51 信用卡的技術架構是基於 Spring Cloud 所打造的微服務體系,隨著業務的飛速發展,不斷增多的微服務以及指標給監控平臺帶來了極大的挑戰。監控團隊在開源vs自研,靈活vs穩定等問題上需要不斷做出權衡,以應對飛速發展的需求。本文會分享 51 信用卡在微服務下的白盒監控思考,以及如何將時下社群流行的 Spring Cloud、Kubernetes、Prometheus 等開源技術在企業落地。
傳統的監控一般會將監控分層,比如我們常用的分層方式是將監控分成基礎設施、系統、應用、業務和使用者端這幾層,分完層後將每層的監控做到位。
而在傳統的監控裡,Zabbix 是最常用的開源軟體,Zabbix 的優點主要是成熟可靠,社群非常強大,幾乎你的需求,社群都有一套對應的解決方案,但 Zabbix 的缺點也很明顯,就是太難用,很多監控配置加起來成本很高,甚至很多運維用了很久的 Zabbix,還沒學會怎麼配置 HTTP 監控,這在應用較少的時候,還不是很明顯的問題,但是到了微服務時代,這個問題就暴露得非常明顯了,而且 Zabbix 以機器為維度的監控也無法適用微服務時代的理念。
微服務監控比起傳統應用的監控,最明顯的改變就是視角的改變,我們把監控從分層+機器的視角轉換成以服務為中心的視角,在微服務的視角下,我們的監控可以分為指標監控、鏈路監控和日誌監控,在開源社群,這些監控也都有對應的解決方案,比如指標監控有 Prometheus、InfluxDB,鏈路監控有 Zipkin、Pinpoint,日誌則有 ELK。
在 51 信用卡發展起步的時候,我們也同樣使用這些開源方案來解決我們的監控問題,但當我們業務快速發展的時候,我們開始不斷碰到監控上的挑戰,其中有部分是網際網路金融特有的,另一部分是微服務所帶給我們的。
微服務監控有什麼特點?用一句話概括就是服務特別多,服務間的呼叫也變得非常複雜。我們其實是微服務的受害者,其實業內很多人做的架構只是服務化,並不夠「微」,而我們做的比較徹底,我們線上很多服務都只有一個 API,但這樣造成線上指標非常多,告警也非常多,讀和寫的壓力都非常大。
網際網路金融是一個跟錢息息相關的行業,所以網際網路金融對監控也有自己的要求。首先是對故障的容忍程度很低,監控的有效性需要被反覆確認,其次是對監控的改寫度,黑盒監控在網際網路金融裡很難行得通,白盒監控變得越來越重要,開發們迫切需要對自己的應用有全面的瞭解。然後是對告警的及時以及快速診斷有更高的需求,告警以及診斷資訊在 10 分鐘內發出與 5 分鐘內發出有很大的差別,舉個例子,如果有個活動有個漏洞被黑產行業抓住,如果能早一分鐘確定問題關閉後門,就能給公司輓回巨大的損失。

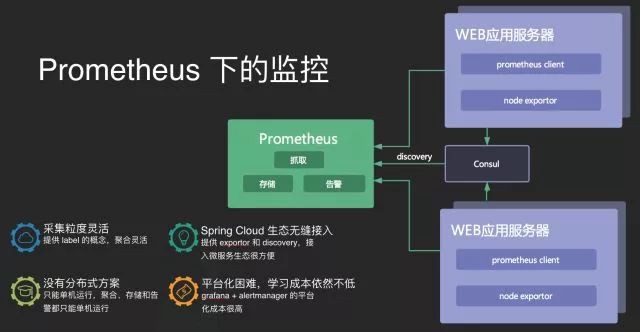
51 信用卡在早期也同樣使用 Prometheus,其實 Prometheus 是個很棒的產品,白盒監控的理念也很先進,自帶告警以及 PromQL,稍微學習之後便能上手,作為 CNCF 的專案與 Kubernetes 等開源產品結合得也很好。
在隨著服務的增長,我們開始不斷地踩坑,首先突出的問題就是 Prometheus 沒有現成的分散式方案,效能遇到單機瓶頸之後只能手動給業務劃分叢集並且之間的資料不能共享,然後拉樣式在相容多資料源上也顯得力不從心,比如我們有場景需要指定精確的時間,還有比如我們有些資料是從日誌來的或是從 Kafka 來的,這些都沒有現成的方案。
微服務的指標增長其實比想像得要快很多,因為微服務架構下,我們總是迫切想要把應用的每個細節都搞清楚,比如主機指標、虛擬機器指標、容器指標、應用效能指標、應用間呼叫指標、日誌指標以及自定義的業務指標等等,甚至在這些指標下,我們還會給指標打上更多的標簽,比如是哪個行程,哪個機房,我們大致算過一筆賬,一個服務即使開發什麼都不做,他透過基礎框架就自帶了 5000 個指標。
我們內部也討論過為什麼指標會這麼多,能不能把一些指標去掉,但很快我們就否決了去指標的想法,我們覺得業界的趨勢是白盒監控會變得越來越重要,APM 的概念會變得越來越重要,DevOps 會和白盒監控不斷發生化學反應,變成一種潮流。
而在 51 信用卡,我們是怎麼解決的呢,其實很簡單,用三個字概況就是「平臺化」,平臺化的好處很多,最直觀的好處就是提供了一個統一的平臺去處理監控問題,並給開髮帶來了統一的使用體驗。
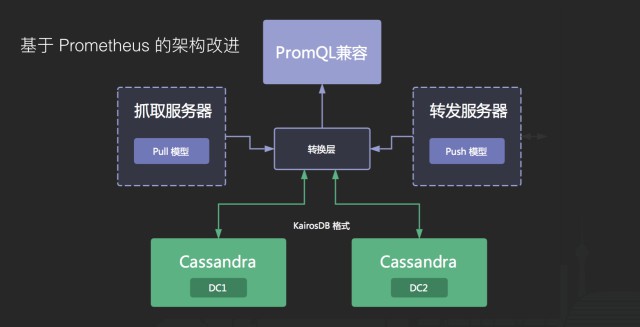
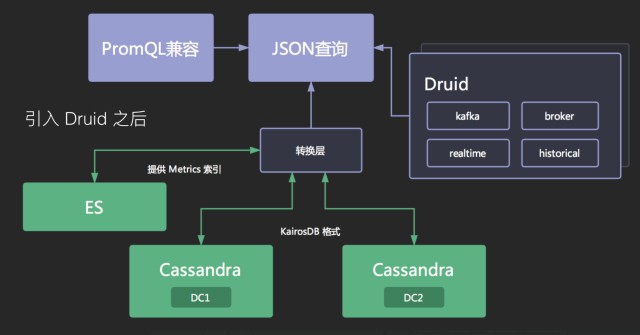
我們首先要解決的問題是如何構建對上層統一的儲存,一開始我們基於 Prometheus 的生態做了一些架構改進,將底層換成分散式的列式儲存 Cassandra,並開發了推送服務和拉取服務來相容原先的資料模型,在上層,我們開發了相容 PromQL 的介面提供給開發使用。
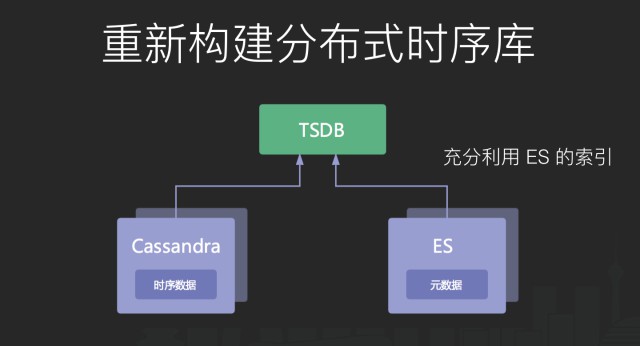
首先是 labels 的匹配效率問題,當指標名相同的時候,由於 label 是自由組合的,在匹配部分 label 的時候,我們需要先將 labels 的元資料全部讀出來,然後進行過濾,這樣的效率會顯得很低,我們的做法是在 label 元資料上面加上倒排索引,因為我們是分散式方案,倒排索引本身也需要分散式,所以我們直接使用 ES 來幫我們構建元資料。
第二個問題是預聚合,比如我們只想看 API 的整體訪問量,但做這個查詢的時候,我們會在底層讀到 4 份資料,然後再聚合再顯示出來,這樣無疑也是一種浪費。我們的做法是引入預聚合機制,在縱向,我們需要捨棄維度,在橫向,我們需要聚合時間軸。對於分散式而言,預聚合會顯得比較麻煩,因為我們需要考慮的東西比較多,比如需要在記憶體裡完成,需要合理將資料分批分配到不同機器,需要有一個視窗機制保證資料的及時有效又高效能。業內常用的做法是引入一個 Storm 這樣的流式計算或者 Spark Streaming 這樣的微批計算,然後將計算完的結果推入快取或者記憶體供告警來使用。
第三個問題是 Metric 的長度,因為在列式儲存的底層,我們直接借鑒 Kairosdb 的儲存格式,相容 UTF8 的 Metric 而直接講 Metric 轉換成二進位制儲存在資料庫裡,如果指標很少,這個問題不大,但如果指標非常多,這會造成底層儲存的儲存浪費,而且影響索引的效率,這個問題的解決辦法也很簡單,直接引入一個 Bitmap 機制就可以解決。
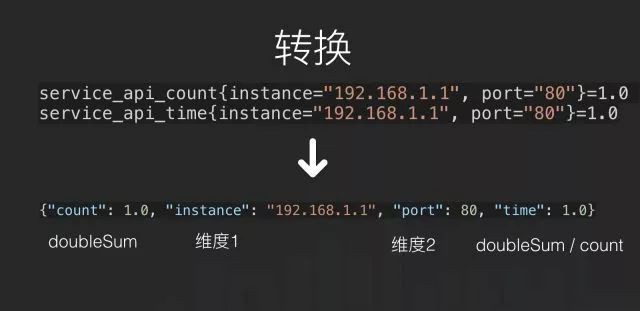
第四個問題是維度重覆,比如我們有三個指標,這三個指標的維度都一樣,但這三個指標完全不同,代表不同的值,但儲存在資料庫的時候,它會佔用三個 series 的空間,查詢的時候也不夠高效,因為往往三個指標會同時查詢同時展示。這個解決辦法是將資料庫裡原本的 value 定義成多型別支援,不只是雙精度浮點或是整型,增加 Map 的支援型別,併在資料庫的上層做相容。
當初我們在解決這些問題的時候,我們發現社群已經有一個比較好的解決方案了,就是 Druid,不是阿裡那個資料庫連線池 Druid,而是 druid.io。它比較好地滿足了 Bitmap、預聚合、複合型別、倒排索引、冷熱資料這些需求。
我們將拉服務和收服務做了進一步的改進,可以自動將資料做轉換,相容原先資料模型的同時,將資料也投遞一份到 Druid 裡。
至此我們基本完成了一個能夠滿足需求的儲存架構改進。
最後和大家分享兩個非常有用又容易實踐的告警智慧診斷:
第一個是和日誌監控的聯動,當一個告警發生的時候,我們以時間、服務為維度去匹配 ERROR 或是 Exception日誌,並以 simhash 之類的相似演演算法排序日誌,就會非常快速地找到問題的直接原因,不一定是 Root Cause,但告警的時候如果附上這個日誌,對開發排查問題的效率會有很大的幫助。
第二個是和鏈路監控的聯動,當一個告警發生的時候,我們同樣以時間、服務查詢鏈路監控,並從日誌監控裡排名靠前的日誌提取 trace id 後進行過濾,能很快發現故障的關聯原因,這同樣不一定是 Root Cause(很有可能是),但同樣對開發排查問題很有幫助。
-
第一個是更好的底層儲存,Cassandra 畢竟是一個通用的列式資料庫,對時序資料來說,有很多不好最佳化的地方,我們期望能夠自研一個時序資料庫來滿足我們的業務需求。
-
第二個是智慧化的監控和告警,運用合適的演演算法並加上機器學習或是深度學習,探索出無閾值的告警體系,並自動分析出告警之間的關聯關係,給出根因。
-
第三個是APM和監控的更緊密結合,將鏈路監控、日誌監控和指標監控直接合併,更深度地診斷系統,系統沒有無法探查的秘密。
作者介紹:楊帆 CliveYoung,2017 年加入 51 信用卡,現任監控系統負責人,負責監控系統的架構升級及落地方案。在監控、私有雲、分散式儲存等方面有豐富的經驗,同時對 DevOps 也充滿興趣,熱衷於將開源技術與業務結合提升效率。
本次培訓內容包括:Docker基礎、容器技術、Docker映象、資料共享與持久化、Docker三駕馬車、Docker實踐、Kubernetes基礎、Pod基礎與進階、常用物件操作、服務發現、Helm、Kubernetes核心元件原理分析、Kubernetes服務質量保證、排程詳解與應用場景、網路、基於Kubernetes的CI/CD、基於Kubernetes的配置管理等,點選瞭解具體培訓內容。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。