來自:codewill(微訊號:codelynn)

Redis是一個非常火的非關係型資料庫,火到什麼程度呢?只要是一個網際網路公司都會使用到。Redis相關的問題可以說是面試必問的,下麵我從個人當面試官的經驗,總結幾個必須要掌握的知識點。(知識點較多,我整理了個思維導圖,後臺回覆redis,傳送給你)
介紹:Redis 是一個開源的使用 ANSI C 語言編寫、遵守 BSD 協議、支援網路、可基於記憶體亦可持久化的日誌型、Key-Value 資料庫,並提供多種語言的 API的非關係型資料庫。
傳統資料庫遵循 ACID 規則。而 Nosql(Not Only SQL 的縮寫,是對不同於傳統的關係型資料庫的資料庫管理系統的統稱) 一般為分散式而分散式一般遵循 CAP 定理。
Github 原始碼:https://github.com/antirez/redis
Redis 官網:https://redis.io/
01
Redis支援的資料型別?
String字串:
格式: set key value
string型別是二進位制安全的。意思是redis的string可以包含任何資料。比如jpg圖片或者序列化的物件 。
string型別是Redis最基本的資料型別,一個鍵最大能儲存512MB。
Hash(雜湊)
格式: hmset name key1 value1 key2 value2
Redis hash 是一個鍵值(key=>value)對集合。
Redis hash是一個string型別的field和value的對映表,hash特別適合用於儲存物件。
List(串列)
Redis 串列是簡單的字串串列,按照插入順序排序。你可以新增一個元素到串列的頭部(左邊)或者尾部(右邊)
格式: lpush name value
在 key 對應 list 的頭部新增字串元素
格式: rpush name value
在 key 對應 list 的尾部新增字串元素
格式: lrem name index
key 對應 list 中刪除 count 個和 value 相同的元素
格式: llen name
傳回 key 對應 list 的長度
Set(集合)
格式: sadd name value
Redis的Set是string型別的無序集合。
集合是透過雜湊表實現的,所以新增,刪除,查詢的複雜度都是O(1)。
zset(sorted set:有序集合)
格式: zadd name score value
Redis zset 和 set 一樣也是string型別元素的集合,且不允許重覆的成員。
不同的是每個元素都會關聯一個double型別的分數。redis正是透過分數來為集合中的成員進行從小到大的排序。
zset的成員是唯一的,但分數(score)卻可以重覆。
02
什麼是Redis持久化?Redis有哪幾種持久化方式?優缺點是什麼?
持久化就是把記憶體的資料寫到磁碟中去,防止服務宕機了記憶體資料丟失。
Redis 提供了兩種持久化方式:RDB(預設) 和AOF
RDB:
rdb是Redis DataBase縮寫
功能核心函式rdbSave(生成RDB檔案)和rdbLoad(從檔案載入記憶體)兩個函式

AOF:
Aof是Append-only file縮寫

每當執行伺服器(定時)任務或者函式時flushAppendOnlyFile 函式都會被呼叫, 這個函式執行以下兩個工作
aof寫入儲存:
WRITE:根據條件,將 aof_buf 中的快取寫入到 AOF 檔案
SAVE:根據條件,呼叫 fsync 或 fdatasync 函式,將 AOF 檔案儲存到磁碟中。
儲存結構:
內容是redis通訊協議(RESP )格式的命令文字儲存。
比較:
1、aof檔案比rdb更新頻率高,優先使用aof還原資料。
2、aof比rdb更安全也更大
3、rdb效能比aof好
4、如果兩個都配了優先載入AOF
03
剛剛上面你有提到redis通訊協議(RESP ),能解釋下什麼是RESP?有什麼特點?(可以看到很多面試其實都是連環炮,面試官其實在等著你回答到這個點,如果你答上了對你的評價就又加了一分)

RESP 是redis客戶端和服務端之前使用的一種通訊協議;
RESP 的特點:實現簡單、快速解析、可讀性好
For Simple Strings the first byte of the reply is “+” 回覆
For Errors the first byte of the reply is “-” 錯誤
For Integers the first byte of the reply is “:” 整數
For Bulk Strings the first byte of the reply is “$” 字串
For Arrays the first byte of the reply is “*” 陣列
04
Redis 有哪些架構樣式?講講各自的特點
單機版

特點:簡單
問題:
1、記憶體容量有限 2、處理能力有限 3、無法高可用。
主從複製

Redis 的複製(replication)功能允許使用者根據一個 Redis 伺服器來建立任意多個該伺服器的複製品,其中被覆制的伺服器為主伺服器(master),而透過複製創建出來的伺服器複製品則為從伺服器(slave)。 只要主從伺服器之間的網路連線正常,主從伺服器兩者會具有相同的資料,主伺服器就會一直將發生在自己身上的資料更新同步 給從伺服器,從而一直保證主從伺服器的資料相同。
特點:
1、master/slave 角色
2、master/slave 資料相同
3、降低 master 讀壓力在轉交從庫
問題:
無法保證高可用
沒有解決 master 寫的壓力
哨兵

Redis sentinel 是一個分散式系統中監控 redis 主從伺服器,併在主伺服器下線時自動進行故障轉移。其中三個特性:
監控(Monitoring): Sentinel 會不斷地檢查你的主伺服器和從伺服器是否運作正常。
提醒(Notification): 當被監控的某個 Redis 伺服器出現問題時, Sentinel 可以透過 API 向管理員或者其他應用程式傳送通知。
自動故障遷移(Automatic failover): 當一個主伺服器不能正常工作時, Sentinel 會開始一次自動故障遷移操作。
特點:
1、保證高可用
2、監控各個節點
3、自動故障遷移
缺點:主從樣式,切換需要時間丟資料
沒有解決 master 寫的壓力
叢集(proxy 型):

Twemproxy 是一個 Twitter 開源的一個 redis 和 memcache 快速/輕量級代理伺服器; Twemproxy 是一個快速的單執行緒代理程式,支援 Memcached ASCII 協議和 redis 協議。
特點:1、多種 hash 演演算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins
2、支援失敗節點自動刪除
3、後端 Sharding 分片邏輯對業務透明,業務方的讀寫方式和操作單個 Redis 一致
缺點:增加了新的 proxy,需要維護其高可用。
failover 邏輯需要自己實現,其本身不能支援故障的自動轉移可擴充套件性差,進行擴縮容都需要手動幹預
叢集(直連型):
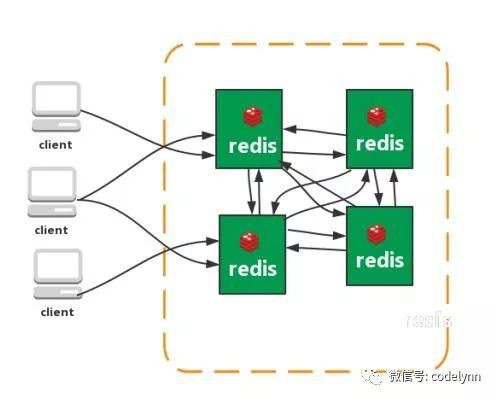
從redis 3.0之後版本支援redis-cluster叢集,Redis-Cluster採用無中心結構,每個節點儲存資料和整個叢集狀態,每個節點都和其他所有節點連線。
特點:
1、無中心架構(不存在哪個節點影響效能瓶頸),少了 proxy 層。
2、資料按照 slot 儲存分佈在多個節點,節點間資料共享,可動態調整資料分佈。
3、可擴充套件性,可線性擴充套件到 1000 個節點,節點可動態新增或刪除。
4、高可用性,部分節點不可用時,叢集仍可用。透過增加 Slave 做備份資料副本
5、實現故障自動 failover,節點之間透過 gossip 協議交換狀態資訊,用投票機制完成 Slave到 Master 的角色提升。
缺點:
1、資源隔離性較差,容易出現相互影響的情況。
2、資料透過非同步複製,不保證資料的強一致性
05
什麼是一致性雜湊演演算法?什麼是雜湊槽?
這兩個問題篇幅過長 網上找了兩個解鎖的不錯的文章
https://www.cnblogs.com/lpfuture/p/5796398.html
https://blog.csdn.net/z15732621582/article/details/79121213
06
Redis是基於CAP理論的,什麼是CAP理論?
可以參考我的上一篇文章。
07
Redis常用命令?
Keys pattern
*表示區配所有
以bit開頭的
檢視Exists key是否存在
Set
設定 key 對應的值為 string 型別的 value。
setnx
設定 key 對應的值為 string 型別的 value。如果 key 已經存在,傳回 0,nx 是 not exist 的意思。
刪除某個key
第一次傳回1 刪除了 第二次傳回0
Expire 設定過期時間(單位秒)
TTL檢視剩下多少時間
傳回負數則key失效,key不存在了
Setex
設定 key 對應的值為 string 型別的 value,並指定此鍵值對應的有效期。
Mset
一次設定多個 key 的值,成功傳回 ok 表示所有的值都設定了,失敗傳回 0 表示沒有任何值被設定。
Getset
設定 key 的值,並傳回 key 的舊值。
Mget
一次獲取多個 key 的值,如果對應 key 不存在,則對應傳回 nil。
Incr
對 key 的值做加加操作,並傳回新的值。註意 incr 一個不是 int 的 value 會傳回錯誤,incr 一個不存在的 key,則設定 key 為 1
incrby
同 incr 類似,加指定值 ,key 不存在時候會設定 key,並認為原來的 value 是 0
Decr
對 key 的值做的是減減操作,decr 一個不存在 key,則設定 key 為-1
Decrby
同 decr,減指定值。
Append
給指定 key 的字串值追加 value,傳回新字串值的長度。
Strlen
取指定 key 的 value 值的長度。
persist xxx(取消過期時間)
選擇資料庫(0-15庫)
Select 0 //選擇資料庫
move age 1//把age 移動到1庫
Randomkey隨機傳回一個key
Rename重新命名
Type 傳回資料型別
08
使用過Redis分散式鎖麼,它是怎麼實現的?
先拿setnx來爭搶鎖,搶到之後,再用expire給鎖加一個過期時間防止鎖忘記了釋放。
如果在setnx之後執行expire之前行程意外crash或者要重啟維護了,那會怎麼樣?
set指令有非常複雜的引數,這個應該是可以同時把setnx和expire合成一條指令來用的!
09
使用過Redis做非同步佇列麼,你是怎麼用的?有什麼缺點?
一般使用list結構作為佇列,rpush生產訊息,lpop消費訊息。當lpop沒有訊息的時候,要適當sleep一會再重試。
缺點:
在消費者下線的情況下,生產的訊息會丟失,得使用專業的訊息佇列如rabbitmq等。
能不能生產一次消費多次呢?
使用pub/sub主題訂閱者樣式,可以實現1:N的訊息佇列。
10
什麼是快取穿透?如何避免?什麼是快取雪崩?何如避免?
快取穿透
一般的快取系統,都是按照key去快取查詢,如果不存在對應的value,就應該去後端系統查詢(比如DB)。一些惡意的請求會故意查詢不存在的key,請求量很大,就會對後端系統造成很大的壓力。這就叫做快取穿透。
如何避免?
1:對查詢結果為空的情況也進行快取,快取時間設定短一點,或者該key對應的資料insert了之後清理快取。
2:對一定不存在的key進行過濾。可以把所有的可能存在的key放到一個大的Bitmap中,查詢時透過該bitmap過濾。
快取雪崩
當快取伺服器重啟或者大量快取集中在某一個時間段失效,這樣在失效的時候,會給後端系統帶來很大壓力。導致系統崩潰。
如何避免?
1:在快取失效後,透過加鎖或者佇列來控制讀資料庫寫快取的執行緒數量。比如對某個key只允許一個執行緒查詢資料和寫快取,其他執行緒等待。
2:做二級快取,A1為原始快取,A2為複製快取,A1失效時,可以訪問A2,A1快取失效時間設定為短期,A2設定為長期
3:不同的key,設定不同的過期時間,讓快取失效的時間點儘量均勻。
●編號418,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
