
導讀:在2018人工智慧計算大會上,叢京生髮表“可定製計算與AI”的演講。叢京生提出,計算能力的提高,讓今天的AI無處不在。而當前計算的瓶頸是能耗和能效的問題。可定製計算將對AI的發展起到重要作用,同時,AI的發展對可定製化計算也有很大的幫助。目前的工作是想讓AI晶片的設計民主化,讓人人都可以設計電路。
講者:叢京生(美國工程院院士,加州大學洛杉磯分校教授)
整理:邸利會
來源:知識分子
圖源: 圖靈人工智慧
01 計算的瓶頸是能耗和能效的問題
AI無處不在,現在可以看到各種各樣的AI產品,在這邊也看到AI支援的語音識別和同聲翻譯,王恩東院士講到AI三次革命,我有幸看到兩次革命,第一次80年代末,AI有很多有效的進展,我校楊教授的一篇文章,80年代末的時候可以認識數字了。
這個很重要,因為在美國送信要寫郵政編碼,可以自動識別把信分開,他當時做的神經網路有很多是現有神經網路的基礎,包括用全機的這些工作,這些工作中斷了不少時間,AI並沒有那麼風風火火,到了2010年來做影象識別和VGG,很多發展都是在最近五到八年發生的。

為什麼有30年的停滯,直到最近才有大的發展?我個人看AI的基本演演算法沒有太大的變化,推動AI的發展有兩個因素,一是因為網際網路的產生,網際網路產生之後有了大資料,各個地方的工作者可以把大量資料傳上來,比如用影象識別的例子,已經有1400萬個影象在裡面,做語音和影片的也非常多,這在80年代是完全不可能的,沒有大量資料推動AI發展。

第二,計算使AI無所不在,當時大家用到的計算機是英特爾的383,每秒鐘執行200萬到300萬指令,當Alexnet產生的時候英特爾的CPU已經發展到多核,在一秒有一千億到兩千億的運算。再往下是用到GPU又把這個能力提高了十倍到上百倍。因為有這些計算能力的提高讓今天的AI到了無處不在的地方。

我今天的主題是強調可定製化計算,因為我覺得下麵計算的瓶頸是能耗和能效的問題。

90年代的時候買機器要看主頻的速度,浪潮的機器是兩百兆還是五百兆的,到上年十年大家就不只看主頻了,因為主頻到兩到四個核的時候基本停止了,當集中起來的時候晶片就燒掉了,把主頻停下來做平行計算,但是這個也很快不能往下做了,你可以上上千個或者上萬個,但是不能同時開啟,否則晶片還是會燒掉。
十年前有一個方案,計算的下一個方向是可定製化,我的體系結構要為你做的應用來調整定製,所以我們很有幸的在2008年給美國自然基金會送了一個提案,可定製計算,有一千萬美元,我們後面若干年的工作做這方面的研究。
我自己關註可定製化是15年前,我一個同事給我看了這個表,他舉了一個例子,用加密演演算法,可以用一個晶片來做,這個晶片的效率定義成一,第二個用了一個低功耗的arm processor來做,他的效率差了85倍,用英特爾的CPU做,效率差800倍,最後一個就很離譜了,如果你寫JAVA在嵌入式處理器上做呢,我一看可定製的專用和通用差的這麼大,我們一定要用上。

我們做的更多的是FPGA。你可能說這個例子太古老了,是15年前的了。那斯坦福教授在不到十年前做了一個實驗,做了視覺影象處理很常見的例子,他把處理器各種各樣的最佳化用上了,之後還是通用計算和專用計算之間差了50倍,這就是我們想彌補的差距。
我們說以後的計算不要用通用的處理器,通用處理器儘量用各種各樣的加速器,加速器是專用定製計算,大多數計算在加速器上,處理器只是協調你計算的過程。
這其實跟現有的技術有非常大的區別,學計算機的知道,馮諾伊曼體系結構是一個非常漂亮,優雅的體系結構,它有一個共用的資料通道,再加上控制邏輯,各種各樣的指令都可以執行。

這麼一個體系結構為什麼走了四五十年,因為我覺得他解決了當時的一個瓶頸,咱們的計算能力非常有限,有不少年輕的同事們我問一下,大家知道第一個電子計算機裡面有多少個電子管?有六萬多個電子管,第一個積體電路處理器裡有多少電晶體,只有2200個。
相比之下,你花了幾千塊錢買了一個智慧手機,華為或者蘋果,裡面有多少電晶體,裡面有了三四十億個電晶體,所以今天我們有足夠多的計算元件,恰恰卡在能耗上,我不能把它全用起來。
在今天的環境下用處理器的好處是每一個處理器的效率都非常高,但是他改寫的工作量是非常有限。人腦其實很了不起,咱們乾這麼多事情,我在這兒講話,你們在學習,每天用的功耗只是20瓦的功耗,非常有效。

可是大腦裡面,我也問過很多神經系的專家,沒有一個資料通道,沒有執行各種各樣的指令,他是特別的區域,有的區域負責語言處理,有的區域負責思維,有的區域負責運動,這使他的神經網路大大的定製化了,而且專用化了,效率大大提高。
再看社會的發展,更先進、更文明的社會分工更仔細,你生病了以後不會看律師,你肯定會找醫生,你要想學AI就要到這個會場上,找到計算機的工程師。
這裡可能需要解釋一下為什麼馮諾伊曼體系結構、基於指令的計算不那麼有效,因為當時元件很有限,有一個公用的資料通道,為了各種各樣的指令,比如你做加法,先要把加法指令從記憶體拿來這是一步,要看是什麼指令,是加法還是乘法,還是比較,這又是一步。
然後兩個資料加的時候還沒有算出來,還要在那兒等,這叫scheduling, 排程,等七八步以後最後才是做加法,這是它的效率為什麼不高。今天如果我做了專用的計算器,我就是加乘,完全為你量身訂作的電路。
02 可定製計算怎麼為AI起到作用?
我的報告有兩部分,第一,可定製計算怎麼為AI起到作用。我們設計一個專用的晶片來為AI,這個確實是有人在做的。可能最為人知的例子就是,谷歌做的GPU晶片,他做了兩款,2014年和2017年各釋出了一款,他的資料比最好的CPU提高了幾十倍的效率。

但是這有一個問題,谷歌團隊非常大,你今天要想做一個晶片,沒有幾千萬美元做不出來,有多少公司有幾千萬美元的資歷做一個晶片,而且你怎麼保證做完了以後賣出去,有幾億美元的收入才能把成本拿回來,很多人沒有這個信心,而且設計週期特別長,即使是谷歌,也設計了12個月到24個月。24個月以後,AI的很多演演算法就有比較大的變化了,這是一個非常尷尬的問題,需要解決。

我的工作是想讓AI晶片的設計民主化,在座的每一位都可以設計。我們透過一個可程式設計的邏輯電路來做,就叫FPGA,它裡面每個邏輯可以定義做加法乘法或者與或門,它的互聯也非常靈活,可以告訴它直走還是往上往下或者分叉。

所以透過configure logic, interconnect, 這些你可以做出各種各樣專用的電路,而且你花幾百塊錢買這個FPGA放在辦公桌上,想設計一個電路就可以設計一個電路,一秒鐘以內就可以掃清變成另外一個電路,今天可以做壓縮,明天可以做人臉識別,後天做語音識別。
今天在浪潮可以買到這樣的機器,買一個一般的伺服器插一個FPGA的卡,我們跟工業界的朋友都有合作,IBM、英特爾,最後一個是英特爾把CPU和FPGA放在同一個電腦上,你插進去這裡又有CPU又有FPGA。

在UCLA,我們透過這種晶片搭了各種各樣的系統,比如左邊的那個是2013年做的,透過FPGA做的小的資料中心,FPGA低功耗,而且特別有效,每個只有兩瓦,七八個集中起來也不過幾十瓦,沒有風扇,完全聽不到聲音;右邊這個是高效能運算的叢集,裡面上千個核,每個伺服器都接了一個FPGA。

這都可以做到,難在哪裡,給浪潮打個電話把機器買了沒有問題,問題是怎麼程式設計式,這是比較重要的問題。
這些工作我們做了以後,業界也很關註,亞馬遜把FPGA放在他的雲端計算平臺裡,他做完了以後阿裡和華為都把FPGA加進來了,微軟也做了不少先驅的工作和國內的百度,微軟把每個伺服器接到資料中心的網路之前都經過一個FPGA,結果有成千上萬的FPGA連在一起,變成非常強大的微軟的大腦,所有的FPGA可以程式設計,變成各種各樣的邏輯。

他去年顯示了一下他們在做AI方面的工作,還是很驚人的,他們做了上百倍的提高,雖說是可編成的邏輯,在這個延遲方面比TPU還是有更高的提升,這個大家可以看一下他們的論文。(微軟有一個採訪講,為什麼資料中心用FPGA)
我們在UCLA和北大的組做了深度學習用FPGA加速的第一篇論文,2014年做的工作,2015年初發表的,這篇論文是我職業生涯中取用率發展最快的論文,第一年出來就有20篇,兩年之後就有幾百篇,今年還沒過完,已經接近兩百篇了,所以可見大家用FPGA實現深度學習有多大的興趣。

但是其實,做起來很不容易,我們在這邊有好幾年的嘗試,有什麼難度?第一,今天深度學習的網路越來越深,剛才講到精確度一直在提高,現在的錯誤率不到5%,這是什麼概念,人的錯誤率在圖片識別上大概有5%左右,它超過人眼的識別率了,但是為了達到這個精確度,有了一百多層的神經網路。

我們做了一個統計,我們在《自然Electronics》裡發表的論文,我們有一個大膽的預言,神經網路的引數是指數型的增長,中間這條線,很熟悉的從Lenet,AlexNet,VGG上去之後也是指數級的增長,橫軸是年代,縱軸是引數,是指數型增長的,是log的。

上面是工業界用到神經網路的數字,發展的更快。最底下的線是最近做的壓縮的工作,使神經網路的大小有幾十百甚至上百倍的壓縮,壓縮完了以後,它的發展趨勢還是指數型的,所以這個對計算能力的要求非常大。
第二,用了伺服器的就知道,買伺服器不光調計算能力主頻能力,還要調頻寬,能儲存資料和處理資料都需要帶到計算器裡,再拿出來,他的要求很不一樣,比如你看神經網路,其中有幾個部分,一個是做摺積,最後要全連線的層來做分類。摺積用了99%的計算,基本通訊要求不是很強,但看他的通訊要求摺積不到20%,但是最後的要80%。要設計一個加速器又能做摺積,又能做全連線的層,還是很有挑戰的。

第三,Abstraction Gap,昨天有一個訓練營,有上千人參加,你們怎麼寫神經網路,基本用caffe、Tensorflow很高層的描述性的工具來寫,但是你要在變成C程式在機器上跑起來,要上百行才能實現出來,要想把一個電路實現出來就更了不起了,要上萬行的原始碼才可以實現,我們一直在做一個自動的編譯器,從高層下來。

我給大家介紹一下2016年的工作,顯示了我們可以做的能力,剛才講了摺積神經網路和全連線層這兩個有很不一樣的計算特徵,我們有一個通用的計算表示,第二,我們有一個軟體可定義的加速器,這個加速器可以使我們或者最佳化計算能力,或者最佳化通訊能力。第三,加上新的層次,這個層次是讓你可以從最高層的描述做,比如Tensorflow、Caffe,這個也可以交流一下,我們一個是在學術界,有一個技術公司都可以提供這個服務。
要把它的效能做好挺不容易的,仔細看一下谷歌的TPU,它裡面的加速器用到一個微處理的結構,叫做脈衝陣列。脈衝陣列有什麼好處呢?就是資料來了以後,做計算做處理,處理完了把它只給我的鄰居,不用傳的很遠,這樣做下去。

為什麼要這樣呢?如果大家一直在做電路設計,就知道,今天的電路已經到了這個程度,計算可以很快,但把資料從一個節點傳到另外一個節點是計算的幾倍了。我要把資料傳輸的能耗或者延遲縮短,那我就做的很好,任何一個計算來了之後能不能用脈衝陣列做出來,這是很難的問題。
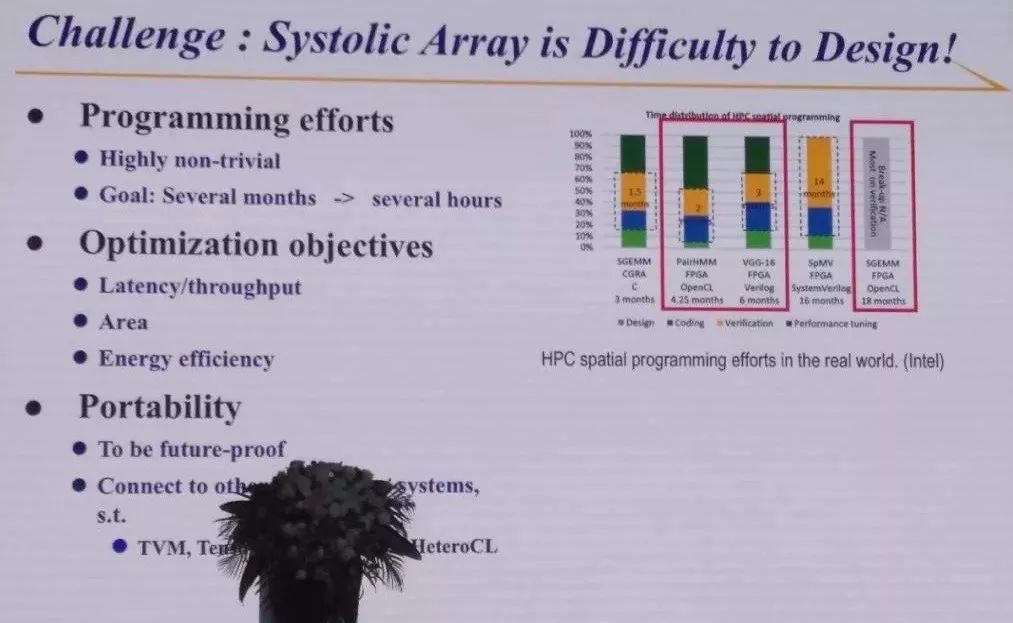
這個圖是英特爾的同事做的,他們做了幾個脈衝陣列,手工做的,幾個月到十幾個月,非常繁瑣,有各種各樣最佳化的條件,比如考慮延時、能效等。我們在UCLA兩年前做一個自動編譯器,給我任何一個C程式,就判定能不能用脈衝陣列做出來,如果能就生成出來了。

這個需要的數學還比較多一點,我用了一個多面體的模型,Polyhedral模型,任何一個程式來了,需要加速,基本都是有多層迴圈,就可以對映到一個多維的空間,節點需要自己去做,多維空間節點,然後變成一個三維空間的表達,我需要做的是把三維空間的資料流變成一個二維的或者一維的脈衝陣列。

變的時候考慮兩點,第一,哪個計算在哪個脈衝陣列裡做,第二,決定什麼時候做,這也很重要,因為計算是有一定相關性的,有時候這一步做完了之後才能做下一步,因為第一步的資料要被第二步用到,這都可以用數學運算式描述出來,然後需要解一個高維的最佳化上的問題。
你的邏輯可能很複雜,我們需要透過幾步,而且你的資料進來只能在邊緣,不能在裡面。比如這個矩陣乘法是我們做神經網路非常重要的計算單元,我們看下來可以淘汰出各種各樣的實現,歸納出五個脈衝陣列實現,你選哪個看你的計算要求,做摺積更有意思,我們可以自動生成15個候選陣列,具體選哪個看你的應用。

MIT發表的結果是我們這裡面的第五個,UCLA和北大也有,是第七個,另外幾個也很好,我們可以自動生成,而且可以給你看到每一個節點的特有的有效性。其實,你不一定只在一個FPGA上,我們搭了一個原型,可以有多個FPGA在裡面,有很大的神經網路。

這是第一部分,我們做了這個工作就是讓你從很高層次的描述,透過一個中間的表達語言,然後到各種各有的可以很最佳化的微處理的結構,比如脈衝陣列,平行計算的架構等,我們的標的是希望把晶片設計民主化,在座的每一位都可以做需要定製的晶片,在FPGA上跑起來。
03 AI的發展對可定製化計算也有很大的幫助
大家知道很大的一個突破,就是兩三年前,阿爾法狗把世界圍棋冠軍打敗了。我看到這個訊息以後還是很震撼,它都把九段的圍棋冠軍打敗了,咱們能不能用AI的辦法,把電路設計師打敗?這就是我們在做的工作,用AI技術幫助你設計晶片,來自動化。

可晶片設計比下圍棋難多了,圍棋的規則是固定的,要是換另外一個遊戲就玩不了,電路是五花八門的,大家的想象力非常豐富,所以這一點是完全不一樣的地方。那你說這個電路能設計出來嗎,我相信經過二三十年的努力我們有了非常長足的進展。
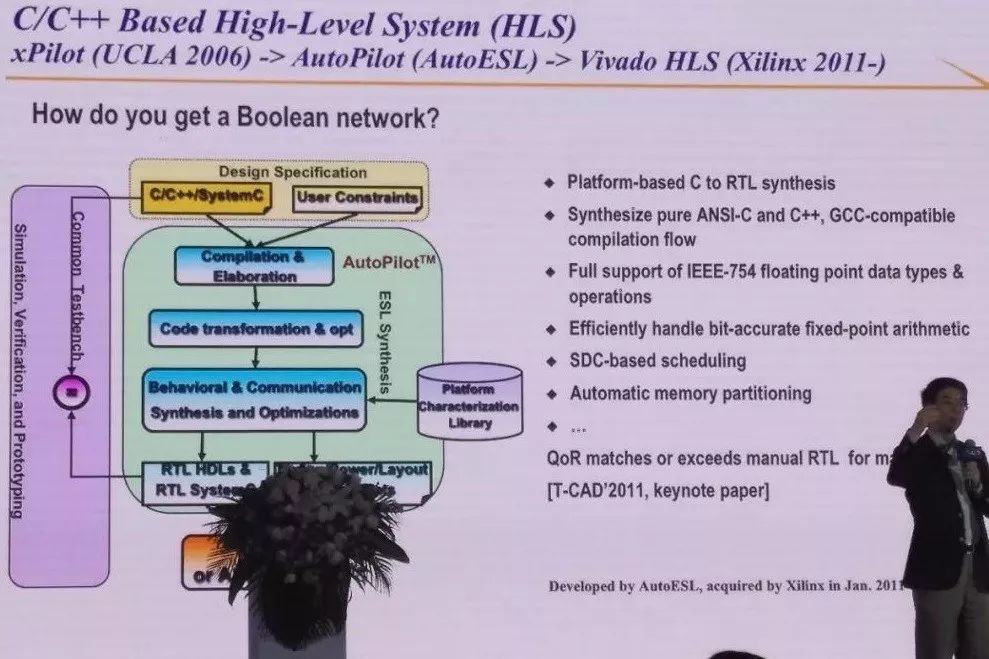
我1992年的一個工作就是,你給我任何一個布林電路,我可以生成最快的FPGA,叫做FlowMap,今天所有的FPGA工作裡都用我們這個演演算法。那你要問,布林電路從哪來,不用手寫,只要寫一個C程式,我們就可以最佳化成很好的布林電路,這叫高層綜合。

我們做了一個研究上的示範性的工作,後來有一個小型的技術轉讓公司,後來就被全球最大的FPGA廠商買下來了。如果你在谷歌裡搜尋一下,光是論文用到HLS(High-level synthesis)的就有兩千五百多篇了。
但是直接拿來用還是有問題的,寫一段基因分析的C程式,它馬上給你一個電路,但是往往這個效果不是很好,要慢有上百倍,因為很多微處理結構沒有考慮到。
我們的研究生也是寫C程式,但是他加了各種各樣的程式碼,指揮定義高層綜合怎麼生成體系結構,首先要考慮要做到有並行,考慮資料能重用,還要考慮到做流水,把這些都加上之後,確實可以做出來有十倍的加速,但是這個過程不是所有的IT工作者都能做的,因為你要對體系結構非常清楚。

為了把這個事情簡單化,我們又開發了一個軟體,一開始也是在學校裡開發的,英特爾、百度、華為都是使用者,這樣寫一個C程式,就生成了加速器和CPU可以協同工作,像我講到的各種各樣的最佳化都在裡面了。

更重要的是,現在我們加到人工智慧的因素,剛才講到怎麼定義各種各樣的微處理架構,把讀資料、計算和存資料並行,這些體系結構的搜尋可以用AI的辦法做下來。
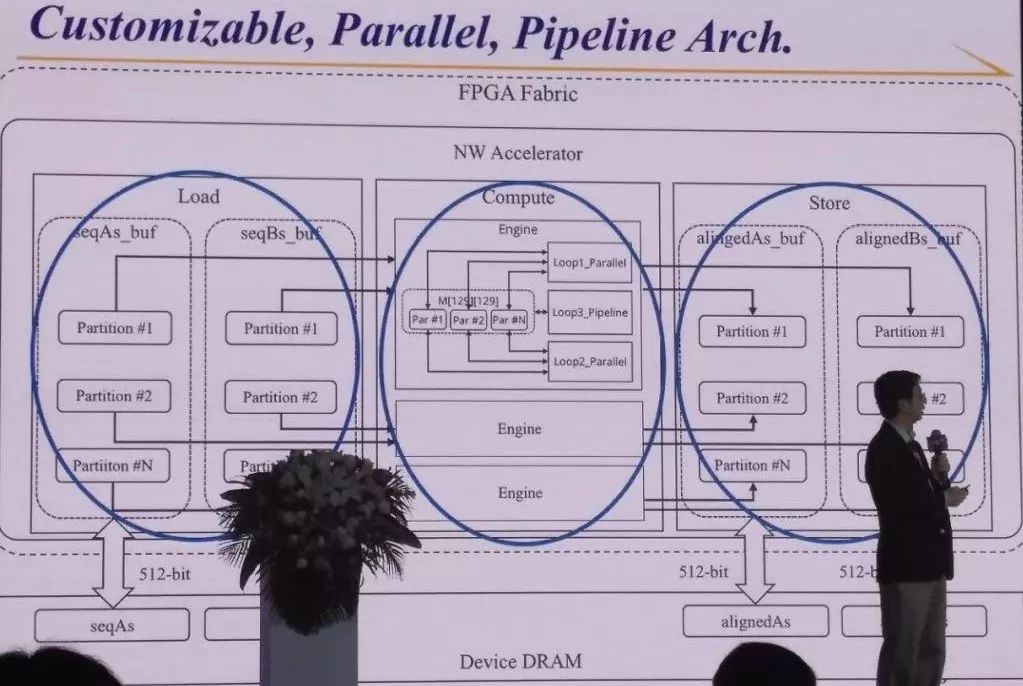
我們做的結果跟手工最佳化已經很接近了,有一兩個例子做的更好,透過這種工具,我希望大家都可以很簡單的用上高階的軟體做可定製計算。
最後舉個例子,在座很多人知道大資料處理有效的計算平臺Spark,Spark程式可以翻譯成C程式,但如果簡單的翻譯就慢了幾百倍,但是用到最佳化平臺提高了十倍。

我的演講就到這裡,希望大家記幾個點:一,深度學習從大資料和大計算來完成的。二,神經網路的複雜性增長的非常之快,我覺得可定製計算一定需要達到人工智慧所需要計算能力。
最後,人工智慧反過來給我們不少新的提示,怎麼來自動設計我們的加速器。感謝實驗室很多的研究生、博士後和合作者,包括給我們提供贊助的夥伴。
關於作者:叢京生(Jason Cong),美國工程院院士,加州大學洛杉磯分校教授,《可定製計算》作者。他的研究領域涉及VLSI電路和系統綜合、可程式設計系統、新型計算體系結構、奈米系統以及高度可擴充套件演演算法。
延伸閱讀《可定製計算》
推薦語:叢京生教授領銜撰寫,涵蓋處理器核的定製、松耦合計算引擎、片上儲存器定製和互連定製等內容。全書緊跟新近研究動態,主要內容包括處理器核的定製、松耦合計算引擎、片上儲存器定製和互連定製等,不僅涵蓋對核心技術的探討,還分析了一些成功的設計案例,為計算機體系結構研究人員提供了迎接未來挑戰的有益參考。

更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 可定製計算會給AI發展帶來哪些影響?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

