作者:嚴瀾
網址:http://www.lanceyan.com/tech/arch/consistenthashing_and_solr.html
網際網路創業中大部分人都是草根創業,這個時候沒有強勁的伺服器,也沒有錢去買很昂貴的海量資料庫。在這樣嚴峻的條件下,一批又一批的創業者從創業中獲得成功,這個和當前的開源技術、海量資料架構有著必不可分的關係。比如我們使用mysql、nginx等開源軟體,透過架構和低成本伺服器也可以搭建千萬級使用者訪問量的系統。新浪微博、淘寶網、騰訊等大型網際網路公司都使用了很多開源免費系統搭建了他們的平臺。所以,用什麼沒關係,只要能夠在合理的情況下採用合理的解決方案。
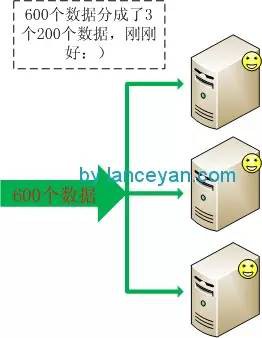
那怎麼搭建一個好的系統架構呢?這個話題太大,這裡主要說一下資料分流的方式。比如我們的資料庫伺服器只能儲存200個資料,突然要搞一個活動預估達到600個資料。
可以採用兩種方式:橫向擴充套件或者縱向擴充套件。
- 縱向擴充套件是升級伺服器的硬體資源。但是隨著機器的效能配置越高,價格越高,這個代價對於一般的小公司是承擔不起的。
- 橫向擴充套件是採用多個廉價的機器提供服務。這樣一個機器只能處理200個資料、3個機器就可以處理600個資料了,如果以後業務量增加還可以快速配置增加。在大多數情況都選擇橫向擴充套件的方式。如下圖:

現在有個問題了,這600個資料如何路由到對應的機器。需要考慮如果均衡分配,假設我們600個資料都是統一的自增id資料,從1~600,分成3堆可以採用 id mod 3的方式。其實在真實環境可能不是這種id是字串。需要把字串轉變為hashcode再進行取模。
目前看起來是不是解決我們的問題了,所有資料都很好的分發並且沒有達到系統的負載。但如果我們的資料需要儲存、需要讀取就沒有這麼容易了。業務增多怎麼辦,大家按照上面的橫向擴充套件知道需要增加一臺伺服器。但是就是因為增加這一臺伺服器帶來了一些問題。看下麵這個例子,一共9個數,需要放到2臺機器(1、2)上。各個機器存放為:1號機器存放1、3、5、7、9 ,2號機器存放 2、4、6、8。如果擴充套件一臺機器3如何,資料就要發生大遷移,1號機器存放1、4、7, 2號機器存放2、5、8, 3號機器存放3、6、9。如圖:
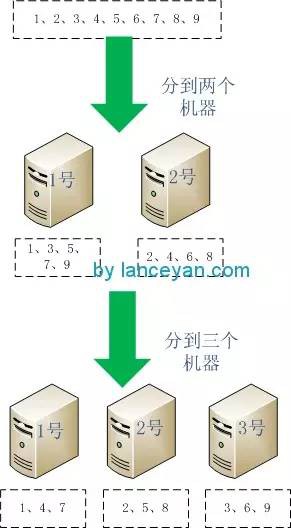
從圖中可以看出 1號機器的3、5、9遷移出去了、2好機器的4、6遷移出去了,按照新的秩序再重新分配了一遍。資料量小的話重新分配一遍代價並不大,但如果我們擁有上億、上T級的資料這個操作成本是相當的高,少則幾個小時多則數天。並且遷移的時候原資料庫機器負載比較高,那大家就有疑問了,是不是這種水平擴充套件的架構方式不太合理?
一致性hash就是在這種應用背景提出來的,現在被廣泛應用於分散式快取,比如memcached。下麵簡單介紹下一致性hash的基本原理。最早的版本 http://dl.acm.org/citation.cfm?id=258660。國內網上有很多文章都寫的比較好。如: http://blog.csdn.net/x15594/article/details/6270242
下麵簡單舉個例子來說明一致性hash。
準備:1、2、3 三臺機器
還有待分配的9個數 1、2、3、4、5、6、7、8、9
一致性hash演演算法架構
步驟
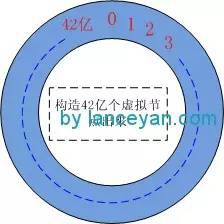
一、構造出來 2的32次方 個虛擬節點出來,因為計算機裡面是01的世界,進行劃分時採用2的次方資料容易分配均衡。另 2的32次方是42億,我們就算有超大量的伺服器也不可能超過42億臺吧,擴充套件和均衡性都保證了。
二、將三臺機器分別取IP進行hashcode計算(這裡也可以取hostname,只要能夠唯一區別各個機器就可以了),然後對映到2的32次方上去。比如1號機器算出來的hashcode並且mod (2^32)為 123(這個是虛構的),2號機器算出來的值為 2300420,3號機器算出來為 90203920。這樣三臺機器就對映到了這個虛擬的42億環形結構的節點上了。
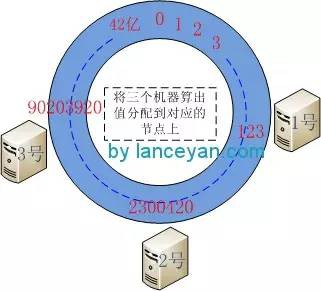
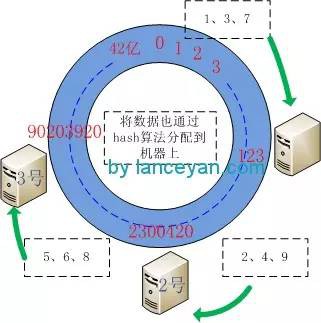
三、將資料(1-9)也用同樣的方法算出hashcode並對42億取模將其配置到環形節點上。假設這幾個節點算出來的值為 1:10,2:23564,3:57,4:6984,5:5689632,6:86546845,7:122,8:3300689,9:135468。可以看出 1、3、7小於123, 2、4、9 小於 2300420 大於 123, 5、6、8 大於 2300420 小於90203920。從資料對映到的位置開始順時針查詢,將資料儲存到找到的第一個Cache節點上。如果超過2^32仍然找不到Cache節點,就會儲存到第一個Cache節點上。也就是1、3、7將分配到1號機器,2、4、9將分配到2號機器,5、6、8將分配到3號機器。
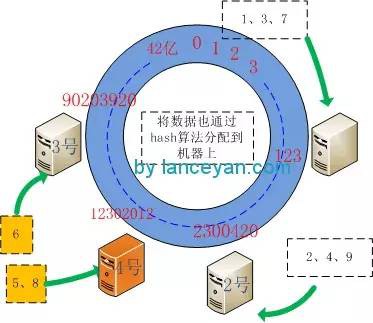
這個時候大家可能會問,我到現在沒有看見一致性hash帶來任何好處,比傳統的取模還增加了複雜度。現在馬上來做一些關鍵性的處理,比如我們增加一臺機器。按照原來我們需要把所有的資料重新分配到四臺機器。一致性hash怎麼做呢?現在4號機器加進來,他的hash值算出來取模後是12302012。 5、8 大於2300420 小於12302012 ,6 大於 12302012 小於90203920 。這樣調整的只是把5、8從3號機器刪除,4號機器中加入 5、6。
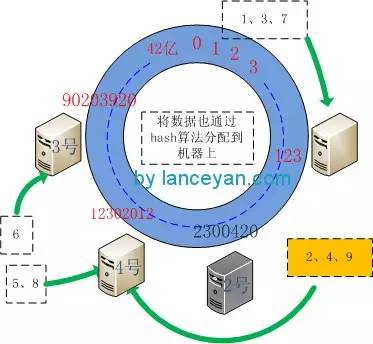
同理,刪除機器怎麼做呢,假設2號機器掛掉,受影響的也只是2號機器上的資料被遷移到離它節點,上圖為4號機器。
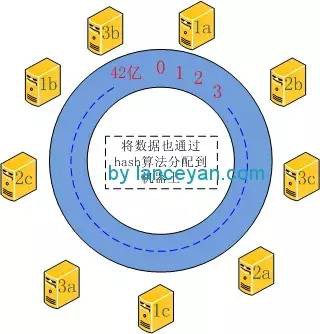
大家應該明白一致性hash的基本原理了吧。不過這種演演算法還是有缺陷,比如在機器節點比較少、資料量大的時候,資料的分佈可能不是很均衡,就會導致其中一臺伺服器的資料比其他機器多很多。為瞭解決這個問題,需要引入虛擬伺服器節點的機制。如我們一共有隻有三臺機器,1、2、3。但是實際又不可能有這麼多機器怎麼解決呢?把 這些機器各自虛擬化出來3臺機器,也就是 1a 1b 1c 2a 2b 2c 3a 3b 3c,這樣就變成了9臺機器。實際 1a 1b 1c 還是對應1。但是實際分佈到環形節點就變成了9臺機器。資料分佈也就能夠更分散一點。如圖:
寫了這麼多一致性hash,這個和分散式搜尋有什麼半點關係?我們現在使用solr4搭建了分散式搜尋,測試了基於solrcloud的分散式平臺提交20條資料居然需要幾十秒,所以就廢棄了solrcloud。採用自己hack solr平臺,不用zookeeper做分散式一致性管理平臺,自己管理資料的分發機制。既然需要自己管理資料的分發,就需要考慮到索引的建立,索引的更新。這樣我們的一致性hash也就用上了。整體架構如下圖:
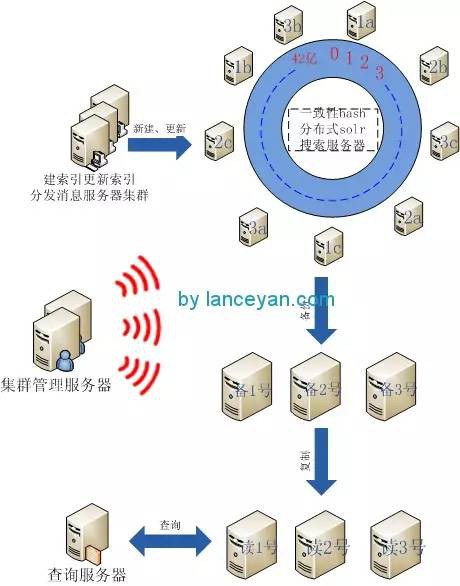
- 建立和更新需要維持機器的位置,能夠根據資料的key找到對應的資料分發並更新。這裡需要考慮的是如何高效、可靠的把資料建立、更新到索引裡。
- 備份伺服器防止建立伺服器掛掉,可以根據備份伺服器快速恢復。
- 讀伺服器主要做讀寫分離使用,防止寫索引影響查詢資料。
- 叢集管理伺服器管理整個叢集內的伺服器狀態、告警。
整個叢集隨著業務增多還可以按照資料的型別劃分,比如使用者、微博等。每個型別按照上圖架構搭建,就可以滿足一般效能的分散式搜尋。對於solr和分散式搜尋的話題後續再聊。
擴充套件閱讀
java的hashmap隨著資料量的增加也會出現map調整的問題,必要的時候就初始化足夠大的size以防止容量不足對已有資料進行重新hash計算。
疫苗:Java HashMap的死迴圈 http://coolshell.cn/articles/9606.html
一致性雜湊演演算法的最佳化—-關於如何保正在環中增加新節點時,命中率不受影響 (原拍拍同事scott)http://scottina.iteye.com/blog/650380
語言實現:
http://weblogs.java.net/blog/2007/11/27/consistent-hashing java 版本的例子
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx PHP 版的例子
http://www.codeproject.com/KB/recipes/lib-conhash.aspx C語言版本例子