導語:伴隨著各類高新技術的出現,“人工智慧”一詞越來越多地出現在人們的日常生活中,而運維朋友常聽到與自身工作息息相關的便是智慧運維了。
但在當前,國內大部分的智慧運維並沒有完全落地,整個行業處在一個初期的探索階段。因此,很多運維人或多或少都有這樣的疑問:一個傳統企業的智慧運維之路該如何走?AIOps 的架構設計與組成究竟從哪裡落地?今天,小編就為大家帶來了日誌易產品總監饒琛琳對於智慧運維平臺建設的演講分享實錄。
本篇分享,主要從運維需求的源頭出發,逐步推匯出 AIOps 的架構設計與組成,在推導過程中,饒琛琳詳細介紹了時序預測、異常檢測、樣式概要的分析原理與實現方式的具體場景,以及對應的開源專案選擇。實錄詳情如下,還等什麼,快來收乾貨吧!

今天分享的是資料驅動的智慧運維平臺,可以看到,標題有兩個點,第一個是平臺,第二個是資料驅動。主要是分享平臺本身的主件架構,重點放在一些與資料分析相關的細節,包括對異常檢測、時序預測、模組聚類等場景的剖析。
我在參與編寫《企業級 AIOps 實施建議》白皮書期間,與騰訊、華為手機的一些朋友在討論“智慧運維”時候,得到了一個比較有趣說法:我們可以把 AIOps 進行分級,像“異常檢測”這樣的細節點,就認為它是一個原子場景,不用再細分,或者是取用周志華教授的說法,稱其為“學件”,這種學件,類似於程式中的 API 或公共庫,可以放到四海而皆準;再往上層就是類似於“根因分析”的串聯應用,透過多種演演算法、多個原子場景組建出來的串聯組合場景;再往上便是更高階的場景,最終達到終極 AIOps 。今天分享的皆是原子場景的使用方式。
怎麼構建一個 AIOps 平臺?我們先要確定目的,然後再談如何達到目的。
在定義 AIOps 時畫了一張圖,除了中間有機器學習、BigData、Platform 外,外層的內容就是監管控,這也就是做 AIOps 的目的。只不過是在做監管控時,要使用一些新的方式,以減輕運維的工作量。

與傳統運維相比,智慧運維可以更靈活、更易用,並且快速探索資料。比如有 1000 臺伺服器,如果沒有一個統一的平臺,要發現問題會非常麻煩。
探索和實驗平臺是什麼意思呢?這其實是總結了運維人員的一個工作狀態:猜測、試錯,如果試錯不對,再進行下一次試錯,即一個探索發現的過程。如果這個過程執行不夠快,就意味著解決故障的速度會慢下來。因此,我認為,這個快慢問題對於運維來說非常重要的一個點。

從實際情況來看,AIOps 平臺裡應該有哪些東西?我覺得下麵的描述很有趣,資料湖,即儲存採集資料,還有自動化系統、記錄系統、互動系統、監控生態圈。

將這幾個系統拆分一下,我們可以發現,監控系統和互動系統在運維的分類中比較混淆。一般來說,監控系統負責的只是把資料抓下來,然後去判斷是不是有問題,但是實際上監控系統還要負責一個重要的流程,也就是這個問題和其他問題有沒有聯絡?應該把這個問題發給誰?傳送時只能告訴有這麼一個問題,還是描述更多資訊?這段流程要比資料採集部分更重要。要做好支撐運維目的的平臺,就需要將其單獨拆分考慮。
這張幻燈看起來好像和 AI 沒有太大的關係,只要具備這些系統,就可以承認這是一個 Ops 平臺了,但是在這個平臺中,AI 是什麼?

下圖是阿裡雲 AI 平臺的一張截圖,類似於這種的機器學習 Web 平臺,市面上應該有三四十種,但這種平臺對運維來說並沒有實際的意義。

我們運維人真正需要的是機器學習在運維工作中的運用。AppDynamics 的 2016 年度總結中提出一些對於 APM 廠商來說可以做出的 AI 場景,可以對這些內容進行拆解,得出運維人的真正需求。

我這裡提供一種很好的拆解方式,下圖是《 Google SRE book 》書中的一張圖,對於運維人員來說,最重要的還是要去解決底層需求,包括監控、事件響應、根因分析、CICD、容量規劃、部署,將這張圖與上圖中 AI 應用場景進行對照,便會得到從技術到需求應用之間的關係。


從對應的關係中可以看出,很多鏈條是相通的,而最終的目的都是要做好一個監控,即最底層的需求。此外,還有一條鏈是“根因分析-智慧報警-自動化”。也就是上面的鏈條發現故障,最後一條鏈發出報警,並明確後續流程。

下麵主要聊一下兩個大鏈條裡幾個最常見、比較好入手的場景。第一個是時序預測,預測這個話題非常大。在與客戶交流時,也會被問到一些離譜的預測需求,但真正可落地的需求,還是那些資料量足夠大、細,且全面,同時預測的是比較細緻情況的需求。

即使是靠譜的未來預測需求,也依然是太大的話題。例如下圖,有了時序資料,以紅框為點,中間的藍線是資料實際情況,剩下三條線是用了三種不同的預測演演算法得到的預測結果,你會發現依然千差萬別。
因此,即便有資料,在要求不高的情況下,能不能做依然是一個需要劃分的問題。

回到運維領域,下麵幾張圖是大家比較常見到的序列,對於四種常見的序列情況我們可以想到它應該怎麼走,這時就可以想辦法讓機器去想。
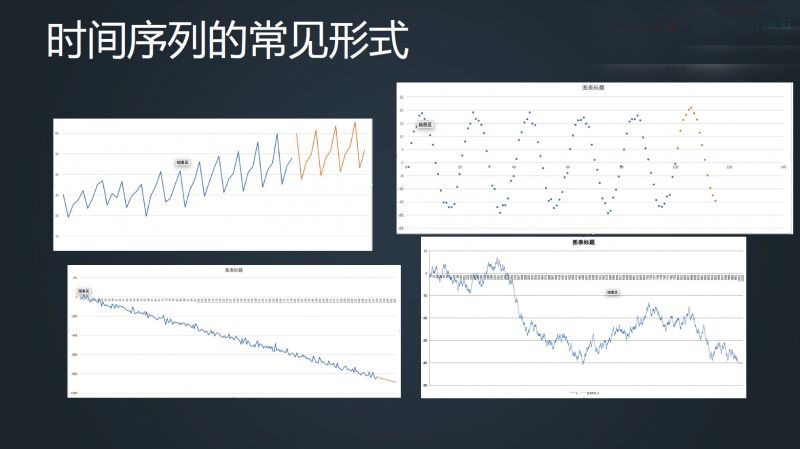
對於以上幾張圖來說,可以用統計學上的辦法去做時序預測,也就是指數平滑,從一階、二階、三階持續運算,α、β、γ 會越來越多。
如果有 100 萬條這樣的線,依次去配 α、β、γ,那工作量將會非常浩大。就這麼幾個引數、十幾條線,可能就要花費兩三個月的時間來做,如果說所有的監控指標全這麼做,那肯定是不現實的。

在此基礎上,就可以考慮用一些減輕人工作量的辦法,我們可以用各種不同統計學裡的函式確定情況,最後獲取一個相對最好的MSE,確定最佳引數,這樣工作量就會減輕一些。


對於時序預測的開源選擇有很多,除了剛才講到的 RRDtool 、Holt-Winters 外,還有 Facebook、hawkular 的開源專案。
前面講的對自動化調參的過程,很多具體的細節來自 Redhat 專案,雖然主專案已經沒有更新,但是這個子專案還是推薦大家看一下。

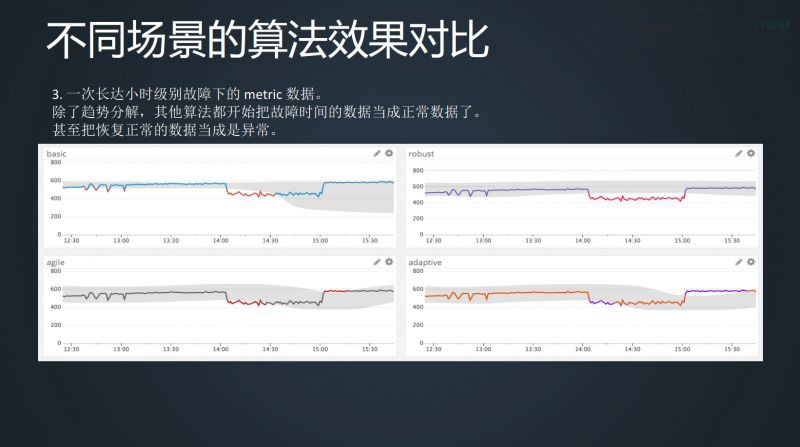
第二個場景是異常檢測。其實預測本身就是異常檢測的一種方式,但異常檢測並不只是這種方式。例如下麵這兩種,雖然是比較離譜的情況,但並不代表在長時間維度下不會出現,這種情況應用任何平滑的方法,對這條線的異常檢測都沒有任何意義。

再如下麵這種線,在不同的障礙階段差別很大,但用平均值的話,整個這一段中平均值都在一條線上,根本無法判斷這條線的任何區別。

此外,異常檢測還要考慮一個最基本的同環比,也要考慮同比的魯棒性。

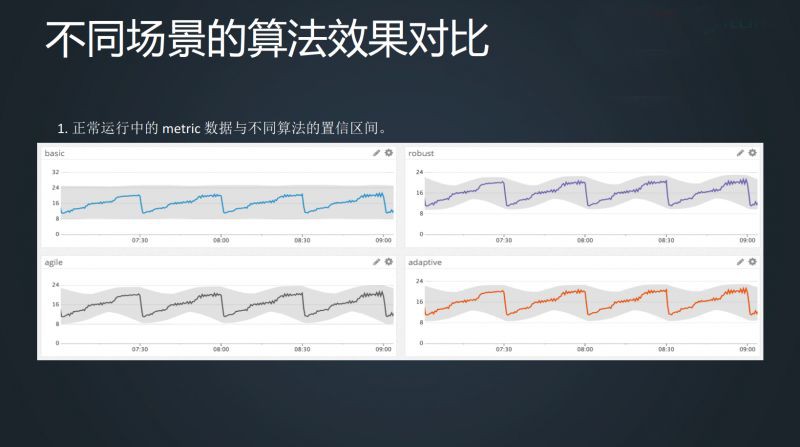
這裡可以介紹一下 datadog 的異常檢測,提供 4 種檢測方法, Basic 採用的是四分位方法,Agile 用的是 SARIMA 演演算法,Robust 用的是趨勢分解,Adaptive 在我看起來,採用的是 sigma 標準差。

下麵是在不同場景下,這四種不同演演算法對這一條線是否異常的判斷,我們可以看到,如果不需要對本身業務的理解,單純就是一個演演算法,一切都正常,如第一個想過對比,但在實際工作中卻不太可能。
所以當我們真的要去做異常檢測時,必須對業務要有一定的瞭解,明白 metric 這條線背後代表的含義,才能對各種演演算法進行選擇,這個地方沒有萬能鑰匙。



對於異常檢測的開源庫選擇,有些是原子的,有些是組合的。Etsy 的 skyline 是比較高階的場景,裡面帶有資料儲存、異常檢測分析、告警等;Twitter、Netflix、Numenta 是純粹的機器學習演演算法庫,沒有任何附加內容;Yahoo 的 egads 庫可以算是異常檢測的原子場景,比 Twitter 和 Netflix 層級稍高。

第三個要講的是資料概要-文字聚類。我們知道,前面講的兩類都是監控 metric 情況,但是一些故障單純看 metric 是無法找出故障的。在排障過程中可以看幾條線,包括時間相關性或者時序聚類,也可以做根因分析,但這些還不足夠。
我這邊可以提供的是另外一條思路,日誌易是一款日誌分析產品,企業有各種各樣的系統,產生各種各樣的日誌,如果透過ETL的方式把日誌收集起來,可能要寫上萬個運算式,是不可能完成的任務。

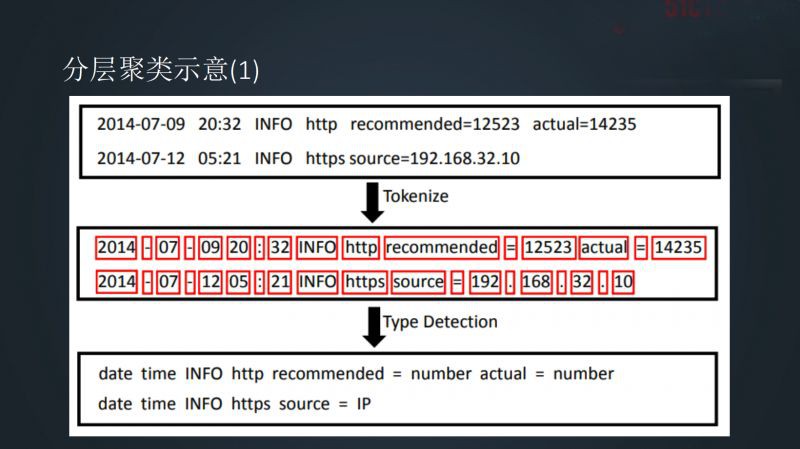
我們可以看到下圖有四行日誌的輸出程式碼,可以看出日誌格式和種類是有限的。假如這四行程式碼打了 1000 萬條,其實也就是這四行程式碼打的而已。如果從人的理解上看,這四行程式碼就說了兩件事:1. 有一個 User 登入了,2. 定義了一個常量。我們要乾的是什麼?就是把 1000 萬行程式碼反推到四個不同的日誌樣式。

另外一個細節,在處理自然語言時,逗號還是分號沒有任何意義,我們關註的是文字,但日誌裡面的每一個符號都很關鍵,是一個獨特的聚類聚合方式。如果我們不想上機器學習技術,只想先跨出第一步,就可以利用這個特性,除去文字,留下這堆標點符號。

替換之後,留下的內容也足夠反映出一些資訊。例如下麵這個實體,這個思科的 ASA 日誌情況,進行處理後,得到了一些一模一樣的標點符號,我們就可以推測應該是同樣的內容,這個是最簡單的方式,因為比較粗略,所以推測得也不是特別有效。

可以再往前一步,加上一點聚類的東西,先走 TFIDF ,提取一些文字的特徵值,再走一個 DBSCAN ,拿每個聚類的樣本情況來看。當看到某個樣本不太對,就單獨把這個樣本拿出來,調整引數,將聚類裡的日誌重新聚類,再觀察一下情況。


聚類的思路是相通的,先提取,做聚類,聚類出來有問題,再切分一個小類。但是實際上線使用的話,還是有很多問題需要考慮的。用 DBScan 聚類的執行時間比較長,是一個偏離線執行狀態,而且佔用的資源也多。
除了這類演演算法上的問題,還有一個思路上的問題,單純只是完全的聚類,沒有辦法合適地判斷邏輯程式碼,也就不足以達到知道它的原始程式碼是什麼樣的目的。


這裡我們參考一下日本電器美國實驗室曾經發表的一篇論文,他們的演演算法叫 HLAer,原理是不直接上一大堆文字的聚類方式,而是反過來去推導。

我們做的是運維日誌,大多數情況下,運維日誌有很多東西不需要耗費 CPU 處理。第一個,像 Num、Date、IP、ID 等都是運維 IT 日誌裡一定會出現的,但在關註樣式時不會關註這些。因此,可以在開始就把這些資訊替換,節省工作量。
第二個是對齊,對齊也是耗資源的,如何減少對齊的時候強行匹配資源呢?可以開始先走一個距離極其小的聚類,這樣每一類中的原始文字差異非常小。此時意味著第二步得到的最底層聚類去做對齊時,在這個類裡的對齊耗損就會非常小,可以直接做樣式發現。
到第四步的時候,雖然還是聚類,但是消耗的資源已經非常少,因為給出的資料量已經很小,可以快速完成整個速度的迭代。

這是一個事例,首先將兩條日誌去做分層,再去做一個發現,然後去做一個對齊和一個樣式發現。透過這種方式,可以把所有日誌一層一層往上推,最終把整個結果全部推匯出來。

比如一開始給出的是 15 種,覺得不合適,往下走一層,看 13、14 是怎麼樣的,還不合適,再往下走一層,看 9、10、11、12 是什麼,總有一層是合適的,就可以把前面的 8 條日誌得到一個樹狀結構。

當然,為了方便使用,可以提前中止結構樹生成,不一定要推到頂上那個點。一般會在提前、合適的情況下,終止這個數的生成,從機器辦法來說,可以記錄下每一層剩下多少個這樣的樣式,找到拐點,這個拐點能夠證明再往下已經不方便合併即可,但是這種方式計算量比較大。
因此,目前會選擇一個簡單但是對肉眼比較合適的方式,即每一行都有分詞,如果一行裡面分了 20 個,其中,要被替換成新的東西超過了 5%,覺得不太合適看,這個時候就可以停下來了。

相關閱讀:
運維圈頂級大會SREcon現場報道,解讀SRE 2017年動向
從5臺伺服器到兩地三中心:魅族系統運維架構演進之路(含PPT)
活動預告:
6 月 1 ~ 2 日,GIAC 全球網際網路架構大會將於深圳舉行。GIAC 是高可用架構技術社群推出的面向架構師、技術負責人及高階技術從業人員的技術架構大會。今年的 GIAC 已經有騰訊、阿裡巴巴、百度、今日頭條、科大訊飛、新浪微博、小米、美圖、Oracle、鏈家、唯品會、京東、餓了麼、美圖點評、羅輯思維、ofo、迅雷、曠視、LinkedIn、Pivotal 等公司專家出席。
本期 GIAC 大會上,運維部分精彩的議題如下:

參加 GIAC,盤點2018最新技術。點選“閱讀原文”瞭解大會更多詳情。
