1 前言
說起linux內核的棧回溯功能,我想這對每個Linux核心或驅動開發人員來說,太常見了。如下演示的是linux核心崩潰的一個棧回溯列印,有了這個崩潰列印我們能很快定位到在核心哪個函式崩潰,大概在函式什麼位置,大大簡化了問題排查過程。

網上或多或少都能找到棧回溯的一些文章,但是講的都並不完整,沒有將核心棧回溯的功能用於實際的核心、應用程式除錯,這是本篇文章的核心:盡可能引導讀者將棧回溯的功能用於實際專案除錯,棧回溯的功能很強大。
本文詳細講解了基於mips、arm架構linux核心棧回溯原理,透過不少例子,盡可能全面給讀者展示各種棧回溯的原理,期望讀者理解透徹棧回溯。在這個基礎上,講解筆者近幾年專案開發過程中使用linux核心棧回溯功能的幾處重點應用。
1 當核心某處陷入死迴圈,有時執行sysrq的核心執行緒棧回溯功能可以排查,但並不適用所用情況,筆者實際專案遇到過。最後是在系統定時鐘中斷函式,對死迴圈執行緒棧回溯20多級終於找到死迴圈的函式。
2 當應用程式段錯誤,核心捕捉到崩潰,對崩潰的應用空間行程/執行緒棧回溯,像核心棧回溯一樣,列印應用段錯誤行程/執行緒的層層函式呼叫關係。雖然運用core檔案分析或者gdb也很簡便排查應用崩潰問題,但是對於不容易復現、測試部偶先的、客戶現場偶先的,這二者就很難發揮作用。還有就是如果崩潰發生在C庫中,CPU的pc和lr(arm架構)暫存器指向的函式指令在C庫的使用者空間,很難找到應用的程式碼哪裡呼叫了C庫的函式。arm架構網上能找到應用層棧回溯的例子,但是編譯較麻煩,程式碼並不容易理解,況且mips能在應用層實現嗎?還是在核心實現應用程式棧回溯比較方便。
3 應用程式發生double free,運用內核的棧回溯功能,找到應用程式碼哪裡發生了double free。double free是C庫層發現並截獲該事件,然後向當前行程/執行緒傳送SIGABRT行程終止訊號,後續就是核心強制清理該行程/執行緒。double free比應用程式段錯誤更麻煩,後者核心還會打印出錯行程/執行緒名字、pid、pc和lr暫存器值,double free這些列印全沒有。筆者做過的一個專案,釋出前,遇到一例double free崩潰問題,極難復現,當初要是把double free核心對出問題行程/執行緒棧回溯的功能做進核心,就能找到出問題的應用函式了。
4 當應用程式出現鎖死問題,對應用所有執行緒棧回溯,分析每個執行緒的函式執行流程,對查詢鎖死問題有幫助。
以上幾例應用,在筆者所做的專案中,核心已經合入相關程式碼,功能得到驗證。
2 棧回溯的原理解釋
2.1 基於fp棧幀暫存器形式的棧回溯
筆者最初學習棧回溯,首先看到的資料就是arm架構基於fp暫存器的棧回溯,這種資料網上比較多,這裡按照自己理解再描述一遍。這種形式的棧回溯相對來說並不複雜,也容易理解,遵循APCS(ARM Procedure Call Standard)規範, APCS規範了arm暫存器的使用、函式呼叫過程出棧和入棧的約定。如下圖所示,是一個傳統的arm架構下函式棧資料分佈,函式棧由fp和sp暫存器分別指向棧底和棧頂(這裡舉的例子函式無形參,無區域性變數,方便理解)。

透過fp暫存器就可以找到儲存在棧中lr暫存器資料,這個資料就是函式傳回地址。同時也可以找到儲存在函式棧中的上一級函式fp暫存器資料,這個資料指向了上一級函式的棧底,如此就可以按照同樣的方法找出上一級函式棧中儲存的lr和fp資料,就知道哪個函式呼叫了上一級函式以及這個函式的棧底地址。這樣就構成了一個棧回溯過程,整個流程以fp為核心,依次找出每個函式棧中儲存的lr和fp資料,計算出函式傳回地址和上一級函式棧底地址,從而找出每一級函式呼叫關係。
為了使讀者理解更充分,舉一個簡單的例子。以C函式呼叫了B函式為例,兩個函式無形參,無區域性變數,此時的入棧情況最簡單。兩個函式以偽程式碼的形式列出,演示入棧過程,暫存器的入棧及賦值,與實際的彙編程式碼有偏差。

假設C函式的棧底地址是0x7fff001c,C函式的前5條入棧指令執行後,pc等暫存器的值儲存到C函式棧中,此時fp暫存器的值是C函式棧底地址0x7fff001c。然後C函式跳轉到B函式,B函式前5條指令執行後,pc、lr、fp暫存器的值依次儲存到B函式棧中:B函式棧的第二片記憶體儲存的就是lr值,即B函式的傳回地址;第四片記憶體儲存的是fp值,就是C函式棧底地址0x7fff001c(在開始執行B函式指令前,fp暫存器的值是C函式的棧底地址,B函式的第4條指令又是令fp暫存器入棧);B函式第五條指令執行後,fp暫存器已經更新,其資料是B函式棧的棧底地址0x7fff000c。當B函式發生崩潰,根據fp暫存器找到B函式棧底地址,從B函式棧第二片記憶體取出的資料就是lr,即B函式傳回地址,第4片記憶體取出的資料就是fp,即C函式棧底地址。有了C函式棧底地址,就能按照上述方法找出C函式棧中儲存的的lr和fp,實現棧回溯…..

2.2 unwind 形式的棧回溯
在arm架構下,不少32位系統用的是unwind形式的棧回溯,這種棧回溯要複雜很多。首先需要程式有一個特殊的段.ARM.unwind_idx 或者.ARM.unwind_tab,linux核心本身由多段組成,比如核心驅動初始化函式的init段。在System.map檔案可以搜尋到__start_unwind_idx,這就是ARM.unwind_idx段的起始地址。這個unwind段中儲存著跟函式入棧相關的關鍵資料。當函式執行入棧指令後,在unwind段會儲存跟入棧指令一一對應的編碼資料,根據這些編碼資料,就能計算出當前函式棧大小和cpu的哪些暫存器入棧了,在棧中什麼位置。當棧回溯時,首先根據當前函式中的指令地址,就可以計算出函式unwind段的地址,然後從unwind段取出跟入棧有關的編碼資料,根據這些編碼資料就能計算出當前函式棧的大小以及入棧時lr暫存器資料在棧中的儲存地址。這樣就可以找到lr暫存器資料,就是當前函式傳回地址,也就是上一級函式的指令地址。此時sp一般指向的函式棧頂,sp+函式棧大小就是上一級函式的棧頂。這樣就完成了一次棧回溯,並且知道了上一級函式的指令地址和棧頂地址,按照同樣的方法就能對上一級函式棧回溯,類推就能實現整個棧回溯流程。為了方便理解,下方舉一個實際除錯的示例。該示例中首先列出棧回溯過程每個函式unwind段的編碼資料和棧資料。
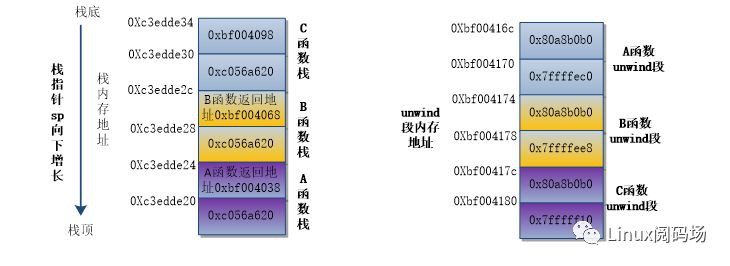
假設函式呼叫過程C->B->A,另外每個函式中只有一個printk列印。這種情況下函式的入棧和unwind段的資訊就很規則和簡單,這裡就以簡單的來講解,便於理解。此時每個函式第一條指令一般是push{r4,lr},這表示將lr和r4暫存器入棧,此時系統會將跟push{r4,lr}指令相關的編碼資料0x80a8b0b0存入C函式的unwind段中,0x7fffff10跟偏移有關,但是實際用處不大。0x80a8b0b0分離成0x80,0xa8 ,0xb0又有不同的意義,最重要的是0xa8,表示出棧指令pop {r4 r14},r14就是lr暫存器,與push{r4,lr}入棧指令正好相反。C函式跳轉到B函式後,會把B函式的傳回地址0xbf004068存入B函式棧。B函式按照同樣的方法執行,當執行到A函式最後,幾個函式的棧資訊和unwind段資訊就如圖所示。假設在A函式中崩潰了,會首先根據崩潰的pc值,找到崩潰A函式的unwind段(每個函式的指令地址和unwind段都是對應的,內核有標準的函式可以查詢)。如圖所示,從地址0xbf00416c的A函式unwind段中取出資料0x80a8b0b0,分析出其中的0xa8,就知道對應的pop {r4 r14}出棧指令,相應就知道函式入棧時執行的是push{r4,lr}指令,其中有兩個重要資訊,一個是函式入棧時只有lr和r4暫存器入棧,並且函式棧大小是2*4=8個位元組,函式崩潰時棧指標sp指向崩潰函式A的棧頂,根據sp就能找到lr暫存器儲存在A函式棧的資料0xbf004038,就是崩潰函式的傳回地址,上一級函式B的指令地址,而sp+ 2*4就是上一級B函式的棧頂。知道了B函式的指令地址和棧頂地址,就能根據指令地址找到B函式的unwind段,分析出B函式的入棧指令,按照同樣的方法,就能找到C函式的傳回地址和棧頂。這隻是幾個很簡單unwind棧回溯過程的演示,省去了很多細節,讀者想研究清楚的話,可以閱讀核心arm架構unwind_frame函式實現流程,其中最核心的是在unwind_exec_insn函式,根據0xa8,0xb0這些跟函式入棧過程有關的編碼資料,分析入棧過程的詳細資訊,計算出函式lr暫存器儲存在棧中的地址和上一級函式的棧頂地址。
不同的入棧指令在函式的unwind段對應不同的編碼,0x80a8b0b0只是其中比較簡單的的編碼,還有0x80acb0b0,0x80aab0b0等等很多。可以執行readelf -u .ARM.unwind_idx vmlinux檢視核心init段函式的unwind段資料。比如:

這就表示match_dev_by_uuid函式在unwind段編碼資料是0x808ab0b0,0xc0008af8是該函式指令首地址。其中有用的是0xa8 ,表示pop {r4,r14}出棧指令,0xb0表示unwind段結束。
為了方便讀者分析對應的棧回溯核心原始碼,這裡把關鍵點列出,並新增必要註釋。核心版本3.10.104。
arch/arm/kernel/unwind.c


2.3 fp和unwind形式棧回溯的比較
上文介紹了兩種常用的棧回溯形式的基本原理,並輔助了例子說明。基於fp暫存器的棧回溯和unwind形式的棧回溯,各有優點和缺點。fp形式的棧回溯,基於APCS規範,入棧過程必須要將pc、lr、fp等4個暫存器入棧(其實沒必要這樣做,只需把lr和fp入棧),並且消耗的入棧指令要多(除了入棧pc、lr、fp等4個暫存器,還得將棧底地址儲存到fp),同時還浪費了暫存器,至少fp暫存器是浪費了,不能參與指令資料運算,CPU暫存器是很寶貴的,多一個對加快指令資料運算是有積極意義的。而unwind形式的棧回溯,就沒有這些缺點,僅僅只是將入棧相關的指令的編碼儲存到unwind段中,不用把無關的暫存器儲存到棧中,也不用浪費fp暫存器。unwind形式棧回溯是有缺點的,首先棧回溯的速度肯定比fp形式棧回溯慢,理解難度要比fp形式大很多,並且,站在開發者角度,使用前還得對每個入棧指令編碼,這都是需要工作量的。但是站在使用者角度,這些缺點影響並不大,所以現在有很多arm32系統用的是unwind形式的棧回溯。
3 linux核心棧回溯的原理
當核心崩潰,將會執行異常處理程式,這裡以mips架構為例,崩潰函式執行流程是:
do_page_fault()->die()->show_registers()->show_stacktrace()->show_backtrace()
棧回溯的過程就是在show_backtrace()函式,arm架構最終是在dump_backtrace()函式,核心崩潰處理流程與mips不同。arm架構棧回溯過程相對來說更簡單,首先講解arm架構的棧回溯過程。
不同核心版本,核心程式碼有差異,本核心版本3.10.104
3.1 arm架構核心棧回溯的分析
核心實際的棧回溯程式碼還是有點複雜的,在正式講解程式碼前,先透過一個簡單演示,進一步詳細的介紹棧回溯的原理。這次演示是基於fp形式的棧回溯,與上文介紹傳統的fp形式棧回溯稍有差異,但是原理是一樣的。
下方以偽彙編指令,演示一個完整的函式指令執行與跳轉流程:C函式執行B函式,B函式執行A函式,然後A函式發生空指標崩潰。

為了幫助讀者理解,做一下解釋,以C函式的第一條指令為例:
0x00034: C函式傳回地址lr入棧指令; C函式指令1
0x00034:表示彙編指令的記憶體地址,反彙編的讀者應該熟悉
C函式傳回地址lr入棧指令:表示具體指令的意思,不再用實際彙編指令表示,理解簡單
C函式指令1:表示C函式第一條指令,為了取用的簡單
其中提到的lr,做過arm核心開發的讀者肯定熟悉,是CPU的一個暫存器,儲存函式傳回地址,當C函式跳轉到B函式時,CPU自動將C函式的指令地址0x00048存入lr暫存器,這表示B函式執行完傳回後,CPU將從0x00048地址取指令繼續執行(mips架構是ra暫存器,先以arm為例)。fp暫存器也是arm架構的一個CPU暫存器,英文釋義是frame point,中文有稱為棧幀暫存器,我們這裡用來儲存每個函式棧的第2片記憶體地址(一片記憶體地址4個位元組,這樣稱呼是為了敘述方便),下方有詳細講解。為了方便讀者理解,特畫出函式執行過程函式棧資料示意圖。

矩形框表示函式棧,初始化全為0,0x1000、0x1004等表示函式棧處於記憶體的地址,函式棧向下增長。每個函式前兩條指令都是入棧指令,每個函式指令執行後只佔用兩片記憶體。由於C函式是初始函式,棧回溯過程C函式棧意義不大,就從C函式跳轉到B函式指令開始分析。此時fp暫存器儲存的資料是C函式棧地址0x1010,原因下文會分析到。當執行C函式指令5,跳轉到B函式後,棧指標sp指向地址0x100C(先假設,下文的講解可以驗證),B函式的傳回地址也就是C函式的指令6的地址0x00048就會自動儲存到CPU的lr暫存器,然後執行B函式指令1, 就會將0x00048存入B函式棧地址0x100C,棧指標sp減一,指向B函式棧地址0X1008。接著執行B函式的指令2,將fp暫存器中的資料0x1010存入棧指標sp指向的記憶體地址0x1008,示意圖已經標明。接著執行B函式指令3,將此時棧指標sp指向的地址0x1008(就是B函式的第二片記憶體)存入fp暫存器。指令接著執行,由B函式跳轉到A函式,A函式前三條指令與B函式執行情況類似,重點就三處,A函式棧的第一片記憶體儲存A函式的傳回地址,A函式棧的第二片記憶體儲存B函式棧的第二片記憶體地址,當A函式執行到指令5後,fp暫存器儲存的是A函式棧的第二片記憶體地址,示意圖中全部標出。當A函式執行指令6崩潰,怎麼棧回溯?
A函式崩潰時,按照上文的分析,fp暫存器儲存的資料是A函式棧的第二片記憶體首地址0X1000。0X1000地址中儲存的資料就是B函式的棧地址0x1008(就是B函式的棧的第二片記憶體),0x1000+4=0X1004地址就是A函式棧的第一片記憶體,儲存的資料是A函式的傳回地址0X0030,這個指令地址就是B函式的指令6地址,這樣就知道了時B函式呼叫了A函式。因為此時已經知道了B函式棧的第二片記憶體地址,該地址的資料就是C函式棧的第二片記憶體地址,B函式棧的第一片記憶體地址中的資料是B函式的傳回地址0X0048(C函式的指令6記憶體地址)。這樣就倒著推出函式呼叫關係:A函式ßB函式ßC函式。
筆者認為,這種情況棧回溯的核心是:每個函式棧的第二片記憶體地址儲存的資料是上一級函式棧的第二片記憶體地址,每個函式棧的第一片記憶體地址儲存的資料是函式傳回地址。只要獲取到崩潰函式棧的第二片記憶體地址(此時就是fp暫存器的資料),就能迴圈計算出每一級呼叫的函式。
3.1.1 核心原始碼分析
如果讀者對上一節的演示理解的話,理解下方的原始碼就比較容易。
arch/arm64/kerneltraps.c

核心崩潰時,產生異常,內核的異常處理程式自動將崩潰時的CPU暫存器存入struct pt_regs結構體,並傳入該函式,相關程式碼不再列出。這樣棧回溯的關鍵環節就是紅色標註的程式碼,先對frame.fp,frame.sp,frame.pc賦值。下方進入while迴圈,先執行unwind_frame(&frame;) 找出崩潰過程的每個函式中的彙編指令地址,存入frame.pc(第一次while迴圈是直接where = frame.pc賦值,這就是當前崩潰函式的崩潰指令地址),下次迴圈存入where變數,再傳入dump_backtrace_entry函式,在該函式中列印諸如[

這個列印的其實是在print_ip_sym函式中做的,將ip按照%pS形式列印,就能打印出該函式指令所在的函式,以及相對函式首指令的偏移。棧回溯的重點是在unwind_frame函式。
在正式貼出程式碼前,先介紹一下棧回溯過程的三個核心CPU暫存器:pc、lr、fp。pc指向執行的彙編指令地址;sp指向函式棧;fp是棧幀指標,不同架構情況不同,但筆者認為它是棧回溯過程中,聯絡兩個有呼叫關係函式的紐帶,下麵的分析就能體現出來。
arch/arm64/kernel/stacktrace.c

首先說明一下,這是arm64位系統,一個long型資料8個位元組大小。為了敘述方便,假設核心程式碼的崩潰函式流程還是 C函式->B函式->A函式,在A函式崩潰,最後在unwind_frame函式中棧回溯。
接著針對程式碼介紹棧回溯的原理。第一次執行unwind_frame函式時,第二行,frame->fp儲存的就是崩潰時CPU的fp暫存器的值,就是A函式棧第二片記憶體地址,frame->sp = fp + 0x10賦值後,frame->sp就是A函式的棧底地址;frame->fp= *(unsigned long *)(fp)獲取的是儲存在A函式棧第二片記憶體中的資料,就是呼叫A函式的B函式的棧的第二片記憶體地址;frame->pc = *(unsigned long *)(fp + 8)是獲取A函式棧的第一片記憶體中的資料,就是A函式的傳回地址(就是B函式中指令地址),這樣就知道了是B函式呼叫了A函式;經過一次unwind_frame函式呼叫,就知道了A函式的傳回地址和B函式的棧的第二片記憶體地址,有了B函式棧的第二片記憶體地址,就能按照上述過程推出B函式的傳回地址(C函式的指令地址)和C函式棧的第二片記憶體地址,這樣就知道了時C函式呼叫了B函式,如此迴圈,不管有多少級函式呼叫,都能按照這個規律找出函式呼叫關係。當然這裡的關係是是AßBßC。
為什麼棧回溯的原理是這樣?首先這個原理筆者都是實際驗證過的,細心的讀者應該會發現,這個棧回溯的流程跟前文第2節演示的簡單棧回溯原理一樣。是的,第2節就是筆者按照自己對arm 64位系統棧回溯的理解,用簡單的形式表達出來,還附了演示圖,這裡不瞭解的讀者可以回到第2節分析一下。
3.1.2 arm架構從彙編程式碼角度解釋棧回溯的原理
為了使讀者理解的更充分,下文列出一段應用層C語言程式碼和反彙編後的程式碼
C程式碼

彙編程式碼

分析test_2函式的彙編程式碼,第一條指令stpx29, x30,[sp,#-16],x29就是fp暫存器,x30就是lr暫存器,指令執行過程:將x30(lr)、x29(fp)暫存器的值隨著棧指標sp向下偏移依次入棧,棧指標sp共偏移兩次8+8=16個位元組(arm 64位系統棧指標sp減一偏移8個位元組,並且棧是向下增長,所以指令是-16)。mov x29,sp 指令就是將棧指標賦予fp暫存器,此時sp就指向test_2函式棧的第二片記憶體,因為sp偏移了兩次,fp暫存器的值就是test_2函式棧的第二片記憶體地址。去除不相關的指令,直接從test_2函式跳轉到test_1函式開始分析,看test_1函式的第一條指令stp x29, x30,[sp,#-16],首先棧指標sp減一,將x30(lr)暫存器的資料存入test_1函式棧的第一片記憶體,這就是test_1函式的傳回地址,接著棧指標sp減一,將x29(fp)暫存器值入棧,存入test_1函式的第二片記憶體,此時fp暫存器的值正是test_2函式棧的第二片記憶體地址,本質就是將test_2函式棧的第二片記憶體地址存入test_1函式棧的第二片記憶體中。接著執行mov x29,sp 指令,就是將棧指標sp賦予fp暫存器,此時sp指向test_1函式棧的第二片記憶體…..
這樣就與上一小結的分析一致了, 這裡就對arm棧回溯的一般過程,做個較為系統的總結:當C函式跳轉的B函式時,先將B函式的傳回地址存入B函式棧的第一片記憶體,然後將C函式棧的第二片記憶體地址存入B函式棧的第二片記憶體,接著將B函式棧的第二片記憶體地址存入fp暫存器,B函式跳轉到A函式流程也是這樣。當A函式中崩潰時,先從fp暫存器中獲取A函式棧的第二片記憶體地址,從中取出B函式棧的第二片記憶體地址,再從A函式棧的第一片記憶體取出A函式的傳回地址,也就是B函式中的指令地址,這樣就推匯出B函式呼叫了A函式,同理推匯出C函式呼叫了B函式。
演示的程式碼很簡答,但是這個分析是適用於複雜函式的,已經實際驗證過。
3.1.3 arm 核心棧回溯的“bug”
這個不是我危言聳聽,是實際測出來的。比如如下程式碼:

這個函式呼叫流程在核心崩潰了,核心棧回溯是不會列印上邊的b函式,有arm 64系統的讀者可以驗證一下,我多次驗證得出的結論是,如果崩潰的函式沒有執行其他函式,就會打亂棧回溯規則,為什麼呢?請回頭看上一節的程式碼演示

彙編程式碼是

可以發現,test_a_函式前兩條指令不是stpx29, x30,[sp,#-16]和mov x29,sp,這兩條指令可是棧回溯的關鍵環節。怎麼解決呢?仔細分析的話,是可以解決的。一般情況,函式崩潰,fp暫存器儲存的資料是當前函式棧的第二片記憶體地址,當前函式棧的第一片記憶體地址儲存的是函式傳回地址,從該地址取出的資料與lr暫存器的資料應是一致的,因為lr暫存器儲存的也是函式傳回地址,如果不相同,說明該函式中沒有執行stp x29, x30,[sp,#-16]指令,此時應使用lr暫存器的值作為函式傳回地址,並且此時fp暫存器本身就是上一級函式棧的第二片記憶體地址,有了這個資料就能按照前文的方法棧回溯了。解決方法就是這樣,讀者可以仔細體會一下我的分析。
3.2 mips 棧回溯過程
前文說過,mips核心崩潰處理流程是
do_page_fault()->die()->show_registers()->show_stacktrace()->show_backtrace()
列印崩潰函式流程是在show_backtrace()函式。
3.2.1 mips 架構核心棧回溯原理分析
arch/mips/kernel/ traps.c

可以發現,與arm架構棧回溯流程基本一致。函式開頭是對sp、ra、pc暫存器器賦值,sp和pc與arm架構一致,ra相當於arm架構的lr暫存器,沒有arm架構的fp暫存器。print_ip_sym函式就是根據pc值列印形如[
如下是mips架構核心驅動ko檔案的 C程式碼和彙編程式碼。
C程式碼

彙編程式碼
這裡說明一下,驅動ko反彙編出來的指令是從0地址開始的,為了敘述方便,筆者加了0x80000000,實際的彙編程式碼不是這樣的。

這裡直接介紹根據筆者的分析,總結mips架構核心棧回溯的原理,分析完後再結合原始碼驗證。mips架構沒有fp暫存器,假設在test_c函式中0X80000048地址處指令崩潰了,首先利用內核的kallsyms模組,根據崩潰時的指令地址找出該指令是哪個函式的指令,並且找出該指令地址相對函式指令首地址的偏移ofs,在本案例中ofs = 0X10(0X80000048 – 0X80000038 =0X10),這樣就能算出test_c函式的指令首地址是 0X80000048 – 0X10 = 0X80000038。然後就從地址0X80000038開始,依次取出每條指令,找到addiu sp,sp,-24 和sw ra,20(sp),內核有標準函式可以判斷出這兩條指令,下文可以看到。addiu sp,sp,-24是test_c函式的第一條指令,棧指標向下偏移24個位元組,筆者認為是為test_c函式分配棧大小( 24個位元組);sw ra,20(sp)指令將test_c函式傳回地址存入sp +20 記憶體地址處,此時sp指向的是test_c函式的棧頂,sp+20就是test_c函式棧的第二片記憶體,該函式棧大小24位元組,一共24/4=6片記憶體。
根據sw ra,20(sp)指令知道test_c函式傳回地址在test_c函式棧的儲存位置,取出該地址的資料,就知道是test_a函式的指令地址,當然就知道是test_a函式呼叫了test_c函式。並根據addiu sp,sp,-24指令知道test_c函式棧總計24位元組,因為test_c函式崩潰時,棧指標sp指向test_c函式棧頂,sp+24就是test_a函式的棧頂,因為test_a函式呼叫了test_c函式,兩個函式的棧必是緊挨著的。按照上述推斷,首先知道了test_a函式中的指令地址了,使用核心kallsyms功能就推算出test_a函式的指令首地址,同時也計算出test_a函式的棧頂,就能按照上述規律找出誰呼叫了test_a函式,以及該函式的棧頂。依次就能找出所有函式呼叫關係。
關於內核的kallsyms,筆者的理解是:執行過cat /proc/kallsyms命令的讀者,應該瞭解過,該命令會列印核心所有的函式的首地址和函式名稱,還有核心編譯後生成的System.map檔案,記錄核心函式、變數的名稱與記憶體地址等等,kallsyms也是記錄了這些內容,當執行kallsyms_lookup_size_offset(0X80000048, &size;,&ofs;)函式,就能根據0X80000048指令地址計算出處於test_c函式,並將相對於test_c函式指令首地址的偏移0X10存入ofs,test_c函式指令總位元組數存入size。筆者沒有研究過kallsyms模組,但是可以理解到,內核的所有函式都是按照分配的地址,順序排布。如果記錄了每個函式的首地址和名稱,當知道函式的任何一條指令地址,就能在其中搜索比對,找到該指令處於按個函式,計算出函式首地址,該指令的偏移。
3.2.2 mips 架構核心棧回溯核心原始碼分析
3.2.1詳細講述了mips棧回溯的原理,接著講解棧回溯的核心函式unwind_stack_by_address。




上述原始碼已經在關鍵點做了詳細註釋,其實就是對3.2.1節棧回溯原理的完善,請讀者自己分析,這裡不再贅述。但是有一點請註意,就是藍色註釋,這是針對崩潰的函式沒有執行其他函式的情況,此時該函式沒有類似彙編指令sw ra,20(sp) 將函式傳回地址儲存到棧中,計算方法就變了,要直接使用ra暫存器的值作為函式傳回地址,計算上一級函式棧頂的方法還是一致的,後續棧回溯的方法與前文相同。
4 linux核心棧回溯的應用
文章最開頭說過,筆者在實際專案開發過程,已經總結出了3個核心棧回溯的應用:
1 應用程式崩潰,像核心棧回溯一樣列印整個崩潰過程,應用函式的呼叫關係
2 應用程式發生double free,像核心棧回溯一樣列印double free過程,應用函式的呼叫關係
3 核心陷入死迴圈,sysrq的核心執行緒棧回溯功能無法發揮作用時,在系統定時鐘中斷函式中對卡死執行緒棧回溯,找出卡死位置
下文逐一講解。
4.1 應用程式崩潰棧回溯
筆者在研究過核心棧回溯功能後,不禁發問,為什麼不能用同樣的方法對應用程式的崩潰棧回溯呢?不管是核心空間,應用空間,程式的指令是一樣的,無非是地址有差異,函式入棧出棧原理是一樣的。棧回溯的入口,arm架構是獲取崩潰執行緒/行程的pc、fp、lr暫存器值,mips架構是獲取pc、ra、sp暫存器值,有了這些值就能按照各自的回溯規律,實現棧回溯。從理論上來說,完全是可以實現的。
4.1 .1 arm架構應用程式棧回溯的實現
當應用程式發生崩潰,與核心一樣,系統自動將崩潰時所有的CPU暫存器存入struct pt_regs結構,一般崩潰入口函式是do_page_fault,又因為是應用程式崩潰,所以是__do_user_fault函式,這裡直接分析__do_user_fault。

在該函式中,tsk就是崩潰的執行緒,struct pt_regs *regs就指向執行緒/行程崩潰時的CPU暫存器結構。regs->[29]就是fp暫存器,regs->[30]是lr暫存器, regs->pc的意義很直觀。現在有了崩潰應用執行緒/行程當時的fp、sp、lr暫存器,就能棧回溯了,完全仿照核心dump_backtrace的方法,請看筆者寫在user_thread_ dump_backtrace函式中的演示程式碼。


與核心棧回溯原理一致,列印崩潰過程每個函式的指令地址,然後在應用程式的反彙編檔案中查詢,就能找到該指令處於的函式,如果不理解,請看文章前方講解的核心棧回溯程式碼與原理。請註意,這不是筆者專案實際用的棧回溯程式碼,實際的改動完善了很多,這隻是演示原理的示例程式碼。
還有一點就是,筆者在3.1.3節提到的,假如崩潰的函式中沒有呼叫其他函式,那上述棧回溯就會有問題,就不會列印第二級函式,解決方法講的也有,解決的程式碼這裡就不再列出了。
4.1 .2 mips架構應用程式棧回溯的實現
mips 架構不僅核心棧回溯的程式碼比arm複雜,應用程式的棧回溯更複雜,還有未知bug,即便這樣,還是講解一下具體的解決思路,最後講一下存在的問題。
先簡單回顧一下核心棧回溯的原理,首先根據崩潰函式的pc值,運用核心kallsyms模組,計算出該函式的指令首地址,然後從指令首地址開始分析,找出類似addiu sp,sp,-24和sw ra,20(sp)指令,前者可以找到該函式的棧大小,棧指標sp加上這個數值,就知道上一級函式的棧頂地址(崩潰時sp指向崩潰函式的棧頂);後者知道函式傳回地址在該函式棧中儲存的地址,從該地址就能獲取該函式的傳回地址,就是上一級函式的指令地址,也就知道了上一級函式是哪個(同樣使用核心kallsyms模組)。知道了上一級函式的指令地址和棧頂地址,按照同樣方法,就能知道再上一級的函式…….
問題來了,內核有kallsyms模組記錄了每個函式的首地址和函式名字,函式還是順序排布。應用程式並沒有kallsyms模組,即便知道了崩潰函式的pc值,也無法按照同樣的方法找到崩潰函式的指令首地址,真的沒有方法?其實還有一個最簡單的方法。先列出一段一個應用程式函式的彙編程式碼,如下所示,與核心態的有小的差別。

現在假如從0X4006a4地址處取指,執行後崩潰了。崩潰發生時,能像arm架構一樣獲取崩潰前的CPU暫存器值,最重要就是pc、sp、ra值。pc值就是0X4006a4,然後令一個unsigned long型指標指向該記憶體地址0X4006a4,每次減一,並取出該地址的指令資料分析,這樣肯定能分析到addiu sp,sp,-32 和sw ra,28(sp)指令,我想看到這裡,讀者應該可以清楚方法了。沒錯,就是以崩潰時pc值作為基地址,每次減1並從對應地址取出指令分析,直到分析出久違的addiu sp,sp,-32 和sw ra,28(sp)類似指令,再結合崩潰時的棧指標值sp,就能計算出該函式的傳回地址和上一級函式的棧頂地址。後續的方法,就與核心棧回溯的過程一致了。下方列出演示的程式碼。

為了一致性,應用程式棧回溯的函式還是採用名字user_thread_ dump_backtrace。



如上就是mips應用程式棧回溯的示例程式碼,只是一個演示,筆者實際使用的程式碼要複雜太多。讀者使用時,要基於這個基本原理,多除錯,才能應對各種情況,筆者前後除錯幾周才穩定。由於這個方法並不是標準的,實際使用時還是會出現誤報函式現象,分析了發生誤報的彙編程式碼及C程式碼,發現當函式程式碼複雜時,函式的彙編指令會變得非常複雜,會出現相似指令等等,讀者實際除錯時就會發現。這個mips應用程式棧回溯的方法,可以應對大部分崩潰情況,但是有誤報的可能,最佳化的空間非常大,這點請讀者註意。
4.2 應用程式double free 核心棧回溯
double free是在C庫層發生的,正常情況核心無能為力,但是筆者研究過後,發現照樣可以實現對發生double free應用行程的棧回溯。
以arm架構為例,doublefree C庫層的程式碼,大體原理是,當檢測到double free(本人實驗時,一片malloc分配的記憶體free兩次就會發生),就會執行kill系統呼叫函式,向出問題的行程傳送SIGABRT訊號,既然是系統呼叫,從使用者空間進入核心空間時,就會將應用行程使用者空間執行時的CPU暫存器pc、sp、lr等儲存到行程的核心棧中,傳送訊號核心必然執行send_signal函式。在該函式中,使用struct pt_regs *regs = task_pt_regs(current)方法就能從當前行程核心棧中獲取進入核心空間前,使用者空間執行指令的pc、sp、fp等CPU暫存器值,有了這些值,就能按照使用者空間行程崩潰棧回溯方法一樣,對double free的行程棧回溯了。比如,A函式double free,A函式->C庫函式1-> C庫函式2->C庫函式3(檢測到double free併傳送SIGABRT訊號,執行系統呼叫進入核心空間傳送訊號)。回溯的結果是:C庫函式3 ß C庫函式2 ß C庫函式1ß A函式。
原始碼不再列出,相信讀者理解的話是可以自己開發的。其中task_pt_regs函式的使用,需要讀者對行程核心棧有一定的瞭解。
筆者有個理解,當獲取某個行程執行指令某一時間點的CPU暫存器pc、lr、fp的值,就能對該行程進行棧回溯。
4.3 核心發生死迴圈sysrq無效時棧回溯的應用
內核的sysrq中有一個方法,執行後可以對所有執行緒進行核心空間函式棧回溯,但是本人遇到過一次因某個外設導致的死迴圈,該方法列印的棧回溯資訊都是核心級的函式,沒有頭緒。於是,嘗試在系統定時鐘中斷函式中實現卡死執行緒的棧回溯(也可以在account_process_tick核心標準函式中,系統定時鐘中斷函式會執行到)。原理是,當一個核心執行緒卡死時,首先考慮在某個函式陷入死迴圈,系統定時鐘中斷是不斷產生的,此時current執行緒很大機率就是卡死執行緒(要考慮核心搶佔,核心支援搶佔時,核心某處陷入死迴圈照樣可以排程出去),然後使用struct pt_regs *regs = get_irq_regs()方法,就能獲取中斷前執行緒的pc、sp、fp等暫存器值,有了這些值,就能按照核心執行緒崩潰棧回溯原理,對卡死執行緒函式呼叫過程棧回溯,找到卡死函式。mips架構棧回溯的核心函式show_backtrace()定義如下,只要傳入核心執行緒的struct task_struct和structpt_regs結構,就能對核心執行緒當時指令的執行進行棧回溯。
static void show_backtrace(struct task_struct *task, const struct pt_regs *regs)
4.4 應用程式鎖死時對所有應用執行緒的棧回溯
以arm架構為例。當應用鎖死,尤其是偶現的鎖死卡死問題,可以使用棧回溯的思路解決。以單核CPU為例,應用程式的所有執行緒,正常情況,兩種狀態:正在執行和其他狀態(大部分情況是休眠)。休眠的應用執行緒,一般要先進入核心空間,將應用層執行時的pc、lr、fp等暫存器存入核心棧,執行schdule函式讓出CPU使用權,最後執行緒休眠。此時可以透過tesk_pt_regs函式從執行緒核心棧中獲取執行緒進入核心空間前的pc、lr、fp等暫存器的資料。正在執行的應用執行緒,系統定時鐘中斷產生後,系統要執行硬體定時器中斷,此時可以透過get_irq_regs函式獲取中斷前的pc、lr、fp等暫存器的值。不管應用執行緒是否正在執行,都可以獲取執行緒當時使用者空間執行指令的pc、lr、fp等暫存器資料。當應用某個執行緒,不管是使用鎖異常而長時間休眠,還是陷入死迴圈,從內核的行程執行佇列中,依次獲取到所有應用執行緒的pc、lr、fp等暫存器的資料後(可以考慮在account_process_tick函式實現),就可以按照前文思路對應用執行緒棧回溯,找出懷疑點。
實際使用時,要防止核心執行緒的幹擾,task->mm可以用來判斷,核心執行緒為NULL。當然也可以透過執行緒名字加限制,對疑似的幾個執行緒棧回溯。應用執行緒正在核心空間執行時,這種情況用這個方法就有問題,這時需加限制,比如透過get_irq_regs函式獲取到 pc值後,判斷是在核心空間還是使用者空間。讀者實現該功能時,有不少其他細節要註意,這裡不再一一列出。
5 應用程式棧回溯的展望
關於應用程式的棧回溯,筆者正在考慮一個方法,使應用程式的棧回溯能真正像核心一樣打印出函式的符號及偏移,比如

現有的方法只能實現如下效果:

之後還得對應用程式反彙編才能找到崩潰的函式。
筆者的分析是,理論上是可以實現的,只要仿照內核的kallsyms方法,按照順序記錄每個應用函式的函式首地址和函式名字到一個檔案中,當應用程式崩潰時,核心中讀取這個檔案,根據崩潰的指令地址在這個檔案中搜索,就能找到該指令處於哪個函式中,本質還是實現了與核心kallsyms類似的方法。有了這個功能,不僅應用程式棧回溯能列印函式的名稱與偏移,還能讓mips架構應用程式崩潰的棧回溯按照核心崩潰棧回溯的原理來實現,不會再出現函式誤報現象,不知讀者是否理解我的思路?後續有機會,會嘗試開發這個功能並分享出來。
6總結
實際專案除錯時,發現棧回溯的應用價值非常大,掌握棧回溯的原理,不僅對核心除錯有很大幫助,對加深內核的理解也是有不少益處。
這是本人第一次投稿,經驗不足,文章可能也有失誤的地方,請讀者及時提出,但是筆者保證,文章講解的內容都是經過理論和實際驗證的,不會有原理性偏差。有問題請發往筆者郵箱。後續有機會,筆者會將記憶體管理、檔案系統方面的總結分享出來。