點選▲關註 “資料和雲” 給公眾號標星置頂
更多精彩 第一時間直達
導讀:雲端計算時代的服務端網路環境越來越複雜。不但要考慮實際的物理網路,也要考慮到SDN/安全等技術的影響。理論上說,網路對應用開發無感知,然而有時候也並非如此。本文作者記錄了一種阿裡雲上Redis/MySQL的靈異現象,並且記錄了問題原因,給出瞭解決方案。
引子:Redis client library 連線 Redis server 超時
差不多一兩年前,在阿裡雲上遇到一個奇怪的 Redis 連線問題,每隔十來分鐘,服務裡的 Redis client 庫就報告連線 Redis server 超時,當時花了很大功夫,發現是阿裡雲會斷開長時間閑置的 TCP 連線,不給兩頭髮 FIN or RST 包,而當時我們的 Redis server 沒有開啟 tcp_keepalive 選項,於是 Redis server 側那個連線還存在於 Linux conntrack table 裡,而 Redis client 側由於連線池重用連線進行 get、set 發現連線壞掉就關閉了,所以 client 側的對應 local port 回收了,當接下來 Redis 重用這個 local port 向 Redis server 發起連線時,由於 Redis server 側的 conntrack table 裡 四元組對應狀態是 ESTABLISHED,所以自然客戶端發來的 TCP SYN packet 被丟棄,Redis client 看到的現象就是連線超時。
解決這個問題很簡單,開啟 Redis server 的 tcp_keepalive 選項就行。 然而當時沒想到,這個問題深層次的原因影響很重大,後果很嚴重!
孽債:”SELECT 1″ 觸發的 jdbc4.CommunicationsException
最近生產環境的 Java 服務幾乎每分鐘都報告類似下麵這種錯誤:

由於有之前調查 Redis 連線被阿裡雲異常中斷的先例,所以懷疑是類似問題,花了大量時間比對客戶端和服務端的 conntrack table,然而並沒有引子中描述的問題,然後又去比對多個 MySQL 伺服器的 sysctl 設定,研究 iptables TRACE,研究 tcpdump 抓到的報文,試驗 tw_reuse, tw_recyle 等引數,調整 Aliyun 負載均衡器後面掛載的 MySQL 伺服器個數,都沒效果, 反而意外發現一個**新問題**,在用如下命令不經過阿裡雲 SLB 直接連線資料庫時,有的資料庫可以在 600s 時傳回,有的則客戶端一直掛著,半個多小時了都退不出來,按 ctrl-c 中斷都不行。

當時檢查了一個正常的資料庫和一個不正常的資料庫,發現兩者的 wait_timeout 和 interactive_timeout 都是 600s,思索良苦,沒明白怎麼回事,然後偶然發現另外一個資料庫的 wait_timeout=60s,卻一下子明白了原始的 “select 1” 問題怎麼回事。
我們的服務使用了 Hikari JDBC 連線池[1],它的 idleTimeout 預設是 600s, maxLifetime 預設是 1800s,前者表示 idle JDBC connection 數量超過 minimumIdle 數目並且閑置時間超過 idleTimeout 則關閉此 idle connection,後者表示連線池裡的 connection 其生存時間不能超過 maxLifetime,到點了會被關掉。
在發現 “select 1” 問題後,我們以為是這倆引數比資料庫的 wait_timeout=600s 大的緣故,所以把這兩個引數縮小了,idleTimeout=570s, maxLifetime=585s,並且設定了 minimumIdle=5。但這兩個時間設定依然大於其中一個資料庫失誤設定的 wait_timeout=60s,所以閑置連線在 60s 後被 MySQL server 主動關閉,而 JDBC 並沒有什麼事件觸發回呼機制去關閉 JDBC connection,時間上也不夠 Hikari 觸發 idleTimeout 和 maxLifetime 清理邏輯,所以 Hikari 拿著這個“已經關閉”的連線,發了 “select 1” SQL 給伺服器檢查連線有效性,於是觸發了上面的異常。
解決辦法很簡單,把那個錯誤配置的資料庫裡 wait_timeout 從 60s 修正成 600s 就行了。 下麵繼續講述 “SELECT sleep(1000)” 會掛住退不出來的問題。
緣起:阿裡雲安全組與 TCP KeepAlive
最近看了一點佛教常識,對”諸法由因緣而起“的緣起論很是感慨,在調查 “SELECT sleep(1000)” 問題中,真實感受到了“由因緣而起” 的意思
首先解釋下,為什麼有的資料庫伺服器對 “SELECT sleep(1000)” 可以傳回,有的卻掛著退不出來。 其實 wait_timeout 和 interactive_timeout 兩個引數只對 “閑置” 的資料庫連線,也即沒有 SQL 正在執行的連線生效,對於 “SELECT sleep(1000)”,這是有一個正在執行的 SQL,其最大執行時間受 MySQL Server 的 max_execution_time 限制,這個引數在我司一般設定為 600s,這就是 “正常的資料庫” 在 600s 時 “SELECT sleep(1000)” 中斷執行而退出了。
但不走運的是(可以說又是個失誤配置 ),我們有的資料庫 max_execution_time 是 6000s,所以 “SELECT sleep(1000)” 在 MySQL server 服務端會在 1000s 時正常執行結束——但問題是,透過二分查詢以及 tcpdump、iptables TRACE,發現阿裡雲會”靜默“丟棄 >=910s idle TCP connection,不給客戶端、服務端傳送 FIN or RST 以強行斷掉連線,於是 MySQL server 在 1000s 結束時發給客戶端的 ACK+PSH TCP packet 到達不了客戶端,然後再過 wait_timeout=600s,MySQL server 就斷開了這個閑置連線——可憐的是,mysql client 這個命令列程式還一無所知,它很執著的等待 MySQL server 傳回,Linux 內核的 conntrack table 顯示這個連線一直是 ESTABLISHED,哪怕 MySQL server 端已經關閉對應的連線了,只是這個關閉動作的 FIN TCP packet 到不了客戶端!
下麵是 iptables TRACE 日誌對這個問題的實錘證明。
mysql 命令列所在機器的 iptables TRACE 日誌表明,mysql client 在 23:58:25 連線上了 mysql server,開始執行 SELECT sleep(1000),然後一直收不到伺服器訊息,最後在 00:41:20 的時候我手動 kill 了 mysql 客戶端命令列行程,mysql 客戶端給 mysql server 發 FIN 包但收不到響應(此時 mysql server 端早關閉連線了)。

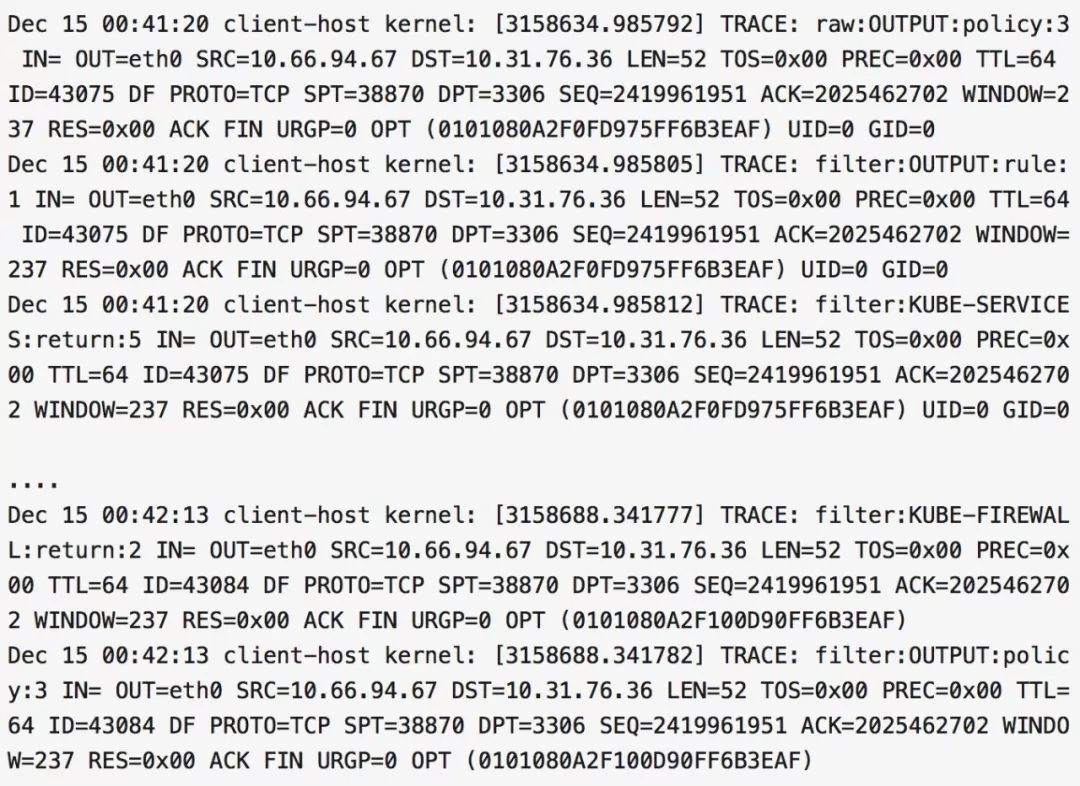
MySQL server 在 00:15:05 時執行 SELECT sleep(1000) 結束,給 mysql 客戶端回送結果,但 mysql 客戶端無響應(被阿裡雲丟包了,mysql 客戶端壓根收不到),在 00:25:05 時,由於 wait_timeout=600s,所以 MySQL server 給 mysql 客戶端發 FIN 包以斷開連線,自然,mysql 客戶端收不到,所以也沒有回應,結局是 MySQL server 一側的 Linux 核心反正自行關閉 TCP 連線了,mysql client 一側的 Linux 核心還在傻乎乎的在 conntrack table 維持著 ESTABLISHED 狀態的 TCP 連線,mysql client 命令列還在傻乎乎的 recv() 等著服務端傳回或者關閉連結。

Ok,現在知道是阿裡雲對 >= 910s 沒有發生 TCP packet 傳輸的虛擬機器之間直連閑置 TCP 連線會“靜默”丟包,那麼是任意虛擬機器之間嗎?是任意埠嗎?要求伺服器掛到負載均衡器後面嗎?要求對應埠的併發連線到一定數目嗎?
在阿裡雲提交工單詢問後,沒得到什麼有價值資訊,在經過艱苦卓絕的試驗後——每一次試驗要等近二十分鐘啊——終於功夫不負有心人,我發現一個穩定復現問題的規律了:
-
兩臺虛擬機器分別處於不同安全組,沒有共同安全組;
-
服務端的安全組開放埠 P 允許客戶端的安全組連線,客戶端不開放埠給服務端(按照一般有狀態防火牆的配置規則,都是隻開服務端埠,不用開客戶端埠);
-
客戶端和服務端連線上後,閑置 >= 910s,不傳輸任何資料,也不傳輸有 keep alive 用途的 ack 包;
-
然後服務端在此長連線上發給客戶端的 TCP 包會在網路上丟棄,到不了客戶端;
-
但如果客戶端此時給服務端發點資料,那麼會重新“啟用”這條長連結,但此時還是單工狀態,客戶端能給服務端發包,服務端的包還到不了客戶端(大概是在服務端 OS 核心裡重試中);
-
啟用後,服務端再給客戶端發資料時,之前傳送不出去的資料(如果還在核心裡的 TCP/IP 協議棧重試中),加上新發的資料,會一起到達客戶端,此後這條長連線進入正常的雙工工作狀態;
下圖是用 nc 試驗的結果。


在跟網友討論後,認識到這應該是阿裡雲安全組基於“集中式防火牆”實現導致的,因為集中式防火牆處於網路中心樞紐,它要應付海量連線,因此其記憶體裡的 conntrack table 需要比較短的 idle timeout(目前是 910s),以把長時間沒活躍的 conntrack record 清理掉節約記憶體,所以上面問題的根源就清晰了:
-
client 連線 server,安全組(其實是防火牆)發現規則允許,於是加入一個記錄到 conntrack table;
-
client 和 server 到了 910s 還沒資料往來,所以安全組把 conntrack 裡那條記錄去掉了;
-
server 在 910s 之後給 client 發資料,資料包到了安全組那裡,它一看 conntrack table 裡沒記錄,而 client 側安全組又不允許這個埠的包透過,所以丟包了,於是 server -> client 不通;
-
client 在同一個長連線上給 server 發點資料,安全組一看規則允許,於是加入 conntrack table 裡;
-
server 重試的資料包,或者新資料包,透過安全組時,由於已經有 conntrack record 了,所以放行,於是能到達客戶端了。
原因知道了,怎麼繞過這個問題呢?阿裡雲給了我兩個無法接受的 workaround:
-
把 server、client 放進同一個安全組;
-
修改 client 所在安全組,開放所有埠給 server 所在安全組;
再琢磨下,透過 netstat -o 發現我們的 Java 服務使用的 Jedis 庫和 mysql JDBC 庫都對 socket 檔案控制代碼開啟了 SO_KEEPALIVE 選項[2]:

而 MySQL server 也對其開啟的 socket 檔案控制代碼開啟了 SO_KEEPALIVE 選項,所以我只用修改下服務端和客戶端至少其中一側的對應 sysctl 選項即可,下麵是我司服務端的預設配置,表示 TCP 連線閑置 1800s 後,每隔 30s 給對方發一個 ACK 包,最多發 3 次,如果在此期間對方回覆了,則計時器重置,再等 1800s 閑置條件,如果發了 3 次後對方沒反應,那麼會給對端發 RST 包同時關閉本地的 socket 檔案控制代碼,也即關閉這條長連線。

由於阿裡雲跨安全組的 910s idle timeout 限制,所以需要把 net.ipv4.tcp_keepalive_time 設定成小於 910s,比如 300s。
預設的 tcp_keepalive_time 特別大,這也解釋了為什麼當初 Redis client 設定了 SO_KEEPALIVE 選項後還是被阿裡雲靜默斷開。
如果某些網路庫封裝之後沒有提供 setsockopt() 呼叫的機會,那麼需要用 LD_PRELOAD 之類的黑科技強行設定了,只有開啟了 socket 檔案控制代碼的 SO_KEEPALIVE 選項,上面三個 sysctl 才對這個 socket 檔案控制代碼生效,當然,程式碼裡可以用 setsockopt() 函式進一步設定 keep_alive_intvl 和 keepalive_probes,不用 Linux 內核的全域性預設設定。
最後,除了 Java 家對 SO_KEEPALIVE 處理的很好,利用 netstat -o 檢查得知,對門的 NodeJS 家,其著名 Redis client library 開了 SO_KEEPALIVE 但其著名 mysql client library 並沒有開,而 Golang 家則嚴謹多了,兩個庫都開了 SO_KEEPALIVE。 為什麼引子裡說這個問題很嚴重呢?因為但凡服務端處理的慢點,比如 OLAP 場景,不經過阿裡雲 SLB 直連服務端在 910s 之內沒傳回資料的話,就有可能沒機會傳回資料給客戶端了啊,這個問題查死人有沒有! 你可能問我為啥不透過阿裡雲 SLB 中轉,SLB 不會靜默丟包啊——但它的 idle timeout 上限是 900s 啊!!!
頭圖 Photo credit: “No Bugs” Hare
文中連結:
[1] https://github.com/brettwooldridge/HikariCP
[2] http://www.tldp.org/HOWTO/TCP-Keepalive-HOWTO/usingkeepalive.html
轉載自:高可用架構

