素值是不允許刪除的,但我們可以使用 del 陳述句來刪除整個元組
元組函式
-
len(tuple) 元組元素個數
-
max(tuple) 元組元素中的最大值
-
min(tuple) 元組元素中的最小值
-
tuple(tuple) 將串列轉換為元組
元組推導式
t = 1, 2, 3
print(t)
# (1, 2, 3)
u = t, (3, 4, 5)
print(u)
# ((1, 2, 3), (3, 4, 5))
字典(dict)
-
字典是另一種可變容器模型,可儲存任意型別物件
-
字典的每個鍵值(key=>value)對用冒號(:)分割,每個對之間用逗號(,)分割,整個字典包括在花括號({})中
-
鍵必須是唯一的,但值則不必
-
值可以是任意資料型別
-
鍵必須是不可變的,例如:數字、字串、元組可以,但串列就不行
-
如果用字典裡沒有的鍵訪問資料,會報錯
-
字典的元素沒有順序,不能透過下標取用元素,透過鍵來取用
-
字典內部存放的順序和 key 放入的順序是沒有關係的
格式如下:
d = {key1 : value1, key2 : value2 }
訪問字典
dis = {'a': 1, 'b': [1, 2, 3]}
print(dis['b'][2])
修改字典
dis = {'a': 1, 'b': [1, 2, 3], 9: {'name': 'hello'}}
dis[9]['name'] = 999
print(dis)
# {'a': 1, 9: {'name': 999}, 'b': [1, 2, 3]}
刪除字典
用 del 陳述句刪除字典或字典的元素。
dis = {'a': 1, 'b': [1, 2, 3], 9: {'name': 'hello'}}
del dis[9]['name']
print(dis)
del dis # 刪除字典
# {'a': 1, 9: {}, 'b': [1, 2, 3]}
字典函式
-
len(dict) 計算字典元素個數,即鍵的總數
-
str(dict) 輸出字典,以可列印的字串表示
-
type(variable) 傳回輸入的變數型別,如果變數是字典就傳回字典型別
-
key in dict 判斷鍵是否存在於字典中
字典方法
-
dict.clear()
-
刪除字典內所有元素
-
dict.copy()
-
傳回一個字典的淺複製
-
dict.fromkeys(seq[, value])
-
建立一個新字典,以序列 seq 中元素做字典的鍵,value 為字典所有鍵對應的初始值
-
dict.get(key, default=None)
-
傳回指定鍵的值,如果值不在字典中傳回預設值
-
dict.items()
-
以串列形式傳回可遍歷的(鍵, 值)元組陣列
-
dict.keys()
-
以串列傳回一個字典所有的鍵
-
dict.values()
-
以串列傳回字典中的所有值
-
dict.setdefault(key, default=None)
-
如果 key 在字典中,傳回對應的值。如果不在字典中,則插入 key 及設定的預設值 default,並傳回 default ,default 預設值為 None。
-
dict.update(dict2)
-
把字典引數 dict2 的鍵/值對更新到字典 dict 裡
dic1 = {'a': 'a'}
dic2 = {9: 9, 'a': 'b'}
dic1.update(dic2)
print(dic1)
# {'a': 'b', 9: 9}
-
dict.pop(key[,default])
-
刪除字典給定鍵 key 所對應的值,傳回值為被刪除的值。key 值必須給出,否則傳回 default 值。
-
dict.popitem()
-
隨機傳回並刪除字典中的一對鍵和值(一般刪除末尾對)
字典推導式
建構式 dict() 直接從鍵值對元組串列中構建字典。如果有固定的樣式,串列推導式指定特定的鍵值對:
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'jack': 4098, 'guido': 4127}
此外,字典推導可以用來建立任意鍵和值的運算式詞典:
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
如果關鍵字只是簡單的字串,使用關鍵字引數指定鍵值對有時候更方便:
>>> dict(sape=4139, guido=4127, jack=4098)
{'sape': 4139, 'jack': 4098, 'guido': 4127}
集合(set)
集合是一個無序不重覆元素的序列
建立集合
-
可以使用大括號 {} 或者 set() 函式建立集合
-
建立一個空集合必須用 set() 而不是 {},因為 {} 是用來建立一個空字典
-
set(value) 方式建立集合,value 可以是字串、串列、元組、字典等序列型別
-
建立、新增、修改等操作,集合會自動去重
{1, 2, 1, 3} # {} {1, 2, 3}
set('12345') # 字串 {'3', '5', '4', '2', '1'}
set([1, 'a', 23.4]) # 串列 {1, 'a', 23.4}
set((1, 'a', 23.4)) # 元組 {1, 'a', 23.4}
set({1:1, 'b': 9}) # 字典 {1, 'b'}
新增元素
將元素 val 新增到集合 set 中,如果元素已存在,則不進行任何操作:
set.add(val)
也可以用 update 方法批次新增元素,引數可以是串列,元組,字典等:
set.update(list1, list2,...)
移除元素
如果存在元素 val 則移除,不存在就報錯:
set.remove(val)
如果存在元素 val 則移除,不存在也不會報錯:
set.discard(val)
隨機移除一個元素:
set.pop()
元素個數
與其他序列一樣,可以用 len(set) 獲取集合的元素個數。
清空集合
set.clear()
set = set()
判斷元素是否存在
val in set
其他方法
-
set.copy()
-
複製集合
-
set.difference(set2)
-
求差集,在 set 中卻不在 set2 中
-
set.intersection(set2)
-
求交集,同時存在於 set 和 set2 中
-
set.union(set2)
-
求並集,所有 set 和 set2 的元素
-
set.symmetric_difference(set2)
-
求對稱差集,不同時出現在兩個集合中的元素
-
set.isdisjoint(set2)
-
如果兩個集合沒有相同的元素,傳回 True
-
set.issubset(set2)
-
如果 set 是 set2 的一個子集,傳回 True
-
set.issuperset(set2)
-
如果 set 是 set2 的一個超集,傳回 True
集合計算
a = set('abracadabra')
b = set('alacazam')
print(a) # a 中唯一的字母
# {'a', 'r', 'b', 'c', 'd'}
print(a - b) # 在 a 中的字母,但不在 b 中
# {'r', 'd', 'b'}
print(a | b) # 在 a 或 b 中的字母
# {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
print(a & b) # 在 a 和 b 中都有的字母
# {'a', 'c'}
print(a ^ b) # 在 a 或 b 中的字母,但不同時在 a 和 b 中
# {'r', 'd', 'b', 'm', 'z', 'l'}
集合推導式
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a)
# {'d', 'r'}
流程控制
if 控制
if 運算式1:
陳述句
if 運算式2:
陳述句
elif 運算式3:
陳述句
else:
陳述句
elif 運算式4:
陳述句
else:
陳述句
1、每個條件後面要使用冒號 :,表示接下來是滿足條件後要執行的陳述句塊。 2、使用縮排來劃分陳述句塊,相同縮排數的陳述句在一起組成一個陳述句塊。 3、在 Python 中沒有 switch – case 陳述句。
三元運運算元:
if else
編寫條件陳述句時,應該儘量避免使用巢狀陳述句。巢狀陳述句不便於閱讀,而且可能會忽略一些可能性。
for 遍歷
for in :
else:
else 陳述句中的陳述句2只有迴圈正常退出(遍歷完所有遍歷物件中的值)時執行。
在字典中遍歷時,關鍵字和對應的值可以使用 items() 方法同時解讀出來:
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
for k, v in knights.items():
print(k, v)
在序列中遍歷時,索引位置和對應值可以使用 enumerate() 函式同時得到:
for i, v in enumerate(['tic', 'tac', 'toe']):
print(i, v)
同時遍歷兩個或更多的序列,可以使用 zip() 組合:
questions = ['name', 'quest', 'favorite color']
answers = ['lancelot', 'the holy grail', 'blue']
for q, a in zip(questions, answers):
print('What is your {0}? It is {1}.'.format(q, a))
要反向遍歷一個序列,首先指定這個序列,然後呼叫 reversed() 函式:
for i in reversed(range(1, 10, 2)):
print(i)
要按順序遍歷一個序列,使用 sorted() 函式傳回一個已排序的序列,並不修改原值:
basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
for f in sorted(set(basket)):
print(f)
while 迴圈
while:
else:
break、continue、pass
break 陳述句用在 while 和 for 迴圈中,break 陳述句用來終止迴圈陳述句,即迴圈條件沒有 False 條件或者序列還沒被完全遞迴完,也會停止執行迴圈陳述句。 continue 陳述句用在 while 和 for 迴圈中,continue 陳述句用來告訴 Python 跳過當前迴圈的剩餘陳述句,然後繼續進行下一輪迴圈。 continue 陳述句跳出本次迴圈,而 break 跳出整個迴圈。
pass 是空陳述句,是為了保持程式結構的完整性。pass 不做任何事情,一般用做佔位陳述句。
迭代器
-
迭代器是一個可以記住遍歷的位置的物件。
-
迭代器物件從集合的第一個元素開始訪問,直到所有的元素被訪問完結束。迭代器只能往前不會後退。
-
迭代器有兩個基本的方法:iter() 和 next()。
-
字串,串列或元組物件都可用於建立迭代器。
迭代器可以被 for 迴圈進行遍歷:
li = [1, 2, 3]
it = iter(li)
for val in it:
print(val)
迭代器也可以用 next() 函式訪問下一個元素值:
import sys
li = [1,2,3,4]
it = iter(li)
while True:
try:
print (next(it))
except StopIteration:
sys.exit()
生成器
-
在 Python 中,使用了 yield 的函式被稱為生成器(generator)。
-
跟普通函式不同的是,生成器是一個傳回迭代器的函式,只能用於迭代操作,更簡單點理解生成器就是一個迭代器。
-
在呼叫生成器執行的過程中,每次遇到 yield 時函式會暫停並儲存當前所有的執行資訊,傳回 yield 的值, 併在下一次執行 next() 方法時從當前位置繼續執行。
-
呼叫一個生成器函式,傳回的是一個迭代器物件。
import sys
def fibonacci(n): # 生成器函式 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一個迭代器,由生成器傳回生成
while True:
try:
print(next(f))
except StopIteration:
sys.exit()
函式
自定義函式
函式(Functions)是指可重覆使用的程式片段。它們允許你為某個程式碼塊賦予名字,允許你透過這一特殊的名字在你的程式任何地方來執行程式碼塊,並可重覆任何次數。這就是所謂的呼叫(Calling)函式。
-
函式程式碼塊以 def 關鍵詞開頭,後接函式識別符號名稱和圓括號 ()。
-
任何傳入引數和自變數必須放在圓括號中間,圓括號之間可以用於定義引數。
-
函式的第一行陳述句可以選擇性地使用檔案字串—用於存放函式說明。
-
函式內容以冒號起始,並且縮排。
-
return [運算式] 結束函式,選擇性地傳回一個值給呼叫方。不帶運算式的 return 相當於傳回 None。
-
return 可以傳回多個值,此時傳回的資料未元組型別。
-
定義引數時,帶預設值的引數必須在無預設值引數的後面。
def 函式名(引數串列):
函式體
引數傳遞
在 Python 中,型別屬於物件,變數是沒有型別的:
a = [1,2,3]
a = "Runoob"
以上程式碼中,[1,2,3] 是 List 型別,”Runoob” 是 String 型別,而變數 a 是沒有型別,她僅僅是一個物件的取用(一個指標),可以是指向 List 型別物件,也可以是指向 String 型別物件。
可更改與不可更改物件
在 Python 中,字串,數字和元組是不可更改的物件,而串列、字典等則是可以修改的物件。
-
不可變型別:變數賦值 a=5 後再賦值 a=10,這裡實際是新生成一個 int 值物件 10,再讓 a 指向它,而 5 被丟棄,不是改變a的值,相當於新生成了a。
-
可變型別:變數賦值 la=[1,2,3,4] 後再賦值 la[2]=5 則是將 list la 的第三個元素值更改,本身la沒有動,只是其內部的一部分值被修改了。
Python 函式的引數傳遞:
-
不可變型別:類似 c++ 的值傳遞,如 整數、字串、元組。如fun(a),傳遞的只是a的值,沒有影響a物件本身。比如在 fun(a)內部修改 a 的值,只是修改另一個複製的物件,不會影響 a 本身。
-
可變型別:類似 c++ 的取用傳遞,如 串列,字典。如 fun(la),則是將 la 真正的傳過去,修改後fun外部的la也會受影響
Python 中一切都是物件,嚴格意義我們不能說值傳遞還是取用傳遞,我們應該說傳不可變物件和傳可變物件。
引數
必需引數
必需引數須以正確的順序傳入函式。呼叫時的數量必須和宣告時的一樣。
關鍵字引數
關鍵字引數和函式呼叫關係緊密,函式呼叫使用關鍵字引數來確定傳入的引數值。 使用關鍵字引數允許函式呼叫時引數的順序與宣告時不一致,因為 Python 直譯器能夠用引數名匹配引數值。
def print_info(name, age):
"列印任何傳入的字串"
print("名字: ", name)
print("年齡: ", age)
return
print_info(age=50, name="john")
預設引數
呼叫函式時,如果沒有傳遞引數,則會使用預設引數。
def print_info(name, age=35):
print ("名字: ", name)
print ("年齡: ", age)
return
print_info(age=50, name="john")
print("------------------------")
print_info(name="john")
不定長引數
-
加了星號 * 的引數會以元組的形式匯入,存放所有未命名的變數引數。
-
如果在函式呼叫時沒有指定引數,它就是一個空元組。我們也可以不向函式傳遞未命名的變數。
def print_info(arg1, *vartuple):
print("輸出: ")
print(arg1)
for var in vartuple:
print (var)
return
print_info(10)
print_info(70, 60, 50)
-
加了兩個星號 ** 的引數會以字典的形式匯入。變數名為鍵,變數值為字典元素值。
def print_info(arg1, **vardict):
print("輸出: ")
print(arg1)
print(vardict)
print_info(1, a=2, b=3)
匿名函式
Python 使用 lambda 來建立匿名函式。
所謂匿名,意即不再使用 def 陳述句這樣標準的形式定義一個函式。
lambda 只是一個運算式,函式體比 def 簡單很多。 lambda 的主體是一個運算式,而不是一個程式碼塊。僅僅能在 lambda 運算式中封裝有限的邏輯進去。 lambda 函式擁有自己的名稱空間,且不能訪問自己引數串列之外或全域性名稱空間裡的引數。 雖然 lambda 函式看起來只能寫一行,卻不等同於 C 或 C++ 的行內函式,後者的目的是呼叫小函式時不佔用棧記憶體從而增加執行效率。
# 語法格式
lambda [arg1 [,arg2,.....argn]]:expression
變數作用域
-
L (Local) 區域性作用域
-
E (Enclosing) 閉包函式外的函式中
-
G (Global) 全域性作用域
-
B (Built-in) 內建作用域
以 L –> E –> G –> B 的規則查詢,即:在區域性找不到,便會去區域性外的區域性找(例如閉包),再找不到就會去全域性找,再者去內建中找。
Python 中只有模組(module),類(class)以及函式(def、lambda)才會引入新的作用域,其它的程式碼塊(如 if/elif/else/、try/except、for/while等)是不會引入新的作用域的,也就是說這些陳述句內定義的變數,外部也可以訪問。
定義在函式內部的變數擁有一個區域性作用域,定義在函式外的擁有全域性作用域。
區域性變數只能在其被宣告的函式內部訪問,而全域性變數可以在整個程式範圍內訪問。呼叫函式時,所有在函式內宣告的變數名稱都將被加入到作用域中。
當內部作用域想修改外部作用域的變數時,就要用到global和nonlocal關鍵字。
num = 1
def fun1():
global num # 需要使用 global 關鍵字宣告
print(num)
num = 123
print(num)
fun1()
如果要修改巢狀作用域(enclosing 作用域,外層非全域性作用域)中的變數則需要 nonlocal 關鍵字。
def outer():
num = 10
def inner():
nonlocal num # nonlocal關鍵字宣告
num = 100
print(num)
inner()
print(num)
outer()
模組
編寫模組有很多種方法,其中最簡單的一種便是建立一個包含函式與變數、以 .py 為字尾的檔案。
另一種方法是使用撰寫 Python 直譯器本身的本地語言來編寫模組。舉例來說,你可以使用 C 語言來撰寫 Python 模組,並且在編譯後,你可以透過標準 Python 直譯器在你的 Python 程式碼中使用它們。
模組是一個包含所有你定義的函式和變數的檔案,其字尾名是.py。模組可以被別的程式引入,以使用該模組中的函式等功能。這也是使用 Python 標準庫的方法。
當直譯器遇到 import 陳述句,如果模組在當前的搜尋路徑就會被匯入。
搜尋路徑是一個直譯器會先進行搜尋的所有目錄的串列。如想要匯入模組,需要把命令放在指令碼的頂端。
一個模組只會被匯入一次,這樣可以防止匯入模組被一遍又一遍地執行。
搜尋路徑被儲存在 sys 模組中的 path 變數。當前目錄指的是程式啟動的目錄。
匯入模組
匯入模組:
import module1[, module2[,... moduleN]]
從模組中匯入一個指定的部分到當前名稱空間中:
from modname import name1[, name2[, ... nameN]]
把一個模組的所有內容全都匯入到當前的名稱空間:
from modname import *
__name__ 屬性
每個模組都有一個 __name__ 屬性,當其值是 ‘__main__’ 時,表明該模組自身在執行,否則是被引入。
一個模組被另一個程式第一次引入時,其主程式將執行。如果我們想在模組被引入時,模組中的某一程式塊不執行,我們可以用 __name__ 屬性來使該程式塊僅在該模組自身執行時執行。
if __name__ == '__main__':
print('程式自身在執行')
else:
print('我來自另一模組')
dir 函式
內建的函式 dir() 可以找到模組內定義的所有名稱。以一個字串串列的形式傳回。
如果沒有給定引數,那麼 dir() 函式會羅列出當前定義的所有名稱。
在 Python 中萬物皆物件,int、str、float、list、tuple等內建資料型別其實也是類,也可以用 dir(int) 檢視 int 包含的所有方法。也可以使用 help(int) 檢視 int 類的幫助資訊。
包
包是一種管理 Python 模組名稱空間的形式,採用”點模組名稱”。
比如一個模組的名稱是 A.B, 那麼他表示一個包 A中的子模組 B 。
就好像使用模組的時候,你不用擔心不同模組之間的全域性變數相互影響一樣,採用點模組名稱這種形式也不用擔心不同庫之間的模組重名的情況。
在匯入一個包的時候,Python 會根據 sys.path 中的目錄來尋找這個包中包含的子目錄。
目錄只有包含一個叫做 __init__.py 的檔案才會被認作是一個包,主要是為了避免一些濫俗的名字(比如叫做 string)不小心的影響搜尋路徑中的有效模組。
最簡單的情況,放一個空的 __init__.py 檔案就可以了。當然這個檔案中也可以包含一些初始化程式碼或者為 __all__ 變數賦值。
第三方模組
-
easy_install 和 pip 都是用來下載安裝 Python 一個公共資源庫 PyPI 的相關資源包的,pip 是 easy_install 的改進版,提供更好的提示資訊,刪除 package 等功能。老版本的 python 中只有 easy_install,沒有pip。
-
easy_install 打包和釋出 Python 包,pip 是包管理。
easy_install 的用法:
-
安裝一個包
easy_install 包名
easy_install "包名 == 包的版本號"
-
升級一個包
easy_install -U "包名 >= 包的版本號"
pip 的用法:
-
安裝一個包
pip install 包名pip install 包名 == 包的版本號
-
升級一個包 (如果不提供version號,升級到最新版本)
pip install —upgrade 包名 >= 包的版本號
-
刪除一個包
pip uninstall 包名
-
已安裝包串列
pip list
面向物件
類與物件是面向物件程式設計的兩個主要方面。一個類(Class)能夠建立一種新的型別(Type),其中物件(Object)就是類的實體(Instance)。可以這樣來類比:你可以擁有型別 int 的變數,也就是說儲存整數的變數是 int 類的實體(物件)。
-
類(Class):用來描述具有相同的屬性和方法的物件的集合。它定義了該集合中每個物件所共有的屬性和方法。物件是類的實體。
-
方法:類中定義的函式。
-
類變數:類變數在整個實體化的物件中是公用的。類變數定義在類中且在函式體之外。類變數通常不作為實體變數使用。
-
資料成員:類變數或者實體變數用於處理類及其實體物件的相關的資料。
-
方法重寫:如果從父類繼承的方法不能滿足子類的需求,可以對其進行改寫,這個過程叫方法的改寫(override),也稱為方法的重寫。
-
實體變數:定義在方法中的變數,只作用於當前實體的類。
-
繼承:即一個派生類(derived class)繼承基類(base class)的欄位和方法。繼承也允許把一個派生類的物件作為一個基類物件對待。例如,有這樣一個設計:一個Dog型別的物件派生自Animal類,這是模擬”是一個(is-a)”關係(例圖,Dog是一個Animal)。
-
實體化:建立一個類的實體,類的具體物件。
-
物件:透過類定義的資料結構實體。物件包括兩個資料成員(類變數和實體變數)和方法。
Python 中的類提供了面向物件程式設計的所有基本功能:類的繼承機制允許多個基類,派生類可以改寫基類中的任何方法,方法中可以呼叫基類中的同名方法。
物件可以包含任意數量和型別的資料。
self
self 表示的是當前實體,代表當前物件的地址。類由 self.__class__ 表示。
self 不是關鍵字,其他名稱也可以替代,但 self 是個通用的標準名稱。
類
類由 class 關鍵字來建立。 類實體化後,可以使用其屬性,實際上,建立一個類之後,可以透過類名訪問其屬性。
物件方法
方法由 def 關鍵字定義,與函式不同的是,方法必須包含引數 self, 且為第一個引數,self 代表的是本類的實體。
類方法
裝飾器 @classmethod 可以將方法標識為類方法。類方法的第一個引數必須為 cls,而不再是 self。
靜態方法
裝飾器 @staticmethod 可以將方法標識為靜態方法。靜態方法的第一個引數不再指定,也就不需要 self 或 cls。
__init__ 方法
__init__ 方法即構造方法,會在類的物件被實體化時先執行,可以將初始化的操作放置到該方法中。
如果重寫了 __init__,實體化子類就不會呼叫父類已經定義的 __init__。
變數
類變數(Class Variable)是共享的(Shared)——它們可以被屬於該類的所有實體訪問。該類變數只擁有一個副本,當任何一個物件對類變數作出改變時,發生的變動將在其它所有實體中都會得到體現。
物件變數(Object variable)由類的每一個獨立的物件或實體所擁有。在這種情況下,每個物件都擁有屬於它自己的欄位的副本,也就是說,它們不會被共享,也不會以任何方式與其它不同實體中的相同名稱的欄位產生關聯。
在 Python 中,變數名類似 __xxx__ 的,也就是以雙下劃線開頭,並且以雙下劃線結尾的,是特殊變數,特殊變數是可以直接訪問的,不是 private 變數,所以,不能用 __name__、__score__ 這樣的變數名。
訪問控制
-
私有屬性
-
__private_attr:兩個下劃線開頭,宣告該屬性為私有,不能在類地外部被使用或直接訪問。
-
私有方法
-
__private_method:兩個下劃線開頭,宣告該方法為私有方法,只能在類的內部呼叫,不能在類地外部呼叫。
我們還認為約定,一個下劃線開頭的屬性或方法為受保護的。比如,_protected_attr、_protected_method。
繼承
類可以繼承,並且支援繼承多個父類。在定義類時,類名後的括號中指定要繼承的父類,多個父類之間用逗號分隔。
子類的實體可以完全訪問所繼承所有父類的非私有屬性和方法。
若是父類中有相同的方法名,而在子類使用時未指定,Python 從左至右搜尋,即方法在子類中未找到時,從左到右查詢父類中是否包含方法。
方法重寫
子類的方法可以重寫父類的方法。重寫的方法引數不強制要求保持一致,不過合理的設計都應該保持一致。
super() 函式可以呼叫父類的一個方法,以多繼承問題。
類的專有方法:
-
__init__: 建構式,在生成物件時呼叫
-
__del__: 解構式,釋放物件時使用
-
__repr__: 列印,轉換
-
__setitem__: 按照索引賦值
-
__getitem__: 按照索引獲取值
-
__len__: 獲得長度
-
__cmp__: 比較運算
-
__call__: 函式呼叫
-
__add__: 加運算
-
__sub__: 減運算
-
__mul__: 乘運算
-
__div__: 除運算
-
__mod__: 求餘運算
-
__pow__: 乘方
類的專有方法也支援多載。
實體
class Person:
"""人員資訊"""
# 姓名(共有屬性)
name = ''
# 年齡(共有屬性)
age = 0
def __init__(self, name='', age=0):
self.name = name
self.age = age
# 多載專有方法: __str__
def __str__(self):
return "這裡多載了 __str__ 專有方法, " + str({'name': self.name, 'age': self.age})
def set_age(self, age):
self.age = age
class Account:
"""賬戶資訊"""
# 賬戶餘額(私有屬性)
__balance = 0
# 所有賬戶總額
__total_balance = 0
# 獲取賬戶餘額
# self 必須是方法的第一個引數
def balance(self):
return self.__balance
# 增加賬戶餘額
def balance_add(self, cost):
# self 訪問的是本實體
self.__balance += cost
# self.__class__ 可以訪問類
self.__class__.__total_balance += cost
# 類方法(用 @classmethod 標識,第一個引數為 cls)
@classmethod
def total_balance(cls):
return cls.__total_balance
# 靜態方法(用 @staticmethod 標識,不需要類引數或實體引數)
@staticmethod
def exchange(a, b):
return b, a
class Teacher(Person, Account):
"""教師"""
# 班級名稱
_class_name = ''
def __init__(self, name):
# 第一種多載父類__init__()構造方法
# super(子類,self).__init__(引數1,引數2,....)
super(Teacher, self).__init__(name)
def get_info(self):
# 以字典的形式傳回個人資訊
return {
'name': self.name, # 此處訪問的是父類Person的屬性值
'age': self.age,
'class_name': self._class_name,
'balance': self.balance(), # 此處呼叫的是子類多載過的方法
}
# 方法多載
def balance(self):
# Account.__balance 為私有屬性,子類無法訪問,所以父類提供方法進行訪問
return Account.balance(self) * 1.1
class Student(Person, Account):
"""學生"""
_teacher_name = ''
def __init__(self, name, age=18):
# 第二種多載父類__init__()構造方法
# 父類名稱.__init__(self,引數1,引數2,...)
Person.__init__(self, name, age)
def get_info(self):
# 以字典的形式傳回個人資訊
return {
'name': self.name, # 此處訪問的是父類Person的屬性值
'age': self.age,
'teacher_name': self._teacher_name,
'balance': self.balance(),
}
# 教師 John
john = Teacher('John')
john.balance_add(20)
john.set_age(36) # 子類的實體可以直接呼叫父類的方法
print("John's info:", john.get_info())
# 學生 Mary
mary = Student('Mary', 18)
mary.balance_add(18)
print("Mary's info:", mary.get_info())
# 學生 Fake
fake = Student('Fake')
fake.balance_add(30)
print("Fake's info", fake.get_info())
# 三種不同的方式呼叫靜態方法
print("john.exchange('a', 'b'):", john.exchange('a', 'b'))
print('Teacher.exchange(1, 2)', Teacher.exchange(1, 2))
print('Account.exchange(10, 20):', Account.exchange(10, 20))
# 類方法、類屬性
print('Account.total_balance():', Account.total_balance())
print('Teacher.total_balance():', Teacher.total_balance())
print('Student.total_balance():', Student.total_balance())
# 多載專有方法
print(fake)
輸出:
John's info: {'name': 'John', 'age': 36, 'class_name': '', 'balance': 22.0}Mary's info: {'name': 'Mary', 'age': 18, 'teacher_name': '', 'balance': 18}Fake's info {'name': 'Fake', 'age': 18, 'teacher_name': '', 'balance': 30}john.exchange('a', 'b'): ('b', 'a')Teacher.exchange(1, 2) (2, 1)Account.exchange(10, 20): (20, 10)Account.total_balance(): 0Teacher.total_balance(): 20Student.total_balance(): 48這裡多載了 __str__ 專有方法, {'name': 'Fake', 'age': 18}
錯誤和異常
語法錯誤
SyntaxError 類表示語法錯誤,當直譯器發現程式碼無法透過語法檢查時會觸發的錯誤。語法錯誤是無法用 try…except…捕獲的。
>>> print:
File "", line 1
print:
^
SyntaxError: invalid syntax
異常
即便程式的語法是正確的,在執行它的時候,也有可能發生錯誤。執行時發生的錯誤被稱為異常。 錯誤資訊的前面部分顯示了異常發生的背景關係,並以呼叫棧的形式顯示具體資訊。
>>> 1 + '0'
Traceback (most recent call last):
File "", line 1, in
TypeError: unsupported operand type(s) for +: 'int' and 'str'
異常處理
Python 提供了 try … except … 的語法結構來捕獲和處理異常。
try 陳述句執行流程大致如下:

-
首先,執行 try 子句(在關鍵字 try 和關鍵字 except 之間的陳述句)
-
如果沒有異常發生,忽略 except 子句,try 子句執行後結束。
-
如果在執行 try 子句的過程中發生了異常,那麼 try 子句餘下的部分將被忽略。如果異常的型別和 except 之後的名稱相符,那麼對應的 except 子句將被執行。最後執行 try 陳述句之後的程式碼。
-
如果一個異常沒有與任何的 except 匹配,那麼這個異常將會傳遞給上層的 try 中。
-
一個 try 陳述句可能包含多個 except 子句,分別來處理不同的特定的異常。
-
最多隻有一個 except 子句會被執行。
-
處理程式將只針對對應的 try 子句中的異常進行處理,而不是其他的 try 的處理程式中的異常。
-
一個 except 子句可以同時處理多個異常,這些異常將被放在一個括號裡成為一個元組。
-
最後一個 except 子句可以忽略異常的名稱,它將被當作萬用字元使用。可以使用這種方法列印一個錯誤資訊,然後再次把異常丟擲。
-
try except 陳述句還有一個可選的 else 子句,如果使用這個子句,那麼必須放在所有的 except 子句之後。這個子句將在 try 子句沒有發生任何異常的時候執行。
-
異常處理並不僅僅處理那些直接發生在 try 子句中的異常,而且還能處理子句中呼叫的函式(甚至間接呼叫的函式)裡丟擲的異常。
-
不管 try 子句裡面有沒有發生異常,finally 子句都會執行。
-
如果一個異常在 try 子句裡(或者在 except 和 else 子句裡)被丟擲,而又沒有任何的 except 把它截住,那麼這個異常會在 finally 子句執行後再次被丟擲。
丟擲異常
使用 raise 陳述句丟擲一個指定的異常。
raise 唯一的一個引數指定了要被丟擲的異常。它必須是一個異常的實體或者是異常的類(也就是 Exception 的子類)。
如果你只想知道這是否丟擲了一個異常,並不想去處理它,那麼一個簡單的 raise 陳述句就可以再次把它丟擲。
自定義異常
可以透過建立一個新的異常類來擁有自己的異常。異常類繼承自 Exception 類,可以直接繼承,或者間接繼承。
當建立一個模組有可能丟擲多種不同的異常時,一種通常的做法是為這個包建立一個基礎異常類,然後基於這個基礎類為不同的錯誤情況建立不同的子類。
大多數的異常的名字都以”Error”結尾,就跟標準的異常命名一樣。
實體
import sys
class Error(Exception):
"""Base class for exceptions in this module."""
pass
# 自定義異常
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
try:
print('code start running...')
raise InputError('input()', 'input error')
# ValueError
int('a')
# TypeError
s = 1 + 'a'
dit = {'name': 'john'}
# KeyError
print(dit['1'])
except InputError as ex:
print("InputError:", ex.message)
except TypeError as ex:
print('TypeError:', ex.args)
pass
except (KeyError, IndexError) as ex:
"""支援同時處理多個異常, 用括號放到元組裡"""
print(sys.exc_info())
except:
"""捕獲其他未指定的異常"""
print("Unexpected error:", sys.exc_info()[0])
# raise 用於丟擲異常
raise RuntimeError('RuntimeError')
else:
"""當無任何異常時, 會執行 else 子句"""
print('"else" 子句...')
finally:
"""無論有無異常, 均會執行 finally"""
print('finally, ending')
檔案操作
開啟檔案
open() 函式用於開啟/建立一個檔案,並傳回一個 file 物件:
open(filename, mode)
-
filename:包含了你要訪問的檔案名稱的字串值
-
mode:決定了開啟檔案的樣式:只讀,寫入,追加等
檔案開啟樣式:

檔案物件方法
-
fileObject.close()
-
close() 方法用於關閉一個已開啟的檔案。關閉後的檔案不能再進行讀寫操作,否則會觸發 ValueError 錯誤。 close() 方法允許呼叫多次。
-
當 file 物件,被取用到操作另外一個檔案時,Python 會自動關閉之前的 file 物件。 使用 close() 方法關閉檔案是一個好的習慣。
-
fileObject.flush()
-
flush() 方法是用來掃清緩衝區的,即將緩衝區中的資料立刻寫入檔案,同時清空緩衝區,不需要是被動的等待輸出緩衝區寫入。
-
一般情況下,檔案關閉後會自動掃清緩衝區,但有時你需要在關閉前掃清它,這時就可以使用 flush() 方法。
-
fileObject.fileno()
-
fileno() 方法傳回一個整型的檔案描述符(file descriptor FD 整型),可用於底層作業系統的 I/O 操作。
-
fileObject.isatty()
-
isatty() 方法檢測檔案是否連線到一個終端裝置,如果是傳回 True,否則傳回 False。
-
next(iterator[,default])
-
Python 3 中的 File 物件不支援 next() 方法。 Python 3 的內建函式 next() 透過迭代器呼叫 __next__() 方法傳回下一項。在迴圈中,next() 函式會在每次迴圈中呼叫,該方法傳回檔案的下一行,如果到達結尾(EOF),則觸發 StopIteration。
-
fileObject.read()
-
read() 方法用於從檔案讀取指定的位元組數,如果未給定或為負則讀取所有。
-
fileObject.readline()
-
readline() 方法用於從檔案讀取整行,包括 “ ” 字元。如果指定了一個非負數的引數,則傳回指定大小的位元組數,包括 “ ” 字元。
-
fileObject.readlines()
-
readlines() 方法用於讀取所有行(直到結束符 EOF)並傳回串列,該串列可以由 Python 的 for… in … 結構進行處理。如果碰到結束符 EOF,則傳回空字串。
-
fileObject.seek(offset[, whence])
-
seek() 方法用於移動檔案讀取指標到指定位置。
-
whence 的值, 如果是 0 表示開頭, 如果是 1 表示當前位置, 2 表示檔案的結尾。whence 值為預設為0,即檔案開頭。例如:
-
seek(x, 0):從起始位置即檔案首行首字元開始移動 x 個字元
-
seek(x, 1):表示從當前位置往後移動 x 個字元
-
seek(-x, 2):表示從檔案的結尾往前移動 x 個字元
-
fileObject.tell(offset[, whence])
-
tell() 方法傳回檔案的當前位置,即檔案指標當前位置。
-
fileObject.truncate([size])
-
truncate() 方法用於從檔案的首行首字元開始截斷,截斷檔案為 size 個字元,無 size 表示從當前位置截斷;截斷之後 V 後面的所有字元被刪除,其中 Widnows 系統下的換行代表2個字元大小。
-
fileObject.write([str])
-
write() 方法用於向檔案中寫入指定字串。
-
在檔案關閉前或緩衝區掃清前,字串內容儲存在緩衝區中,這時你在檔案中是看不到寫入的內容的。
-
如果檔案開啟樣式帶 b,那寫入檔案內容時,str (引數)要用 encode 方法轉為 bytes 形式,否則報錯:TypeError: a bytes-like object is required, not ‘str’。
-
fileObject.writelines([str])
-
writelines() 方法用於向檔案中寫入一序列的字串。這一序列字串可以是由迭代物件產生的,如一個字串串列。換行需要指定換行符 。
實體
filename = 'data.log'
# 開啟檔案(a+ 追加讀寫樣式)
# 用 with 關鍵字的方式開啟檔案,會自動關閉檔案資源
with open(filename, 'w+', encoding='utf-8') as file:
print('檔案名稱: {}'.format(file.name))
print('檔案編碼: {}'.format(file.encoding))
print('檔案開啟樣式: {}'.format(file.mode))
print('檔案是否可讀: {}'.format(file.readable()))
print('檔案是否可寫: {}'.format(file.writable()))
print('此時檔案指標位置為: {}'.format(file.tell()))
# 寫入內容
num = file.write("第一行內容
")
print('寫入檔案 {} 個字元'.format(num))
# 檔案指標在檔案尾部,故無內容
print(file.readline(), file.tell())
# 改變檔案指標到檔案頭部
file.seek(0)
# 改變檔案指標後,讀取到第一行內容
print(file.readline(), file.tell())
# 但檔案指標的改變,卻不會影響到寫入的位置
file.write('第二次寫入的內容
')
# 檔案指標又回到了檔案尾
print(file.readline(), file.tell())
# file.read() 從當前檔案指標位置讀取指定長度的字元
file.seek(0)
print(file.read(9))
# 按行分割檔案,傳回字串串列
file.seek(0)
print(file.readlines())
# 迭代檔案物件,一行一個元素
file.seek(0)
for line in file:
print(line, end='')
# 關閉檔案資源
if not file.closed:
file.close()
輸出:
檔案名稱: data.log
檔案編碼: utf-8
檔案開啟樣式: w+
檔案是否可讀: True
檔案是否可寫: True
此時檔案指標位置為: 0
寫入檔案 6 個字元
16
第一行內容
16
41
第一行內容
第二次
['第一行內容
', '第二次寫入的內容
']
第一行內容
第二次寫入的內容
序列化
在 Python 中 pickle 模組實現對資料的序列化和反序列化。pickle 支援任何資料型別,包括內建資料型別、函式、類、物件等。
方法
dump
將資料物件序列化後寫入檔案
pickle.dump(obj, file, protocol=None, fix_imports=True)
必填引數 obj 表示將要封裝的物件。 必填引數 file 表示 obj 要寫入的檔案物件,file 必須以二進位制可寫樣式開啟,即wb。 可選引數 protocol 表示告知 pickle 使用的協議,支援的協議有 0,1,2,3,預設的協議是新增在 Python 3 中的協議3。
load
從檔案中讀取內容並反序列化
pickle.load(file, fix_imports=True, encoding='ASCII', errors='strict')
必填引數 file 必須以二進位制可讀樣式開啟,即rb,其他都為可選引數。
dumps
以位元組物件形式傳回封裝的物件,不需要寫入檔案中
pickle.dumps(obj, protocol=None, fix_imports=True)
loads
從位元組物件中讀取被封裝的物件,並傳回
pickle.loads(bytes_object, fix_imports=True, encoding='ASCII', errors='strict')
實體
import pickle
data = [1, 2, 3]
# 序列化資料並以位元組物件傳回
dumps_obj = pickle.dumps(data)
print('pickle.dumps():', dumps_obj)
# 從位元組物件中反序列化資料
loads_data = pickle.loads(dumps_obj)
print('pickle.loads():', loads_data)
filename = 'data.log'
# 序列化資料到檔案中
with open(filename, 'wb') as file:
pickle.dump(data, file)
# 從檔案中載入並反序列化
with open(filename, 'rb') as file:
load_data = pickle.load(file)
print('pickle.load():', load_data)
輸出:
pickle.dumps(): b'€]q(KKKe.'
pickle.loads(): [1, 2, 3]
pickle.load(): [1, 2, 3]
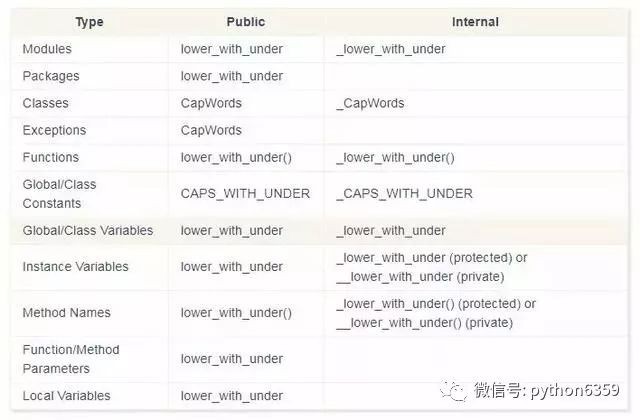
命名規範
Python 之父 Guido 推薦的規範