
來源:架構師小秘圈
ID:seexmq
微服務有哪些要點呢?先看下圖是 SpringCloud 的整個生態。

在實施微服務的過程中,不免要面臨服務的聚合與拆分,當後端服務的拆分相對比較頻繁的時候,作為手機 App 來講,往往需要一個統一的入口,將不同的請求路由到不同的服務,無論後面如何拆分與聚合,對於手機端來講都是透明的。
有了 API 閘道器以後,簡單的資料聚合可以在閘道器層完成,這樣就不用在手機 App 端完成,從而手機 App 耗電量較小,使用者體驗較好。
有了統一的 API 閘道器,還可以進行統一的認證和鑒權,儘管服務之間的相互呼叫比較複雜,介面也會比較多,API 閘道器往往只暴露必須的對外介面,並且對介面進行統一的認證和鑒權,使得內部的服務相互訪問的時候,不用再進行認證和鑒權,效率會比較高。
有了統一的 API 閘道器,可以在這一層設定一定的策略,進行 A/B 測試,藍綠釋出,預發環境導流等等。API 閘道器往往是無狀態的,可以橫向擴充套件,從而不會成為效能瓶頸。

影響應用遷移和橫向擴充套件的重要因素就是應用的狀態,無狀態服務,是要把這個狀態往外移,將 Session 資料,檔案資料,結構化資料儲存在後端統一的儲存中,從而應用僅僅包含商務邏輯。
狀態是不可避免的,例如 ZooKeeper, DB,Cache 等,把這些所有有狀態的東西收斂在一個非常集中的叢集裡面。
整個業務就分兩部分,一個是無狀態的部分,一個是有狀態的部分。
無狀態的部分能實現兩點,一是跨機房隨意地部署,也即遷移性,一是彈性伸縮,很容易地進行擴容。
有狀態的部分,如 DB,Cache,ZooKeeper 有自己的高可用機制,要利用到他們自己高可用的機制來實現這個狀態的叢集。
雖說無狀態化,但是當前處理的資料,還是會在記憶體裡面的,當前的行程掛掉資料,肯定也是有一部分丟失的,為了實現這一點,服務要有重試的機制,介面要有冪等的機制,透過服務發現機制,重新呼叫一次後端服務的另一個實體就可以了。
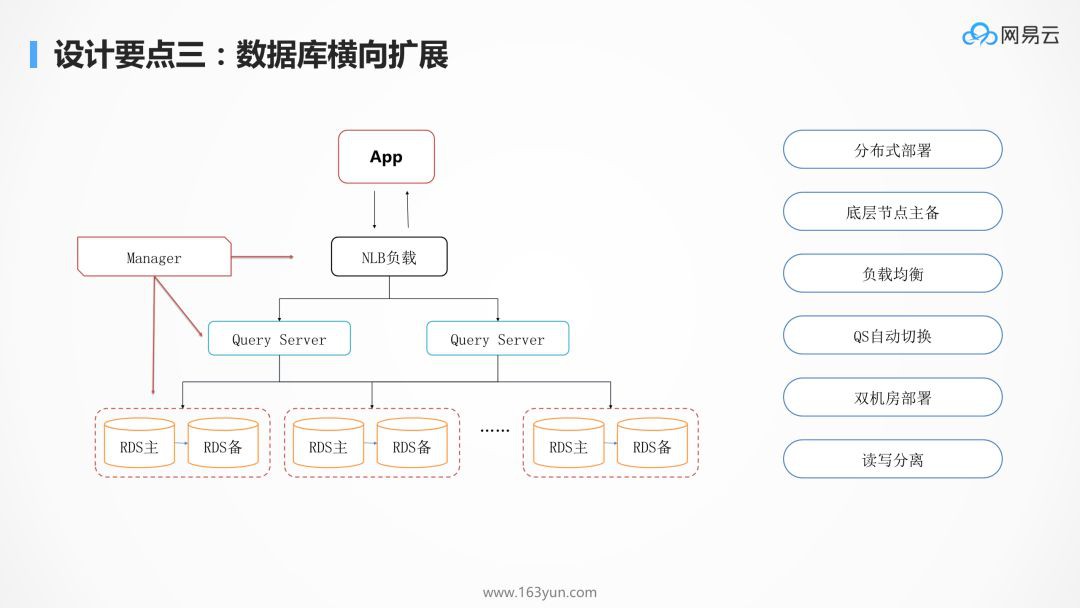
資料庫是儲存狀態,是最重要的也是最容易出現瓶頸的。有了分散式資料庫可以使資料庫的效能可以隨著節點增加線性地增加。
分散式資料庫最最下麵是 RDS,是主備的,透過 MySql 的核心開發能力,我們能夠實現主備切換資料零丟失,所以資料落在這個 RDS 裡面,是非常放心的,哪怕是掛了一個節點,切換完了以後,你的資料也是不會丟的。
再往上就是橫向怎麼承載大的吞吐量的問題,上面有一個負載均衡 NLB,用 LVS,HAProxy, Keepalived,下麵接了一層 Query Server。Query Server 是可以根據監控資料進行橫向擴充套件的,如果出現了故障,可以隨時進行替換的修複,對於業務層是沒有任何感知的。
另外一個就是雙機房的部署,DDB 開發了一個資料運河 NDC 的元件,可以使得不同的 DDB 之間在不同的機房裡面進行同步,這時候不但在一個資料中心裡面是分散式的,在多個資料中心裡面也會有一個類似雙活的一個備份,高可用性有非常好的保證。

在高併發場景下快取是非常重要的。要有層次的快取,使得資料儘量靠近使用者。資料越靠近使用者能承載的併發量也越大,響應時間越短。
在手機客戶端 App 上就應該有一層快取,不是所有的資料都每時每刻從後端拿,而是隻拿重要的,關鍵的,時常變化的資料。
尤其對於靜態資料,可以過一段時間去取一次,而且也沒必要到資料中心去取,可以透過 CDN,將資料快取在距離客戶端最近的節點上,進行就近下載。
有時候 CDN 裡面沒有,還是要回到資料中心去下載,稱為回源,在資料中心的最外層,我們稱為接入層,可以設定一層快取,將大部分的請求攔截,從而不會對後臺的資料庫造成壓力。
如果是動態資料,還是需要訪問應用,透過應用中的商務邏輯生成,或者去資料庫讀取,為了減輕資料庫的壓力,應用可以使用本地的快取,也可以使用分散式快取,如 Memcached 或者 Redis,使得大部分請求讀取快取即可,不必訪問資料庫。
當然動態資料還可以做一定的靜態化,也即降級成靜態資料,從而減少後端的壓力。

當系統扛不住,應用變化快的時候,往往要考慮將比較大的服務拆分為一系列小的服務。
這樣第一個好處就是開發比較獨立,當非常多的人在維護同一個程式碼倉庫的時候,往往對程式碼的修改就會相互影響,常常會出現我沒改什麼測試就不透過了,而且程式碼提交的時候,經常會出現衝突,需要進行程式碼合併,大大降低了開發的效率。
另一個好處就是上線獨立,物流模組對接了一家新的快遞公司,需要連同下單一起上線,這是非常不合理的行為,我沒改還要我重啟,我沒改還讓我釋出,我沒改還要我開會,都是應該拆分的時機。
另外再就是高併發時段的擴容,往往只有最關鍵的下單和支付流程是核心,只要將關鍵的交易鏈路進行擴容即可,如果這時候附帶很多其他的服務,擴容即是不經濟的,也是很有風險的。
再就是容災和降級,在大促的時候,可能需要犧牲一部分的邊角功能,但是如果所有的程式碼耦合在一起,很難將邊角的部分功能進行降級。
當然拆分完畢以後,應用之間的關係就更加複雜了,因而需要服務發現的機制,來管理應用相互的關係,實現自動的修複,自動的關聯,自動的負載均衡,自動的容錯切換。

當服務拆分了,行程就會非常的多,因而需要服務編排來管理服務之間的依賴關係,以及將服務的部署程式碼化,也就是我們常說的基礎設施即程式碼。這樣對於服務的釋出,更新,回滾,擴容,縮容,都可以透過修改編排檔案來實現,從而增加了可追溯性,易管理性,和自動化的能力。
既然編排檔案也可以用程式碼倉庫進行管理,就可以實現一百個服務中,更新其中五個服務,只要修改編排檔案中的五個服務的配置就可以,當編排檔案提交的時候,程式碼倉庫自動觸發自動部署升級指令碼,從而更新線上的環境,當發現新的環境有問題時,當然希望將這五個服務原子性地回滾,如果沒有編排檔案,需要人工記錄這次升級了哪五個服務。有了編排檔案,只要在程式碼倉庫裡面 revert,就回滾到上一個版本了。所有的操作在程式碼倉庫裡都是可以看到的。
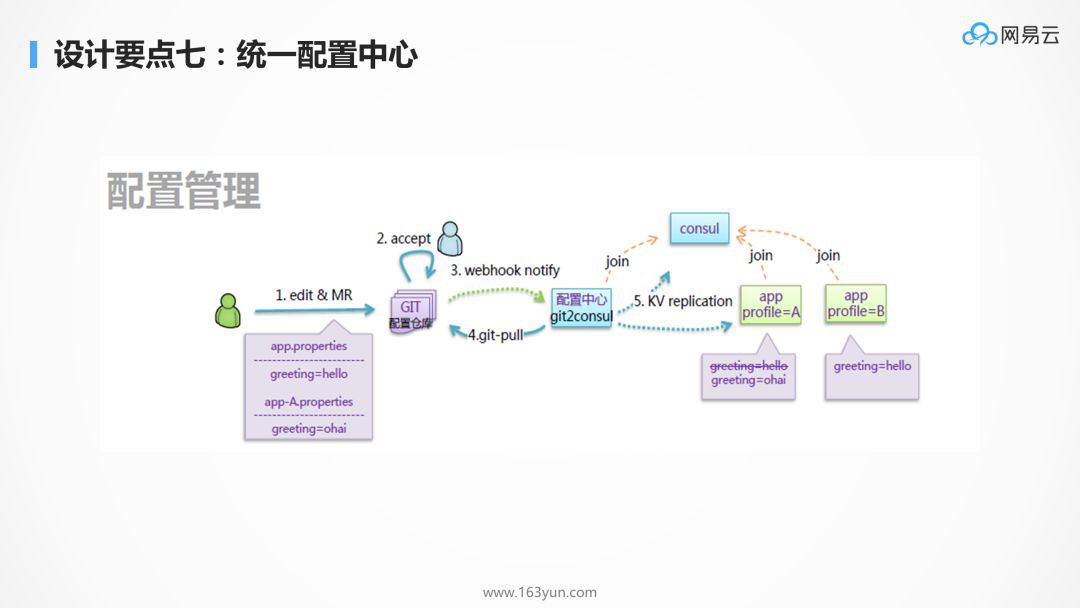
服務拆分以後,服務的數量非常多,如果所有的配置都以配置檔案的方式放在應用本地的話,非常難以管理,可以想象當有幾百上千個行程中有一個配置出現了問題,是很難將它找出來的,因而需要有統一的配置中心,來管理所有的配置,進行統一的配置下發。
在微服務中,配置往往分為幾類,一類是幾乎不變的配置,這種配置可以直接打在容器映象裡面,第二類是啟動時就會確定的配置,這種配置往往透過環境變數,在容器啟動的時候傳進去,第三類就是統一的配置,需要透過配置中心進行下發,例如在大促的情況下,有些功能需要降級,哪些功能可以降級,哪些功能不能降級,都可以在配置檔案中統一配置。

同樣是行程數目非常多的時候,很難對成千上百個容器,一個一個登入進去檢視日誌,所以需要統一的日誌中心來收集日誌,為了使收集到的日誌容易分析,對於日誌的規範,需要有一定的要求,當所有的服務都遵守統一的日誌規範的時候,在日誌中心就可以對一個交易流程進行統一的追溯。例如在最後的日誌搜尋引擎中,搜尋交易號,就能夠看到在哪個過程出現了錯誤或者異常。

服務要有熔斷,限流,降級的能力,當一個服務呼叫另一個服務,出現超時的時候,應及時傳回,而非阻塞在那個地方,從而影響其他使用者的交易,可以傳回預設的託底資料。
當一個服務發現被呼叫的服務,因為過於繁忙,執行緒池滿,連線池滿,或者總是出錯,則應該及時熔斷,防止因為下一個服務的錯誤或繁忙,導致本服務的不正常,從而逐漸往前傳導,導致整個應用的雪崩。
當發現整個系統的確負載過高的時候,可以選擇降級某些功能或某些呼叫,保證最重要的交易流程的透過,以及最重要的資源全部用於保證最核心的流程。
還有一種手段就是限流,當既設定了熔斷策略,又設定了降級策略,透過全鏈路的壓力測試,應該能夠知道整個系統的支撐能力,因而就需要制定限流策略,保證系統在測試過的支撐能力範圍內進行服務,超出支撐能力範圍的,可拒絕服務。當你下單的時候,系統彈出對話方塊說 “系統忙,請重試”,並不代表系統掛了,而是說明系統是正常工作的,只不過限流策略起到了作用。

當系統非常複雜的時候,要有統一的監控,主要有兩個方面,一個是是否健康,一個是效能瓶頸在哪裡。當系統出現異常的時候,監控系統可以配合告警系統,及時地發現,通知,幹預,從而保障系統的順利執行。
當壓力測試的時候,往往會遭遇瓶頸,也需要有全方位的監控來找出瓶頸點,同時能夠保留現場,從而可以追溯和分析,進行全方位的最佳化。
《Linux雲端計算及運維架構師高薪實戰班》2018年08月27日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Linux好文請點選【閱讀原文】哦
↓↓↓
