從2010年至今,大資料投資熱潮與大資料崗位開始集中爆發。從360指數我們可以看出,目前大資料在市場的熱度遠遠高於前幾年特別火的產品經理。

大資料之火熱,以致身邊很多人對於大資料相關熱門趨勢及詞彙都能隨口就來。但如果問他大資料和他之間的關係,卻很難能說出一二三來。
究其原因,大家置身於大資料環境下,耳濡目染各種新的概念,但是真正參與實踐大資料的案例少之又少,造成了對大資料整體認知的缺失。
下麵講講大資料行業不同角色對大資料的觀點,希望能夠還原出來一個較為全面的認識,瞭解不同角色對大資料的需求背景。
大資料開發
2010開始,大資料成為了分散式技術框架的別名,Hadoop開始頻繁進入大家眼中,從此以後,hive,spark,flink等分散式計算框架如雨後春筍進入大家的開發工作環境中(當然大資料的薪資也開始水漲船高,遠遠高於其他同類開發)。
那麼在大資料開發的眼中,大資料應該是長這樣的:
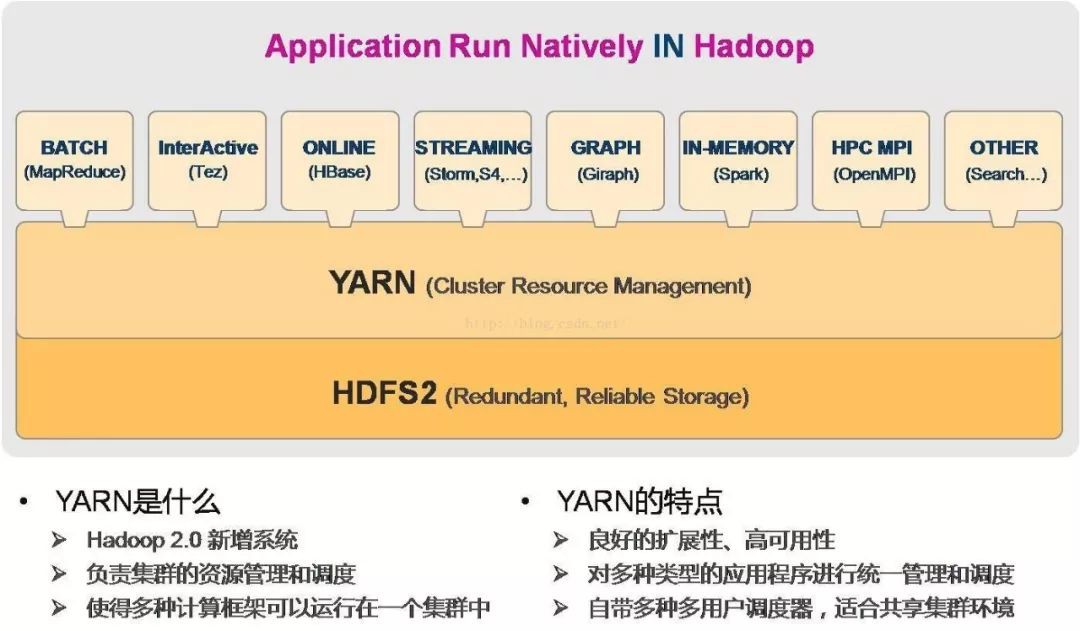
-
第一:資料體量巨大。大資料的起始計量單位至少是P(1000個T)、E(100萬個T)或Z(10億個T);
-
第二:資料型別繁多。比如,網路日誌、影片、圖片、地理位置資訊等等;
-
第三:需要不同的框架解決不同的問題。
在大資料開發眼裡,大資料是一堆框架的集合。
資料分析及演演算法工程師
隨著大資料技術的發展,傳統基於關係型資料庫的BI底層逐步被大資料替代。
資料採集全面進入線上化,公司開始全量採集線上資料,全量儲存使用者行為資料作為分析資料源。傳統的基於抽樣的統計方式逐步被全量統計方式替換,原有技術框架支援不了的使用者行為分析也逐步成為大資料分析場景的標準流程,基於單機的資料挖掘演演算法逐步被替換成分散式的機器學習和深度學習替代。

在分析師和演演算法工程師眼裡,資料又表現為如下幾個方面:
-
第一:資料記錄全面,能夠分析的場景越來越多;
-
第二:資料價值密度很低、挖掘難度變大;
-
第三:單機無法解決,需要藉助大資料相關工具。
在他們眼裡,大資料意味著更多的場景可以被分析量化。
資料產品經理
隨著工具及演演算法的逐步完成,基於大資料做到千人千面的推送及定價方案已經成為可能。
有一個非常經典的案例:為提高在主營產品上的贏利,亞馬遜在2000年9月中旬開始了著名的差別定價實驗。
亞馬遜選擇了68種DVD碟片進行動態定價試驗,試驗當中,亞馬遜根據潛在客戶的人口統計資料、在亞馬遜的購物歷史、上網行為以及上網使用的軟體系統確定對這68種碟片的報價水平。例如,名為《泰特斯》(Titus)的碟片對新顧客的報價為22.74美元,而對那些對該碟片表現出興趣的老顧客的報價則為26.24美元。
透過這一定價策略,亞馬遜提高了銷售的毛利率。在此我們不考慮這個定價策略是否妥當,但是大資料技術的確已經驗證可以為企業帶來更多的收益。

在產品經理眼裡,我們發現了另外一種大資料的看法:
大資料意味著更好的產品最佳化及產品收益已經成為可能,至於具體的技術細節和演演算法,並不是他們關註的點。
當然,除瞭如上三個崗位,其實還有很多大資料相關的配套崗位,他們對大資料亦有各自的理解。
但是如果作為一個企業落地大資料項目,我們唯一需要綜合考慮的是如何在最低投入的情況下,保證長期與短期效益的均衡,舉個例子來說:
1、 如果過分重於技術,會導致技術費用投入過大, 成本急劇放大
2、 如果過分重於分析,缺乏有效產品整合的話,可能犧牲長期效應
3、 過分重於產品的話,投入較長的時間產品化,可能犧牲短期收益
為了平衡三個崗位偏差造成的需求差異,大資料架構師、資料科學家相關崗位應運而生。
與傳統商業智慧領域類似,大資料架構師及資料科學家需要解決的核心問題還是如何構建一套穩定高效的大資料技術元件下的資料倉庫。
我從落地的多個企業級大資料專案總結出,設計一個高效可靠的資料倉庫會成為一個企業大資料專案成敗的最關鍵因素,為什麼這麼說呢?
我們邀請了網易資深大資料開發工程師-王潘安,給大家詮釋大資料倉庫的重要性,介紹構建企業級資料體系的標準化流程。幫助大家在學習大資料的道路上有跡可循,形成體系化的思維。避免陷入大量的大資料工具和框架中無法自拔。

現加入QQ群(獲取方式見底部)即可免費預約直播,同時附贈免費體驗課程、學習資料包。
【免費體驗課程】

1. 從資料到大資料
2. 大資料技術淺談
計算原理:從平行計算說起
儲存原理:海納百川,有容乃大
大資料技術架構
【免費學習資料包】
【如何獲取】
掃碼加入QQ群
群號:750454491
點選【閱讀原文】,免費領取福利
