
報告摘要:近年來,知識圖譜技術進展迅速,各種領域知識圖譜技術在很多領域或行業取得了顯著落地效果。在領域知識圖譜技術的落地實踐過程中湧現出一大批理論與工程問題。本報告結合復旦大學知識工場實驗室十多個領域知識圖譜落地專案實踐,嘗試對這些問題進行初步解答,梳理這些問題背後的關鍵科學問題,總結領域知識圖譜技術落地的最佳實踐,以期為各行業的知識圖譜落地實踐提供參考。


隨著近幾年知識圖譜技術的進步,知識圖譜研究與落地發生了一些轉向。其中一個重要變化就是越來越多的研究與落地工作從通用知識圖譜轉向了領域或行業知識圖譜,轉向了企業知識圖譜。知識圖譜技術與各行業的深度融合已經成為一個重要趨勢。
在這一過程當中,湧現出一系列理論與技術問題。例如:知識圖譜技術到底能夠解決怎樣的行業痛點問題?知識圖譜技術與各行業融合的具體路徑是怎樣的?領域知識圖譜與通用知識圖譜的聯絡與區別是什麼?領域知識圖譜落地過程當中的關鍵科學技術問題是什麼?
這一系列問題的剖析與回答是進一步推動知識圖譜技術落地實踐、生根開花的關鍵所在。本次報告主要結合復旦大學知識工場實驗室在十多個行業的領域知識圖譜實踐經歷,對領域知識圖譜落地實踐中的關鍵問題以及主要對策做個初步解答。

報告思路很簡單,是一問一答的形式。這裡列出的問題是各個行業普遍關心的代表性的關鍵問題。

首先回答什麼是領域知識圖譜?領域知識圖譜(Domain-specific Knowledge Graph: DKG)的概念是從通用知識圖譜(General-purpose Knowledge Graph: GKG)演化而來,所以我們首先闡述什麼是知識圖譜(knowledge graph)。
在回答什麼是知識圖譜這個問題上有個非常有意思的現象,一直以來,工業界和學術界都沒有對於知識圖譜給出一個嚴格的定義。如果大家去搜維基百科,會看到維基百科說知識圖譜是 Google 的一種知識表示。
然而,一個相對嚴格的定義是必要的,我給出的定義是“大規模語意網路”。理解這個定義有兩個要點。第一個是語意網路,語意網路包含的是物體、概念以及物體和概念之間各種各樣的語意關係。比如 C 羅是一個足球運動員,是一個物體,金球獎也是一個物體。何為物體?黑格爾在《小邏輯》裡面曾經給物體下過一個定義:“能夠獨立存在的,作為一切屬性的基礎和萬物本原的東西”。
也就是說物體是屬性賴以存在的基礎,必須是自在的,也就是獨立的、不依附於其他東西而存在的。比如身高,單單說身高是沒有意義的,說“運動員”這個類別的身高也是沒有意義的,必須說某個人的身高,才是有明確所指,有意義的。理解何為物體,對於進一步理解屬性、概念是十分必要的。
再來看概念(concept),概念又稱之為類別(type)、類(category)等。比如“運動員”,不是指某一個運動員,而是指一類人,這就是一個概念。語意網路中的關聯都是語意關聯,這些語意關聯發生在物體之間、概念之間或者物體與概念之間。物體與概念之間是instanceOf(實體)關係,比如“C羅”是“運動員”的一個實體。概念之間是subclassOf(子類)關係,比如“足球運動員”是“運動員”的一個子類。物體與物體之間的關係十分多樣,比如“C羅”效力於“皇家馬德里球隊”。
理解知識圖譜的第二個要點是大規模。除了語意網路之外,上個世紀伴隨著專家系統的研製而發展出了類別多樣的知識表示形式,比如產生式規則、本體、框架,還有決策樹、貝葉斯網路、馬爾可夫邏輯網路等。這些知識表示表達了現實世界各種複雜語意。知識表示多種多樣,語意網路只是各種知識表示中的一種而已。
既然上世紀七八十年代有如此多的知識表示,而且知識圖譜本質上是語意網路,為什麼今天還要提知識圖譜?那是因為知識圖譜與傳統七八十年代的知識表示有一個根本的差別,那就是在規模上的差別。
知識圖譜是一個大規模語意網路,而七八十年代的語意網路是個典型的小知識(small knowledge)。知識圖譜的規模巨大,像 Google knowledge graph 在 2012 年釋出之初就有 5 億多的物體,10 億多的關係,如今規模更大。知識圖譜的規模之所以如此巨大,是因為它強調對於物體的改寫。比如說運動員作為一個類別在知識圖譜裡涵蓋了數以萬計諸如 C 羅這樣的物體。知識圖譜的規模效應帶來了效用方面的質變。知識圖譜是典型的大資料時代產物。關於這些觀點的詳細描述參考本人的《知識圖譜與認知智慧》,在此不再贅述。
那什麼是領域知識圖譜呢?比如“足球知識圖譜”,裡面大多都是跟足球相關的物體和概念。如果知識圖譜聚焦在特定領域,就可以認為是領域知識圖譜。領域知識圖譜的範疇再大一些就是行業知識圖譜了,比如農業知識圖譜。近幾年一些大型企業對於利用知識圖譜解決企業自身的問題十分感興趣,於是就有了橫貫企業各核心流程的企業知識圖譜。領域知識圖譜、行業知識圖譜與企業知識圖譜有時邊界也十分模糊。近幾年,這幾類知識圖譜得到越來越多的關註。
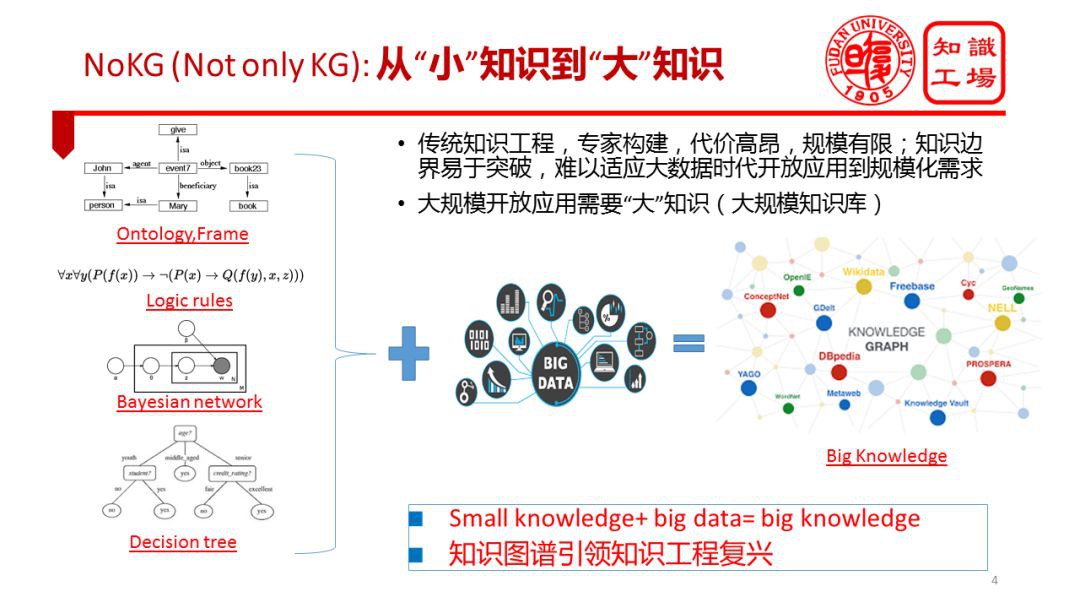
在理解領域知識圖譜時,我想指出一個非常重要的觀點,我稱之為“NoKG”,也就是 Not only KG。這裡是借鑒“NoSQL”的說法。首先,知識圖譜只是知識表示的一種,單單知識圖譜不足以表達現實世界的豐富語意,不足以解決所有問題。比如很多領域有著豐富的if-then規則(比如故障維修、計算機系統配置),這些規則利用知識圖譜表達就很牽強,特別是對於 if A and B then C 這樣的規則。條件部分的原子運算式之間的關係可以很複雜,利用知識圖譜難以表達。知識表示方面的缺陷限制了知識圖譜解決問題的範圍。
其次,知識圖譜輔以其他知識表示則有可能解決很多複雜的實際問題。作為一種語意網路,知識圖譜在大資料的賦能下就已經能夠解決很多實際問題。可以設想一下,還有更多的知識表示沒有突破規模瓶頸。在大資料的賦能下,其他型別的知識表示也將能夠解決更多實際的問題。越來越多的領域應用需要的知識已經突破了知識圖譜的範圍,對其他知識(比如產生式規則、貝葉斯網路、決策樹等)提出了訴求。比如,我們正在嘗試聯合使用知識圖譜與產生式規則實現面向故障診斷的精準語意檢索。
NoKG 的另一層含義在於領域應用不僅需要靜態知識,更需要動態知識。知識圖譜側重於表達物體、概念之間的語意關聯,這些語意關聯大多是靜態的、顯性的、客觀的、明確的。而實際應用中對過程性、決策性知識是有著大量需求的,這些知識大部分是動態的、隱形的、帶有一定主觀性的,比如疾病診斷、投資決策、司法解釋等等。
這些應用需要把決策的因素、機制與過程加以表達。動態知識的沉澱對於很多行業來說是強需求。隨著我國人口紅利消失,人力成本持續提高,特別是富有經驗的領域專家成本越加高昂。這些人員一旦流失,會給企業造成巨大損失。為此,企業特別需要將領域專家大腦中的決策知識加以沉澱,賦予機器,從而一定程度上降低對專家的依賴。
但是,動態知識的表達與獲取仍然是個具有重大挑戰的技術問題。很多決策過程難以明確表達,很多決策因素是隱性的。比如老中醫看病,中醫智慧化一直希望將有經驗的老中醫的看病經驗沉澱下來。但是老中醫自己也未必說得清楚是根據什麼看病的。雖然中醫也有樸素的理論在支撐其診斷,但總體而言整個過程是模糊的。
在傳統知識管理領域曾經設計出很多激勵制度以促進企業內的知識表達與沉澱,但是阻力重重,收效甚微。關鍵問題在於工程師、分析師、醫生等等領域專家自己也不知道如何表達。傳統知識工程透過專業的知識工程師協助領域專家進行知識獲取,但總體上的代價太大,過程太重,不易成功。動態過程的知識表達已經困難重重,知識獲取就更加雪上加霜了。曾有人設想獲取金牌投資經理投資決策的知識,嘗試為投資經理提供新聞閱讀工具,透過其點選行為把握其所關註新聞,甚至透過眼球跟蹤捕捉其關註的文章片段,以期精準捕捉其決策要素。知識獲取之困難可見一斑。但是知識表示及獲取的重心將逐步過渡到動態知識是必然趨勢,也是擺在研究人員面前的攻關戰。

現在回答第二個問題,DKG(領域知識圖譜)和 GKG(通用知識圖譜)的關係和區別。首先來看 GKG 和 DKG 的區別。兩者之間的區別是明顯的,體現在知識表示、知識獲取和知識應用三個層面。
在知識表示層面的差別可以從廣度、深度和粒度這三個維度加以考察。從廣度來看,GKG 涵蓋的範圍明顯大於 DKG。從深度來看,DKG 通常更深,尤其體現在概念圖譜的層級體繫上。比如,在娛樂領域,追星族們可能很關心“內地鼻子長得帥的男明星”,在電商領域單單“連衣裙”不足以滿足人們的購物需求,電商圖譜中往往要涵蓋“韓版夏裝連衣裙”這樣的細分品類。
如何表達與處理這些較深層次的概念對於很多領域知識圖譜應用而言是個巨大挑戰。需要指出的是層次較深的細粒度概念往往不是基本概念(basic concept)。這意味著不同人對這些深層次概念有著不同的認知體驗的,因而會有較大的主觀分歧。這就是很多人工構建的概念層級深到一定層次就很難繼續下去的重要原因。此時,資料驅動的自下而上的自動化方法往往比較適合。
第三個維度是知識表示的粒度,DKG 通常涵蓋細粒度的知識。知識表示是有粒度的,知識的基本單元可以是一個檔案,也可以是文章中的段落、法律中的條款、教育資源中的知識點等等。傳統知識管理往往以檔案為單位組織企業知識資源。在司法智慧中的司法解釋往往需要將知識粒度控制在條款級別。在教育智慧化領域,學科的知識點往往是個合適的粒度,以知識點為中心組織教學素材和資源是個可行的思路。
知識表示的粒度也可以細化到知識圖譜中的物體與屬性級別,或者是邏輯規則中的條件與結果。比如法律條款可以進一步細化到由條件與結果構成的產生式規則,數學中的很多定理也可以進一步細化為相關的公理系統(一組產生式規則)。
既然知識表示的粒度是可控的,我們應該如何控制呢?很多場景下知識表示的粒度是個需要仔細斟酌的問題。一般而言,粒度越細表達能力越強,但是其表達與獲取代價也越大。細粒度知識表示一般是領域應用的強需求之一。比如在知識管理領域,粒度粗放已經成為阻礙企業知識管理髮展的根本問題。傳統知識搜尋只能搜尋到檔案級別,如果不幸這個檔案含有 1000 頁內容,則會給使用者帶來巨大麻煩。
但是,凡事過猶不及,太細粒度的知識表示也往往會給知識獲取帶來巨大的複雜性。合理控制知識表示的粒度,不盲目求精求細,是知識庫技術落地成功的關鍵思路之一。很多落地實踐中過早地陷入細粒度知識獲取的泥潭當中,消耗巨大但收效甚微。但事實上細粒度的知識表示在很多場景下也是不必要的。因此,在實踐中建議緊扣應用需求,從應用出發反推需要怎樣粒度的知識表示。
在知識獲取層面,DKG 對質量往往有著極為苛刻的要求。因為很多領域應用場景是極為嚴肅的(也就是 mission critical 的 AI 應用)。比如醫療,某個藥物有哪些禁忌症,這類知識是不能出錯的。對質量的苛刻要求自然就意味著領域知識圖譜構建過程中專家參與的程度相對較高。需要指出的是,專家的積極幹預並不意味著盲目的手動構建。如何應用好人力資源,包括哪些環節讓人參與以及專家參與的具體方式等問題一直以來就是領域知識圖譜落地的關鍵問題。
在眾包計算中有不少方法值得借鑒。但是對於有著依賴專家經驗的歷史傳統而言,如何盡可能降低人力資源的成本是個值得深入研究的問題。一般而言,我們期望構建過程盡可能自動化;但是由於對標的圖譜有著苛刻的質量要求,最終的知識驗證過程還是要訴諸人力。較多的人工幹預自然決定了領域知識圖譜落地過程自動化程度相對較低。
相比較而言,通用知識圖譜構建一定要高度自動化,因為通用知識圖譜規模太大(動輒數千萬的物體,數億的關係),如果沒有自動化的辦法,根本無法推進,除非存在有效的大規模眾包化手段,比如知識類互動遊戲等。
在知識應用層面,首先,領域知識圖譜的推理鏈條往往相對較長。原因有兩個方面。一是領域知識圖譜相對密集。比如某個疾病在通用知識庫中相關物體可能寥寥無幾,但是在一個醫療知識圖譜中相關物體可能數以百計。知識庫建設有一個有意思的現象那就是永遠不要指望知識庫是完備的。完備是知識庫建設永遠在追求但卻無法企及的標的。
但是,DKG 相對於 GKG 在單個物體的相關知識改寫面有著明顯優勢。也正是基於此,領域知識圖譜上的推理鏈條可以較長。在一個相對稠密的領域知識圖譜上長距離推理之後的結果仍然還可能是個有意義的結果。但是在通用知識圖譜上,由於其相對稀疏,多步推理之後語意漂移(semantic drift)嚴重,其推理結果很容易“面目全非”、“離題千里”,令人難以理解了。
所以在 GKG 之上的推理操作大都是基於背景關係的一到兩步的推理。比如搜尋“劉德華”,可以推薦他的歌曲,那是因為知識圖譜告知我們劉德華是一個歌星,主要作品是歌曲,這是兩步的推理鏈條。其次,領域知識圖譜上的計算操作也相對複雜一些。像之前提到的深度推理就是一種複雜的應用。
此外,領域應用往往會涉及複雜查詢。比如在公共安全領域,對於重點監控人群,通常需要在相關圖譜中查詢該人群形成的稠密子圖。諸如此類的複雜計算和操作,在領域知識圖譜中並不罕見。相反,通用知識圖譜的查詢多為一到兩步的鄰居查詢,相對簡單。
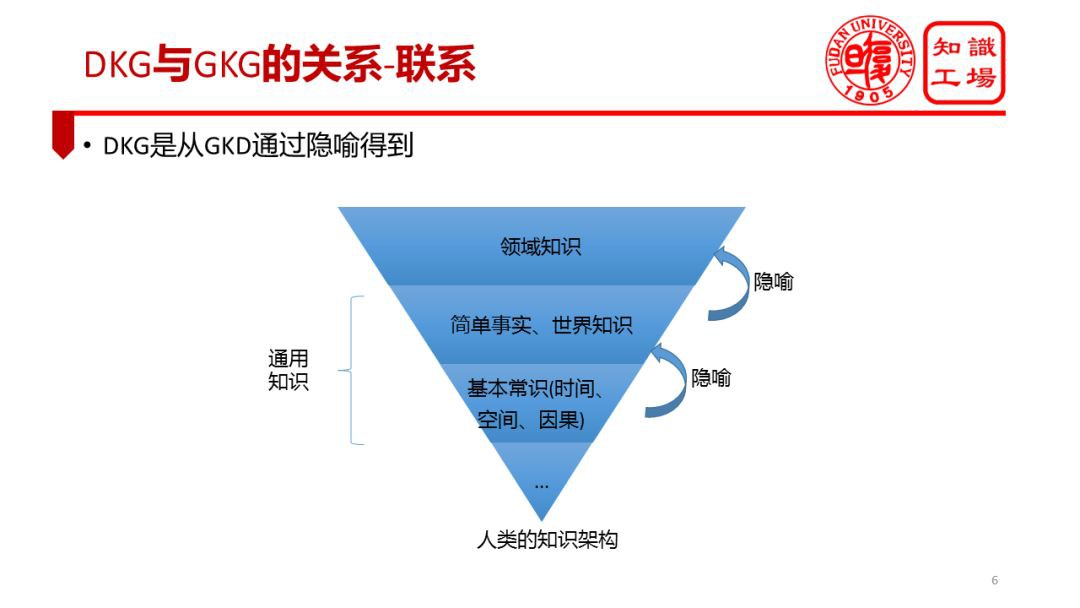
現在來看聯絡,通用知識圖譜與領域知識圖譜關係是十分密切的,根本原因是人類的知識體系是有結構的。我個人認為人類的知識體系呈現出倒三角形的結構。三角結構越是接近底層的部分越是最為基本的、形式簡單的知識;越往上層知識越為抽象、越加多樣,也越加細分、專業性越強。
在個人成長的早期階段,人類透過自身身體與世界的互動習得了最為基本的常識,特別是關於時間、空間、因果的基本常識。我們知道時間是在流逝的、我們知道空間是有一定位置關係的、我們明白有因必有果。這些都是最為基本的常識。
這些常識是構建認知體系的基礎。在此基礎上,透過“隱喻”或者“類比”(美國的侯世達教授甚至認為類比是智慧的本質,見其《哥德爾、艾舍爾、巴赫》一書),人類發展出更為高層的知識,包括對於世界的知識(比如我們知道太陽從東邊升起,人是要呼吸的等等)、簡單關聯事實(比如下雨了,地面會潮濕)。基於這些簡單知識,再透過隱喻和類比,進一步形成特定領域的知識。
很多領域知識本質上是透過隱喻從基本知識發展而來的。比如人們關於社會地位的認識,某個人社會地位較高實際上是從空間上的高低隱喻而來的。說某個人很積極、很激進,實際上是從時間的先後隱喻而來的。最近還有一個例子,將各種晶片與人體的各器官相類比:做人工智慧的晶片就好比在做大腦,做通用晶片就好比在做血管,做計算晶片就好比在做心臟,這都是典型的隱喻。所以很多領域知識都是從人類的基本常識和世界知識透過隱喻發展而來的。因此,領域知識和通用知識之間存在著千絲萬縷的聯絡。理解自然語言中的隱喻現象也一直是自然語言處理領域的一個研究熱點。
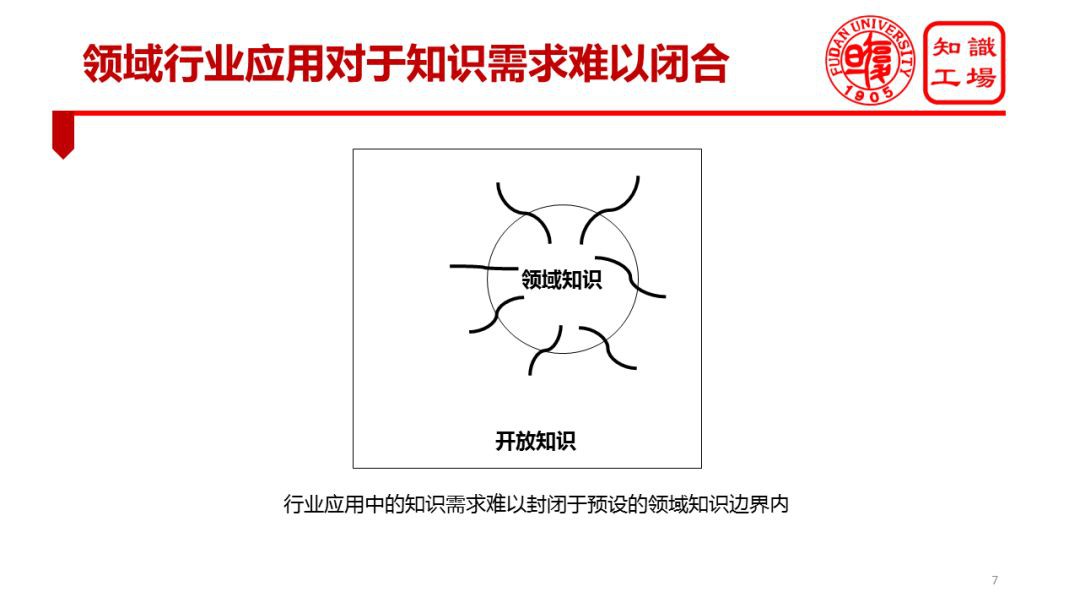
DKG 與 GKG的另一個聯絡在於行業應用對於領域知識的需求難以閉合。也就是說,很多行業應用看上去好像只需要領域知識,但是實際應用過程中往往會超出領域所預先設定的知識邊界。比如在金融知識圖譜落地過程中,本以為涵蓋公司、法人、機構、產品等就足夠了。但是實際應用過程中我們發現這些型別的知識還遠遠不夠。比如基於金融知識圖譜的關聯分析往往會牽扯出幾乎萬事萬物。比如說諸如龍卷風的氣候災害,會使得農作物產量下降,農業機械的出貨量因而就會下降,農機的發動機產量也就相應要下降,從事農機發動機關鍵部件生產的公司業績就會下降,相關公司的股票可能就會下跌。
這個例子形象地說明幾乎一切事物在某種意義下都是跟金融有關係。事實上,一切物體都身處在一個複雜的因果網路中,世界是普遍關聯的。這就導致沿著任何一個物體開展關聯分析都極為容易超出預先設定的知識邊界。
因此,行業應用中的知識需求難以封閉於領域知識的邊界範圍內。換言之,越為封閉的應用場景,機器越容易取得成功。所謂封閉是指一個有限的知識子集足以支撐應用需求。比如,AlphaGo 的成功很大程度上得益於圍棋遊戲規則有限,整個遊戲過程不會用到下棋規則之外的知識。但對於星際爭霸之類的遊戲,機器取得優異成績就顯得較為困難。因為這類策略性遊戲所用到的知識型別多樣,不僅需要有關排兵佈陣、武器應用、戰場環境等相關知識,還可能涉及很多與社會及文化相關的知識。智慧客服等領域的成功也一定程度上歸功於客服知識的相對封閉。
所以,領域應用所涉及的知識體系越是封閉,越容易成功。這是在很多領域知識圖譜落地過程中選擇應用試點時,應該遵循的一個基本原則。
延續上面的分析,進一步可以回答業界十分關心的一個問題:知識圖譜在什麼樣的應用中易於成功?知識圖譜落地應用往往遵循一個循序漸進的推進過程。因此,很多行業都希望選取特定場景先行試點,那麼選擇什麼樣的場景進行優先驗證呢?知識圖譜只是整個智慧化技術的手段之一。知識圖譜不能解決行業的所有問題,那麼,某個特定的行業應用到底能否受益於知識圖譜技術?這些都是知識圖譜的行業應用亟需回答的問題。
我根據前兩頁內容中觀點,給出幾個選擇依據。第一、領域知識相對封閉。已經闡明,越是封閉的領域越容易成功。
第二、簡單知識與簡單應用。何為簡單知識?關於知識複雜性的評估實際上是個非常複雜的問題。知識複雜性的內在機理和評測機制是個十分有趣的科學問題。
從操作層面來看,可以從特定人群學習某類知識所需要時間來評估。假設我們只考慮完成了基礎教育(比如中國的九年制基礎教育)的人群。對於不同知識,這一人群學習週期不一。比如,很顯然對於某個企業的客服知識,幾乎一週簡單培訓就可以上崗。但是對於治病的知識,即便一個醫學院學生可能也要十多年才能掌握。所以,大部分對於人而言簡單崗位培訓就能勝任的工作,也往往適用於機器,是有可能優先被機器所代替的。還有些應用場景屬於知識的簡單應用,比如同樣是在醫療領域,醫院的導診崗位,就屬於醫學知識的簡單應用。只需要根據癥狀進行簡單的分類,即便不夠精準,在具體科室醫生治療時還有進一步糾正的機會。
第三、較少涉及常識。如果領域應用所涉及的知識集中在人類知識結構的上層(也就是專業性較強的知識),較少涉及底層的常識,則相對容易成功。其根本原因在於常識的獲取是異常困難的。人類很容易理解常識,但是對於機器而言常識理解卻十分困難。我們知道太陽從東邊升起,人是兩條腿走路的,魚是在水裡遊的,而機器很難知道這些常識。因為常識是人類在學齡前透過身體與世界的互動與體驗積累而得。我們每個人都理解常識,因而不用掛在嘴邊說明,就能彼此理解。
因此,文字或者語料中對於常識鮮有提及,常識因而也就無從抽取。常識缺失也就成了知識庫、知識工程,乃至整個人工智慧的痛點問題。目前機器智慧在常識理解方面仍然舉步維艱。因此,我認為大量用到常識的應用面臨巨大挑戰。比如說有公司想做財務報銷方面的智慧化,此類場景就有可能涉及很多常識。比如半夜 12 點打出租車,或者說打出租車打了四五個小時,又或者從美國飛到上海只飛了一個小時,這都是有問題的。這些問題我們人類很容易識別,因為都是常識問題,但對機器而言就很困難。還有一個非常典型的大量用到常識的場景就是刑偵智慧化。公安人員在破案過程中用到大量常識,嫌疑人往往是基於證據根據常識進行推理而鎖定的,因此讓機器代替刑偵人員破案仍十分困難。

很多領域知識圖譜應用的方案是建立在通用知識圖譜基礎之上的。GKG 對於 DKG 有著重要的支撐作用。一方面,GKG 可以給很多 DKG 提供高質量的種子事實。這些種子事實可以用做樣本指導抽取模型的訓練。另一方面,GKG 可以提供領域樣式(Schema)。
領域知識圖譜構建時需要花費巨大精力設計領域樣式,比如為了構建娛樂領域知識圖譜,必須首先明確描述歌手的屬性串列(有時又稱作 template)中應該包括專輯、代表作、簽約公司等屬性。雖然 GKG 對於特定領域的物體改寫率不高,但是透過聚合 GKG 中所有歌手資訊,有關歌手的描述模板基本上已經能夠滿足初步需要。後續只需要在初始模板基礎上逐步完善即可。
能否充分利用通用知識圖譜對很多領域知識圖譜的構建具有重要意義。這就是為什麼很多團隊不遺餘力地做好通用知識圖譜(比如我們實驗室的通用百科知識圖譜 CN-DBpedia 和通用概念圖譜 CN-Probase)的重要原因。
領域圖譜建好之後又可以反哺通用知識圖譜。復旦知識工場實驗室就是按照這個思路持續運營多年。我們先透過通用知識圖譜為各領域知識圖譜構建提供大量的種子事實,使得快速構建很多領域知識圖譜成為可能。各領域知識圖譜做的很深很細之後,可以反過來補充通用知識圖譜。GKG 與 DKG 這種互補形式的架構在很多領域的知識圖譜落地中是個非常重要的架構。

知識表示其實一直以來都有兩種基本的方式:符號化表示與數值型表示。兩者孰優孰劣?各自的適用場景是怎樣的?一直是知識圖譜落地過程中常被問及的問題。
第一種是符號化(Symbol)的表示,比如說 PPT 左上角的小規模語意網路,表達了約翰給瑪麗一本書這樣的事實。這個例子中大量的使用了字元、箭頭等符號。顯然,符號表示形象直觀,易於我們理解。人是可以理解符號的,但是沒辦法理解向量。
知識表示還有一種表示是數值化的分散式表示,它是面向機器的。機器是無法“理解”符號的,只能處理數值和向量。分散式表示是將符號知識整合到深度學習框架中的一種基本方式。符號化表示是一種顯性的表示,而分散式表示是一種隱性的表示。符號化表示易理解、可解釋,而分散式表示是難解釋、難理解的。符號化表示的另一優點在於推理能力。比如數學定理證明都是基於符號推理進行的。雖然基於知識圖譜的分散式表示,也可以開展一定程度上的推理,
但是需要指出的是分散式推理已經很大程度上丟失了知識圖譜原有的語意,分散式推理只能推理語意相關性,而無法明確是何種意義下的語意相關。我個人傾向於認為分散式推理離實用還很遙遠。如果非要為知識圖譜上的分散式推理找到應用場景,那隻能作為很多複雜任務的預處理步驟,將明顯語意不相關的元素加以剪枝,後續仍需要能夠充分利用符號語意的方法進行精準的語意推理。
不管是大資料時代還是人工智慧時代,都需要領域知識圖譜。我曾在《知識圖譜與認知智慧》這一報告中詳細闡述過相關觀點。這裡補充幾個觀點。
首先,需要知識圖譜去構建知識引擎,去釋放大資料的價值。很多行業和企業都有資料,都有大資料。但是這些大資料非但沒有創造價值,反而成為了很多行業的負擔。阻礙大資料價值變現的根本原因在於缺少智慧化的手段,更具體而言就是缺少一個能像人一樣能夠理解行業資料的知識引擎。
行業從業人員為什麼能理解行業資料進而開展行業工作呢,那是因為行業從業人員具有相應的行業知識。如果把同樣的行業知識賦予機器,構建一個行業知識引擎,那麼機器也就可能代替人去理解、挖掘、分析、使用資料,可以代替行業從業人員挖掘資料中的價值。簡言之,將行業知識賦予機器,讓機器代替行業從業人員從事簡單知識工作,是當下以及未來一段時間內基於機器認知智慧的行業智慧化的本質。在行業智慧化的實現行程中,透過領域知識圖譜對資料進行提煉、萃取、關聯、整合,形成行業知識或領域知識,讓機器形成對於行業工作的認知能力,從而實現一個行業知識引擎,實現知識工作自動化,已經成為了行業智慧化日漸清晰的一條路徑。
伴隨著人工智慧時代的到來,“智慧”機器無處不在,手錶、手環、手機、音響、電視、機器人等等都已是隨處可見的“智慧”物體,這些機器逐步走入人們的生活。但是現在機器普遍不具備人們所期望的智慧,與人類智慧相比只能算是機器“智障”。機器“智障”的根本原因是這些機器沒有一個像人一樣聰慧的大腦。事實上,機器最缺的是一個機器智腦。沒有這樣的智腦,機器只能是一具沒有“靈魂”的僵屍。人腦之所以能給人類帶來智慧的根本原因在於人腦能夠儲存知識與利用知識。
類似地,機器智腦也需要有知識的充實,才能夠形成真正意義上的機器智慧。富含各類知識的機器智腦,可以理解人類的語言與行為,能夠理解我們所從事的行業工作,從而使得自然人機互動成為可能,使得人機協同混合智慧成為可能。最終為機器融入人類社會掃清障礙,促進人機和諧共存。
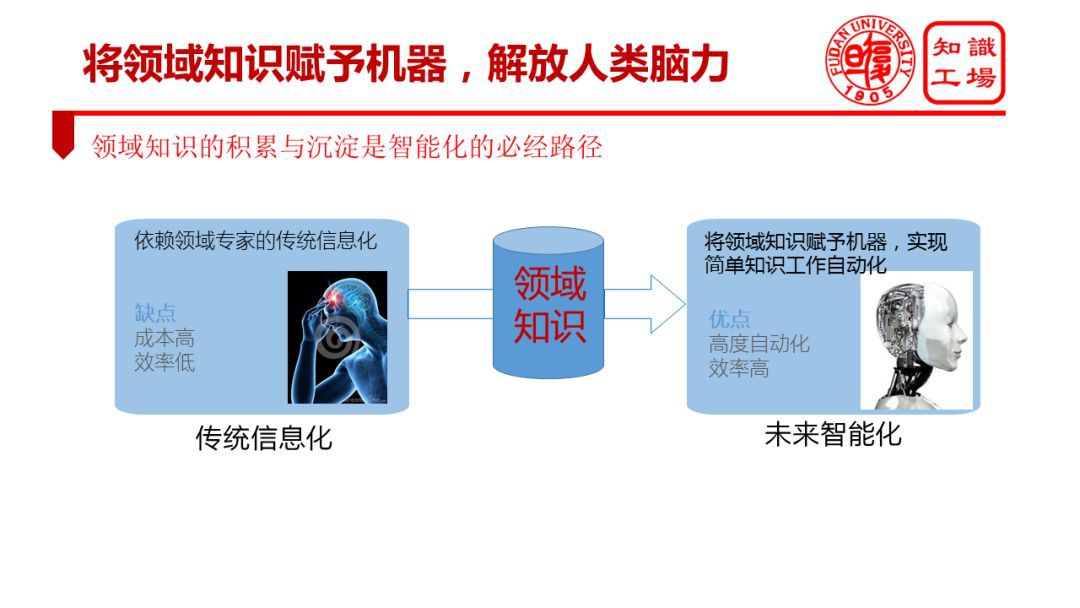
從社會發展的角度來看,可以說將領域知識賦予機器,將是進一步提高機器生產力、釋放勞動力資源、降低人力成本的重要技術。伴隨著我國人口紅利的逐步消失,各行業的人力成本普遍提高,各行業對於機器生產力的提升提出了普遍訴求。伴隨著工業 4.0 的推進以及自動化技術普及,傳統物體行業人的體力勞動已經逐步被解放。人力資源成本釋放的空間已經逐步從體力勞動轉向腦力勞動。
當下,人工智慧技術給人力成本降低帶來的新機遇主要體現在用機器代替人的腦力勞動,特別是各行業的簡單知識工作將逐步為機器所代替。機器的記憶幾乎是無窮無盡的,機器決策時可以同時考慮數百萬變數,機器運算的速度遠超人類,所以一旦把行業知識賦予機器,就能實現高度自動化的機器工作。在這一背景下,各行業都走上了智慧化升級轉型的道路,而實現機器的認知能力是智慧化升級轉型的基本路徑。

以政府資料治理為例,在政府領域,由於歷史原因,政府各部門的資訊系統的建設多是各自為陣,形成了大量的資訊孤島,這就給政府資料價值發揮帶來了巨大障礙。這些障礙尤為集中地體現在政府資料治理與應用方面,碎片化資料難以融合、資料共享開放缺乏必要依據、政府決策仍然缺乏來自資料的有效支撐、政府資料的應用樣式相對單一。
但如果有了領域知識圖譜,就可以為資料融合提供元資料,將政府資料融合從繁重的手工整合中解放出來。比如 ID 與身份證通常指代相同的欄位,這樣的元資料可以自動建立 A 資料庫中名為“ID”的欄位與 B 資料庫中名為“身份證”欄位的對映。
政府在大力推進政府資料共享和開放過程中,必須確保資料安全。比如個人隱私資料很敏感是不可以開放的,當前擬開放的資料都要經過人工的審慎判斷,耗時耗力。但事實上知識圖譜可以為政府資料開放提供必要的背景知識。比如如果設定了個人資訊是不能開放的,那麼個人的住址、出生日期等等都是不能開放的,這可以透過背景知識庫自動推斷得到。
政府資料的決策和分析缺乏可解釋依據,這些依據都可以從領域知識圖譜裡去尋找。當前政府資料的應用多是簡單的檢索與分析,缺乏基於深度推理的智慧應用。而推理需要一個基本的載體,推理載體的天然選擇是知識圖譜。基於符號化的知識圖譜,可以開展有效的深度推理。

領域知識圖譜系統的生命週期包含四個重要環節:知識表示、知識獲取、知識管理與知識應用。這四個環節迴圈迭代。知識應用環節明確應用場景,明確知識的應用方式。知識表示定義了領域的基本認知框架,明確領域有哪些基本的概念,概念之間有哪些基本的語意關聯。比如企業家與企業之間的關係可以是創始人關係,這是認知企業領域的基本知識。知識表示只提供機器認知的基本骨架,還要透過知識獲取環節來充實大量知識實體。比如喬布斯是個企業家,蘋果公司是家企業,喬布斯與蘋果公司就是“企業家-創始人-企業”這個關係的一個具體實體。
知識實體獲取完成之後,就是知識管理。這個環節將知識加以儲存與索引,併為上層應用提供高效的檢索與查詢方式,實現高效的知識訪問。四個環節環環相扣,彼此構成相鄰環節的輸入與輸出。在知識的具體應用過程中,會不斷得到使用者的反饋,這些反饋會對知識表示、獲取與管理提出新的要求,因此整個生命週期會不斷迭代持續演進下去。
在整個生命週期中,我認為最重要的是明確知識的應用場景,也就是回答清楚一個問題:利用領域知識解決怎樣的應用問題。再根據應用來反推到底需要怎樣的知識表示,明確知識邊界。
在當下的很多知識圖譜應用實踐中,有一個不好的苗頭就是“為了圖譜而圖譜”。雖然知識圖譜是當下的熱點技術,儘管每年各行業大量的資訊化預算苦苦尋求好的落地專案,儘管資本界熱錢湧動尋求好的投資標的,但是不應以知識圖譜為名,不應盲目炒作知識圖譜技術。
知識圖譜技術是當下熱點不假,但絕不是萬能技術。它能解決的問題是有限的,它的成功應用有著苛刻的條件。需要謹慎選擇落地場景;需要客觀評估技術成熟度以及技術與應用的適配程度;需要充分考慮資源與收益的平衡等一系列問題。為圖譜而圖譜,或者僅以圖譜為名而行悖圖譜之實,對知識圖譜產業有百害而無一利。歷史上前車之鑒太多了。很多做 AI 的研究人員與公司,最終落得個“騙子”下場。
歷史上的 AI 技術的演進道路呈現出大起大落之勢。這一系列現象歸根結底是因為人們對於 AI 預期過高,盲目大規模上線很多知識工程專案,無視應用場景而對知識庫盲目求大求全。殊不知人之所以偉大其實就在於任何一個普通人所掌握的知識都可以說是無邊無界的。我們現在構建的知識庫離機器達到普通人認知世界所需要的水平還十分遙遠。
知識資源建設可以說是永遠在路上,沒有最好,只有更好。所以,比較務實的作法是:謹慎選擇合適的應用場景,構建滿足場景需要的知識資源。這背後體現的也是典型的自下而上的建設思路。大而全、自上而下、運動式知識資源建設(這個經常是國內的典型方式),容易遇到難以逾越的技術瓶頸。一言以蔽之,知識資源建設的基本原則是適度。“適”是指對於特定應用場景的適配,“度”是指合理把控知識的邊界與體量。

我們常用三元組表示領域知識圖譜。我想強調一點,知識圖譜只能表達一些簡單的關聯事實,但很多領域應用的需求已經遠遠超出了三元組所能表達的簡單關聯事實,實際應用日益對於利用更加多元的知識表示豐富和增強知識圖譜的語意表達能力提出了需求。
這一趨勢首先體現在對於時間和空間語意的拓展與表達方面。有很多知識和事實是有時間和空間條件的,比如說“美國總統是特朗普”這個事實的成立是有時間條件的,十年前美國的總統不是特朗普,十年之後應該也不大可能是特朗普。還有很多事實是有空間條件的,比如“早餐是燒餅與油條”這件事,在中國是這樣,但是在西方並非如此,西方的早餐可能是咖啡、麵包。
從時空維度拓展知識表示對很多特定領域具有較強的現實意義。比如在位置相關的應用中,如何將 POI (Point of Interest) 與該 POI 相關物體加以關聯,成為當下拓展 POI 語意表示的重要任務之一。比如將“邯鄲路 220 號”(復旦大學地址)關聯到“復旦大學”是十分有意義的。在網際網路娛樂領域,粉絲們往往不僅僅關心某個明星的妻子是誰,可能更關心明星的前任妻子、前任女友等資訊,這些應用都對事實成立的時間提出了需求。
第二、增強知識圖譜的跨媒體語意表示。當前的知識圖譜主要以文字為主,但是實際應用需要有關某個物體的各種媒體表示方式,包括聲音、圖片、影片等等。比如對於物體“Tesla Model S”,我們需要將其關聯到相應圖片和影片。知識圖譜時空維度拓展在物理實現上可以透過定義四元組或者五元組加以實現。跨媒體表示可以透過定義相關的屬性加以實現。
知識圖譜的語意增強總體上而言將是未來一段時間知識表示的重要任務。知識圖譜作為語意網路,側重於表達物體、概念之間的語意關聯,還難以表達複雜因果關聯與複雜決策過程。如何利用傳統知識表示增強知識圖譜,或者說如何融合知識圖譜與傳統知識表示,更充分地滿足實際應用需求,是知識圖譜領域值得研究的問題之一。在一些實際應用中,研究人員已經開始嘗試各種定製的知識表示,在知識圖譜基礎上適當擴充套件其他知識表示是一個值得嘗試的思路。

領域知識圖譜的構建是個領域知識的獲取過程。這一過程系統性強,涉及眾多技術手段。但是其基本流程具有一定共性,如 PPT 所示。
第一步是樣式(Schema)設計。這一步是傳統本體設計所要解決的問題。基本標的是把認知領域的基本框架賦予機器。在所謂認知基本框架中需要指定領域的基本概念,以及概念之間 subclassof 關係(比如足球領域需要建立“足球運動員”是“運動員”的子類);需要明確領域的基本屬性;明確屬性的適用概念;明確屬性值的類別或者範圍。比如“效力球隊”這個屬性一般是定義在足球運動員這個概念上,其合理取值是一個球隊。
此外,領域還有大量的約束或規則,比如對於屬性是否可以取得多值的約束(比如“獎項”作為屬性是可以取得多值的),再比如球隊的“隸屬球員”屬性與球員的“效力球隊”是一對互逆屬性。這些元資料對於消除知識庫不一致、提升知識庫質量具有重要意義。
第二步是明確資料來源。在這一步要明確建立領域知識圖譜的資料來源。可能來自網際網路上的領域百科爬取,可能來自通用百科圖譜的匯出、可能來自內部業務資料的轉換,可能來自外部業務系統的匯入。應該儘量選擇結構化程度相對較高、質量較好的資料源,以盡可能降低知識獲取代價。
第三步是詞彙挖掘。人們從事某個行業的知識的學習,都是從該行業的基本詞彙開始的。在傳統圖書情報學領域,領域知識的積累往往是從敘詞表的構建開始的。敘詞表裡涵蓋的大都是領域的主題詞,及這些詞彙之間的基本語意關聯。在這一步我們是要識別領域的高質量詞彙、同義詞、縮寫詞,以及領域的常見情感詞。比如在政治領域,我們需要知道特朗普又被稱為川普,其英文簡稱為 Trump。
第四步是領域物體發現(或挖掘)。需要指出的是領域詞彙只是識別出領域中的重要短語和詞彙。但是這些短語未必是一個領域物體。從領域文字識別某個領域常見物體是理解領域文字和資料的關鍵一步。在物體識別後,還需對物體進行物體歸類。能否把物體歸到相應的類別(或者說將某個物體與領域類別或概念進行關聯),是物體概念化的基本標的,是理解物體的關鍵步驟。比如將特朗普歸類到政治人物、美國總統等類別,對於理解特朗普的含義具有重要意義。物體挖掘的另一個重要任務是物體連結,也就是將文本里的物體提及(Mention)連結到知識庫中的相應物體。物體連結是拓展物體理解,豐富物體語意表示的關鍵步驟。
第五步是關係發現。關係發現,或者知識庫中的關係實體填充,是整個領域知識圖譜構建的重要步驟。關係發現根據不同的問題模型又可以分為關係分類、關係抽取和開放關係抽取等不同變種。關係分類旨在將給定的物體對分類到某個已知關係;關係抽取旨在從文字中抽取某個物體對的具體關係;開放關係抽取(OpenIE)從文字中抽取出物體對之間的關係描述。也可以綜合使用這幾種模型與方法,比如根據開放關係抽取得到的關係描述將物體對分類到知識庫中的已知關係。
第六步是知識融合。因為知識抽取來源多樣,不同的來源得到的知識不盡相同,這就對知識融合提出了需求。知識融合需要完成物體對齊、屬性融合、值規範化。物體對齊是識別不同來源的同一物體。屬性融合是識別同一屬性的不同描述。不同來源的資料值通常有不同的格式、不同的單位或者不同的描述形式。比如日期有數十種表達方式,這些需要規範化到統一格式。
最後一步是質量控制。知識圖譜的質量是構建的核心問題。知識圖譜的質量可能存在幾個基本問題:缺漏、錯誤、陳舊。先談知識庫的缺漏問題。某種意義上,知識完備對於知識資源建設而言似乎是個偽命題,我們總能列舉出知識庫中缺漏的知識。知識缺漏對於自動化方法構建的知識庫而言尤為嚴重。但是即便如此,構建一個盡可能全的知識庫仍是任何一個知識工程的首要標的。
既然自動化構建無法做到完整,補全也就成為了提升知識庫質量的重要手段。補全可以是基於預定義規則(比如一個人出生地是中國,我們可以推斷其國籍也可能是中國),也可以從外部網際網路文字資料進行補充(比如很多百科圖譜沒有魯迅身高的資訊,需要從網際網路文字尋找答案進行補充)。
其次是糾錯。自動化知識獲取不可避免地會引入錯誤,這就需要糾錯。根據規則進行糾錯是基本手段,比如 A 的妻子是 B,但 B 的老公是 C,那麼根據妻子和老公是互逆屬性,我們知道這對事實可能有錯。知識圖譜的結構也可以提供一定的資訊幫助推斷錯誤關聯。比如在由概念和實體構成的 Taxonomy 中,理想情況下應該是個有向無環圖,如果其中存在環,那麼有可能存在錯誤關聯。
最後一個質量控制的重要問題是知識更新。更新是一個具有重大研究價值,卻未得到充分研究的問題。很多領域都有一定的知識積累。但問題的關鍵在於這些知識無法實時更新。比如電商的商品知識圖譜,往往內容陳舊,無法滿足使用者的實時消費需求(比如“戰狼同款飾品”這類與熱點電影相關的消費需求很難在現有知識庫中涵蓋)。
因此,電商領域的圖譜構建要從被動的供給側構建過渡到主動的消費側構建,要從管理者視角轉變成消費者視角。消費側的需求充分體現在搜尋日誌和購物籃中。面嚮日誌、購物籃的自動知識獲取將成為研究熱點。
經歷了上述步驟之後得到一個初步的領域知識圖譜。在實際應用中會得到不少反饋,這些反饋作為輸入進一步指導上述流程的完善,從而形成閉環。此外,除了上述自動化構建的閉環流程,還應充分考慮人工的幹預。人工補充很多時候是行之有效的方法。比如一旦發現部分知識缺漏或陳舊,可以透過特定的知識編輯工具實現知識的新增、編輯和修改。也可以利用眾包手段將很多知識獲取任務分發下去。如何利用眾包手段進行大規模知識獲取,是個十分有意思的問題,涉及到知識貢獻的激勵機制,我前幾年有個題為《未來人機區分》的報告,專門討論如何利用知識問答形式的驗證碼來做知識獲取,可以百度此文獲取更多資訊。
可以看出,整個領域知識圖譜的構建是個系統工程,流程複雜,內涵豐富,涉及到知識表示、自然語言處理、資料庫、資料挖掘、眾包等一系列技術。也正是這個原因使得知識圖譜落地對很多行業或者企業來講都是一個十分重要的舉措,甚至是戰略性舉措。

領域圖譜的評價標準是落地過程中常常被問及的問題。總體而言有三個方面的指標應該予以充分考慮。第一個是規模。前面已經指出,絕對完備的知識庫是不存在的,完備只能相對於一些封閉領域而言。因此,規模一般而言是個相對指標。
關於規模問題,在落地過程有兩個有意思的問題。一是,當前知識庫是否足以支撐實際應用,或者多大規模就夠了?這個問題沒有絕對答案。我給出的是看實際應用的反饋,也就是知識圖譜上線後的使用者滿意率。比如在利用知識圖譜支撐語意搜尋方面,多少查詢能被準確理解,這個比率是個重要的指標。當然查詢理解率不僅涉及知識圖譜的改寫率也關係到理解模型的準確率。因此,在實際評估中需要客觀對待查詢理解率,不能簡單地將查詢理解率直接等同於圖譜改寫率。
第二個指標是質量。當前 AI 系統努力避免的一個事實就是“Garbage-In-Garbage-Out”。喂給機器的是錯誤知識,就只會導致錯誤的應用結果。提升知識圖譜質量是知識圖譜構建的核心命題。
那麼知識圖譜質量又應該從哪些維度進行衡量呢?我想至少有幾個維度。一是、準確率。比如是否存在錯誤事實,錯誤事實所佔比例都是質量的直接反映。二是、知識的深度。比如很多知識庫只涵蓋人物這樣的大類,無法細化到作家、音樂家、運動員這些細分類目(fine-grained concepts)。三是、知識的粒度。粒度越細應用越靈活,應用時精讀越高。細化知識表示的粒度是領域知識圖譜的構建過程中的重要任務之一。
第三個方面是實時。絕對實時是不現實的,因而實時大都從知識的延時(latency)角度進行刻畫。短延時顯然是我們期望的。知識圖譜的更新是個複雜問題,不同的更新策略導致不同的延時。
一般而言,知識圖譜更新包括被動更新和主動更新兩種方式。實際應用中往往是兩種策略的結合。被動更新往往採取週期性更新策略,這種策略延時長,適用於大規模知識更新。主動更新,往往從需求側、消費側、應用側出發,主動觸發相關知識更新,適用於頭部或者高頻物體及知識的更新。關於知識庫更新的細節,感興趣的朋友可以參考知識工場微信公眾號文章《百科知識圖譜同步更新》。

領域知識圖譜如何儲存也是大家很關註的問題。由於知識圖譜本質上在表達關聯,天然地可以用圖加以建模,因而很多人想到用圖資料庫對領域知識圖譜加以儲存。圖資料庫的確是知識圖譜儲存選型的重要選擇,但是不是唯一選擇。傳統關係資料庫,近幾年充分發展的其他型別的 NoSQL 資料庫在很多場景下也是合理選擇。
那麼資料庫的選擇考慮的要素是什麼呢?有兩類重要的選型要素:圖譜的規模以及操作複雜度。從圖譜的規模角度來看,百萬、千萬的節點和關係規模(以及以下規模)的圖譜對於圖資料庫的需求並不強烈,圖資料庫的必要性在中等或者小規模知識圖譜上體現並不充分。但是如果圖譜規模在數億節點規模以上,圖資料庫就十分必要了。
從操作複雜性來看,圖譜上的操作越是複雜,圖資料庫的必要性越是明顯。圖譜上的全域性計算(比如平均最短路徑的計算),圖譜上的複雜遍歷,圖譜上的複雜子圖查詢等等都涉及圖上的多步遍歷。圖上的多步遍歷操作如果是在關係資料庫上實現需要多個聯結(Join)操作。多個聯結操作的最佳化一直以來是關係資料庫的難題。圖資料庫系統實現時針對多步遍歷做了大量最佳化,能夠實現高效圖遍歷操作。
除了上述因素之外,還應該充分考慮系統的易用性、普及性與成熟度。總體而言圖資料庫還是發展中的技術,對於複雜圖資料管理系統的最佳化也是隻有少部分專業人員才能從事的工作。在資料庫選型時需要充分考慮這些因素。我們實驗室在實現 CN-DBpedia(2000 萬物體、2.2 億關係)線上服務系統時先後採用了 Relational DB、Graph DB、MongoDB,最後出於綜合考慮選用的是 MongoDB,已經穩定運行了三年,累計提供 10 億多次 API 服務。

領域知識圖譜如何查詢?通常對於表達為 RDF 形式的知識圖譜,可以使用 SPARQL 查詢語言。SPARQL 語言針對 RDF 資料定義了大量的運算元,對於推理操作有著很好支撐,因而能夠適應領域中的複雜查詢與複雜推理。從應用角度來看,也可以將知識圖譜僅僅表達為無型別的三元組。對於這種輕量級的表示,關係資料庫與傳統 NoSQL 資料庫也是較好選擇。
那麼此時,SQL 陳述句就是比較好的選擇。SQL 十分成熟,語法簡單,使用者眾多且有著幾十年的成功應用基礎。很多領域圖譜上的查詢是相對簡單的,以單步或者兩到三步遍歷居多。此時,SQL 完全能夠勝任。但是不排除有一些特定場景,特別是公共安全、風控管理等領域,通常需要進行複雜關聯分析,需要較長路徑的遍歷,需要開展複雜子圖挖掘,此時 SQL 的表達能力就顯得相對較弱了。
未來的趨勢是直接利用自然語言進行知識圖譜資料訪問。但是總體而言這還只是個比較熱門的研究主題,離成熟還有一定距離。其根本困難在於自然語言的複雜性,在於自然語言自動化轉成形式語言的巨大複雜性。但這顯然是有著巨大商業價值的問題。資料(知識)訪問方法的獃板是制約資料(知識)價值發揮的重大瓶頸。一旦突破這一瓶頸,資料與知識的使用將從傳統的被動式定製獲取變成主動式按需獲取,傳統管理資訊系統以及知識管理將面臨全新機遇。

領域知識圖譜的應用落腳點無外乎搜尋、推薦、問答、解釋與決策。對於這幾個應用我在《知識圖譜與認知智慧》一文中有詳細論述,在此不再贅述。這裡補充回答幾個問題。第一、知識圖譜支撐下的應用與沒有知識圖譜特別是與基於機器學習的方案相比有何優勢?這是很多應用單位會提出的問題。
首先,從宏觀層面來講,透過領域知識圖譜對於領域知識進行表達與沉澱,使得機器能夠具備領域資料認知能力。這種能力使得推理和解釋成為可能。推理和解釋是當前的機器學習(特別是深度學習)還難以有效解決的問題。
其次,從具體任務來看,知識圖譜能顯著提升一些具體任務的效果。知識圖譜支撐下的搜尋相對於傳統搜尋,能夠顯著提高召回率,也就是能夠解決“搜的到”的問題;知識圖譜支撐下的推薦相對於傳統推薦,能夠顯著提高推薦的個性化,也就是能夠解決“推得準”的問題;知識圖譜支撐下的推薦相對於其他問答方式,能夠顯著提高問答的召回率,特別是需要推理才能回答的問題。知識圖譜支撐下的決策分析相對於傳統決策,能夠提供決策的可解釋依據,能夠為決策提供背景知識支援。解釋是知識圖譜的天然使命,因為人只能理解符號知識,人是解釋的物件。
另一個更為深刻的問題是相對於機器學習,特別是深度學習,符號化知識對於機器智慧是否必要?一些機器學習專家認為,機器智慧只需要數值表示就可以了,所謂知識也無外乎就是深度神經網路中足夠抽象層次上的分散式表示,體現為相應層次上的網路結構與引數。符號知識對於機器智慧是個偽命題,知識表達與沉澱對於機器智慧也就無從談起。深度學習頂級專家Hinton也有類似觀點。
一定程度上,我贊同這個觀念。但問題在於,雖然我們身處在大資料時代,但是當前的資料還不足以讓機器習得人類所具有的高度抽象知識。我們現在的大資料大部分還只是應用場景下產生的直接資料,缺乏產生這些資料的需求與動機的背景資料,缺乏能夠解釋資料之所以如此的因果鏈條資料。比如我們都知道資料挖掘領域的啤酒尿布的例子,意思是說大部分買尿布的人也會同時買啤酒。可是我們從來都不知道為什麼。事實上很可能是產婦行動不便,讓爸爸來買尿布,一個家庭有了新生兒之後,初為人父的爸爸們或多或少比較緊張興奮,因而順帶購買啤酒以緩解壓力。
我們現在的資料採集還無法延伸到能夠理解統計規律背後的因果鏈條的地步。還有很多資料背後是由常識支撐的。比如今年夏天冷飲銷售量增長,是由於天氣炎熱,而天氣炎熱,人們自然會飲用冷飲。這些知識是我們人人都知道的,但是機器無法知道。常識缺失使得機器無法重建完整的資料關聯分析鏈條。所以,大資料時代的“資料饑荒”是機器學習無法習得人類水準的高層抽象知識的重要原因之一。
那麼有人也許會爭論說,既然“資料饑荒”是根本原因,那麼有可能透過增強資料採集廣度與力度來消弭這一問題。我個人認為很難。誠然隨著大資料日積月累,這一問題或許會得到一定程度上的緩解。 但是常識獲取的困難仍然會對這一問題的解決帶來巨大挑戰。因此,至少在當下一段時期內,充分利用符號知識,補齊資料驅動方法的短板應該是比較務實的思路。但是即便意識到這一點,在方法層面我們也仍然捉襟見肘。如何利用符號知識增強統計學習模型仍然是個具有挑戰性的問題。對於這一問題的具體論述可以參考《當知識圖譜“遇見”深度學習》一文。

領域知識圖譜落地有哪些最佳實踐呢?作為一個工程性學科,不斷總結其最佳實踐是非常有必要的。這裡根據我們落地的幾個專案分享幾個最佳實踐。
第一、應用引領。這個問題在知識圖譜專案週期時,已經強調了。明確應用出口對於圖譜的規劃是非常重要的。
第二、避難就簡。在當前階段,文字處理仍然面臨不少困難,落地困難重重。即便是一個簡單的中文分詞任務仍然需要大量的研究工作,比如“南京市長江大橋”分詞,可以是“南京市+長江大橋”,也可以是“南京市長+江大橋”。因此,在實際落地過程中,應該綜合考慮各條技術路徑的難度,優先考慮從結構化的資料中加以轉換,其次是半結構化資料(比如帶格式標記的各類文字,如XML、百科文字等等),最後才是無結構的自然語言文字。
事實上,如果能夠綜合考慮各類技術路徑,融合各類資料源,採取一些巧妙的策略可以顯著提升非結構化文字抽取的有效性。比如利用結構化資料與非結構文字進行比對,獲取很多高質量的關係描述就是一個非常有效的策略。
第三、避免從零開始。很多行業或者企業在建設知識圖譜專案時,或多或少已經存在很多知識資源,比如領域本體、敘詞表等等,網際網路上的公開來源也存在不少相關的百科資源,通用百科圖譜已經涵蓋了某個領域大量的物體。
充分利用這些資源,提高領域知識圖譜構建的起點,是知識圖譜專案成功落地的一個關鍵因素之一。已經存在的這些知識資源很多是消耗了巨大人工成本經過多年持續積累而得到的,充分利用這些知識資源對於領域知識圖譜的構建與完善具有重要意義。知識資源建設有個很有意思的現象,那就是讓人從無到有的貢獻一條知識的代價要顯著高於讓人在一個不那麼完善的知識庫上進行完善的代價。因此,盡可能復用是知識資源建設的重要策略之一。
最後一條是跨領域遷移。其思路很簡單,如果我們為中國移動做了個領域知識圖譜,那麼為中國電信建設圖譜,是不需要從零開始的。相近領域的知識是可以復用的。這個原則也意味著知識圖譜落地過程中,將來會湧現出一大批面向特定行業知識圖譜解決方案的企業。

領域知識圖譜還存在哪些挑戰?總體上在知識表示、獲取和應用等各層面均存在很多挑戰。在知識表示層面,越來越多的領域應用不僅僅需要關聯事實這種簡單知識表示,還要表達包括邏輯規則、決策過程在內的複雜知識;需要同時表達靜態知識和動態知識。單單知識圖譜已經不足以解決領域的很多實際問題。如何去增強知識圖譜的語意表達能力,如何綜合使用多種知識表示來解決實際應用中的複雜問題是非常重要的研究課題。
第二,在知識獲取方面,領域知識圖譜一般樣本很小,如果需要構建抽取模型,那就需要基於小樣本構建有效的模型。目前基於小樣本的機器學習仍然面臨巨大挑戰。解決這一問題的思路之一就是利用知識引導機器學習模型的學習過程。具體實現手段已經有不少團隊在開展相關的探索工作,比如利用知識增強樣本、利用知識構建標的函式的正則項以及利用知識構建最佳化標的的約束等等。總體而言,這仍然是個開放問題需要巨大的研究投入。
第三,知識的深度應用。如何將領域知識圖譜有效應用於各類應用場景,特別是推薦、搜尋、問答之外的應用,包括解釋、推理、決策等方面的應用仍然面臨巨大挑戰,仍然存在很多開放性問題。更多有關知識圖譜的開放性挑戰可以參考知識工場微信公眾號《知識圖譜研究回顧與展望》一文。

點選以下標題檢視更多相關文章:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 獲取最新論文推薦