概述:
Linux的物理記憶體管理採用了以頁為單位的buddy system(夥伴系統),但是很多情況下,核心僅僅需要一個較小的物件空間,而且這些小塊的空間對於不同物件又是變化的、不可預測的,所以需要一種類似使用者空間堆記憶體的管理機制(malloc/free)。然而核心對物件的管理又有一定的特殊性,有些物件的訪問非常頻繁,需要採用緩衝機制;物件的組織需要考慮硬體cache的影響;需要考慮多處理器以及NUMA架構的影響。90年代初期,在Solaris 2.4作業系統中,採用了一種稱為“slab”(原意是大塊的混凝土)的緩衝區分配和管理方法,在相當程度上滿足了內核的特殊需求。
多年以來,SLAB成為linux kernel物件緩衝區管理的主流演演算法,甚至長時間沒有人願意去修改,因為它實在是非常複雜,而且在大多數情況下,它的工作完成的相當不錯。但是,隨著大規模多處理器系統和 NUMA系統的廣泛應用,SLAB 分配器逐漸暴露出自身的嚴重不足:
1). 快取佇列管理複雜;
2). 管理資料儲存開銷大;
3). 對NUMA支援複雜;
4). 除錯調優困難;
5). 摒棄了效果不太明顯的slab著色機制;
針對這些SLAB不足,核心開發人員Christoph Lameter在Linux核心2.6.22版本中引入一種新的解決方案:SLUB分配器。SLUB分配器特點是簡化設計理念,同時保留SLAB分配器的基本思想:每個緩衝區由多個小的slab 組成,每個 slab 包含固定數目的物件。SLUB分配器簡化kmem_cache,slab等相關的管理資料結構,摒棄了SLAB 分配器中眾多的佇列概念,並針對多處理器、NUMA系統進行最佳化,從而提高了效能和可擴充套件性並降低了記憶體的浪費。為了保證核心其它模組能夠無縫遷移到SLUB分配器,SLUB還保留了原有SLAB分配器所有的介面API函式。
(註:本文原始碼分析基於linux-4.1.x)
整體資料結構關係如下圖所示:

1 SLUB分配器的初始化
SLUB初始化有兩個重要的工作:第一,建立用於申請struct kmem_cache和struct kmem_cache_node的kmem_cache;第二,建立用於常規kmalloc的kmem_cache。
1.1 申請kmem_cache的kmem_cache
第一個工作涉及到一個“先有雞還是先有蛋”的問題,因為建立kmem_cache需要從kmem_cache的緩衝區申請,而這時候還沒有建立kmem_cache的緩衝區。kernel的解決辦法是先用兩個靜態變數boot_kmem_cache和boot_kmem_cache_node來儲存struct kmem_cach和struct kmem_cache_node緩衝區管理資料,以兩個靜態變數為基礎申請大小為struct kmem_cache和struct kmem_cache_node物件大小的slub緩衝區,隨後再從這些緩衝區中分別申請兩個kmem_cache,然後把boot_kmem_cache和boot_kmem_cache_node中的內容複製到新申請的物件中,從而完成了struct kmem_cache和struct kmem_cache_node管理結構的bootstrap(自引導)。
- void __init kmem_cache_init(void)
- {
- //宣告靜態變數,儲存臨時kmem_cache管理結構
- static __initdata struct kmem_cache boot_kmem_cache,
- boot_kmem_cache_node;
- •••
- kmem_cache_node =&boot_kmem_cache_node;
- kmem_cache =&boot_kmem_cache;
- //申請slub緩衝區,管理資料放在臨時結構中
- create_boot_cache(kmem_cache_node,“kmem_cache_node”,
- sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN);
- create_boot_cache(kmem_cache,“kmem_cache”,
- offsetof(struct kmem_cache, node)+
- nr_node_ids *sizeof(struct kmem_cache_node *),
- SLAB_HWCACHE_ALIGN);
- //從剛才掛在臨時結構的緩衝區中申請kmem_cache的kmem_cache,並將管理資料複製到新申請的記憶體中
- kmem_cache = bootstrap(&boot_kmem_cache);
- //從剛才掛在臨時結構的緩衝區中申請kmem_cache_node的kmem_cache,並將管理資料複製到新申請的記憶體中
- kmem_cache_node = bootstrap(&boot_kmem_cache_node);
- •••
- }
1.2 建立kmalloc常規快取
原則上系統會為每個2次冪大小的記憶體塊申請一個快取,但是記憶體塊過小時,會產生很多碎片浪費,所以系統為96B和192B也各自建立了一個快取。於是利用了一個size_index陣列來幫助確定小於192B的記憶體塊使用哪個快取
- void __init create_kmalloc_caches(unsignedlong flags)
- {
- •••
- /*使用SLUB時KMALLOC_SHIFT_LOW=3,KMALLOC_SHIFT_HIGH=13
- 也就是說使用kmalloc能夠申請的最小記憶體是8B,最大記憶體是8KB
- 申請記憶體是向上對其2的n次冪,建立對應大小快取儲存在kmalloc_caches [n]*/
- for(i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++){
- if(!kmalloc_caches[i]){
- kmalloc_caches[i]= create_kmalloc_cache(NULL,
- 1<< i, flags);
- }
- /*
- * Caches that are not of the two-to-the-power-of size.
- * These have to be created immediately after the
- * earlier power of two caches
- */
- /*有兩個例外,大小為64~96B和128B~192B,單獨建立了兩個快取
- 儲存在kmalloc_caches [1]和kmalloc_caches [2]*/
- if(KMALLOC_MIN_SIZE <=32&&!kmalloc_caches[1]&& i ==6)
- kmalloc_caches[1]= create_kmalloc_cache(NULL,96, flags);
- if(KMALLOC_MIN_SIZE <=64&&!kmalloc_caches[2]&& i ==7)
- kmalloc_caches[2]= create_kmalloc_cache(NULL,192, flags);
- }
- •••
- }
2 快取的建立與銷毀
2.1 快取的建立
建立快取透過介面kmem_cache_create進行,在建立新的快取以前,嘗試找到可以合併的快取,合併條件包括對物件大小以及快取屬性的判斷,如果可以合併則直接傳回已存在的kmem_cache,並建立一個kobj連結指向同一個節點。
建立新的快取主要是申請管理結構暫用的空間,並初始化,這些管理結構包括kmem_cache、kmem_cache_nodes、kmem_cache_cpu。同時在sysfs建立kobject節點。最後把kmem_cache加入到全域性cahce連結串列slab_caches中。

2.2 快取的銷毀
銷毀過程比建立過程簡單的多,主要工作是釋放partial佇列所有page,釋放kmem_cache_cpu,釋放每個node的kmem_cache_node,最後釋放kmem_cache本身。

3 申請物件
物件是SLUB分配器中可分配的記憶體單元,與SLAB相比,SLUB物件的組織非常簡潔,申請過程更加高效。SLUB沒有任何管理區結構來管理物件,而是將物件之間的關聯嵌入在物件本身的記憶體中,因為申請者並不關心物件在分配之前記憶體的內容是什麼。而且各個SLUB之間的關聯,也利用page自身結構進行處理。
每個CPU都有一個slab作為本地高速快取,只要slab所在的node與申請者要求的node匹配,同時該slab還有空閑物件,則直接在cpu_slab中取出空閑物件,否則就進入慢速路徑。
每個物件記憶體的offset偏移位置都存放著下一個空閑物件,offset通常為0,也就是復用物件記憶體的第一個字來儲存下一個空閑物件的指標,當滿足條件(flags & (SLAB_DESTROY_BY_RCU | SLAB_POISON)) 或者有物件建構式時,offset不為0,每個物件的結構如下圖。
cpu_slab的freelist則儲存著當前第一個空閑物件的地址。

如果本地CPU快取沒有空閑物件,則申請新的slab;如果有空閑物件,但是記憶體node不相符,則deactive當前cpu_slab,再申請新的slab。
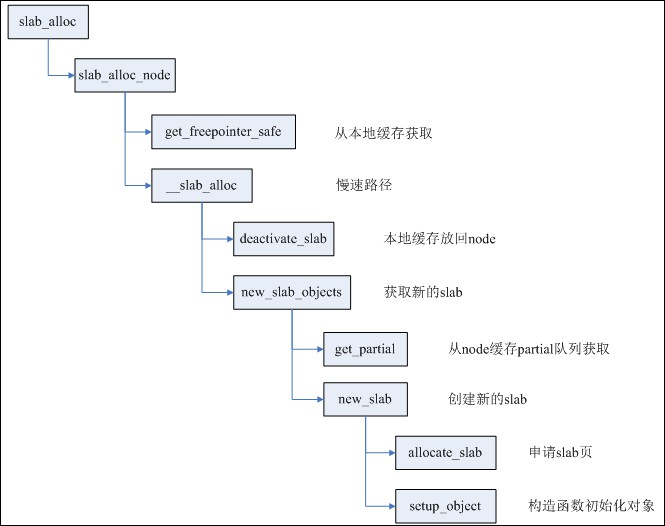
deactivate_slab主要進行兩步工作:
第一步,將cpu_slab的freelist全部釋放回page->freelist;
第二部,根據page(slab)的狀態進行不同操作,如果該slab有部分空閑物件,則將page移到kmem_cache_node的partial佇列;如果該slab全部空閑,則直接釋放該slab;如果該slab全部佔用,而且開啟了CONFIG_SLUB_DEBUG編譯選項,則將page移到full佇列。
page的狀態也從frozen改變為unfrozen。(frozen代表slab在cpu_slub,unfroze代表在partial佇列或者full佇列)。
申請新的slab有兩種情況,如果cpu_slab的partial佇列不為空,則取出佇列中下一個page作為新的cpu_slab,同時再次檢測記憶體node是否相符,還不相符則迴圈處理。
如果cpu_slab的partial佇列為空,則檢視本node的partial佇列是否為空,如果不空,則取出page;如果為空,則看一定距離範圍內其它node的partial佇列,如果還為空,則需要建立新slab。
建立新slab其實就是申請對應order的記憶體頁,用來放足夠數量的物件。值得註意的是其中order以及物件數量的確定,這兩者又是相互影響的。order和object數量同時存放在kmem_cache成員kmem_cache_order_objects中,低16位用於存放object數量,高位存放order。order與object數量的關係非常簡單:((PAGE_SIZE << order) – reserved) / size。
下麵重點看calculate_order這個函式
- staticinlineint calculate_order(int size,int reserved)
- {
- •••
- //嘗試找到order與object數量的最佳配合方案
- //期望的效果就是剩餘的碎片最小
- min_objects = slub_min_objects;
- if(!min_objects)
- min_objects =4*(fls(nr_cpu_ids)+1);
- max_objects = order_objects(slub_max_order, size, reserved);
- min_objects = min(min_objects, max_objects);
- //fraction是碎片因子,需要滿足的條件是碎片部分乘以fraction小於slab大小
- // (slab_size – reserved) % size <= slab_size / fraction
- while(min_objects >1){
- fraction =16;
- while(fraction >=4){
- order = slab_order(size, min_objects,
- slub_max_order, fraction, reserved);
- if(order <= slub_max_order)
- return order;
- //放寬條件,容忍的碎片大小增倍
- fraction /=2;
- }
- min_objects–;
- }
- //嘗試一個slab只包含一個物件
- order = slab_order(size,1, slub_max_order,1, reserved);
- if(order <= slub_max_order)
- return order;
- //使用MAX_ORDER且一個slab只含一個物件
- order = slab_order(size,1, MAX_ORDER,1, reserved);
- if(order < MAX_ORDER)
- return order;
- return–ENOSYS;
- }
4 釋放物件
從上面申請物件的流程也可以看出,釋放的object有幾個去處:
1)cpu本地快取slab,也就是cpu_slab;
2)放回object所在的page(也就是slab)中;另外要處理所在的slab:
2.1)如果放回之後,slab完全為空,則直接銷毀該slab;
2.2)如果放回之前,slab為滿,則判斷slab是否已被凍結;如果已凍結,則不需要做其他事;如果未凍結,則將其凍結,放入cpu_slab的partial佇列;如果cpu_slab partial佇列過多,則將佇列中所有slab一次性解凍到各自node的partial佇列中。
值得註意的是cpu partial佇列的功能是個可選項,依賴於核心選項CONFIG_SLUB_CPU_PARTIAL,如果沒有開啟,則不使用cpu partial佇列,直接使用各個node的partial佇列。
