點選上方“Java技術驛站”,選擇“置頂公眾號”。
有內涵、有價值的文章第一時間送達!
在sharding-jdbc原始碼之group by結果合併(1)中主要分析了sharding-jdbc如何在GroupByStreamResultSetMerger和GroupByMemoryResultSetMerger中選擇,並分析了GroupByStreamResultSetMerger的實現;接下來分析GroupByMemoryResultSetMerger的實現原理;
透過sharding-jdbc原始碼之group by結果合併(1)的分析可知,如果要走GroupByMemoryResultSetMerger,那麼需要這樣的SQL: SELECT o.status,count(o.user_id)count_user_id FROM t_order o whereo.user_id=10groupbyo.status order bycount_user_id asc,即group by和order by的欄位不一樣;接下來的分析都是基於這條SQL;
ExecutorEngine.build()方法中透過 returnnewGroupByMemoryResultSetMerger(columnLabelIndexMap,resultSets,selectStatement);呼叫GroupByMemoryResultSetMerger,GroupByMemoryResultSetMerger的構造方法原始碼如下:
public GroupByMemoryResultSetMerger(
final Map<String, Integer> labelAndIndexMap, final List<ResultSet> resultSets, final SelectStatement selectStatement) throws SQLException {
// labelAndIndexMap就是select結果列與位置索引的map,例如{count_user_id:2, status:1}
super(labelAndIndexMap);
// select查詢陳述句
this.selectStatement = selectStatement;
// resultSets就是併發在多個實際表執行傳回的結果集合,在多少個實際表上執行,resultSets的size就有多大;
memoryResultSetRows = init(resultSets);
}
在實際表torder0和torder1上執行SQL傳回的結果如下:
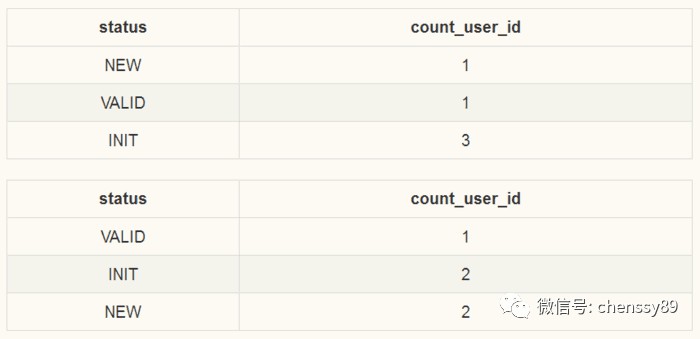
torder0和torder1結果.png
知道實際表的傳回結果後,後面的分析更容易理解;假定這些傳回結果用json表示為:{[{“status”:”NEW”, “countuserid”:1},{“status”:”VALID”, “countuserid”:1},{“status”:INIT, “countuserid”:2}],[{“status”:”VALID”, “countuserid”:1},{“status”:”INIT”, “countuserid”:1},{“status”:””NEW, “countuserid”:3}]}
init()方法原始碼如下:
private Iterator<MemoryResultSetRow> init(final List<ResultSet> resultSets) throws SQLException {
Map<GroupByValue, MemoryResultSetRow> dataMap = new HashMap<>(1024);
Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap = new HashMap<>(1024);
// 遍歷多個實際表執行傳回的結果集合中所有的結果,即2個實際表每個實際表3條結果,總計6條結果
for (ResultSet each : resultSets) {
while (each.next()) {
// each就是遍歷過程中的一條結果,selectStatement.getGroupByItems()即group by項,即status,將結果和group by項組成一個GroupByValue物件--實際是從ResultSet中取出group by項的值,例如NEW,VALID,INIT等
GroupByValue groupByValue = new GroupByValue(each, selectStatement.getGroupByItems());
// initForFirstGroupByValue()分析如下
initForFirstGroupByValue(each, groupByValue, dataMap, aggregationMap);
aggregate(each, groupByValue, aggregationMap);
}
}
// 將aggregationMap中的聚合計算結果封裝到dataMap中
setAggregationValueToMemoryRow(dataMap, aggregationMap);
// 將結果轉換成List形式
List<MemoryResultSetRow> result = getMemoryResultSetRows(dataMap);
if (!result.isEmpty()) {
// 如果有結果,再將currentResultSetRow置為List的第一個元素
setCurrentResultSetRow(result.get(0));
}
// 傳回List的迭代器,後面的取結果,實際上就是迭代這個集合;
return result.iterator();
}
initForFirstGroupByValue()原始碼如下:
private void initForFirstGroupByValue(final ResultSet resultSet, final GroupByValue groupByValue, final Map<GroupByValue, MemoryResultSetRow> dataMap,
final Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap) throws SQLException {
// groupByValue如果是第一次出現,那麼在dataMap中初始化一條資料,key就是groupByValue,例如NEW;value就是new MemoryResultSetRow(resultSet),即將ResultSet中的結果取出來封裝到MemoryResultSetRow中,MemoryResultSetRow實際就一個屬性Object[] data,那麼data值就是這樣的["NEW", 1]
if (!dataMap.containsKey(groupByValue)) {
dataMap.put(groupByValue, new MemoryResultSetRow(resultSet));
}
// groupByValue如果是第一次出現,那麼在aggregationMap中初始化一條資料,key就是groupByValue,例如NEW;value又是一個map,這個map的key就是select中有聚合計算的列,例如count(user_id),即count_user_id;value就是AggregationUnit的實現,count聚合計算的實現是AccumulationAggregationUnit
if (!aggregationMap.containsKey(groupByValue)) {
Map<AggregationSelectItem, AggregationUnit> map = Maps.toMap(selectStatement.getAggregationSelectItems(), new Function<AggregationSelectItem, AggregationUnit>() {
@Override
public AggregationUnit apply(final AggregationSelectItem input) {
// 根據聚合計算型別得到AggregationUnit的實現
return AggregationUnitFactory.create(input.getType());
}
});
aggregationMap.put(groupByValue, map);
}
}
該方法都是為了接下來的聚合計算做準備工作;
aggregate()原始碼如下–即在記憶體中將多個實際表中傳回的結果進行聚合:
private void aggregate(final ResultSet resultSet, final GroupByValue groupByValue, final Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap) throws SQLException {
// 遍歷select中所有的聚合型別,例如COUNT(o.user_id)
for (AggregationSelectItem each : selectStatement.getAggregationSelectItems()) {
List<Comparable>> values = new ArrayList<>(2);
if (each.getDerivedAggregationSelectItems().isEmpty()) {
values.add(getAggregationValue(resultSet, each));
} else {
for (AggregationSelectItem derived : each.getDerivedAggregationSelectItems()) {
values.add(getAggregationValue(resultSet, derived));
}
}
// 透過AggregationUnit實現類即AccumulationAggregationUnit進行聚合,實際上就是聚合本次遍歷到的ResultSet,聚合的臨時結果就在AccumulationAggregationUnit的屬性result中(AccumulationAggregationUnit聚合的本質就是累加)
aggregationMap.get(groupByValue).get(each).merge(values);
}
}
經過 for(ResultSeteach :resultSets){while(each.next()){...遍歷所有結果並聚合計算後,aggregationMap這個map中已經聚合計算完後的結果,如下所示:
{
"VALID": {
"COUNT(user_id)": 2
},
"INIT": {
"COUNT(user_id)": 5
},
"NEW": {
"COUNT(user_id)": 3
}
}
再將aggregationMap中的結果封裝到 Map<GroupByValue,MemoryResultSetRow>dataMap這個map中,結果形式如下所示:
{
"VALID": ["VALID", 2],
"INIT": ["INIT", 5],
"NEW": ["NEW", 3]
}
MemoryResultSetRow的本質就是一個
Object[]data,所以其值是[“VALID”, 2],[“INIT”, 5]這種形式
將結果轉成 List<MemoryResultSetRow>,並且排序–如果有order by,那麼根據order by的值進行排序,否則根據group by的值排序:
private List<MemoryResultSetRow> getMemoryResultSetRows(final Map<GroupByValue, MemoryResultSetRow> dataMap) {
List<MemoryResultSetRow> result = new ArrayList<>(dataMap.values());
Collections.sort(result, new GroupByRowComparator(selectStatement));
return result;
}
@RequiredArgsConstructor
public final class GroupByRowComparator implements Comparator<MemoryResultSetRow> {
private final SelectStatement selectStatement;
@Override
public int compare(final MemoryResultSetRow o1, final MemoryResultSetRow o2) {
if (!selectStatement.getOrderByItems().isEmpty()) {
return compare(o1, o2, selectStatement.getOrderByItems());
}
return compare(o1, o2, selectStatement.getGroupByItems());
}
...
}
到這裡,GroupByMemoryResultSetMerger即記憶體GROUP聚合計算已經分析完成,依舊透過執行過程圖解加深對GroupByMemoryResultSetMerger的理解,執行過程圖如下圖所示:

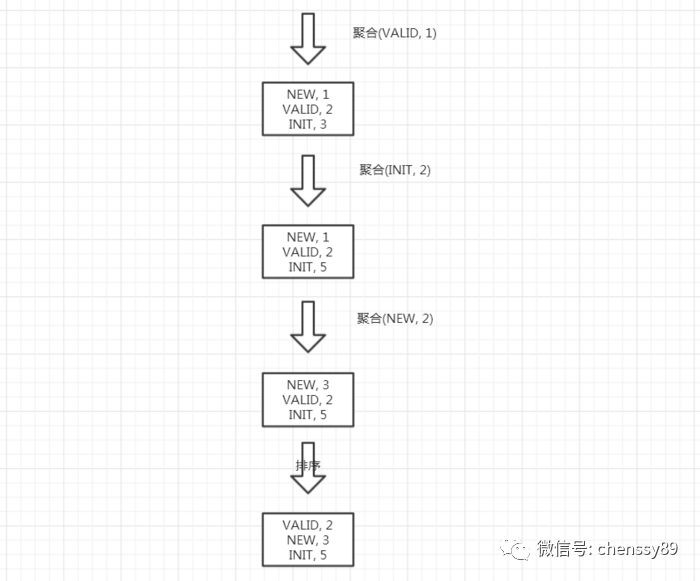
總結
正如GroupByMemoryResultSetMerger的名字一樣,其實現原理是把所有結果載入到記憶體中,在記憶體中進行計算,而GroupByMemoryResultSetMerger是流式計算方法,並不需要載入所有實際表傳回的結果到記憶體中。這樣的話,如果SQL傳回的總結果數比較多,GroupByMemoryResultSetMerger的處理方式就可能會撐爆記憶體;這個是使用sharding-jdbc一個非常需要註意的地方;
END

