
導讀:盡信資料,不如無資料。
你以為資料能夠告訴你一切?其實如果你不能用正確的姿勢運用資料,很可能會被它矇蔽,做出非常危險的錯誤決定。
你對資料的把握、瞭解,決定了你如何利用資料來改變認知。閱讀本文的4個案例,看看谷歌、領英、Netflix等明星公司是如何運用資料驅動決策的。

案例01 Airbnb資料驅動認知的故事
Airbnb是一家資料驅動的公司,但是Airbnb並不是完全靠資料來指導整個工作,他們是先以認知為主導,提出一個假設,基於這個假設,做出一些功能,上線透過A/B測試等方式來驗證這個假設,然後不斷的重覆這樣的驗證驅動。
這種不盲目用資料來指揮決策的方式,是依靠人的直覺和認知來做主導,資料驗證為輔的樣式來驅動。因為在資料中發現的規律,不一定是代表正確的規律,有時候透過小資料發現的規律,再用大資料的分析方式來驗證,可能會更有效果。
人的認知與資料分析是互補的,認知依據小資料可以發現情感、人性、感性所決定的規律,但是資料分析不一定發現得了,資料分析透過演演算法與計算,可以發現人思維觸及不到的地方。
Airbnb認為,如果沒有經過足夠樣本的測試,資料就有可能會誤導人,所以有了想法和假設之後,就要去真實世界嘗試,併發現資料來證明這個假設。
在Airbnb,鼓勵每一個員工都能夠做出新功能,新員工第一天就可以釋出自己的新功能,並測試這個功能是不是有效,鼓勵員工把想法實現成功能,再為功能做好測試。
Airbnb 以前僅僅是釋出房子,尋找房子的功能,對使用者來說黏性還比較小。Airbnb 在 2011 年夏釋出“社交關係”功能,允許使用者在 Facebook 上釋出房源照片和連結。這個功能還能顯示朋友和房東共同社交關係,2011 年 Airbnb 釋出該功能時,使用者裡已有 16516967 對“關係”。
2012 年夏,Airbnb 更新之前的“心願單”功能(Wish Lists ),一個月後,45% 使用者使用了此功能,共建立超過 100 萬清單。

▲Airbnb“心願單”功能
“心願單”功能因為在之前已經有了,團隊希望瞭解,心願單是否有助總預定量增長和最佳化?心願單按鈕以前是星形形狀,大多數網站都是這種星形,有一個員工建議把星形改為心形,有可能效果會更好。於是,將房源照片上原“星星”標記,改成“愛心”心形標記,上線之後對該功能進行測試,發現一段時間之後,這個小的最佳化,將收藏功能提升了30%的使用率。
“心願單”是使用者內心的一種願望,他們建立“好想去住蒙古包和城堡”這樣的清單,並不時點開瀏覽。最終和 Airbnb “社交關係”功能一樣,“心願單”讓其更具差異性,超越了一個“僅用於尋找住宿”的應用,並拓展了 Airbnb 的探索屬性。
這是基於資料驅動的一種探索方式,無論想法是多麼科學,都應該在資料系統中得到驗證,因為資料有時候是使用者真實行為的反饋。
案例02 Netflix以資料驅動產品
Netflix成立於1997年,是一家線上影片租賃提供商。使用者可以透過PC、TV及iPad、iPhone收看電影、電視節目,可透過Wii、Xbox360、PS3等裝置連線TV。比較知名的例子就是Netflix,透過自身大量使用者行為資料,發現使用者喜歡的熱點,投資拍出了超級火熱的電視連續劇《紙牌屋》。
Netflix是以資料驅動來打造產品的公司,資料分析的理念已經成為Netflix的企業文化。Netflix稱之為消費者法則,最主要的標的就是透過創新提高使用者體驗。
Netflix採取的方法,就是依據線下傳統的科學方法進行A/B測試,然後再透過線上測試來驗證。這種想法的具體思路是:
1、提出一個假設。
假設一個設計、功能、演演算法能夠提高使用者體驗。
2、設計線下測試。
透過MVP或者研發的方式,做出方案或原型。
3、線上測試。
4、讓資料說話。
在做線下A/B測試的時候,Netflix會抽出幾千或幾萬的使用者來進行測試,並把這些分到10到20個單元中,然後對這些單元平行檢測,透過A/B測試來驅動資料分析工作,來檢驗創新的想法或者思路,是不是會被使用者所喜歡。
如果線下測試支援了想法或者假設,就可以實施線上使用者測試。只有透過這個線上測試的假設才能夠在系統中進行實施。
Netflix就是依據自己的大資料分析能力,來決策拍出紙牌屋。
作為世界上最大的線上影片租賃服務商,透過資料分析,Netflix發現使用者很喜歡Fincher(社交網路、七宗罪的導演),也知道Spacey主演的片子表現都不錯,還知道英劇版的《紙牌屋》很受歡迎,三者的交集表明,值得在這件事上賭一把。

▲Netflix首部原創電視劇《紙牌屋》
於是Netflix花1億美元買下版權,請來David Fincher和老戲骨Kevin Spacey,首次進軍原創劇集就一炮而紅,在美國及40多個國家成為最熱門的線上劇集。
國內的主流內容推薦引擎(無論是資訊、短影片還是影片)相比,通常採取以使用者為中心,根據使用者瀏覽、收藏、付費等行為來建構個性化推薦體系,而Netflix以內容特徵為中心,來分析不同內容可以推薦給誰,如何推薦,甚至是否要調整內容。
案例03 領英的資料驅動經營
LinkedIn(領英),全球最大職業社交網站,是一家面向商業客戶的社交網路(SNS),成立於2002年12月,於2011年5月20日在美上市,總部位於美國加利福尼亞州山景城。領英2016 年被微軟以 262 億美元收購。
LinkedIn的CEO Jeff Weiner每天早上都會看一份每小時更新的資料報告,從報告中他能迅速瞭解到業務的現狀,一旦發現問題就立即發給業務團隊尋求解答。同時,LinkedIn整個高層對資料都非常敏感。

▲LinkedIn CEO Jeff Weiner
圍繞資料分析來打造產品,也是領英公司的企業文化,領英的資料驅動,是如下步驟:
1)分析資料。
2)依據分析結果,最佳化產品。
3)依據分析結果,建立營銷方案。
領英的資料分析,是從資料來驅動的,然後透過人來發現新認知,再依此來完善產品,以及建立營銷方案。這種資料驅動認知,和以認知主導資料驗證的思路不同,但是核心都是互相驗證。
例如,2004年,領英對自己的使用者來源渠道進行分析,發現從谷歌搜尋來的使用者,是電子郵件邀請來的3倍。領英決定不再去關註郵件獲取的方式,把主要精力放在最佳化搜尋帶來使用者的體驗,這樣一轉折,6個月以後,每個月的使用者數都保持了60%的增長速度。
然後透過分析使用者留存,發現從搜尋來的使用者,特別關註使用者的簡歷,於是就做出決策,不斷的誘導使用者完善簡歷。
再分析使用者的黏度,使用者註冊第一週以後,需要增加5個社交關係,這樣的使用者帶來的價值,是低於5個以下社交關係的使用者的3倍以上。於是,領英又大力推廣自己的產品,提升使用者在第一週內增加使用者幾個社交關係,不斷提高使用者的留存率。
資料本身中就存在著規律,無論資料求和、平均、還是佔比、同比、環比、統計值等,或者利用資料挖掘的各種演演算法,例如聚類、分類、回歸、或者深度學習演演算法,都能發現資料中隱藏的規律。但一般發現的都是相關性的關係,還需要依據認知找出因果關係,有了因果關係,行動上就會有抓手。
所以資料和認知,是需要互相配合,才能找到更好的解決方案。
案例04 Gmail 團隊再造 Inbox的故事
電子郵件已經發明數十年了,各廠商幾乎“江郎才盡”,郵件廠商的產品一直沒有太大的變化。
大約在2012 年,Google Gmail 團隊決定為 Gmail 打造一款獨立應用,為此團隊對 Gmail在設計上進行大幅改版。如同所有Google的產品一樣,它在正式推出前會先在內部進行測試。
這款改版後的 Gmail 在 Google 內部引起了軒然大波,Gmail 收到了大量吐槽的反饋,諸如“你們毀掉了 Gmail”,“你們這些瘋狂的設計師在想些什麼?”,“你們(Gmail團隊)完全破壞了Gmail!”
Google的工程師為了阻止Gmail團隊的決定,寫了很長的帖子併發布在內部的Google+和論壇上,他們詳細說明瞭應用中每一個改變的地方都不應該被改變的理由。因為改版太激進了,不少谷歌人每天經常用到的功能都被刪除了。
為了平息內部的爭議,Gmail 團隊的負責人做了一次“你不是使用者”的演示, 透過大量使用者資料來說明改版決策的原因。
1)一個普通的谷歌人(Googler),平均每天會收到 450 封郵件,其中大部分不僅需要閱讀,而且相當一部分還需要回覆。
2)一個典型的大眾使用者,平均每天收到 5 封郵件,而其中大多數只是推廣郵件,並不需要回覆。
之所以去掉一些功能,是因為這些使用者從來都不使用它們,而谷歌內部的使用者並不代表真正的使用者群體。而且這些功能,會讓產品變得非常複雜,大部分使用者只需要一個簡單的郵件客戶端而已。
如上的回覆,雖然是基於事實的資料分析,但依然沒有平息內部激烈的矛盾,谷歌工程師自己需要利用這些功能應對日常的大量郵件。
最後達成妥協,Gmail 仍然面對龐大的使用者群,但是要保持精簡,一些更高階的功能被隱藏起來。同時,Gmail 團隊開始打造一款針對每天處理大量郵件的高階使用者的產品,這就是今天的 Inbox。Inbox釋出之後,市場反應出奇的好。使用者覺得驚艷到感覺不像谷歌出品,同時,為了專業使用者提供大量方便好用的功能。

▲Gmail團隊再造的郵件系統Inbox
Inbox的決策來源,是資料分析結果的支撐。資料不是一切,也不是唯資料論,但是資料呈現了客觀事實,雖然有時候可能不完備或者侷限,但是利用資料,以避免被過去的認知所誤導,幫助科學決策。
總結
管理者有豐富的經驗,有豐富的想象力,這些都是優勢。但是面對不確定的環境,管理者的成見、偏見,包括意識的推理,以及經驗的侷限性,尤其是管理者個人的倔強的脾氣、倔強的執念、倔強的傲慢、倔強的貪念等不科學的方面,都有可能導致決策和現實有巨大的出入。
例如管理者的貪,體現在想快速獲得推廣,快速獲得大規模營收,而忽視產品所在階段;管理者的傲慢,體現在對自我觀點的自負,為了證明自己,而做出不科學的決策;管理者的執念,個人的妄想,導致產品在不正確性方向上的巨大投入。這些都是管理者個人的侷限性,往往會影響產品的大局。
因此,管理者需要建立資料與認知的雙輪驅動機制。建立資料驅動的分析文化,用資料和自己的認知互相驗證,互相檢查,以避免自己走入誤區。如果已經有一個好的想法或認知,那麼根據這個認知來快速構建一個最小可行化產品,針對這個產品,需要做驗證,獲得資料,瞭解和學習資料,再形成新的認知和想法。周而複始的迴圈,不斷驗證整個產品的進展。
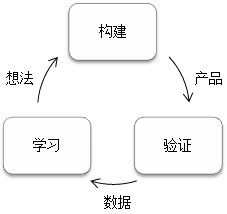
▲構建、驗證、學習的迴圈
為什麼要建立資料驅動的驗證迴圈,是因為管理者認知與現實之間,有三層隔閡,而資料驗證可以發現隔閡,讓認知與現實更加吻合。
1、幻想與現實的隔閡。
管理者有自己的豐富經驗,而且會有自己獨到的認知,這是好的一面。壞的一面,就是管理者,對自己的產品都有一種情結,有創業情結、職業情結、產品情結、夢想情結等,這些會讓管理者陷入認知陷阱。
管理者對自己的認知一般都很堅持,而且很自負、自傲,因為他們至少在某方面是專家,所以越是這樣,他們越容易堅守自己的觀點,尤其是有時候是錯的,但自己並不知道。
當局者迷,需要一套資料分析系統,依據資料來調整認知。管理者需要設計出各類試驗與假設,並用資料來驗證這些認知的正確性。
2、虛假繁榮資料與客觀資料的隔閡。
資料是來自事實與客觀世界的反饋,資料本身沒有問題,即使建立了一套資料分析系統,能夠觀察到各類資料分析的指標,但是人們看資料,依然會帶著有色眼鏡來看,符合自己內心期望的就會加強,不契合的就不會關註或者弱化。
很多指標可能會給團隊帶來很多自我假象,以為發展非常好,但是實際上都是虛假繁榮的數字,例如點選量、訪問量、頁面瀏覽量、獨立訪客數、粉絲數量、下載量、網站停留時間、使用者郵件地址這8個指標,這些指標都是一種原始指標,他們並不代表什麼,但有可能會造成虛假繁榮的現象。
例如1000個訪問量,是10個使用者訪問了100次,還是1000個使用者只訪問了1次,這種意義完全就不同了。1000個點選量,這個點選量是多少人次的點選。下載量增加了,後面增加了多少新使用者?
3、當前指標與行業標準的隔閡與差異。
管理者可能一開始找不到自己要關註的指標,也不知道這個指標應該到底是多少才是科學的。
一般一個線上零售商,其轉化率在2%左右,如果能到10%就非常不錯,大部分轉化率在0.5%左右。根據研究,65%的訪客會遺棄他們的購物車,其中41%是因為還沒想好買不買,25%是因為價格太高。
一般SaaS服務商,爭取每年獲得20%的客戶銷售收入增長,爭取每個月讓2%的使用者增加他們的付費額。在最佳化方面,爭取將每個月的流失率降低到5%以下,否則說明產品的使用者黏性不夠好,如果能降低到2%,證明產品的黏性很不錯。
媒體網站,大部分站內廣告的點選率在0.5%到2%之間,如果低於0.08%,說明有問題。
使用者製造內容網站,如果訪客在你的網站每天平均花費17分鐘,證明黏性較好。25%的訪問者會潛水,5%到15%的使用者會製造內容,而這些參與製造內容的人中,80%的內容來自一小部分極度活躍使用者,而只有2.5%的人會參與內容互動。
針對免費移動應用,65%的使用者會在安裝後90天內停止使用該移動應用。
關於作者:彭耀,象形科技聯合創始人兼CTO,典型的產品型和技術型管理者。資深的大資料專家、人工智慧專家和產品專家,有近20年的開發和產品經驗。
本文摘編自《升維:爭奪產品認知高地的戰爭》,經出版方授權釋出。
延伸閱讀《升維:爭奪產品認知高地的戰爭》
轉載請聯絡微信:togo-maruko
點選文末右下角“寫留言”發表你的觀點
推薦閱讀
Python爬蟲新手進階版:怎樣讀取非結構化網頁、影象、影片、語音資料
Q: 資料與認知的關係,你明白了嗎?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

 點選閱讀原文,瞭解更多
點選閱讀原文,瞭解更多