
導讀:無論你的工作內容是什麼,掌握一定的資料分析能力,都可以幫你更好的認識世界,更好的提升工作效率。資料分析除了包含傳統意義上的統計分析之外,也包含尋找有效特徵、進行機器學習建模的過程,以及探索資料價值、找尋資料本根的過程。
作者:馬海平 於俊 呂昕 向海
本文摘編自《Spark機器學習進階實戰》,如需轉載請聯絡我們
01 資料分析流程
資料分析可以幫助我們從資料中發現有用資訊,找出有建設性的結論,並基於分析結論輔助決策。如圖1所示,資料分析流程主要包括業務調研、明確標的、資料準備、特徵處理、模型訓練與評估、輸出結論等六個關鍵環節。

▲圖1 資料分析流程
資料分析能力並非一朝一夕養成的,需要長期紮根業務進行積累,需要長期根據資料分析流程一步一個腳印分析問題,培養自己對資料的敏感度,從而養成用資料分析、用資料說話的習慣。當你可以基於一些資料,根據自己的經驗做出初步的判斷和預測,你就基本擁有資料思維了。
02 資料分析基本方法
資料分析是以標的為導向的,透過標的實現選擇資料分析的方法,常用的分析方法是統計分析,資料挖掘則需要使用機器學習構建模型。接下來介紹一些簡單的資料分析方法。
1. 彙總統計
統計是指用單個數或者數的小集合捕獲很大值集的特徵,透過少量數值來瞭解大量資料中的主要資訊,常見統計指標包括:
-
分佈度量:機率分佈表、頻率表、直方圖
-
頻率度量:眾數
-
位置度量:均值、中位數
-
散度度量:極差、方差、標準差
-
多元比較:相關係數
-
模型評估:準確率、召回率
彙總統計對一個彈性分散式資料集RDD進行概括統計,它透過呼叫Statistics的colStats方法實現。colStats方法可以傳回RDD的最大值、最小值、均值、方差等,程式碼實現如下:
import org.apache.spark.MLlib.linalg.Vectorimport org.apache.spark.MLlib.stat.{MultivariateStatisticalSummary, Statistics}// 向量[Vector]資料集val data: RDD[Vector] = ... // 彙總統計資訊val summary: statisticalSummary = Statistics.colStats(data)// 平均值和方差println(summary.mean)println(summary.variance) 2. 相關性分析
相關性分析是指透過分析尋找不用商品或不同行為之間的關係,發現使用者的習慣,計算兩個資料集的相關性是統計中的常用操作。
在MLlib中提供了計算多個資料集兩兩相關的方法。目前支援的相關性方法有皮爾遜(Pearson)相關和斯皮爾曼(Spearman)相關。一般對於符合正態分佈的資料使用皮爾遜相關係數,對於不符合正態分佈的資料使用斯皮爾曼相關係數。
皮爾遜相關係數是用來反映兩個變數相似程度的統計量,它常用於計算兩個向量的相似度,皮爾遜相關係數計算公式如下:

其中 表示兩組變數,
表示兩組變數,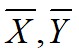 表示兩個變數的平均值,皮爾遜相關係數可以理解為對兩個向量進行歸一化以後,計算其餘弦距離(即使用餘弦函式cos計算相似度,用向量空間中兩個向量的夾角的餘弦值來衡量兩個文字間的相似度),皮爾遜相關大於0表示兩個變數正相關,小於0表示兩個變數負相關,皮爾遜相關係數為0時,表示兩個變數沒有相關性。
表示兩個變數的平均值,皮爾遜相關係數可以理解為對兩個向量進行歸一化以後,計算其餘弦距離(即使用餘弦函式cos計算相似度,用向量空間中兩個向量的夾角的餘弦值來衡量兩個文字間的相似度),皮爾遜相關大於0表示兩個變數正相關,小於0表示兩個變數負相關,皮爾遜相關係數為0時,表示兩個變數沒有相關性。
呼叫MLlib計算兩個RDD皮爾遜相關性的程式碼如下,輸入的資料可以是RDD[Double]也可以是RDD[Vector],輸出是一個Double值或者相關性矩陣。
import org.apache.spark.SparkContextimport org.apache.spark.MLlib.linalg._import org.apache.spark.MLlib.stat.Statistics// 建立應用入口val sc: SparkContext = ...// X變數val seriesX: RDD[Double] = ...// Y變數,分割槽和基數同seriesXval seriesY: RDD[Double] = ... // 使用Pearson方法計算相關性,斯皮爾曼的方法輸入“spearman”val correlation: Double = Statistics.corr(seriesX, seriesY, "pearson")// 向量資料集val data: RDD[Vector] = ... val correlMatrix: Matrix = Statistics.corr(data, "pearson")皮爾遜相關係數在機器學習的效果評估中經常使用,如使用皮爾遜相關係數衡量推薦系統推薦結果的效果。
3. 分層抽樣
分層抽樣先將資料分為若干層,然後再從每一層內進行隨機抽樣組成一個樣本。MLlib提供了對資料的抽樣操作,分層抽樣常用的函式是sampleByKey和sampleByKeyExact,這兩個函式是在key-value對的RDD上操作,用key來進行分層。
其中,sampleByKey方法透過擲硬幣的方式進行抽樣,它需要指定需要的資料大小;sampleByKeyExact抽取 個樣本,
個樣本,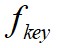 表示期望獲取鍵為key的樣本比例,
表示期望獲取鍵為key的樣本比例, 表示鍵為key的鍵值對的數量。sampleByKeyExact能夠獲取更準確的抽樣結果,可以選擇重覆抽樣和不重覆抽樣,當withReplacement為true時是重覆抽樣,false時為不重覆抽樣。重覆抽樣使用泊松抽樣器,不重覆抽樣使用伯努利抽樣器。
表示鍵為key的鍵值對的數量。sampleByKeyExact能夠獲取更準確的抽樣結果,可以選擇重覆抽樣和不重覆抽樣,當withReplacement為true時是重覆抽樣,false時為不重覆抽樣。重覆抽樣使用泊松抽樣器,不重覆抽樣使用伯努利抽樣器。
分層抽樣的程式碼如下:
import org.apache.spark.SparkContextimport org.apache.spark.SparkContext._import org.apache.spark.rdd.PairRDDFunctionsval sc: SparkContext = ...// RDD[(K, V)]形式的鍵值對val data = ...//指定每個鍵所需的份數val fractions: Map[K, Double] = ...//從每個層次獲取確切的樣本val approxSample = data.sampleByKey(withReplacement = false, fractions)val exactSample = data.sampleByKeyExact(withReplacement = false, fractions)透過使用者特徵、使用者行為對使用者進行分類分層,形成精細化運營、精準化業務推薦,進一步提升運營效率和轉化率。
4. 假設檢驗
假設檢驗是統計中常用的工具,它用於判斷一個結果是否在統計上是顯著的、這個結果是否有機會發生。透過資料分析發現異常情況,找到解決異常問題的方法。
MLlib目前支援皮爾森卡方檢驗,對應的函式是Statistics類的chiSqTest,chiSqTest支援多種輸入資料型別,對不同的輸入資料型別進行不同的處理,對於Vector進行擬合優度檢驗,對於Matrix進行獨立性檢驗,對於RDD用於特徵選擇,使用chiSqTest方法進行假設檢驗的程式碼如下:
import org.apache.spark.SparkContextimport org.apache.spark.MLlib.linalg._import org.apache.spark.MLlib.regression.LabeledPointimport org.apache.spark.MLlib.stat.Statistics._val sc: SparkContext = ...// 定義一個由事件頻率組成的向量val vec: Vector = ... // 作皮爾森擬合優度檢驗val goodnessOfFitTestResult = Statistics.chiSqTest(vec)println(goodnessOfFitTestResult)// 定義一個檢驗矩陣val mat: Matrix = ...// 作皮爾森獨立性檢測val independenceTestResult = Statistics.chiSqTest(mat)// 檢驗總結:包括假定值(p-value)、自由度(degrees of freedom)println(independenceTestResult)// pairs(feature, label).val obs: RDD[LabeledPoint] = ... // 獨立性檢測用於特徵選擇val featureTestResults: Array[ChiSqTestResult] = Statistics.chiSqTest(obs)var i = 1featureTestResults.foreach { result => println(s"Column $i:\n$result") i += 1}03 簡單的資料分析實踐
為了更清楚的說明簡單的資料分析實現,搭建Spark開發環境,並使用gowalla資料集進行簡單的資料分析,該資料集較小,可在Spark本地樣式下,快速執行實踐。
實踐步驟如下:
1)環境準備:準備開發環境並載入專案程式碼;
2)資料準備:資料預處理及one-hot編碼;
3)資料分析:使用均值、方差、皮爾遜相關性計算等進行資料分析。
簡單資料分析實踐的詳細程式碼參考:ch02\GowallaDatasetExploration.scala,本地測試引數和值如表1所示。
|
本地測試引數 |
引數值 |
|
mode |
local[2] |
|
input |
2rd_data/ch02/Gowalla_totalCheckins.txt |
▲表1 本地測試引數和值
1. 環境準備
Spark程常用IntelliJ IDEA工具進行開發,下載地址:www.jetbrains.com/idea/,一般選擇Community版,當前版本:ideaIC-2017.3.4,支援Windows、Mac OS X、Linux,可以根據自己的情況選擇適合的作業系統進行安裝。
(1)安裝scala-intellij外掛
啟動IDEA程式,進入“Configure”介面,選擇“Plugins”,點選安裝介面左下角的“Install JetBrains plugin”選項,進入JetBrains外掛選擇頁面,輸入“Scala”來查詢Scala外掛,點選“Install plugin”按鈕進行安裝。(如果網路不穩定,可以根據頁面提示的地址下載,然後選擇“Install plugin from disk”本地載入外掛),外掛安裝完畢,重啟IDEA。
(2)建立專案開發環境
啟動IDEA程式,選擇“Create New Project”,進入建立程式介面,選擇Scala對應的sbt選項,設定Scala工程名稱和本地目錄(以book2-master為例),選擇SDK、SBT、Scala版本(作者的開發環境:Jdk->1.8.0_162、sbt->1.1.2、scala->2.11.12),點選“Finish”按鈕完成工程的建立。
匯入Spark開發包,具體步驟為:File->Project Structure->Libraries->+New Project Library(Java),選擇spark jars(如:spark-2.3.0-bin-hadoop2.6/jars)和本地libs(如:\book2-master\libs,包括:nak_2.11-1.3、scala-logging-api_2.11-2.1.2、scala-logging-slf4j_2.11-2.1.2)。
(3)複製專案程式碼
複製原始碼中的2rd_data、libs、output、src改寫本地開發專案目錄,即可完成開發環境搭建。
除此之外,也可以透過Maven方式Import Project。
2. 準備資料
我們提供的資料格式:
使用者[user] 簽到時間[check-in time] 維度[latitude] 精度[longitude] 位置標識[location id]
資料樣例如下:
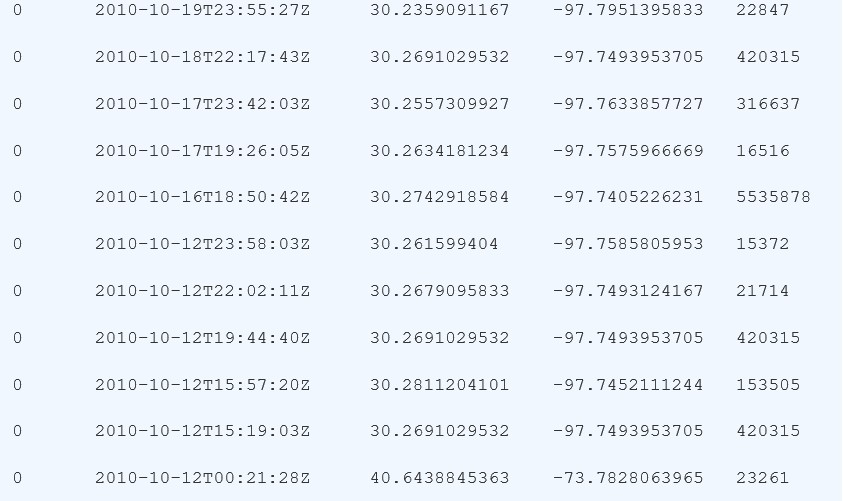
準備資料的步驟如下。
(1)資料清洗
在資料清洗階段過濾掉不符合規範的資料,並將資料進行格式轉換,保證資料的完整性、唯一性、合法性、一致性,並按照CheckIn類填充資料,具體實現方法如下:
// 定義資料類CheckIncase class CheckIn(user: String, time: String, latitude: Double, longitude: Double, location: String)// 實體化應用程式入口val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster(mode)val sc = new SparkContext(conf) val gowalla = sc.textFile(input).map(_.split("\t")).mapPartitions{case iter =>val format = DateTimeFormat.forPattern("yyyy-MM-dd\'T\'HH:mm:ss\'Z\'")iter.map {// 填充資料類case terms => CheckIn(terms(0), terms(1).substring(0, 10), terms(2).toDouble, terms(3).toDouble,terms(4))}}(2)資料轉換
在資料轉化階段,將資料轉換成Vectors的形式,供後面資料分析使用。
// 欄位:user, checkins, checkin days, locationsval data = gowalla.map{ case check: CheckIn => (check.user, (1L, Set(check.time), Set(check.location)))}.reduceByKey {// 並集 unioncase (left, right) =>(left._1 + right._1,left._2.union(right._2),left._3.union(right._3))}.map { case (user, (checkins, days:Set[String], locations:Set[String])) =>Vectors.dense(checkins.toDouble,days.size.toDouble,locations.size.toDouble)}3. 資料分析
透過簡單的資料分析流程,實現均值、方差、非零元素的目錄的統計,以及皮爾遜相關性計算,來實現對資料分析的流程和方法的理解。
簡單的資料分析程式碼示例如下:
// 統計分析val summary: MultivariateStatisticalSummary = Statistics.colStats(data)// 均值、方差、非零元素的目錄println("Mean"+summary.mean)println("Variance"+summary.variance)println("NumNonzeros"+summary.numNonzeros)// 皮爾遜val correlMatrix: Matrix = Statistics.corr(data, "pearson")println("correlMatrix"+correlMatrix.toString)簡單資料分析應用執行結果如下:
均值:[60.16221566503564,25.30645613117692,37.17676390393301]方差:[18547.42981193066,1198.630729157736,7350.7365871949905]非零元素:[107092.0,107092.0,107092.0]皮爾遜相關性矩陣:1.0 0.7329442022276709 0.9324997691135504 0.7329442022276709 1.0 0.5920355112372706 0.9324997691135504 0.5920355112372706 1.0 本文摘編自《Spark機器學習進階實戰》,經出版方授權釋出。
延伸閱讀《Spark機器學習進階實戰》
點選上圖瞭解及購買
轉載請聯絡微信:togo-maruko
推薦語:科大訊飛大資料專家撰寫,從基礎到應用,面面俱到。

更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 資料分析的方法你掌握了多少?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

 點選閱讀原文,瞭解更多
點選閱讀原文,瞭解更多
