業內各大雲服務商以及公司逐漸選擇Kubernetes與Docker作為微服務支撐的首選平臺。為了更好滿足DevOps,我們採用了開源框架Spinnaker作為持續交付平臺,完成服務的快速部署,回滾,A/B測試,以及金絲雀等等的部署方式,同時我們在生產做了多區的容災,更好的保障線上服務。

Spinnaker是Netflix的開源專案,是一個持續交付平臺,它定位於將產品快速且持續的部署到多種雲平臺上。Spinnaker有兩個核心的功能叢集管理和部署管理。Spinnaker透過將釋出和各個雲平臺解耦,來將部署流程流水線化,從而降低平臺遷移或多雲平臺部署應用的複雜度,它本身內部支援Google、AWS EC2、Microsoft Azure、Kubernetes和OpenStack等雲平臺,並且它可以無縫整合其他持續整合(CI)流程,如Git、Jenkins、Travis CI、Docker registry、cron排程器等。
Spinnaker主要用於展示與管理你的雲端資源。
先要瞭解一些關鍵的概念:Applications,Cluster,and Server Groups,透過Load balancers and firewalls將服務展示給使用者。官方給的結構如下:
定義了叢集中一組的Cluster的集合,也包括了Firewalls與Load Balancers,儲存了服務所有的部署相關的的資訊。
定義了一些基礎的源比如(VM image、Docker image),以及一些基礎的配置資訊,一旦部署後,在容器中對應Kubernetes Pod的集合。
Server Groups的有關聯的集合。(Cluster中可以按照dev,prod的去建立不同的服務組),也可以理解為對於一個應用存在多個分支的情況。
它在實體之間做負載均衡流量。您還可以為負載均衡器啟用健康檢查,靈活地定義健康標準並指定健康檢查端點,有點類似於Kubernetes中Ingress。
防火牆定義了網路流量訪問,定義了一些訪問的規則,如安全組等等。
頁面展示如下,還是比較精簡的,可以在它的操作頁面上看到專案以及應用的詳細資訊,還可以進行叢集的伸縮、回滾、修改以及刪除的操作。
上圖中,Infrastructure左側為Pipeline的設計:主要講兩塊內容:Pipeline的建立以及基礎功能,與部署的策略。
-
較強的Pipeline的能力:它的Pipeline可以複雜到無以復加,它還有很強的運算式功能(後續的操作中前面的引數均透過運算式獲取)。
-
觸發的方式:定時任務、人工觸發、Jenkins job、Docker images,或者其他的Pipeline的步驟。
-
通知方式:Email、SMS or HipChat。
-
將所有的操作都融合到Pipeline中,比如回滾、金絲雀分析、關聯CI等等。
由於我們用的是Kubernetes Provider V2(Manifest Based)方式:可修改yaml中:spec.strategy.type。
很多人都是感覺這個很難安裝,其實主要的原因還是牆的問題,只要把這個解決了就會方便很多,官方的檔案寫的很詳細,而且Spinnaker的社群也非常的活躍,有問題均可以在上面進行提問。
-
Halyard安裝方式(官方推薦安裝方式)
-
Helm搭建Spinnaker平臺
-
Development版本安裝
我採用Halyard安裝方式,因為後期我們會整合很多其他的外掛,類似於GitLab、LDAP、Kayenta,甚至多個Jenkins,Kubernetes服務等等,可配置性較強。Helm方式若是需要自定義一些個性化的內容會比較複雜,完全依賴於原始映象,而Development需要對Spinnaker非常的熟悉,以及每個版本之間的對應關係均要瞭解。
vim /opt/halyard/bin/halyard
DEFAULT_JVM_OPTS='-Dhttp.proxyHost=192.168.102.10 -Dhttps.proxyPort=3128'
由於Spinnaker涉及的應用較多,下麵會單獨的介紹,需要消耗比較大的記憶體,官方推薦的配置如下:
18 GB of RAM
A 4 core CPU
Ubuntu 14.04, 16.04 or 18.04
-
Halyard下載以及安裝。
-
選擇雲提供者:我選擇的是Kubernetes Provider V2(Manifest Based),需要在部署Spinnaker的機器上完成Kubernetes叢集的認證,以及許可權管理。
-
部署的時候選擇安裝環境:我選擇的是Debian包的方式。
-
選擇儲存:官方推薦使用Minio,我選擇的是Minio的方式。
-
選擇安裝的版本:我當時最新的是V1.8.0。
-
接下來進行部署工作,初次部署時間較長,會連線代理下載對應的包。
-
全部下載與完成後,檢視對應的日誌,即可使用localhost:9000訪問即可。
完成以上的步驟則可以在Kubernetes上面部署對應的應用了。
-
Deck:面向使用者UI介面元件,提供直觀簡介的操作介面,視覺化操作釋出部署流程。
-
API:面向呼叫API元件,我們可以不使用提供的UI,直接呼叫API操作,由它後臺幫我們執行釋出等任務。
-
Gate:是API的閘道器元件,可以理解為代理,所有請求由其代理轉發。
-
Rosco:是構建beta映象的元件,需要配置Packer元件使用。
-
Orca:是核心流程引擎元件,用來管理流程。
-
Igor:是用來整合其他CI系統元件,如Jenkins等一個元件。
-
Echo:是通知系統元件,傳送郵件等資訊。
-
Front50:是儲存管理元件,需要配置Redis、Cassandra等元件使用。
-
Cloud driver:是用來適配不同的雲平臺的元件,比如Kubernetes、Google、AWS EC2、Microsoft Azure等。
-
Fiat:是鑒權的元件,配置許可權管理,支援OAuth、SAML、LDAP、GitHub teams、Azure groups、 Google Groups等。
| 元件 |
埠 |
依賴元件 |
埠 |
| Clouddriver |
7002 |
Minio |
|
| Fiat |
7003 |
Jenkins |
|
| Front50 |
8080 |
Ldap |
|
| Orca |
8083 |
GitHub |
|
| Gate |
8084 |
|
|
| Rosco |
8087 |
|
|
| Igor |
8088 |
|
|
| Echo |
8089 |
|
|
| Deck |
9000 |
|
|
| Kayenta |
8090 |
|
|
Spinnaker在Kubernetes的持續部署
如下Pipeline設計就是開發將版本合到某一個分支後,透過Jenkins映象構建,釋出測試環境,進而自動化以及人工驗證,在由人工判斷是否需要釋出到線上以及回滾,若是選擇釋出到線上則釋出到prod環境,從而進行prod自動化的CI。若是選擇回滾則回滾到上個版本,從而進行dev自動化的CI。
設定觸發的方式,定義全域性變數,執行報告的通知方式,是Pipeline的起點。
Automated Triggers,其中支援多種觸發的方式:定時任務Corn,Git,Jenkins,Docker Registry,Travis,Pipeline,Webhook等觸發方式,從而能夠滿足我們自動回呼的功能。
Parameters,此處定義的全域性變數會在整個Pipeline中使用${ parameters[‘branch’]}得到,這樣大大的簡化了我們設計Pipeline的通用性。
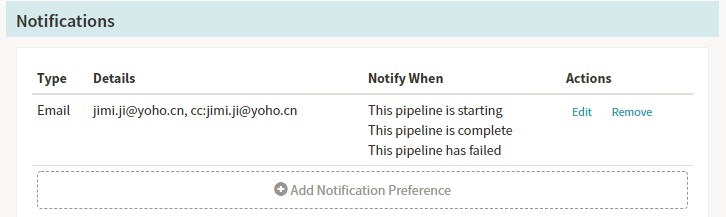
Notifications,這裡通知支援:SMS,Email,HipChat等等的方式。
我們使用了郵件通知的功能:需要在echo的配置檔案中加入發件郵箱的基本資訊。
呼叫Jenkins來執行相關的任務,其中Jenkins的服務資訊存在放hal的配置檔案中(如下展示),Spinnaker可自動以同步Jenkins的Job以及引數等等的資訊,執行後能夠看到對應的Job ID以及狀態:
執行完成後展示如下,我們可以檢視相關的build的資訊,以及此stage執行的相關資訊,點選build可以跳到對應的Jenkins的Job檢視相關的任務資訊。
由於我們配置Spinnaker的時候採用的是Kubernetes Provider V2方式,我們的釋出均採用yaml的方式來實現,可以將檔案存放在GitHub中或者直接在頁面上進行配置,同時yaml中檔案支援了很多的引數化,這樣大大的方便了我們日常的使用。
Halyard關聯Kubernetes的配置資訊:由於我們採用的雲服務是Kubernetes,配置的時候需要將部署Spinnaker的機器對Kubernetes叢集做認證。
Spinnaker釋出資訊展示:此處Manifest Source支援引數化形式,類似於我們寫入的yaml部署檔案,但是這裡支援引數化的方式。
- apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: '${ parameters.deployName }-deployment'
namespace: dev
spec:
replicas: 2
template:
metadata:
labels:
name: '${ parameters.deployName }-deployment'
spec:
containers:
- image: >-
192.168.105.2:5000/${ parameters.imageSource }/${
parameters.deployName }:${ parameters.imageversion }
name: '${ parameters.deployName }-deployment'
ports:
- containerPort: 8080
imagePullSecrets:
- name: registrypullsecret
- apiVersion: v1
kind: Service
metadata:
name: '${ parameters.deployName }-service'
namespace: dev
spec:
ports:
- port: 8080
targetPort: 8080
selector:
name: '${ parameters.deployName }-deployment'
- apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: '${ parameters.deployName }-ingress'
namespace: dev
spec:
rules:
- host: '${ parameters.deployName }-dev.ingress.dev.yohocorp.com'
http:
paths:
- backend:
serviceName: '${ parameters.deployName }-service'
servicePort: 8080
path: /
Webhook我們可以做一些簡單的環境驗證以及去呼叫其他的服務的功能,它自身也提供了一些結果的驗證功能,支援多種請求的方式。
Spinnaker配置資訊,用於人工的邏輯判斷,增加Pipeline的控制性(比如釋出到線上需要測試人員認證以及領導審批),內容支援多種語法表達的方式。
Stage-Check Preconditions
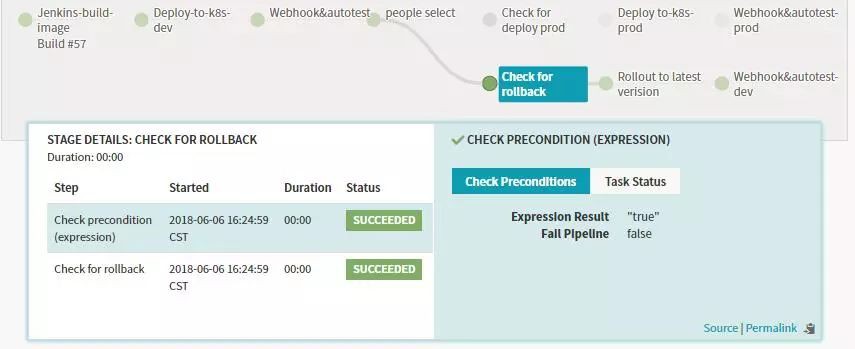
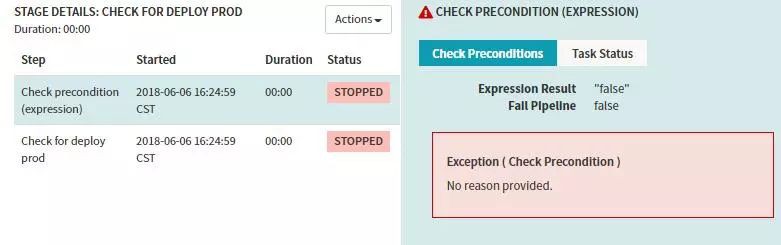
上邊Manual Judgment Stage配置了兩個Judgment Inputs判斷項,接下來我們建兩個Check Preconditions Stage來分別對這兩種判斷項做條件檢測,條件檢測成功,則執行對應的後續Stage流程。比如上面的操作,若是選擇釋出到prod,則執行釋出到線上的分支,若是選擇執行回滾的操作則進行回滾相關的分支。
執行結果的示例:如上圖中我選擇了rollback。
則prod分支判斷為失敗,會阻塞後面的stage執行。
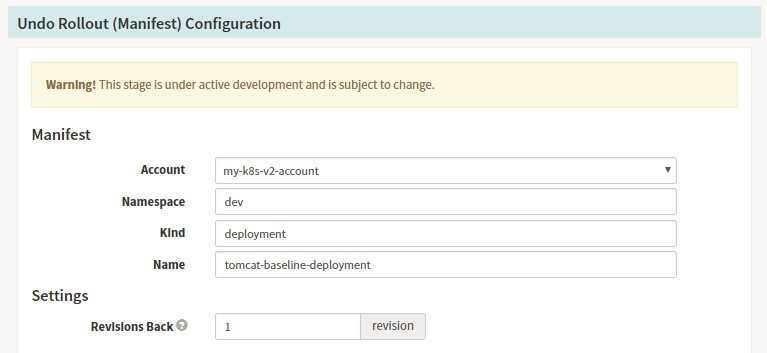
Stage-Undo Rollout(Manifest)
若是我們釋出發現出現問題,也可以設計回滾的stage,Spinnaker的回滾極其的方便,在我們的日常部署中,每個版本都會存在對應的部署記錄,如下所示:
Spinnaker Pipeline配置資訊:回滾的Pipeline描述中我們需要選擇對應的deployment的回滾資訊,以及回滾的版本數量。
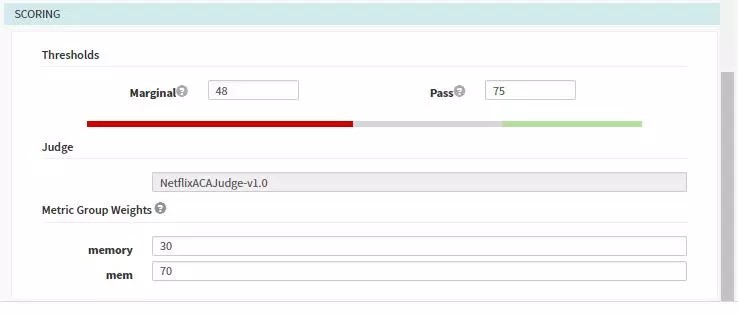
金絲雀部署方式:在我們釋出新版本時引入部分流量到Canary的服務中,Kayenta會讀取Spinnaker中配置的Prometheus中收集的指標,比如記憶體,CPU,介面超時時間,失敗率等等透過Kayenta中Netflix ACA Judge來進行分析與判斷,將分析的結果存於S3中,最終會給出這段時間的最終結果。
-
我們需要對應用開啟Canary的配置。
-
創建出Baseline與Canary的deployment由同一個Service指向這兩個deployment。
-
我們這裡採用讀取Prometheus的指標,需要在hal中增加Prometheus配置。Metric可以直接匹配Prometheus的指標。
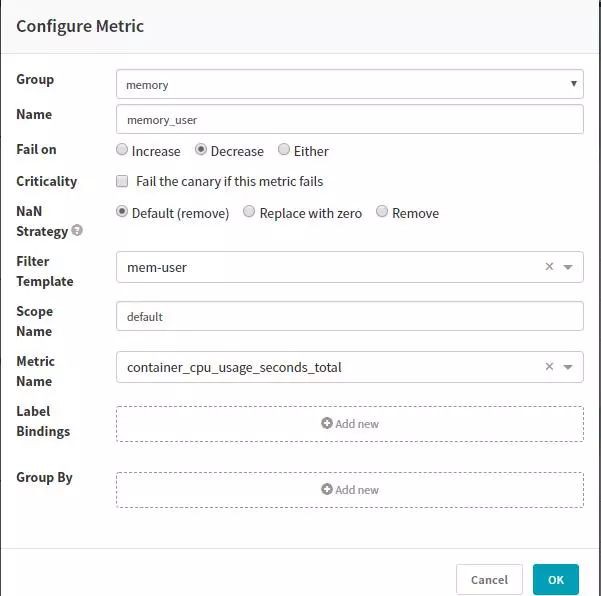
需要配置收集指標以及指標的權重:
-
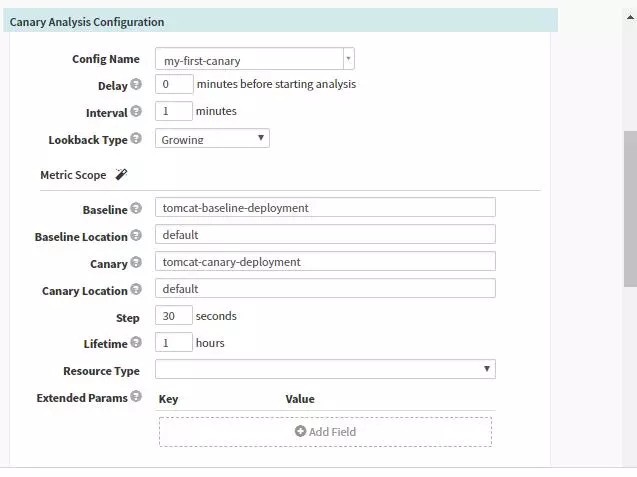
在Pipeline中指定收集分析的頻率以及需要指定的源,同時可以配置scoring從而改寫模板中的配置。
-
每次分析的執行記錄:

-
結果展示如下,由於我們設定的標的是75,所以pipeline的結果判定為失敗。

我們是騰訊雲的客戶,採用騰訊雲容器服務主要看重以下幾個方面:
-
Kubernetes在自搭建的叢集中,要實現Overlay網路,在騰訊雲的環境裡,它本身就是軟體定義網路VPC,所以它在網路上的實現可以做到在容器環境裡和原生的VM網路一樣的快,沒有任何的效能犧牲。
-
應用型負載均衡器和Kubernetes裡的Ingress相關聯,對於需要外部訪問的服務能夠快速的建立。
-
騰訊雲的雲儲存可以被Kubernetes管理,便於持久化的操作。
-
騰訊雲的部署以及告警也對外提供了服務與介面,可以更好的檢視與監控相關的Node與Pod的情況。
-
騰訊雲日誌服務很好的與容器進行融合,能夠方便的收集與檢索日誌。
為了容災我們使用了北京二區與北京三區兩個叢集,若是需要灰度驗證時,則將線上北京三區的權重修改為0,這樣透過灰度負載均衡器即可到達新版本應用。日常使用中二區與三區均同時提供掛服務。
Q:為什麼沒有和CI結合在一起?使用這個比較重的Spannaker有什麼優勢?
A:可以和CI進行結合,比如Webhook的方式,或者採用Jenkins排程的方式。優勢在於可以和很多雲平臺進行結合,而且他的Pipeline比較的完美,引數化程度很高。
Q:目前IaaS只支援OpenStack和國外的公有雲廠商,國內的雲服務商如果要支援的話,底層需要怎麼做呢(管理雲主機而不是容器)?自己實現的話容易嗎?怎麼入手?
A:目前我們主要使用Spinnaker用來管理容器這部分的內容,對於國內的雲廠商Spinnaker支援都不是非常的好,像LB,安全策略這些都不可在Spinnaker上面控制。若是需要研究可以檢視Cloud driver這個元件的功能。
Q:Spinnaker能不能在Pipeline裡透過http API獲取一個deployment yaml進行deploy,這個yaml可能是動態生成的?
A:部署服務有兩種方式:1. 在Spinnaker的UI中直接填入Manifest Source,其實就是對應的deployment YAML,只不過這裡可以寫入Pipeline的引數;2. 可以從GitHub中拉取對應的檔案,來部署。
A:Spinnaker中Fiat是鑒權的元件,配置許可權管理,Auth、SAML、LDAP、GitHub teams、Azure Groups、 Google Groups,我們就採用LDAP,登陸後會在上面顯示對應的登陸人員。
Q: deploy和test以及rollback可以跟helm chart整合嗎?
A:我覺得是可以,很笨的方法最終都是可以藉助於Jenkins來實現,但是Spinnaker的回滾與部署技術很強大,在頁面上點選就可以進行快速的版本回滾與部署。
Q: Spannaker之前的截圖看到也有對部分使用者開發的功能,用Spannaker之後還需要Istio嗎?
A:這兩個有不同的功能,【對部分使用者開發的功能】這個是依靠建立不同的service以及Ingress來實現的,他的路由能力肯定沒有Istio強悍,而且也不具備熔斷等等的技術,我們線下這麼建立主要為了方便開發人員進行快速的部署與除錯。

Kubernetes應用實戰培訓將於2018年9月14日在上海開課,3天時間帶你係統掌握Kubernetes。本次培訓包括:容器特性、映象、網路;Docker特性、架構、元件、概念、Runtime;Docker安全;Docker實踐;Kubernetes架構、核心元件、基本功能;Kubernetes設計理念、架構設計、基本功能、常用物件、設計原則;Kubernetes的實踐、執行時、網路、外掛已經落地經驗;微服務架構、DevOps等,點選下方圖片檢視詳情。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式