

談到OpenStack,大家對其多多少少都有所瞭解,其常見的服務包括Nova、Swift、Glance、Keystone、Neutron、Cinder、Horizon、Ceilometer、Heat、Trove、TripleO、Sahara等等。
-
Nova:提供Compute(計算服務),主要的作用是管理虛擬機器實體的整個生命週期,根據使用者需求來提供虛擬服務。
-
Glance:提供 Image Service(映象管理服務),映象伺服器是一套虛擬機器映象發現、註冊、檢索系統,但它不提供映象檔案的儲存功能。
-
Swift:提供Object Storage(物件儲存服務),儲存數量到一定級別,而且是非結構化資料,通常才會有使用物件儲存的需求。映象檔案通常儲存在Swift中。
其中Ceilometer為計量服務,能把OpenStack內部發生的幾乎所有的事件都收集起來,然後為計費和監控以及其他服務提供資料支援,今天我們主要談的也是Ceilometer服務。
Ceilometer模組主要負責OpenStack的“計量”、“監控”以及“告警”功能。
-
計量主要負責和計費相關的指標度量採集和儲存;
-
監控主要負責和非計費相關的指標、狀態的採集和儲存;
-
告警可分為效能相關的告警分析產生以及透過外掛在openstack各服務執行時及時產生的故障。
Ceilometer功能是以資料庫和訊息佇列為中心的資料採集、訂閱分析和儲存、分發一系列活動。Ceilometer主要組成部分有:
-
ceilometer-api: 向用戶展示聚合後的資料
-
ceilometer-polling:使用polling plug-in去獲取資料
-
ceilometer-agent-central:呼叫不同的元件的API以監控某種資源是否存在(L版本後不使用)
-
ceilometer-agent-compute:監控Hypervisor或者libvirt以獲取實體的效能資料,並透過MQ釋出出去(L版本後不再使用)
-
ceilometer-agent-ipmi:利用伺服器上的IPMI感測器獲取物理機資訊(L版本後不再使用)
-
ceilometer-agent-notification:從MQ獲取其他元件的訊息
-
ceilometer-collector:從MQ獲取ceilometer其他agent的資訊,並將這些資料分配到不同的資料庫。
-
ceilometer-alarm-X:告警相關
除了ceilometer-agent-compute和ceilometer-agent-ipmi,其他元件都要部署在一個或者多個控制節點,ceilometer高度依賴MQ服務,包括元件之間和元件內部。Ceilometer的主要功能是資料收集和資料處理。
Ceilometer的資料採集方式主要分為Poll和Push方式兩種。

其中Push方式主要採集為OpenStack中各個元件模組中無法定時主動獲取的事件訊息,例如,虛擬機器的建立,映象的上傳等等。該種方式的訊息的採集依賴各個元件在事件發生時,依賴Ceilometer提供的訊息機制將事件訊息上報至訊息佇列當中。
然後由Ceilometer-Collector中的notification-agent收集訊息佇列中的事件訊息,然後交由指定的Pipeline將訊息轉換為指定的取樣資料(Samples),轉換之後的取樣資料會被重新傳送至訊息佇列當中,然後由Collector收集處理並存入資料庫當中(MongoDB)。主要架構如下圖:
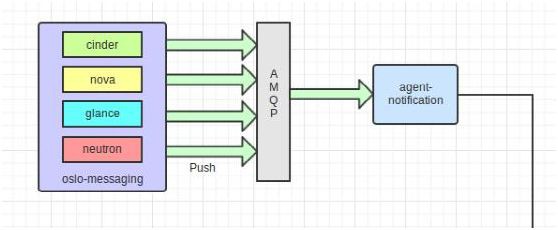
Poll方式主要採集OpenStack中的各個元件的統計資料和計算節點中的實時資料(該資料也是可以被隨時統計獲取的)。
在Controller節點上,Poll方式主要是啟動相應的輪詢行程(Pollsters),依靠輪詢行程定期呼叫元件模組的APIs獲取各個元件的資料資訊。然後將資料交由Pipeline進行處理,最後由Collector處理儲存。此過程與上述Push方式一致。

在Compute節點上,Poll方式也是啟動相應的輪詢行程(Pollsters),依靠輪詢行程定期查詢相應的資訊,只是在資料採集方式上,採用虛擬機器的相關驅動獲取虛擬機器的資訊,目前主要的部署方案都是採用KVM-QEMU實現虛擬化,因此,底層資訊獲取上,採用的為LibVirt操縱虛擬機器,同時也是透過LibVirt獲取虛擬機器的相關資訊。當資料被採集之後,其之後的處理流程與上述兩種方式都是一致的。
前面的資料採集工作完成之後,採集來的資料會交由Pipeline進行資料處理,Pipeline主要實現的是一個資料處理鏈的功能。Pipeline會根據不同的配置將0個或一個或多個Transformers組裝成為一條資料處理鏈,在這條資料處理鏈的末端,會被裝配一個Publisher。
當資料進入這條資料處理鏈後,會被Transformers加工處理,然後由Publisher傳送至訊息佇列當中,由Collector收集。

Collector會時刻監聽著訊息佇列,從訊息佇列中獲取監控資料,然後將資料存入MongoDB中進行持久化。
OpenStack不但是開源私有雲的實際標準,而且已經廣泛的應用在各個行業,包括社群版和廠商企業版。
在OpenStack大規模部署,特性豐富,並逐步走向商用的過程中,有很多經驗和方法論值得參考和借鑒。筆者基於實戰和網路資料,對OpenStack及相關知識進行了梳理,整理成書(OpenStack技術和實戰詳解),供學習者學習和參考。





點選閱讀原文連結獲取(OpenStack技術和實戰詳解)電子書詳細資訊。
相關閱讀:
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多技術文章。

求知若渴, 虛心若愚

