
https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast
作者 | Dave Cheney
譯者 | Baron Hou (houbaron) ?共計翻譯:1.0 篇 貢獻時間:2 天
Anthony Starks 使用他出色的 Deck 演示工具重構了我原來的基於 Google Slides 的幻燈片。你可以在他的部落格上檢視他重構後的幻燈片,
mindchunk.blogspot.com.au/2014/06/remixing-with-deck[1]。
我最近被邀請在 Gocon 發表演講,這是一個每半年在日本東京舉行的 Go 的精彩大會。Gocon 2014[2] 是一個完全由社群驅動的為期一天的活動,由培訓和一整個下午的圍繞著生產環境中的 Go 這個主題的演講組成.(LCTT 譯註:本文發表於 2014 年)
以下是我的講義。原文的結構能讓我緩慢而清晰的演講,因此我已經編輯了它使其更可讀。
我要感謝 Bill Kennedy[3] 和 Minux Ma,特別是 Josh Bleecher Snyder[4],感謝他們在我準備這次演講中的幫助。
大家下午好。
我叫 David.
我很高興今天能來到 Gocon。我想參加這個會議已經兩年了,我很感謝主辦方能提供給我向你們演講的機會。
Gocon 2014
我想以一個問題開始我的演講。
為什麼選擇 Go?
當大家討論學習或在生產環境中使用 Go 的原因時,答案不一而足,但因為以下三個原因的最多。

Gocon 2014
這就是 TOP3 的原因。
第一,併發。
Go 的 併發原語 對於來自 Nodejs,Ruby 或 Python 等單執行緒指令碼語言的程式員,或者來自 C++ 或 Java 等重量級執行緒模型的語言都很有吸引力。
易於部署。
我們今天從經驗豐富的 Gophers 那裡聽說過,他們非常欣賞部署 Go 應用的簡單性。
Gocon 2014
然後是效能。
我相信人們選擇 Go 的一個重要原因是它 快。

Gocon 2014 (4)
在今天的演講中,我想討論五個有助於提高 Go 效能的特性。
我還將與大家分享 Go 如何實現這些特性的細節。

Gocon 2014 (5)
我要談的第一個特性是 Go 對於值的高效處理和儲存。

Gocon 2014 (6)
這是 Go 中一個值的例子。編譯時,gocon 正好消耗四個位元組的記憶體。
讓我們將 Go 與其他一些語言進行比較

Gocon 2014 (7)
由於 Python 表示變數的方式的開銷,使用 Python 儲存相同的值會消耗六倍的記憶體。
Python 使用額外的記憶體來跟蹤型別資訊,進行 取用計數 等。
讓我們看另一個例子:

Gocon 2014 (8)
與 Go 類似,Java 消耗 4 個位元組的記憶體來儲存 int 型。
但是,要在像 List 或 Map 這樣的集合中使用此值,編譯器必須將其轉換為 Integer 物件。

Gocon 2014 (9)
因此,Java 中的整數通常消耗 16 到 24 個位元組的記憶體。
為什麼這很重要? 記憶體便宜且充足,為什麼這個開銷很重要?
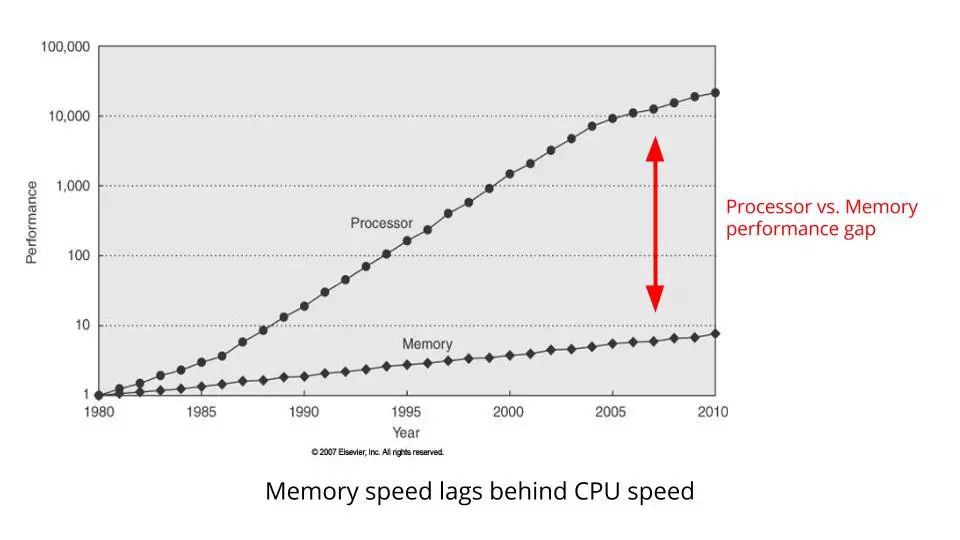
Gocon 2014 (10)
這是一張顯示 CPU 時鐘速度與記憶體匯流排速度的圖表。
請註意 CPU 時鐘速度和記憶體匯流排速度之間的差距如何繼續擴大。
兩者之間的差異實際上是 CPU 花費多少時間等待記憶體。

Gocon 2014 (11)
自 1960 年代後期以來,CPU 設計師已經意識到了這個問題。
他們的解決方案是一個快取,一個更小、更快的記憶體區域,介入 CPU 和主存之間。

Gocon 2014 (12)
這是一個 Location 型別,它儲存物體在三維空間中的位置。它是用 Go 編寫的,因此每個 Location 只消耗 24 個位元組的儲存空間。
我們可以使用這種型別來構造一個容納 1000 個 Location 的陣列型別,它只消耗 24000 位元組的記憶體。
在陣列內部,Location 結構體是順序儲存的,而不是隨機儲存的 1000 個 Location 結構體的指標。
這很重要,因為現在所有 1000 個 Location 結構體都按順序放在快取中,緊密排列在一起。

Gocon 2014 (13)
Go 允許您建立緊湊的資料結構,避免不必要的填充位元組。
緊湊的資料結構能更好地利用快取。
更好的快取利用率可帶來更好的效能。

Gocon 2014 (14)
函式呼叫不是無開銷的。

Gocon 2014 (15)
呼叫函式時會發生三件事。
建立一個新的 棧幀,並記錄呼叫者的詳細資訊。
在函式呼叫期間可能被改寫的任何暫存器都將儲存到棧中。
處理器計算函式的地址並執行到該新地址的分支。

Gocon 2014 (16)
由於函式呼叫是非常常見的操作,因此 CPU 設計師一直在努力最佳化此過程,但他們無法消除開銷。
函調固有開銷,或重於泰山,或輕於鴻毛,這取決於函式做了什麼。
減少函式呼叫開銷的解決方案是 行內。

Gocon 2014 (17)
Go 編譯器透過將函式體視為呼叫者的一部分來行內函式。
行內也有成本,它增加了二進位制檔案大小。
只有當呼叫開銷與函式所做工作關聯度的很大時行內才有意義,因此只有簡單的函式才能用於行內。
複雜的函式通常不受呼叫它們的開銷所支配,因此不會行內。

Gocon 2014 (18)
這個例子顯示函式 Double 呼叫 util.Max。
為了減少呼叫 util.Max 的開銷,編譯器可以將 util.Max 行內到 Double 中,就象這樣

Gocon 2014 (19)
行內後不再呼叫 util.Max,但是 Double 的行為沒有改變。
行內並不是 Go 獨有的。幾乎每種編譯或及時編譯的語言都執行此最佳化。但是 Go 的行內是如何實現的?
Go 實現非常簡單。編譯包時,會標記任何適合行內的小函式,然後照常編譯。
然後函式的原始碼和編譯後版本都會被儲存。

Gocon 2014 (20)
此幻燈片顯示了 util.a 的內容。原始碼已經過一些轉換,以便編譯器更容易快速處理。
當編譯器編譯 Double 時,它看到 util.Max 可行內的,並且 util.Max 的原始碼是可用的。
就會替換原函式中的程式碼,而不是插入對 util.Max 的編譯版本的呼叫。
擁有該函式的原始碼可以實現其他最佳化。

Gocon 2014 (21)
在這個例子中,儘管函式 Test 總是傳回 false,但 Expensive 在不執行它的情況下無法知道結果。
當 Test 被行內時,我們得到這樣的東西。

Gocon 2014 (22)
編譯器現在知道 Expensive 的程式碼無法訪問。
這不僅節省了呼叫 Test 的成本,還節省了編譯或執行任何現在無法訪問的 Expensive 程式碼。
Go 編譯器可以跨檔案甚至跨包自動行內函式。還包括從標準庫呼叫的可行內函式的程式碼。

Gocon 2014 (23)
強制垃圾回收 使 Go 成為一種更簡單,更安全的語言。
這並不意味著垃圾回收會使 Go 變慢,或者垃圾回收是程式速度的瓶頸。
這意味著在堆上分配的記憶體是有代價的。每次 GC 執行時都會花費 CPU 時間,直到釋放記憶體為止。

Gocon 2014 (24)
然而,有另一個地方分配記憶體,那就是棧。
與 C 不同,它強制您選擇是否將值透過 malloc 將其儲存在堆上,還是透過在函式範圍內宣告將其儲存在棧上;Go 實現了一個名為 逃逸分析 的最佳化。

Gocon 2014 (25)
逃逸分析決定了對一個值的任何取用是否會從被宣告的函式中逃逸。
如果沒有取用逃逸,則該值可以安全地儲存在棧中。
儲存在棧中的值不需要分配或釋放。
讓我們看一些例子

Gocon 2014 (26)
Sum 傳回 1 到 100 的整數的和。這是一種相當不尋常的做法,但它說明瞭逃逸分析的工作原理。
因為切片 numbers 僅在 Sum 內取用,所以編譯器將安排到棧上來儲存的 100 個整數,而不是安排到堆上。
沒有必要回收 numbers,它會在 Sum 傳回時自動釋放。

Gocon 2014 (27)
第二個例子也有點尬。在 CenterCursor 中,我們建立一個新的 Cursor 物件併在 c 中儲存指向它的指標。
然後我們將 c 傳遞給 Center() 函式,它將 Cursor 移動到螢幕的中心。
最後我們打印出那個 ‘Cursor` 的 X 和 Y 坐標。
即使 c 被 new 函式分配了空間,它也不會儲存在堆上,因為沒有取用 c 的變數逃逸 CenterCursor 函式。

Gocon 2014 (28)
預設情況下,Go 的最佳化始終處於啟用狀態。可以使用 -gcflags = -m 開關檢視編譯器的逃逸分析和行內決策。
因為逃逸分析是在編譯時執行的,而不是執行時,所以無論垃圾回收的效率如何,棧分配總是比堆分配快。
我將在本演講的其餘部分詳細討論棧。

Gocon 2014 (30)
Go 有 goroutine。 這是 Go 併發的基石。
我想退一步,探索 goroutine 的歷史。
最初,計算機一次執行一個行程。在 60 年代,多行程或 分時 的想法變得流行起來。
在分時系統中,作業系統必須透過保護當前行程的現場,然後恢復另一個行程的現場,不斷地在這些行程之間切換 CPU 的註意力。
這稱為 行程切換。

Gocon 2014 (29)
行程切換有三個主要開銷。
首先,核心需要保護該行程的所有 CPU 暫存器的現場,然後恢復另一個行程的現場。
核心還需要將 CPU 的對映從虛擬記憶體掃清到物理記憶體,因為這些對映僅對當前行程有效。
最後是作業系統 背景關係切換 的成本,以及 排程函式 選擇佔用 CPU 的下一個行程的開銷。

Gocon 2014 (31)
現代處理器中有數量驚人的暫存器。我很難在一張幻燈片上排開它們,這可以讓你知道保護和恢復它們需要多少時間。
由於行程切換可以在行程執行的任何時刻發生,因此作業系統需要儲存所有暫存器的內容,因為它不知道當前正在使用哪些暫存器。

Gocon 2014 (32)
這導致了執行緒的出生,這些執行緒在概念上與行程相同,但共享相同的記憶體空間。
由於執行緒共享地址空間,因此它們比行程更輕,因此建立速度更快,切換速度更快。

Gocon 2014 (33)
Goroutine 升華了執行緒的思想。
Goroutine 是 協作式排程的,而不是依靠核心來排程。
當對 Go 執行時排程器 進行顯式呼叫時,goroutine 之間的切換僅發生在明確定義的點上。
編譯器知道正在使用的暫存器並自動儲存它們。

Gocon 2014 (34)
雖然 goroutine 是協作式排程的,但執行時會為你處理。
Goroutine 可能會給禪讓給其他協程時刻是:

Gocon 2014 (35)
這個例子說明瞭上一張幻燈片中描述的一些排程點。
箭頭所示的執行緒從左側的 ReadFile 函式開始。遇到 os.Open,它在等待檔案操作完成時阻塞執行緒,因此排程器將執行緒切換到右側的 goroutine。
繼續執行直到從通道 c 中讀,並且此時 os.Open 呼叫已完成,因此排程器將執行緒切換回左側並繼續執行 file.Read 函式,然後又被檔案 IO 阻塞。
排程器將執行緒切換回右側以進行另一個通道操作,該操作在左側執行期間已解鎖,但在通道傳送時再次阻塞。
最後,當 Read 操作完成並且資料可用時,執行緒切換回左側。

Gocon 2014 (36)
這張幻燈片顯示了低階語言描述的 runtime.Syscall 函式,它是 os 包中所有函式的基礎。
只要你的程式碼呼叫作業系統,就會透過此函式。
對 entersyscall 的呼叫通知執行時該執行緒即將阻塞。
這允許執行時啟動一個新執行緒,該執行緒將在當前執行緒被阻塞時為其他 goroutine 提供服務。
這導致每 Go 行程的作業系統執行緒相對較少,Go 執行時負責將可執行的 Goroutine 分配給空閑的作業系統執行緒。

Gocon 2014 (37)
在上一節中,我討論了 goroutine 如何減少管理許多(有時是數十萬個併發執行執行緒)的開銷。
Goroutine故事還有另一面,那就是棧管理,它引導我進入我的最後一個話題。
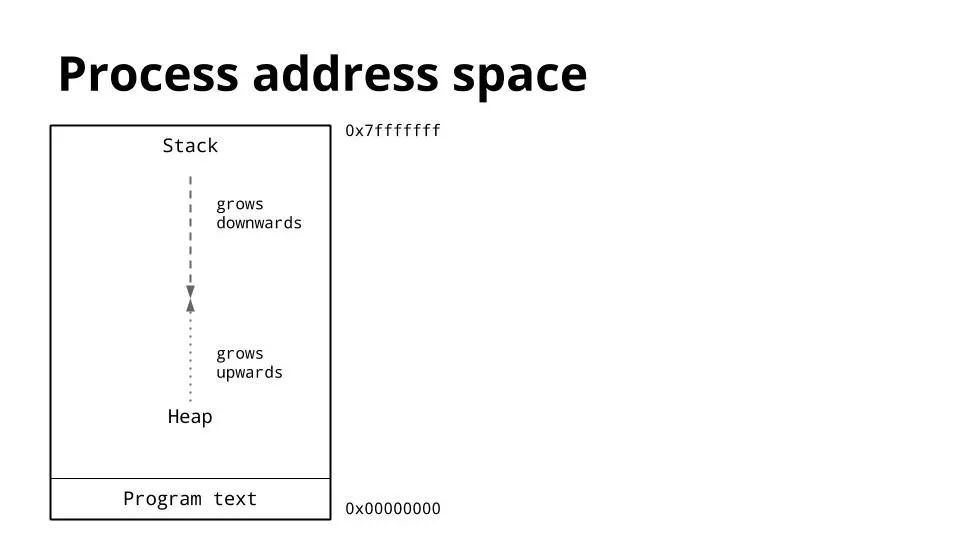
Gocon 2014 (39)
這是一個行程的記憶體佈局圖。我們感興趣的關鍵是堆和棧的位置。
傳統上,在行程的地址空間內,堆位於記憶體的底部,位於程式(程式碼)的上方並向上增長。
棧位於虛擬地址空間的頂部,並向下增長。

Gocon 2014 (40)
因為堆和棧相互改寫的結果會是災難性的,作業系統通常會安排在棧和堆之間放置一個不可寫記憶體區域,以確保如果它們發生碰撞,程式將中止。
這稱為保護頁,有效地限制了行程的棧大小,通常大約為幾兆位元組。

Gocon 2014 (41)
我們已經討論過執行緒共享相同的地址空間,因此對於每個執行緒,它必須有自己的棧。
由於很難預測特定執行緒的棧需求,因此為每個執行緒的棧和保護頁面保留了大量記憶體。
希望是這些區域永遠不被使用,而且防護頁永遠不會被擊中。
缺點是隨著程式中執行緒數的增加,可用地址空間的數量會減少。

Gocon 2014 (42)
我們已經看到 Go 執行時將大量的 goroutine 排程到少量執行緒上,但那些 goroutines 的棧需求呢?
Go 編譯器不使用保護頁,而是在每個函式呼叫時插入一個檢查,以檢查是否有足夠的棧來執行該函式。如果沒有,執行時可以分配更多的棧空間。
由於這種檢查,goroutines 初始棧可以做得更小,這反過來允許 Go 程式員將 goroutines 視為廉價資源。

Gocon 2014 (43)
這是一張顯示了 Go 1.2 如何管理棧的幻燈片。
當 G 呼叫 H 時,沒有足夠的空間讓 H 執行,所以執行時從堆中分配一個新的棧幀,然後在新的棧段上執行 H。當 H 傳回時,棧區域傳回到堆,然後傳回到 G。

Gocon 2014 (44)
這種管理棧的方法通常很好用,但對於某些型別的程式碼,通常是遞迴程式碼,它可能導致程式的內部迴圈跨越這些棧邊界之一。
例如,在程式的內部迴圈中,函式 G 可以在迴圈中多次呼叫 H,
每次都會導致棧拆分。 這被稱為 熱分裂 問題。

Gocon 2014 (45)
為瞭解決熱分裂問題,Go 1.3 採用了一種新的棧管理方法。
如果 goroutine 的棧太小,則不會新增和刪除其他棧段,而是分配新的更大的棧。
舊棧的內容被覆制到新棧,然後 goroutine 使用新的更大的棧繼續執行。
在第一次呼叫 H 之後,棧將足夠大,對可用棧空間的檢查將始終成功。
這解決了熱分裂問題。

Gocon 2014 (46)
值,行內,逃逸分析,Goroutines 和分段/複製棧。
這些是我今天選擇談論的五個特性,但它們絕不是使 Go 成為快速的語言的唯一因素,就像人們取用他們學習 Go 的理由的三個原因一樣。
這五個特性一樣強大,它們不是孤立存在的。
例如,執行時將 goroutine 復用到執行緒上的方式在沒有可擴充套件棧的情況下幾乎沒有效率。
行內透過將較小的函式組合成較大的函式來降低棧大小檢查的成本。
逃逸分析透過自動將從實體從堆移動到棧來減少垃圾回收器的壓力。
逃逸分析還提供了更好的 快取區域性性。
如果沒有可增長的棧,逃逸分析可能會對棧施加太大的壓力。

Gocon 2014 (47)
相關文章:
作者簡介:
David 是來自澳大利亞悉尼的程式員和作者。
自 2011 年 2 月起成為 Go 的 contributor,自 2012 年 4 月起成為 committer。
聯絡資訊
via: https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast
作者:Dave Cheney[11] 譯者:houbaron 校對:wxy
本文由 LCTT 原創編譯,Linux中國 榮譽推出