(點選上方公號,快速關註我們)
英文:Vinod Kumar,轉自:資料派(ID:datapi),翻譯:季洋
大資料和機器學習都是和資料打交道。因此,在系統中保持資料的正確性就非常重要。如果資料不準確,不僅僅會降低系統的效率,還會得到一些不恰當的觀點。透過資料質量和驗證是確保資料正確性的重要步驟之一。隨著資料量的不斷增加,噪聲資料也隨之而來,每天都要引入新的方法和檢驗以確保資料的質量。由於資料量巨大,需要考慮的另一件事是如何確保快速處理這些檢查和驗證;例如,一個系統採用高分散式的方法來遍歷每一條進入系統的資料。本文將講述關於資料質量和驗證檢查的一些例子,以及在Apache Spark和Scala的幫助下運用程式來確保資料質量是多麼簡單。
資料準確性:指的是觀測結果和真實值或可接受為真的值之間的接近度。
-
空值: 包含空值(null)的記錄。如: male/female/null

-
特定值: 某公司的ID號。

樣式驗證:每一批資料必須遵循相同的列名和資料型別。

同列下的值重覆(如記錄中重覆的email)

唯一性檢查: 各記錄關於某列值是唯一不重覆的,這一點和重覆性檢查類似。

正確性檢查:可以使用正則運算式進行檢查。例如,我們可以查詢包含@的電子郵件id。

資料的普及性:你的資料有多及時?假定每天都有資料進入,隨後要檢查資料並打上時間戳。
資料的質量和驗證檢查的條目可以源源不絕,但是基於Spark和Scala的方法的好處是,用較少的程式碼,可以利用海量的資料達到更多目的。
有些時候,一個系統可能有某些特定的需求,這與誰需要這些資料以及以什麼形式資料有關;同時這些資料使用者會對資料提出假設。
資料的可用性: 使用者可能對資料有特定要求,如:
-
列1的值不等於列2的值
-
列3的值應該等於列1的值加上列2的值
-
列x的值不應該超過x%的時間

然而這些被看作基本的資料驗證,還有一些更高階別的檢查來確保資料的質量,如:
-
異常監測:這包括兩個主要方面:
比如給定維度,如基於時間的異常。這意味著在任何指定時間範圍內(時間片段),記錄數不能超過平均值的x%。為了做到這點,運用Spark做法如下:
-
假定時間片段為1分鐘。
-
首先,需要對時間戳列進行過濾和格式化處理,如此時間戳才能以分鐘為單位表示出來。這將產生重覆,但是這應該不是問題。
-
接下來,運用groupBy,
-
如下:
sampledataframe.groupBy(“timestamp”).count()。
-
算出平均值,同時找出記錄數超出均值x%的那些時間片段(如果存在的話)。
-
排序
記錄應該遵循一定的順序。例如,在一天內,某個消費者的資料記錄應該是從產生興趣開始,點選,載入頁面,加入購物車,最後以購買結束。這些可能只是部分記錄,但它們應該遵循一定的順序。為了檢查順序,運用Spark做法如下:
-
groupBy(“ID”) – 以序列號分組
-
對每一分組執行排序檢查
-
迴圈依賴:讓我用一個例子來解釋這點。
-
如果從列A到列B中取出兩列,記錄如下:
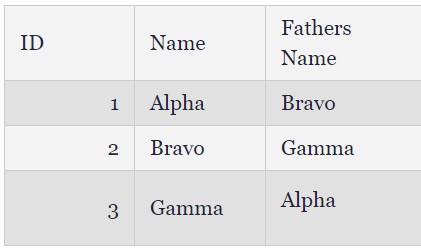
-
如果應用程式要得到家庭關係結構,這會形成一個環狀依賴關係。
-
故障趨勢
考慮到每天都有資料進入系統。讓我們設想它的行為或接觸點資料。為了簡單起見,我們將每天的資料稱為一‘批’。在每一批資料中,如果我們都會得到一組完全相同的故障,則一定存在跨批次的故障趨勢。
如果故障是源於相同的一組email_id(郵箱號為一列欄位),則這可能是自動程式行為的徵兆。
-
資料偏倚:這意味著在圖形上資料呈現一個連續的偏差。如:
如果向時間戳上加上30分鐘,那麼所有的記錄都會有這30分鐘的隱形偏倚。如此一來,如果預測演演算法想要使用這些資料,這種偏差將影響結果。
如果用來生成這些資料的演演算法有學習偏差,那麼對一組資料會生成更多的預設值,隨後用於其他資料。例如基於購買行為,它會預測出錯誤的購買者性別。
自動程式行為: 通常,一個自動程式行為如下:
-
它使用相同的唯一識別符號生成記錄。像前文提到的同一組email_id。
-
它會在任何特定時間生成網路流量。這是基於時間的異常現象。
-
它生成的記錄有固定順序:跨資料批次的順序檢查。
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

