
作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
前言:自從在機器之心上看到了 Glow 模型之後(下一個GAN?OpenAI提出可逆生成模型Glow),我就一直對其念念不忘。現在機器學習模型層出不窮,我也經常關註一些新模型動態,但很少像 Glow 模型那樣讓我怦然心動,有種“就是它了”的感覺。更意外的是,這個效果看起來如此好的模型,居然是我以前完全沒有聽說過的。於是我翻來覆去閱讀了好幾天,越讀越覺得有意思,感覺透過它能將我之前的很多想法都關聯起來。在此,先來個階段總結。
背景
本文主要是 NICE: Non-linear Independent Components Estimation 一文的介紹和實現。這篇文章也是 Glow 模型的基礎文章之一,可以說它就是 Glow 的奠基石。
■ 論文 | NICE: Non-linear Independent Components Estimation
■ 連結 | https://www.paperweekly.site/papers/2206
■ 原始碼 | https://github.com/laurent-dinh/nice
艱難的分佈
眾所周知,目前主流的生成模型包括 VAE 和 GAN,但事實上除了這兩個之外,還有基於 flow 的模型(flow 可以直接翻譯為“流”,它的概念我們後面再介紹)。
事實上 flow 的歷史和 VAE、GAN 它們一樣悠久,但是 flow 卻鮮為人知。在我看來,大概原因是 flow 找不到像 GAN 一樣的諸如“造假者-鑒別者”的直觀解釋吧,因為 flow 整體偏數學化,加上早期效果沒有特別好但計算量又特別大,所以很難讓人提起興趣來。不過現在看來,OpenAI 的這個好得讓人驚嘆的、基於 flow 的 Glow 模型,估計會讓更多的人投入到 flow 模型的改進中。

▲ Glow模型生成的高畫質人臉
生成模型的本質,就是希望用一個我們知道的機率模型來擬合所給的資料樣本,也就是說,我們得寫出一個帶引數 θ 的分佈 qθ(x)。然而,我們的神經網路只是“萬能函式擬合器”,卻不是“萬能分佈擬合器”,也就是它原則上能擬合任意函式,但不能隨意擬合一個機率分佈,因為機率分佈有“非負”和“歸一化”的要求。這樣一來,我們能直接寫出來的只有離散型的分佈,或者是連續型的高斯分佈。
當然,從最嚴格的角度來看,影象應該是一個離散的分佈,因為它是由有限個畫素組成的,而每個畫素的取值也是離散的、有限的,因此可以透過離散分佈來描述。這個思路的成果就是 PixelRNN 一類的模型了,我們稱之為“自回歸流”,其特點就是無法並行,所以計算量特別大。所以,我們更希望用連續分佈來描述影象。當然,影象只是一個場景,其他場景下我們也有很多連續型的資料,所以連續型的分佈的研究是很有必要的。
各顯神通
所以問題就來了,對於連續型的,我們也就只能寫出高斯分佈了,而且很多時候為了方便處理,我們只能寫出各分量獨立的高斯分佈,這顯然只是眾多連續分佈中極小的一部分,顯然是不夠用的。為瞭解決這個困境,我們透過積分來創造更多的分佈:

這裡 q(z) 一般是標準的高斯分佈,而 qθ(x|z)=qθ(x|z) 可以選擇任意的條件高斯分佈或者狄拉克分佈。這樣的積分形式可以形成很多複雜的分佈。理論上來講,它能擬合任意分佈。
現在分佈形式有了,我們需要求出引數 θ,那一般就是最大似然,假設真實資料分佈為 p̃(x),那麼我們就需要最大化標的:

然而 qθ(x) 是積分形式的,能不能算下去很難說。
於是各路大神就“八仙過海,各顯神通”了。其中,VAE 和 GAN 在不同方向上避開了這個困難。VAE 沒有直接最佳化標的 (2),而是最佳化一個更強的上界,這使得它只能是一個近似模型,無法達到良好的生成效果。GAN 則是透過一個交替訓練的方法繞開了這個困難,確實保留了模型的精確性,所以它才能有如此好的生成效果。但不管怎麼樣,GAN 也不能說處處讓人滿意了,所以探索別的解決方法是有意義的。
直面機率積分
flow 模型選擇了一條“硬路”:直接把積分算出來。
具體來說,flow 模型選擇 q(x|z) 為狄拉克分佈 δ(x−g(z)),而且 g(z) 必須是可逆的,也就是說:

要從理論上(數學上)實現可逆,那麼要求 z 和 x 的維度一樣。假設 f,g 的形式都知道了,那麼透過 (1) 算 q(x) 相當於是對 q(z) 做一個積分變換 z=f(x)。即本來是:

的標準高斯分佈(D 是 z 的維度),現在要做一個變換 z=f(x)。註意機率密度函式的變數代換並不是簡單地將 z 替換為 f(x) 就行了,還多出了一個“雅可比行列式”的絕對值,也就是:

這樣,對 f 我們就有兩個要求:
1. 可逆,並且易於求逆函式(它的逆 g 就是我們希望的生成模型);
2. 對應的雅可比行列式容易計算。
這樣一來:

這個最佳化標的是可以求解的。並且由於 f 容易求逆,因此一旦訓練完成,我們就可以隨機取樣一個 z,然後透過 f 的逆來生成一個樣本 ,這就得到了生成模型。
,這就得到了生成模型。
flow
前面我們已經介紹了 flow 模型的特點和難點,下麵我們來詳細展示 flow 模型是如何針對難點來解決問題的。因為本文主要是介紹第一篇文章 NICE: Non-linear Independent Components Estimation 的工作,因此本文的模型也專稱為 NICE。
分塊耦合層
相對而言,行列式的計算要比函式求逆要困難,所以我們從“要求 2”出發思考。熟悉線性代數的朋友會知道,三角陣的行列式最容易計算:三角陣的行列式等於對角線元素之積。所以我們應該要想辦法使得變換f的雅可比矩陣為三角陣。NICE 的做法很精巧,它將 D 維的 x 分為兩部分 x1,x2,然後取下述變換:

其中 x1,x2 是 x 的某種劃分,m 是 x1 的任意函式。也就是說,將 x 分為兩部分,然後按照上述公式進行變換,得到新的變數 h,這個我們稱為“加性耦合層”(Additive Coupling)。不失一般性,可以將 x 各個維度進行重排,使得 x1=x1:d 為前 d 個元素,x2=xd+1:D 為 d+1∼D 個元素。
不難看出,這個變換的雅可比矩陣![]() 是一個三角陣,而且對角線全部為 1,用分塊矩陣表示為:
是一個三角陣,而且對角線全部為 1,用分塊矩陣表示為:

這樣一來,這個變換的雅可比行列式為 1,其對數為 0,這樣就解決了行列式的計算問題。
同時,(7) 式的變換也是可逆的,其逆變換為:

細水長flow
上面的變換讓人十分驚喜:可逆,而且逆變換也很簡單,並沒有增加額外的計算量。儘管如此,我們可以留意到,變換 (7) 的第一部分是平凡的(恆等變換),因此單個變換不能達到非常強的非線性,所以我們需要多個簡單變換的複合,以達到強非線性,增強擬合能力。

其中每個變換都是加性耦合層。這就好比流水一般,積少成多,細水長流,所以這樣的一個流程成為一個“流(flow)”。也就是說,一個 flow 是多個加性耦合層的耦合。
由鏈式法則:

因為“矩陣的乘積的行列式等於矩陣的行列式的乘積”,而每一層都是加性耦合層,因此每一層的行列式為 1,所以結果就是:
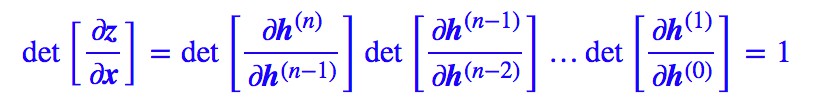
考慮到下麵的錯位,行列式可能變為 -1,但絕對值依然為 1,所以我們依然不用考慮行列式。
交錯中前進
要註意,如果耦合的順序一直保持不變,即:

那麼最後還是 z1=x1,第一部分依然是平凡的,如下圖:

▲ 簡單的耦合使得其中一部分仍然保持恆等,資訊沒有充分混合
為了得到不平凡的變換,我們可以考慮在每次進行加性耦合前,打亂或反轉輸入的各個維度的順序,或者簡單地直接交換這兩部分的位置,使得資訊可以充分混合,比如:

如下圖:

▲ 透過交叉耦合,充分混合資訊,達到更強的非線性
尺度變換層
在文章的前半部分我們已經指出過,flow 是基於可逆變換的,所以當模型訓練完成之後,我們同時得到了一個生成模型和一個編碼模型。但也正是因為可逆變換,隨機變數 z 和輸入樣本 x 具有同一大小。
當我們指定 z 為高斯分佈時,它是遍佈整個 D 維空間的,D 也就是輸入 x 的尺寸。但雖然 x 具有 D 維,但它未必就真正能遍佈整個 D 維空間,比如 MNIST 影象雖然有 784 個畫素,但有些畫素不管在訓練集還是測試集,都一直保持為 0,這說明它遠遠沒有 784 維那麼大。
也就是說,flow 這種基於可逆變換的模型,天生就存在比較嚴重的維度浪費問題:輸入資料明明都不是 D 維流形,但卻要編碼為一個 D 維流形,這可行嗎?
為瞭解決這個情況,NICE 引入了一個尺度變換層,它對最後編碼出來的每個維度的特徵都做了個尺度變換,也就是 這樣的形式,其中 s=(s1,s2,…,sD) 也是一個要最佳化的引數向量(各個元素非負)。這個 s 向量能識別該維度的重要程度(越小越重要,越大說明這個維度越不重要,接近可以忽略),起到壓縮流形的作用。
這樣的形式,其中 s=(s1,s2,…,sD) 也是一個要最佳化的引數向量(各個元素非負)。這個 s 向量能識別該維度的重要程度(越小越重要,越大說明這個維度越不重要,接近可以忽略),起到壓縮流形的作用。
註意這個尺度變換層的雅可比行列式就不再是 1 了,可以算得它的雅可比矩陣為對角陣:

所以它的行列式為![]() 。於是根據 (6) 式,我們有對數似然:
。於是根據 (6) 式,我們有對數似然:
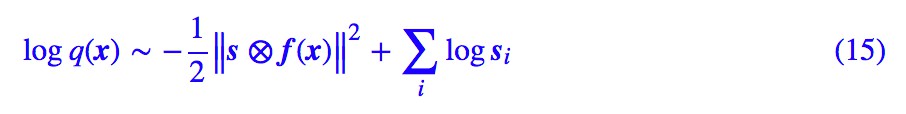
為什麼這個尺度變換能識別特徵的重要程度呢?其實這個尺度變換層可以換一種更加清晰的方式描述:我們開始設 z 的先驗分佈為標準正態分佈,也就是各個方差都為 1。
事實上,我們可以將先驗分佈的方差也作為訓練引數,這樣訓練完成後方差有大有小,方差越小,說明該特徵的“彌散”越小,如果方差為 0,那麼該特徵就恆為均值 0,該維度的分佈坍縮為一個點,於是這意味著流形減少了一維。
不同於 (4) 式,我們寫出帶方差的正態分佈:

將流模型 z=f(x) 代入上式,然後取對數,類似 (6) 式,我們得到:

對比 (15) 式,其實就有 si=1/σi。所以尺度變換層等價於將先驗分佈的方差(標準差)也作為訓練引數,如果方差足夠小,我們就可以認為該維度所表示的流形坍縮為一個點,從而總體流形的維度減 1,暗含了降維的可能。
特徵解耦
當我們將先驗分佈選為各分量獨立的高斯分佈時,除了取樣上的方便,還能帶來什麼好處呢?
在 flow 模型中,![]() 是生成模型,可以用來隨機生成樣本,那麼 f 就是編碼器。但是不同於普通神經網路中的自編碼器“強迫低維重建高維來提取有效資訊”的做法,flow 模型是完全可逆的,那麼就不存在資訊損失的問題,那麼這個編碼器還有什麼價值呢?
是生成模型,可以用來隨機生成樣本,那麼 f 就是編碼器。但是不同於普通神經網路中的自編碼器“強迫低維重建高維來提取有效資訊”的做法,flow 模型是完全可逆的,那麼就不存在資訊損失的問題,那麼這個編碼器還有什麼價值呢?
這就涉及到了“什麼是好的特徵”的問題了。在現實生活中,我們經常抽象出一些維度來描述事物,比如“高矮”、“肥瘦”、“美醜”、“貧富”等,這些維度的特點是:“當我們說一個人高時,他不是必然會肥或會瘦,也不是必然會有錢或沒錢”,也就是說這些特徵之間沒有多少必然聯絡,不然這些特徵就有冗餘了。所以,一個好的特徵,理想情況下各個維度之間應該是相互獨立的,這樣實現了特徵的解耦,使得每個維度都有自己獨立的含義。
這樣,我們就能理解“先驗分佈為各分量獨立的高斯分佈”的好處了,由於各分量的獨立性,我們有理由說當我們用f對原始特徵進行編碼時,輸出的編碼特徵 z=f(x) 的各個維度是解耦的。
NICE 的全稱 Non-linear Independent Components Estimation,翻譯為“非線性獨立成分估計”,就是這個含義。反過來,由於 z 的每個維度的獨立性,理論上我們控制改變單個維度時,就可以看出生成影象是如何隨著該維度的改變而改變,從而發現該維度的含義。
類似地,我們也可以對兩幅影象的編碼進行插值(加權平均),得到過渡自然的生成樣本,這些在後面發展起來的 Glow 模型中體現得很充分。不過,我們後面只做了 MNIST 實驗,所以本文中就沒有特別體現這一點。
實驗
這裡我們用 Keras 重現 NICE 一文中的 MNIST 實驗。
模型細節
先來把 NICE 模型的各個部分彙總一下。NICE 模型是 flow 模型的一種,由多個加性耦合層組成,每個加性耦合層如 (7),它的逆是 (9)。在耦合之前,需要反轉輸入的維度,使得資訊充分混合。最後一層需要加個尺度變換層,最後的 loss 是 (15) 式的相反數。
加性耦合層需要將輸入分為兩部分,NICE 採用交錯分割槽,即下標為偶數的作為第一部分,下標為奇數的作為第二部分,而每個 m(x) 則簡單地用多層全連線(5 個隱藏層,每個層 1000 節點,relu 啟用)。在 NICE 中一共耦合了 4 個加性耦合層。
參考程式碼
這裡是我用 Keras 實現的參考程式碼:
https://github.com/bojone/flow/blob/master/nice.py
在我的實驗中,20 個 epoch 內可以跑到最優,11s 一個 epoch(GTX1070 環境),最終的 loss 約為 -2200。
相比於原論文的實現,這裡做了一些改動。對於加性耦合層,我用了 (9) 式作為前向,(7) 式作為其逆向。因為 m(x) 用 relu 啟用,我們知道 relu 是非負的,因此兩種選擇是有點差別的。因為正向是編碼器,而逆向是生成器,選用 (7) 式作為逆向,那麼生成模型更傾向於生成正數,這跟我們要生成的影象是吻合的,因為我們需要生成的是畫素值為 0~1 的影象。

▲ NICE模型生成的數字樣本
退火引數
雖然我們最終希望從標準正態分佈中取樣隨機數來生成樣本,但實際上對於訓練好的模型,理想的取樣方差並不一定是 1,而是在 1 上下波動,一般比 1 稍小。最終取樣的正態分佈的標準差,我們稱之為退火引數。比如上面的參考實現中,我們的退火引數選為 0.8,目測在這時候生成模型的質量最優。
總結
NICE 的模型還是比較龐大的,按照上述模型,模型的引數量約為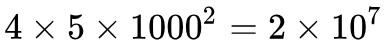 ,也就是兩千萬的引數只為訓練一個 MNIST 生成模型,也是誇張。
,也就是兩千萬的引數只為訓練一個 MNIST 生成模型,也是誇張。
NICE 整體還是比較簡單粗暴的,首先加性耦合本身比較簡單,其次模型 m 部分只是簡單地用到了龐大的全連線層,還沒有結合摺積等玩法,因此探索空間還有很大,Real NVP 和 Glow 就是它們的兩個改進版本,它們的故事我們後面再談。

點選以下標題檢視作者其他文章:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視作者部落格
