來自:從此啟程
連結http://www.cnblogs.com/fancunwei/p/9581168.html
爬蟲系統的意義
爬蟲的意義在於採集大批次資料,然後基於此進行加工/分析,做更有意義的事情。谷歌,百度,今日頭條,天眼查都離不開爬蟲。
標的
我們來實踐一個最簡單的爬蟲系統。根據Url來識別網頁內容。
網頁內容識別利器:HtmlAgilityPack
GitHub地址:https://github.com/zzzprojects/html-agility-pack
HtmlAgilityPack官網:http://html-agility-pack.net/
HtmlAgilityPack的stackoverflow地址:
https://stackoverflow.com/questions/846994/how-to-use-html-agility-pack
至今Nuget已有超過900多萬的下載量,應用量十分龐大。它提供的檔案教程也十分簡單易用。
Parser解析器
HtmlParse可以讓你解析HTML並傳回HtmlDocument
-
FromFile從檔案讀取
///
/// 從檔案讀取
///
public void FromFile() {
var path = @”test.html”;
var doc = new HtmlDocument();
doc.Load(path);
var node = doc.DocumentNode.SelectSingleNode(“//body”);
Console.WriteLine(node.OuterHtml);
}
-
從字串載入
///
/// 從字串讀取
///
public void FromString()
{
var html = @”
This is bold heading
This is underlined paragraph
This is italic heading
“;
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlBody = htmlDoc.DocumentNode.SelectSingleNode(“//body”);
Console.WriteLine(htmlBody.OuterHtml);
}
-
從網路載入
///
/// 從網路地址載入
///
public void FromWeb() {
var html = @”https://www.cnblogs.com/”;
HtmlWeb web = new HtmlWeb();
var htmlDoc = web.Load(html);
var node = htmlDoc.DocumentNode.SelectSingleNode(“//div[@id=’post_list’]”);
Console.WriteLine(“Node Name: ” + node.Name + ”
” + node.OuterHtml);
}
Selectors選擇器
選擇器允許您從HtmlDocument中選擇HTML節點。它提供了兩個方法,可以用XPath運算式篩選節點。
XPath教程:http://www.w3school.com.cn/xpath/index.asp
-
SelectNodes() 傳回多個節點
-
SelectSingleNode(String) 傳回單個節點
簡介到此為止,更全的用法參考 http://html-agility-pack.net
檢視網頁結構
我們以部落格園首頁為示例。用chrome分析下網頁結構,可採集出推薦數,標題,內容Url,內容簡要,作者,評論數,閱讀數。
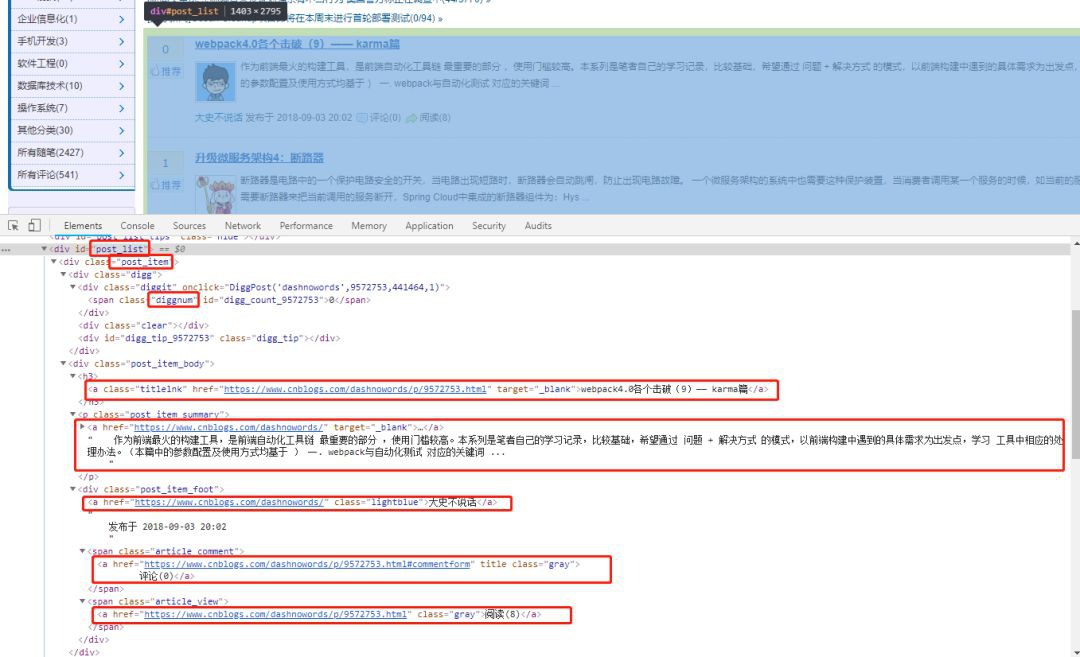
編碼實現
建立一個Article用來接收文章資訊。
public class Article
{
public string Id { get; set; }
///
/// 標題
///
public string Title { get; set; }
///
/// 概要
///
public string Summary { get; set; }
///
/// 文章連結
///
public string Url { get; set; }
///
/// 推薦數
///
public long Diggit { get; set; }
///
/// 評論數
///
public long Comment { get; set; }
///
/// 閱讀數
///
public long View { get; set; }
///
///明細
///
public string Detail { get; set; }
///
///作者
///
public string Author { get; set; }
///
/// 作者連結
///
public string AuthorUrl { get; set; }
}
然後根據網頁結構,檢視XPath路徑,採集內容
///
/// 解析
///
///
public List
{
var url = “https://www.cnblogs.com”;
HtmlWeb web = new HtmlWeb();
//1.支援從web或本地path載入html
var htmlDoc = web.Load(url);
var post_listnode = htmlDoc.DocumentNode.SelectSingleNode(“//div[@id=’post_list’]”);
Console.WriteLine(“Node Name: ” + post_listnode.Name + ”
” + post_listnode.OuterHtml);
var postitemsNodes = post_listnode.SelectNodes(“//div[@class=’post_item’]”);
var articles = new List
var digitRegex = @”[^0-9]+”;
foreach (var item in postitemsNodes)
{
var article = new Article();
var diggnumnode = item.SelectSingleNode(“//span[@class=’diggnum’]”);
//body
var post_item_bodynode = item.SelectSingleNode(“//div[@class=’post_item_body’]”);
var titlenode = post_item_bodynode.SelectSingleNode(“//a[@class=’titlelnk’]”);
var summarynode post_item_bodynode.SelectSingleNode(“//p[@class=’post_item_summary’]”);
//foot
var footnode = item.SelectSingleNode(“//div[@class=’post_item_foot’]”);
var authornode = footnode.ChildNodes[1];
var commentnode = item.SelectSingleNode(“//span[@class=’article_comment’]”);
var viewnode = item.SelectSingleNode(“//span[@class=’article_view’]”);
article.Diggit = int.Parse(diggnumnode.InnerText);
article.Title = titlenode.InnerText;
article.Url = titlenode.Attributes[“href”].Value;
article.Summary = titlenode.InnerHtml;
article.Author = authornode.InnerText;
article.AuthorUrl = authornode.Attributes[“href”].Value;
article.Comment = int.Parse(Regex.Replace(commentnode.ChildNodes[0].InnerText, digitRegex, “”));
article.View = int.Parse(Regex.Replace(viewnode.ChildNodes[0].InnerText, digitRegex, “”));
articles.Add(article);
}
return articles;
}
檢視採集結果
看到結果就驚獃了,竟然全是重覆的。難道是Xpath語法理解不對麼? 採集結果

重溫下XPath語法
XPath 使用路徑運算式在 XML 檔案中選取節點。節點是透過沿著路徑或者 step 來選取的

XPath 萬用字元可用來選取未知的 XML 元素

我測試了幾個語法如:
//例1,會傳回20個
var titlenodes = post_item_bodynode.SelectNodes(“//a[@class=’titlelnk’]”);
//會報錯,因為這個a並不直接在bodynode下麵,而是在子級h3元素的子級。
var titlenodes = post_item_bodynode.SelectNodes(“a[@class=’titlelnk’]”);
然後又實驗了一種:
//Bingo,這個可以,但是強烈指定了下級h3,這就稍微麻煩了點。
var titlenodes = post_item_bodynode.SelectNodes(“h3//a[@class=’titlelnk’]”);
這裡就引申出了一個小問題:如何定位子級的子級?用萬用字元*可以麼?
//傳回1個。
var titlenodes= post_item_bodynode.SelectNodes(“*//a[@class=’titlelnk’]”)
能正確傳回1,應該是可以了,我們改下程式碼看下效果。
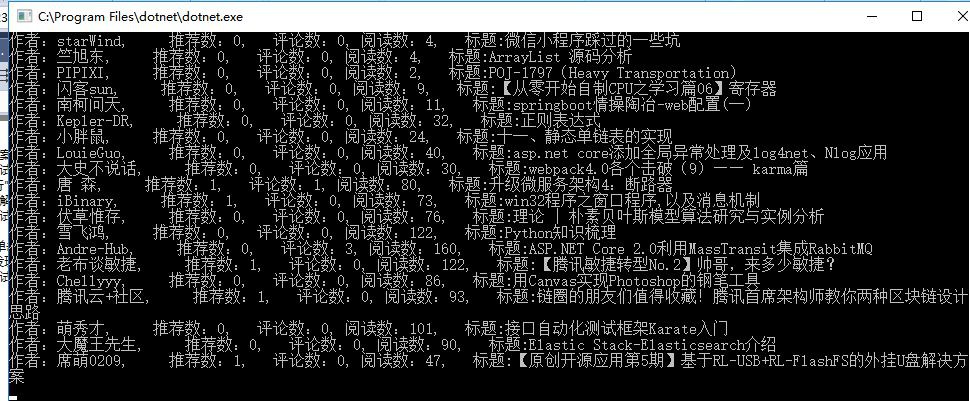
然後和部落格園首頁資料對比,結果吻合。 所以我們可以得出結論:
-
XPath搜尋以//開頭時,會匹配所有的項,並不是子項。
-
直屬子級可以直接跟上 node名稱。
-
只想查子級的子級,可以用*代替子級,實現模糊搜尋。
改過後程式碼如下:
public List
ParseCnBlogs() {
var url = “https://www.cnblogs.com”;
HtmlWeb web = new HtmlWeb();
//1.支援從web或本地path載入html
var htmlDoc = web.Load(url);
var post_listnode = htmlDoc.DocumentNode.SelectSingleNode(“//div[@id=’post_list’]”);
//Console.WriteLine(“Node Name: ” + post_listnode.Name + ”
” + post_listnode.OuterHtml);var postitemsNodes = post_listnode.SelectNodes(“div[@class=’post_item’]”);
var articles = new List
(); var digitRegex = @”[^0-9]+”;
foreach (var item in postitemsNodes)
{
var article = new Article();
var diggnumnode = item.SelectSingleNode(“*//span[@class=’diggnum’]”);
//body
var post_item_bodynode = item.SelectSingleNode(“div[@class=’post_item_body’]”);
var titlenode = post_item_bodynode.SelectSingleNode(“*//a[@class=’titlelnk’]”);
var summarynode = post_item_bodynode.SelectSingleNode(“p[@class=’post_item_summary’]”);
//foot
var footnode = post_item_bodynode.SelectSingleNode(“div[@class=’post_item_foot’]”);
var authornode = footnode.ChildNodes[1];
var commentnode = footnode.SelectSingleNode(“span[@class=’article_comment’]”);
var viewnode = footnode.SelectSingleNode(“span[@class=’article_view’]”);
article.Diggit = int.Parse(diggnumnode.InnerText);
article.Title = titlenode.InnerText;
article.Url = titlenode.Attributes[“href”].Value;
article.Summary = titlenode.InnerHtml;
article.Author = authornode.InnerText;
article.AuthorUrl = authornode.Attributes[“href”].Value;
article.Comment = int.Parse(Regex.Replace(commentnode.ChildNodes[0].InnerText, digitRegex, “”));
article.View = int.Parse(Regex.Replace(viewnode.ChildNodes[0].InnerText, digitRegex, “”));
articles.Add(article);
}
return articles;
}
原始碼
程式碼已上傳至 GitHub:https://github.com/fancunwei/CsharpFanDemo
總結
Demo到此結束,下篇繼續構思如何構建自定義規則,讓使用者可以在頁面自己填寫規則去識別。
●編號151,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
