
作者丨左育莘
學校丨西安電子科技大學
研究方向丨計算機視覺
這篇文章 FSRNet: End-to-End Learning Face Super-Resolution with Facial Priors 是 CVPR 2018 的文章(spotlight),主要思想是透過人臉影象的特殊性,從人臉影象中提取幾何先驗資訊來提高超解析度的效果,同時,為了生成更逼真的人臉影象,作者還提出了“人臉影象超解析度生成對抗網路”。


面部超解析度(SR)是特定的一類影象超解析度問題。目前大多數人臉影象超分辨演演算法是由通用的影象超分辨演演算法加以適當修改得到的。文章提出,可以利用特定的面部先驗知識來獲得更好的超分辨面部影象。
文章提出了一個端到端的深度可訓練面部超分辨網路,充分利用人臉影象的幾何先驗資訊,即面部 landmark 的 heatmap 和人臉解析圖,來對低解析度人臉影象進行超解析度。
網路結構及思想
具體而言,文章提出的網路的整體結構如下:首先構建粗的 SR 網路來生成粗的 HR 影象。然後,粗的 HR 影象會被送到兩個分支去:
1. 精細的SR 編碼器,提取影象特徵。
2. 先驗資訊預測網路,估計 landmark heatmap 和解析圖。
最終,影象特徵和先驗資訊會送到一個精細的 SR 解碼器來恢復 HR 影象。
整個網路的結構如下圖所示:

▲ 整體網路結構,標號解釋:k3n64s1:kernel size:3×3,number of channels:64,stride:1
這裡主要有兩個思想:
1. 為什麼不直接從低解析度影象得到人臉的幾何先驗資訊呢?
由於直接從 LR 輸入中估計面部的 landmark 以及解析圖是有一定複雜度的,所以首先構建一個粗糙的 SR 網路,來生成粗糙的 HR 影象。然後粗糙的 SR 影象就會被送到一個精細的 SR 網路,這個網路中,一個精細的 SR 編碼器和一個先驗資訊的估計網路會共同以粗糙的 HR 影象作為輸入,然後後面接上一個精細的 SR 解碼器。
精細的 SR 編碼器提取影象特徵,而先驗資訊的估計網路則透過多工學習同時估計 landmark heatmap 和解析圖,這樣操作的話,得到的效果會更好。
2. 幾何先驗特徵的選取
任何真實世界的物體在其形狀和紋理上都有不同的分佈,包括臉部。比較面部形狀和紋理,我們選擇建模並利用形狀先驗資訊基於兩個考慮因素。
第一,當影象從高解析度到低解析度時,相比於紋理資訊,形狀資訊會更好地儲存下來,因此更有可能被提取出來促進超解析度的效果。
第二,形狀先驗資訊比紋理先驗資訊更容易表現。例如,面部解析估計不同面部元件的分割,landmark 則提供面部關鍵點的準確位置。兩者都可以表示面部形狀,而面部解析則帶來更多粒度。相反,目前尚不清楚如何對一張特定的人臉的高維度紋理先驗進行表示。
網路細節
粗糙的SR網路(第一階段)
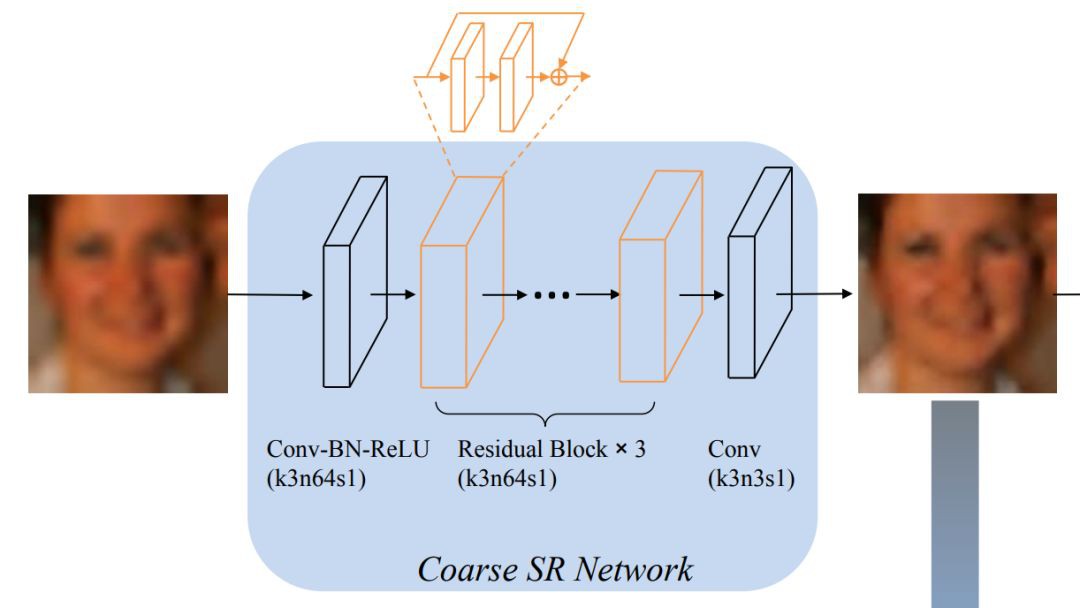
▲ 3個殘差單元,kernel size和stride的設定使得特徵圖的大小始終不變
精細的SR網路(第二階段)

▲ 第二階段網路,HG Block指的就是HourGlass結構
1. 先驗資訊估計網路
從最近成功的疊加熱圖回歸在人體姿勢估計中受到啟發,文章提出在先驗資訊估計網路中使用一個 HourGlass 結構來估計面部 landmark 的 heatmap 和解析圖。因為這兩個先驗資訊都可以表示 2D 的人臉形狀,所以在先驗資訊估計網路中,特徵在兩個任務之間是共享的,除了最後一層。
為了有效整合各種尺度的特徵並保留不同尺度的空間資訊,HourGlass block 在對稱層之間使用 skip-connection 機制。最後,共享的 HG 特徵連線到兩個分離的 1×1 摺積層來生成 landmark heatmap和解析圖。
2. 精細的SR編碼器
受到 ResNet 在超分辨任務中的成功的啟發,文章使用 residual block 進行特徵提取。考慮到計算的開銷,先驗資訊的特徵會降取樣到 64×64。為了使得特徵尺寸一致,編碼器首先經過一個 3×3,stride為 2 的摺積層來把特徵圖降取樣到 64×64。然後再使用 ResNet 結構提取影象特徵。
3. 精細的SR解碼器
解碼器把先驗資訊和影象特徵組合為輸入,首先將先驗特徵 p 和影象特徵 f 進行 concatenate,作為輸入。然後透過 3×3 的摺積層把特徵圖的通道數減少為 64。然後一個 4×4 的反摺積層被用來把特徵圖的 size 上取樣到 128×128。然後使用 3 個 residual block 來對特徵進行解碼。最後的 3×3 摺積層被用來得到最終的 HR 影象。
損失函式
FSRNet
FSRNet 包含四個部分:粗糙的 SR 網路,精細的 SR 編碼器,先驗資訊估計網路,精細的 SR 解碼器。設 x 為輸入的低解析度影象,y 和 p 是高解析度影象和估計得到的先驗資訊。
由於直接從低解析度影象中得到影象的先驗資訊的效果不是那麼好,所以首先構建一個粗糙的 SR 網路來得到一個粗糙的 SR 影象:

C 代表對映(LR 輸入到粗糙的 HR 影象輸出之間的對映)。然後,Yc 會被送入先驗資訊的估計網路 P 和精細的 SR 編碼器 F:

f 為從網路 F 提取得到的特徵。在編碼以後,SR 解碼器則會利用影象特徵 f 和影象先驗資訊 p 得到最終的 HR 影象 y:
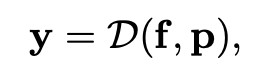
給定訓練集 ,FSRNet的損失函式如下(
,FSRNet的損失函式如下(![]() 和
和![]() 為 ground truth):
為 ground truth):

FSRGAN
對於 FSRGAN(人臉超分辨生成對抗網路),作者參考 CVPR 2017 用於影象轉換的條件生成對抗網路 cGAN [1]:

並引入了感知域損失(high-level 的特徵圖之間的損失,文章使用預訓練的 VGG-16 來得到高層特徵圖):
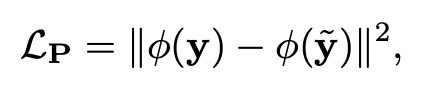
得到最終的損失函式為:
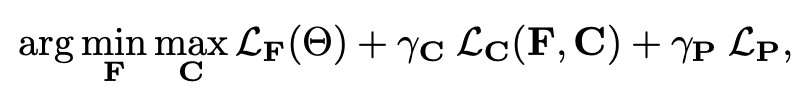
訓練設定
Dataset:Helen & celeA
對於 Helen 資料集,2330 張影象,後 50 張影象作為測試,其他作為訓練,並且使用資料增強(旋轉 90°,180°,270°,以及水平翻轉,所以每張圖都有 7 張資料增強圖),Helen 資料集的每張影象都有 194 個 landmark 和 11 個解析圖。
對於 celeA 資料集,用前 18000 張影象進行訓練,後 100 張影象進行評價。celeA 資料集的 ground truth landmark 數只有 5 個,所以要用一些方法得到 68 個 landmark,以及使用 GFC 方法來估計解析圖的 ground truth。
訓練設定
根據面部區域粗略裁剪訓練影象,在沒有任何預先對齊的情況下裁剪到 128 × 128,彩色影象訓練。低解析度影象首先經過bicubic插值到高解析度影象大小,再進行訓練。
框架:Torch 7
最佳化器:RMSprop
初始學習率:![]()
Mini-batch size:14
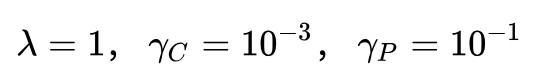
在 Helen 資料集上訓練 FSRNet 大約需要 6 小時(Titan X)。
相關實驗(8倍放大)
先驗資訊對人臉超解析度的影響:
-
人臉影象的先驗資訊真的對超分辨有用嗎?
-
不同的人臉先驗資訊帶來的提升有什麼不同?
首先,文章證明瞭人臉先驗資訊對人臉超分辨是很重要的,即使沒有任何提前處理的步驟。
作者把先驗資訊估計網路移除以後,構建了一個 Baseline 網路。基於 Baseline 網路,引入 ground truth 人臉先驗資訊(landmark heatmap 和解析圖)到拼接層,得到一個新的網路。

▲ Baseline網路 + ground truth人臉先驗資訊
為了公平進行比較,拼接層的特徵圖通道數量和其他兩個網路的通道數量是一樣的。得到不同網路的效能對比:
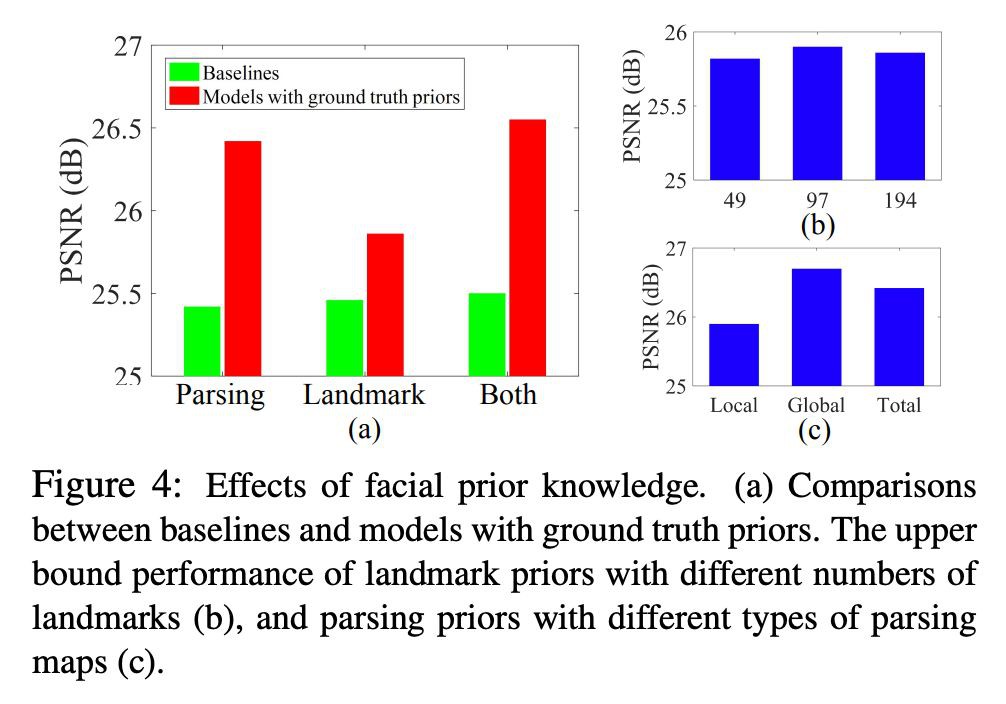
▲ 網路效能對比
可以看到,用了先驗資訊的模型有提高,分別提高了 0.4dB(加入 landmark heatmap),1.0dB(加入解析圖),1.05dB(兩個都加)。
設定不同的 landmark 數,以及使用區域性解析圖或者全域性解析圖。得到的效能比較結果(上圖右半部分)。
透過上面結果的比較,得出以下結論:
1. 解析圖比 landmark heatmap 含有更多人臉影象超分辨的資訊,帶來的提升更大;
2. 全域性的解析圖比區域性的解析圖更有用;
3. landmark 數量增加所帶來的提升很小。
估計得到的先驗資訊的影響:
-
Baseline_v1:完全不包含先驗資訊
-
Baseline_v2:包含先驗資訊,但不進行監督訓練
效能比較:

結論:
1. 即使不進行監督訓練,先驗資訊也能幫助到 SR 任務,可能是因為先驗資訊提供了更多的高頻資訊;
2. 越多先驗資訊越好;
3. 最佳效能為 25.85dB,但是使用 ground truth 資訊時,能達到 26.55dB。說明估計得到的先驗資訊並不完美,更好的先驗資訊估計網路可能會得到更好的結果。
Hourglass數量的影響:
強大的先驗資訊預測網路會得到更好的結果,所以探究 Hourglass 數量 h 對網路效能的影響。分別取 1,2,4,結果為 25.69,25.87,25.95。
不同的 Hourglass 數量對 landmark 估計的影響:

▲ 第一行h=1,第二行h=2
可以看到 h 數量增加時,先驗資訊估計網路結構越深,學習能力越強,效能越好。
與SOTA方法的比較
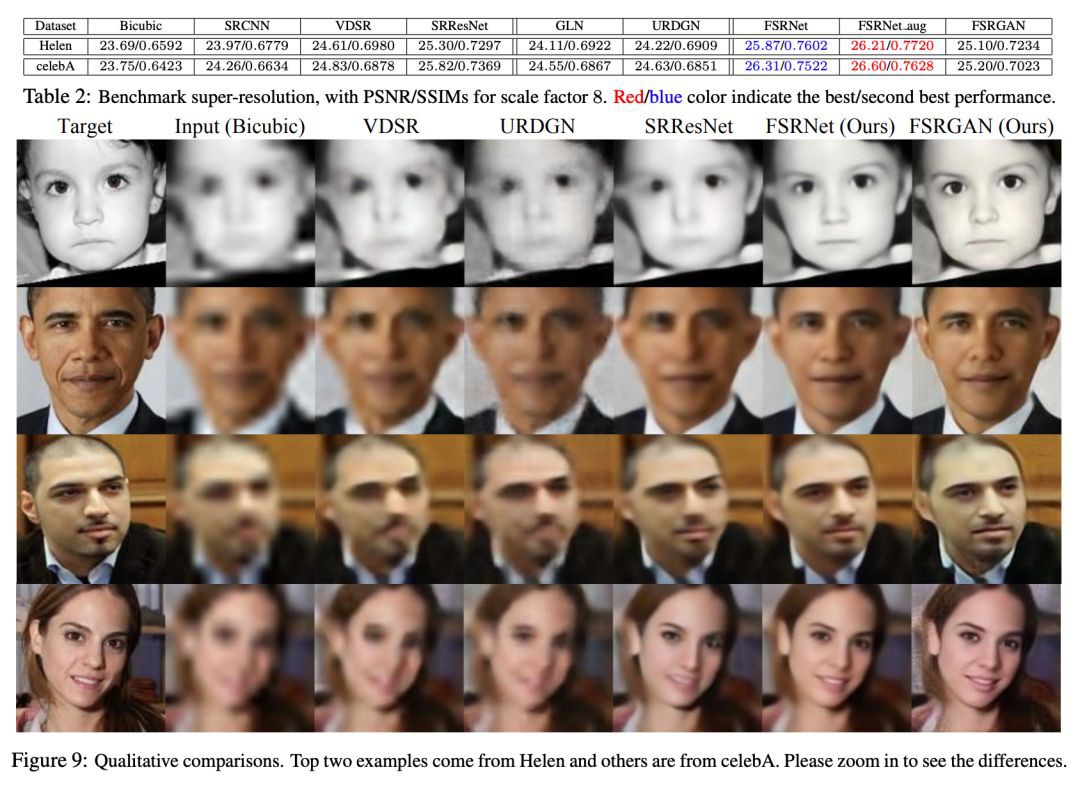
放大 8 倍後的效能比較,雖然 FSRGAN 的兩項指標(PSNR/SSIM)都不如 FSRNet,但是從視覺效果上看更加真實。
這也與目前的一個共識相對應:基於生成對抗網路的模型可以恢復視覺上合理的影象,但是在一些指標上(PSNR , SSIM)的值會低。而基於 MSE 的深度模型會生成平滑的影象,但是有高的 PSNR/SSIIM。
總結
本文提出了深度端到端的可訓練的人臉超分辨網路 FSRNet,FSRNet 的關鍵在於先驗資訊估計網路,這個網路不僅有助於改善 PSNR/SSIM,還提供從非常低解析度的影象精確估計幾何先驗資訊(landmark heatmap 和解析圖)的解決方案。實驗結果表明 FSRNet 比當前的 SOTA 方法要更好,即使在未對齊的人臉影象上。
未來的工作可以有以下幾個方面:1)設計一個更好的先驗資訊估計網路;2)迭代地學習精細的 SR 網路;3)調研其他有用的臉部先驗資訊。
參考文獻
[1] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros, Image-to-Image Translation with Conditional Adversarial Networks, CVPR 2017.

點選以下標題檢視更多往期內容:
讓你的論文被更多人看到 如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準: • 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向) • 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結 • PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱: • 投稿郵箱:hr@paperweekly.site • 所有文章配圖,請單獨在附件中傳送 • 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
 #投 稿 通 道#
#投 稿 通 道#
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 獲取最新論文推薦

