
當專案上升到一定境界時候,需要同時抓取幾百個甚至上千個網站,這個時候,單個的爬蟲已經滿足不了需求。比如我們日常用的百度,它每天都會爬取大量的網站,一臺伺服器肯定是不夠用的。所以需要各個地方的伺服器一起協同工作。
本章知識點:
a.scrapy-redis簡介
b.開始專案前的準備
一、Scrapy-Redis 簡介
scrapy-redis是一個基於redis資料庫的scrapy元件,它提供了四種元件,透過它,可以快速實現簡單分散式爬蟲程式。
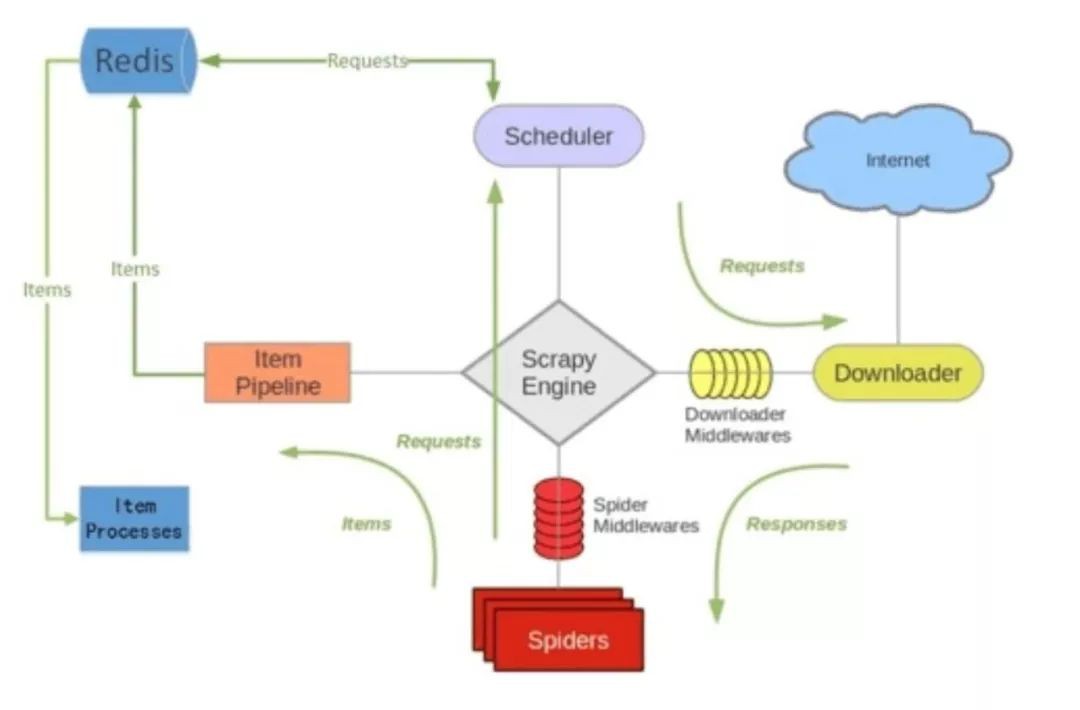
scrapy-redis元件 :
1、Scheduler(排程):Scrapy改造了python本來的collection.deque(雙向佇列)形成了自己Scrapy queue,而scrapy-redis 的解決是把這個Scrapy queue換成redis資料庫,從同一個redis-server存放要爬取的request,便能讓多個spider去同一個資料庫裡讀取。Scheduler負責對新的request進行入列操作(加入Scrapy queue),取出下一個要爬取的request(從Scrapy queue中取出)等操作。
2、Duplication Filter(去重):Scrapy中用集合實現這個request去重功能,Scrapy中把已經傳送的request指紋放入到一個集合中,把下一個request的指紋拿到集合中比對,如果該指紋存在於集合中,說明這個request傳送過了,如果沒有則繼續操作。
3、Item Pipline(管道):引擎將(Spider傳回的)爬取到的Item給Item Pipeline,scrapy-redis 的Item Pipeline將爬取到的 Item 存⼊redis的 items queue。
4、Base Spider(爬蟲):不再使用scrapy原有的Spider類,重寫的RedisSpider繼承了Spider和RedisMixin這兩個類,RedisMixin是用來從redis讀取url的類。
專案地址:
https://github.com/rmax/scrapy-redis
二、Scrapy-Redis 工作機制
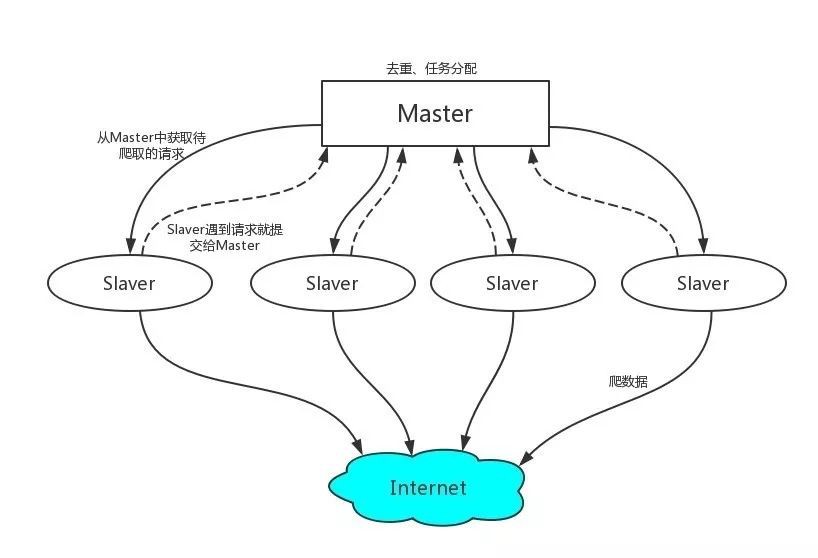
1、首先Slaver端從Master端拿任務(Request、url)進行資料抓取,Slaver抓取資料的同時,產生新任務的Request便提交給 Master 處理;
2、Master端只有一個Redis資料庫,負責將未處理的Request去重和任務分配,將處理後的Request加入待爬佇列,並且儲存爬取的資料。
三、開始專案前的準備
1、Redis配置安裝:
工欲善其事必先利其器,既然是基於redis的服務,當然首先要安裝redis了。
安裝Redis伺服器端
sudo apt-get install redis-server
修改配置檔案 redis.conf
sudo nano /etc/redis/redis.conf
將bind 127.0.0.1註釋掉。這樣Slave端才能遠端連線到Master端的Redis資料庫。
將Ubuntu作為Master端,Windows10和Windows7作為Slaver端,在Master中開啟redis-service服務。Slaver端也需要有redis。
redis-server
Slaver連線測試:
redis-cli -h MasterIP地址

至此,redis已經安裝完成。
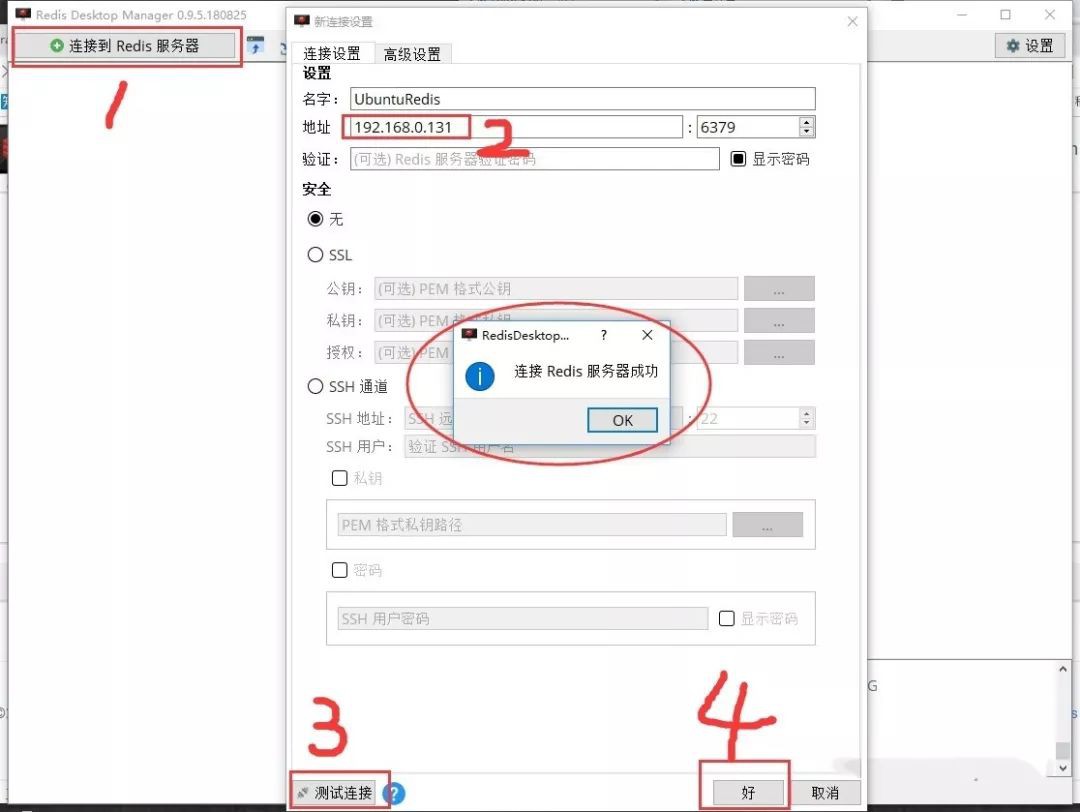
Redis視覺化管理工具-Redis Desktop Manager
下載地址:
https://redisdesktop.com/download
配置方法:
2、獲取自己的ip代理池
很多網站都有反爬蟲機制,只用一個ip去頻繁訪問網站的話,很容易引起網站管理員的註意,如果管理員將這個ip加入黑名單,那麼這個爬蟲就廢掉了。所以,想要做大型的爬蟲的話,基本上是必須要面對ip的問題。
那麼問題來了,我們去哪裡搞代理ip呢??第一種方法就是買買買!!沒有什麼事情是用錢解決不了的,如果有,那就加倍。
當然,網上也有一堆免費的ip代理,但是,免費的質量參差不齊,所以就需要進行篩選。以西刺代理為例:用爬蟲爬取國內的高匿代理IP,併進行驗證。(只爬取前五頁,後面的失效太多,沒有必要去驗證了。)
爬蟲:
class XiciSpider(scrapy.Spider):
name = 'xici'
allowed_domains = ['xicidaili.com']
start_urls = []
for i in range(1, 6):
start_urls.append('http://www.xicidaili.com/nn/' + str(i))
def parse(self, response):
ip = response.xpath('//tr[@class]/td[2]/text()').extract()
port = response.xpath('//tr[@class]/td[3]/text()').extract()
agreement_type = response.xpath('//tr[@class]/td[6]/text()').extract()
proxies = zip(ip, port, agreement_type)
# print(proxies)
# 驗證代理是否可用
for ip, port, agreement_type in proxies:
proxy = {'http': agreement_type.lower() + '://' + ip + ':' + port,
'https': agreement_type.lower() + '://' + ip + ':' + port}
try:
# 設定代理連結 如果狀態碼為200 則表示該代理可以使用
print(proxy)
resp = requests.get('http://icanhazip.com', proxies=proxy, timeout=2)
print(resp.status_code)
if resp.status_code == 200:
print(resp.text)
# print('success %s' % ip)
item = DailiItem()
item['proxy'] = proxy
yield item
except:
print('fail %s' % ip)
Pipeline:
class DailiPipeline(object):
def __init__(self):
self.file = open('proxy.txt', 'w')
def process_item(self, item, spider):
self.file.write(str(item['proxy']) + '\n')
return item
def close_spider(self, spider):
self.file.close()
執行結果:

爬了500條資料,只有四條可以用………
本章專案地址:
https://github.com/ZhiqiKou/Scrapy_notes本文作者
Zhiqi Kou,一個嚮往成為真正程式員的碼奴。
地址:zhihu.com/people/zhiqi-kou
《Linux雲端計算及運維架構師高薪實戰班》2018年11月26日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


