
在解釋機器學習的基本概念的時候,我發現自己總是回到有限的幾幅圖中。以下是我認為最有啟發性的條目串列。


Test and training error
為什麼低訓練誤差並不總是一件好的事情呢:上圖以模型複雜度為變數的測試及訓練錯誤函式。

Under and overfitting
低度擬合或者過度擬合的例子。上圖多項式曲線有各種各樣的命令M,以紅色曲線表示,由綠色曲線適應資料集後生成。

Occam’s razor
上圖為什麼貝葉斯推理可以具體化奧卡姆剃刀原理。這張圖給了為什麼複雜模型原來是小機率事件這個問題一個基本的直觀的解釋。水平軸代表了可能的資料集D空間。貝葉斯定理以他們預測的資料出現的程度成比例地反饋模型。這些預測被資料D上歸一化機率分佈量化。資料的機率給出了一種模型Hi,P(D|Hi)被稱作支援Hi模型的證據。一個簡單的模型H1僅可以做到一種有限預測,以P(D|H1)展示;一個更加強大的模型H2,舉例來說,可以比模型H1擁有更加自由的引數,可以預測更多種類的資料集。這也表明,無論如何,H2在C1域中對資料集的預測做不到像H1那樣強大。假設相等的先驗機率被分配給這兩種模型,之後資料集落在C1區域,不那麼強大的模型H1將會是更加合適的模型。

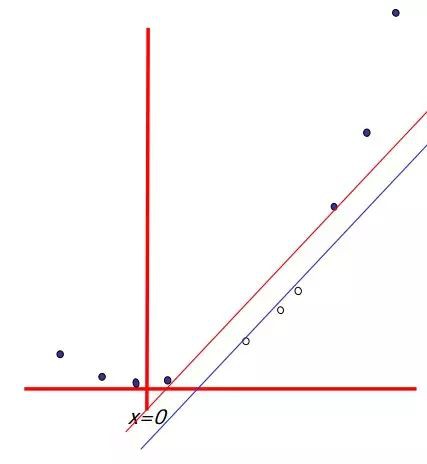
Feature combinations
(1)為什麼集體相關的特徵單獨來看時無關緊要,這也是(2)線性方法可能會失敗的原因。從Isabelle Guyon特徵提取的幻燈片來看。

Irrelevant features
為什麼無關緊要的特徵會損害KNN,聚類,以及其它以相似點聚集的方法。左右的圖展示了兩類資料很好地被分離在縱軸上。右圖添加了一條不切題的橫軸,它破壞了分組,並且使得許多點成為相反類的近鄰。
Basis functions
非線性的基礎函式是如何使一個低維度的非線性邊界的分類問題,轉變為一個高維度的線性邊界問題。Andrew Moore的支援向量機SVM(Support Vector Machine)教程幻燈片中有:一個單維度的非線性帶有輸入x的分類問題轉化為一個2維的線性可分的z=(x,x^2)問題。

Discriminative vs. Generative
為什麼判別式學習比產生式更加簡單:上圖這兩類方法的分類條件的密度舉例,有一個單一的輸入變數x(左圖),連同相應的後驗機率(右圖)。註意到左側的分類條件密度p(x|C1)的樣式,在左圖中以藍色線條表示,對後驗機率沒有影響。右圖中垂直的綠線展示了x中的決策邊界,它給出了最小的誤判率。

Loss functions
學習演演算法可以被視作最佳化不同的損失函式:上圖應用於支援向量機中的“鉸鏈”錯誤函式圖形,以藍色線條表示,為了邏輯回歸,隨著錯誤函式被因子1/ln(2)重新調整,它透過點(0,1),以紅色線條表示。黑色線條表示誤分,均方誤差以綠色線條表示。

Geometry of least squares
上圖帶有兩個預測的最小二乘回歸的N維幾何圖形。結果向量y正交投影到被輸入向量x1和x2所跨越的超平面。投影y^代表了最小二乘預測的向量。

Sparsity
為什麼Lasso演演算法(L1正規化或者拉普拉斯先驗)給出了稀疏的解決方案(比如:帶更多0的加權向量):上圖lasso演演算法的估算影象(左)以及嶺回歸演演算法的估算影象(右)。展示了錯誤的等值線以及約束函式。分別的,當紅色橢圓是最小二乘誤差函式的等高線時,實心的藍色區域是約束區域|β1| + |β2| ≤ t以及β12 + β22 ≤ t2。
作者:Maybe2030
來源:http://lib.csdn.net/article/machinelearning/49601
《Linux雲端計算及運維架構師高薪實戰班》2018年11月26日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


