今天寫爬蟲偶然想到了初學正則運算式時候,看過一篇文章非常不錯。檢索一下還真的找到了。

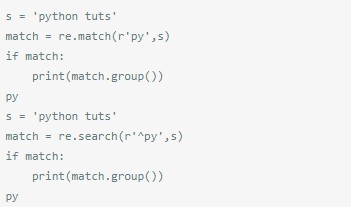
經常用match = re.search(pat, str)的形式。因為有可能匹配不到,所以re.search()後面一般用if statement。

re.match和re.search很相似,只是re.match是從字串的開頭開始匹配。
-
a, X, 9,等字元匹配自己, 元字元不匹配自己,因為有特殊意義,比如 . ^ $ * + ? { }[ ] \ | ( )
-
. 英文句號,匹配任意字元,不包含’\n’
-
\w 匹配’word’字元,[a-zA-Z0-9]
-
\W 匹配非’word’字元
-
\b 匹配’word’和’non-word’之間邊界
-
\s 匹配單個whitespace字元,space, newline, return, tab, form [\n\r\t\f]
-
\S 匹配non-whitespace字元
-
\t, \n, \r 匹配tab, newline, return
-
\d 匹配數字[0-9]
-
^ 匹配字串開頭
-
$ 匹配字串結尾
‘+’ 一或多次, ‘*’ 零或多次, ‘?’ 零或一次

[]類似於or
Square brackets can be used to indicate a set of chars, so [abc] matches ‘a’ or ‘b’ or ‘c’.

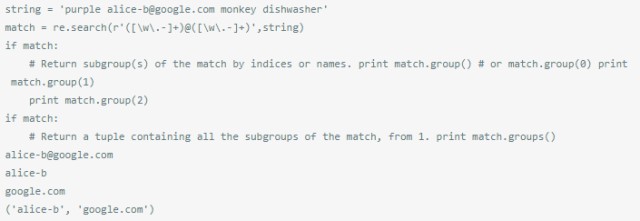
有時候需要提取匹配字元的一部分,比如剛才的郵箱,我們可能需要其中的username和hostname,這時候可以用()分別把username和hostname包起來,就像r'([\w.-]+)@([\w.-]+)’,如果匹配成功,那麼pattern不改變,只是可以用match.group(1)和match.group(2)來username和hostname,match.group()結果不變。
()和findall()結合,如果包括一或多個group,就傳回a list of tuples。
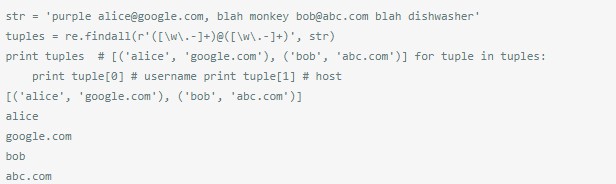
給re.search加^之後是一樣的。
re.sub
re.sub(pat, replacement, str)在str裡尋找和pattern匹配的字串,然後用replacement替換。replacement可以包含\1或者\2來代替相應的group,然後實現區域性替換。

作者:米樂果果
來源:http://www.jianshu.com/p/922e9e56b017
《Linux雲端計算及運維架構師高薪實戰班》2018年11月26日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –