小編邀請您,先思考:
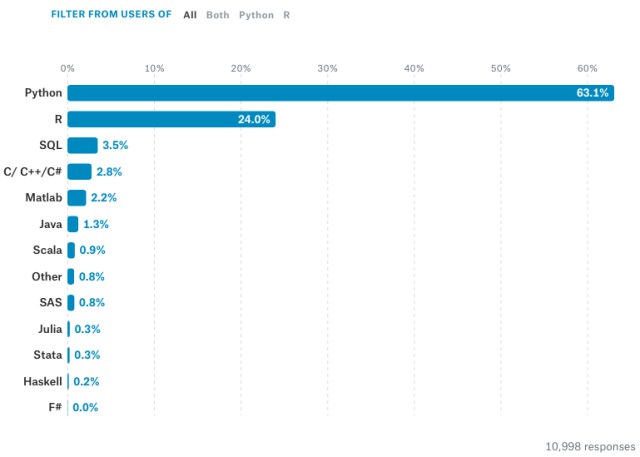
1 您使用Python做過什麼?
2 如何用Python實現決策樹系列演演算法?
人生苦短,就用 Python。
在 Kaggle 最新釋出的全球資料科學/機器學習現狀報告中,來自 50 多個國家的 16000 多位從業者紛紛向新手們推薦 Python 語言,用以學習機器學習。
目錄
-
一、線性回歸
-
1、代價函式
-
2、梯度下降演演算法
-
3、均值歸一化
-
4、最終執行結果
-
5、使用scikit-learn庫中的線性模型實現
-
二、邏輯回歸
-
1、代價函式
-
2、梯度
-
3、正則化
-
4、S型函式(即)
-
5、對映為多項式
-
6、使用的最佳化方法
-
7、執行結果
-
8、使用scikit-learn庫中的邏輯回歸模型實現
-
邏輯回歸_手寫數字識別_OneVsAll
-
1、隨機顯示100個數字
-
2、OneVsAll
-
3、手寫數字識別
-
4、預測
-
5、執行結果
-
6、使用scikit-learn庫中的邏輯回歸模型實現
-
三、BP神經網路
-
1、神經網路model
-
2、代價函式
-
3、正則化
-
4、反向傳播BP
-
5、BP可以求梯度的原因
-
6、梯度檢查
-
7、權重的隨機初始化
-
8、預測
-
9、輸出結果
-
四、SVM支援向量機
-
1、代價函式
-
2、Large Margin
-
3、SVM Kernel(核函式)
-
4、使用中的模型程式碼
-
5、執行結果
-
五、K-Means聚類演演算法
-
1、聚類過程
-
2、標的函式
-
3、聚類中心的選擇
-
4、聚類個數K的選擇
-
5、應用——圖片壓縮
-
6、使用scikit-learn庫中的線性模型實現聚類
-
7、執行結果
-
六、PCA主成分分析(降維)
-
1、用處
-
2、2D–>1D,nD–>kD
-
3、主成分分析PCA與線性回歸的區別
-
4、PCA降維過程
-
5、資料恢復
-
6、主成分個數的選擇(即要降的維度)
-
7、使用建議
-
8、執行結果
-
9、使用scikit-learn庫中的PCA實現降維
-
七、異常檢測 Anomaly Detection
-
1、高斯分佈(正態分佈)
-
2、異常檢測演演算法
-
3、評價的好壞,以及的選取
-
4、選擇使用什麼樣的feature(單元高斯分佈)
-
5、多元高斯分佈
-
6、單元和多元高斯分佈特點
-
7、程式執行結果
正文
一、線性回歸
https://github.com/lawlite19/MachineLearning_Python/tree/master/LinearRegression
全部程式碼
https://github.com/lawlite19/MachineLearning_Python/blob/master/LinearRegression/LinearRegression.py
1、代價函式

其中: 
下麵就是要求出theta,使代價最小,即代表我們擬合出來的方程距離真實值最近
共有m條資料,其中 代表我們要擬合出來的方程到真實值距離的平方,平方的原因是因為可能有負值,正負可能會抵消
代表我們要擬合出來的方程到真實值距離的平方,平方的原因是因為可能有負值,正負可能會抵消
前面有繫數2的原因是下麵求梯度是對每個變數求偏導,2可以消去
實現程式碼:
# 計算代價函式
def computerCost(X,y,theta):
m = len(y)
J = 0
J = (np.transpose(X*theta-y))*(X*theta-y)/(2*m) #計算代價J
return J
註意這裡的X是真實資料前加了一列1,因為有theta(0)
2、梯度下降演演算法
代價函式對 求偏導得到:
求偏導得到:
所以對theta的更新可以寫為:

其中 為學習速率,控制梯度下降的速度,一般取0.01,0.03,0.1,0.3…..
為學習速率,控制梯度下降的速度,一般取0.01,0.03,0.1,0.3…..
為什麼梯度下降可以逐步減小代價函式?
假設函式f(x)
泰勒展開:f(x+△x)=f(x)+f'(x)*△x+o(△x),
令:△x=-α*f'(x) ,即負梯度方向乘以一個很小的步長α
將△x代入泰勒展開式中:f(x+x)=f(x)-α*[f'(x)]²+o(△x)
可以看出,α是取得很小的正數,[f'(x)]²也是正數,所以可以得出:f(x+△x)<=f(x)
所以沿著負梯度放下,函式在減小,多維情況一樣。
# 梯度下降演演算法
def gradientDescent(X,y,theta,alpha,num_iters):
m = len(y)
n = len(theta)
temp = np.matrix(np.zeros((n,num_iters))) # 暫存每次迭代計算的theta,轉化為矩陣形式
J_history = np.zeros((num_iters,1)) #記錄每次迭代計算的代價值
for i in range(num_iters): # 遍歷迭代次數
h = np.dot(X,theta) # 計算內積,matrix可以直接乘
temp[:,i] = theta – ((alpha/m)*(np.dot(np.transpose(X),h-y))) #梯度的計算
theta = temp[:,i]
J_history[i] = computerCost(X,y,theta) #呼叫計算代價函式
print ‘.’,
return theta,J_history
3、均值歸一化
目的是使資料都縮放到一個範圍內,便於使用梯度下降演演算法
其中  為所有此feture資料的平均值
為所有此feture資料的平均值
 可以是最大值-最小值,也可以是這個feature對應的資料的標準差
可以是最大值-最小值,也可以是這個feature對應的資料的標準差
實現程式碼:
# 歸一化feature
def featureNormaliza(X):
X_norm = np.array(X) #將X轉化為numpy陣列物件,才可以進行矩陣的運算
#定義所需變數
mu = np.zeros((1,X.shape[1]))
sigma = np.zeros((1,X.shape[1]))
mu = np.mean(X_norm,0) # 求每一列的平均值(0指定為列,1代表行)
sigma = np.std(X_norm,0) # 求每一列的標準差
for i in range(X.shape[1]): # 遍歷列
X_norm[:,i] = (X_norm[:,i]-mu[i])/sigma[i] # 歸一化
return X_norm,mu,sigma
註意預測的時候也需要均值歸一化資料
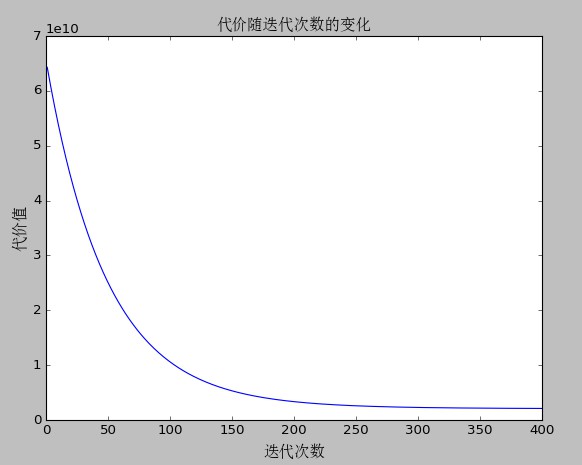
4、最終執行結果
代價隨迭代次數的變化
5、使用scikit-learn庫中的線性模型實現
https://github.com/lawlite19/MachineLearning_Python/blob/master/LinearRegression/LinearRegression_scikit-learn.py
匯入包
from sklearn import linear_model
from sklearn.preprocessing import StandardScaler #引入縮放的包
歸一化
# 歸一化操作
scaler = StandardScaler()
scaler.fit(X)
x_train = scaler.transform(X)
x_test = scaler.transform(np.array([1650,3]))
線性模型擬合
# 線性模型擬合
model = linear_model.LinearRegression()
model.fit(x_train, y)
預測
#預測結果
result = model.predict(x_test)
二、邏輯回歸
https://github.com/lawlite19/MachineLearning_Python/tree/master/LogisticRegression
全部程式碼
https://github.com/lawlite19/MachineLearning_Python/blob/master/LogisticRegression/LogisticRegression.py
1、代價函式

可以綜合起來為:

其中:

為什麼不用線性回歸的代價函式表示,因為線性回歸的代價函式可能是非凸的,對於分類問題,使用梯度下降很難得到最小值,上面的代價函式是凸函式
 的影象如下,即y=1時:
的影象如下,即y=1時:
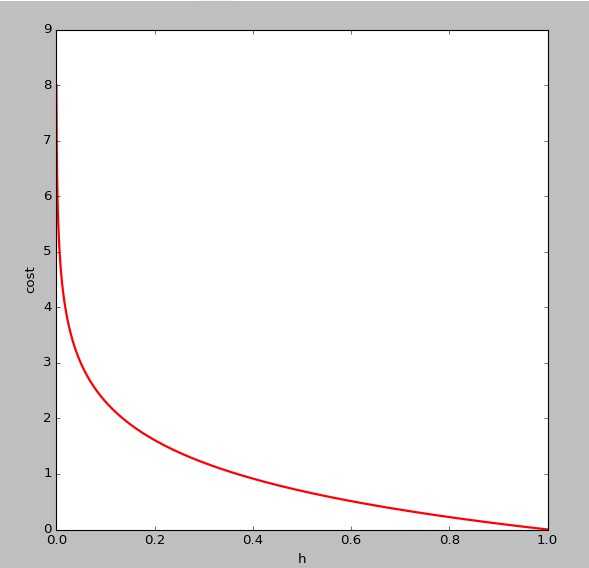
可以看出,當 趨於1,y=1,與預測值一致,此時付出的代價cost趨於0,若趨於0,y=1,此時的代價cost值非常大,我們最終的目的是最小化代價值
趨於1,y=1,與預測值一致,此時付出的代價cost趨於0,若趨於0,y=1,此時的代價cost值非常大,我們最終的目的是最小化代價值
同理 的影象如下(y=0):
的影象如下(y=0):

2、梯度
同樣對代價函式求偏導:
可以看出與線性回歸的偏導數一致
推導過程
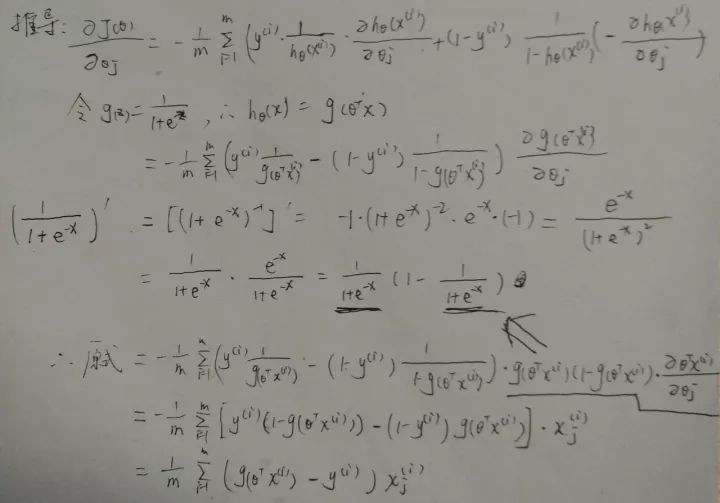
3、正則化
目的是為了防止過擬合
在代價函式中加上一項

註意j是重1開始的,因為theta(0)為一個常數項,X中最前面一列會加上1列1,所以乘積還是theta(0),feature沒有關係,沒有必要正則化
正則化後的代價:
# 代價函式
def costFunction(initial_theta,X,y,inital_lambda):
m = len(y)
J = 0
h = sigmoid(np.dot(X,initial_theta)) # 計算h(z)
theta1 = initial_theta.copy() # 因為正則化j=1從1開始,不包含0,所以複製一份,前theta(0)值為0
theta1[0] = 0
temp = np.dot(np.transpose(theta1),theta1)
J = (-np.dot(np.transpose(y),np.log(h))-np.dot(np.transpose(1-y),np.log(1-h))+temp*inital_lambda/2)/m # 正則化的代價方程
return J
正則化後的代價的梯度
# 計算梯度
def gradient(initial_theta,X,y,inital_lambda):
m = len(y)
grad = np.zeros((initial_theta.shape[0]))
h = sigmoid(np.dot(X,initial_theta))# 計算h(z)
theta1 = initial_theta.copy()
theta1[0] = 0
grad = np.dot(np.transpose(X),h-y)/m+inital_lambda/m*theta1 #正則化的梯度
return grad
4、S型函式(即)
實現程式碼:
# S型函式
def sigmoid(z):
h = np.zeros((len(z),1)) # 初始化,與z的長度一置
h = 1.0/(1.0+np.exp(-z)) return h
5、對映為多項式
因為資料的feture可能很少,導致偏差大,所以創造出一些feture結合
eg:對映為2次方的形式:
實現程式碼:
# 對映為多項式
def mapFeature(X1,X2):
degree = 3; # 對映的最高次方
out = np.ones((X1.shape[0],1)) # 對映後的結果陣列(取代X)
”’
這裡以degree=2為例,對映為1,x1,x2,x1^2,x1,x2,x2^2
”’
for i in np.arange(1,degree+1):
for j in range(i+1):
temp = X1**(i-j)*(X2**j) #矩陣直接乘相當於matlab中的點乘.*
out = np.hstack((out, temp.reshape(-1,1)))
return out
6、使用scipy的最佳化方法
梯度下降使用scipy中optimize中的fmin_bfgs函式
呼叫scipy中的最佳化演演算法fmin_bfgs(擬牛頓法Broyden-Fletcher-Goldfarb-Shanno
costFunction是自己實現的一個求代價的函式,
initial_theta表示初始化的值,
fprime指定costFunction的梯度
args是其餘測引數,以元組的形式傳入,最後會將最小化costFunction的theta傳回
result = optimize.fmin_bfgs(costFunction, initial_theta, fprime=gradient, args=(X,y,initial_lambda))
7、執行結果
data1決策邊界和準確度
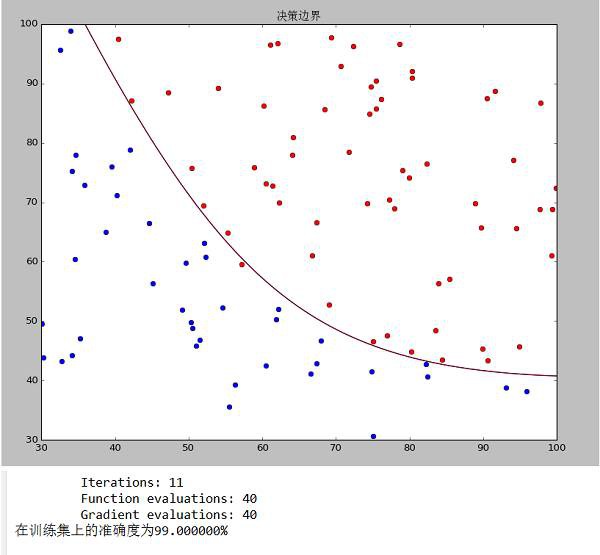
data2決策邊界和準確度

8、使用scikit-learn庫中的邏輯回歸模型實現
https://github.com/lawlite19/MachineLearning_Python/blob/master/LogisticRegression/LogisticRegression_scikit-learn.py
匯入包
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
import numpy as np
劃分訓練集和測試集
# 劃分為訓練集和測試集
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
歸一化
# 歸一化
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)
邏輯回歸
#邏輯回歸
model = LogisticRegression()
model.fit(x_train,y_train)
預測
# 預測
predict = model.predict(x_test)
right = sum(predict == y_test)
predict = np.hstack((predict.reshape(-1,1),y_test.reshape(-1,1))) # 將預測值和真實值放在一塊,好觀察
print predict
print (‘測試集準確率:%f%%’%(right*100.0/predict.shape[0])) #計算在測試集上的準確度
邏輯回歸_手寫數字識別_OneVsAll
https://github.com/lawlite19/MachineLearning_Python/blob/master/LogisticRegression
全部程式碼
https://github.com/lawlite19/MachineLearning_Python/blob/master/LogisticRegression/LogisticRegression_OneVsAll.py
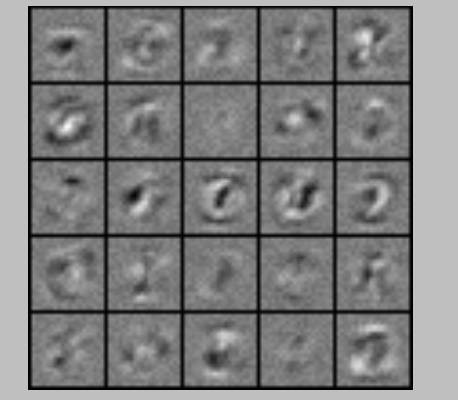
1、隨機顯示100個數字
我沒有使用scikit-learn中的資料集,畫素是20*20px,彩色圖如下

灰度圖:

實現程式碼:
# 顯示100個數字
def display_data(imgData):
sum = 0
”’
顯示100個數(若是一個一個繪製將會非常慢,可以將要畫的數字整理好,放到一個矩陣中,顯示這個矩陣即可)
– 初始化一個二維陣列
– 將每行的資料調整成影象的矩陣,放進二維陣列
– 顯示即可
”’
pad = 1
display_array = -np.ones((pad+10*(20+pad),pad+10*(20+pad)))
for i in range(10):
for j in range(10):
display_array[pad+i*(20+pad):pad+i*(20+pad)+20,pad+j*(20+pad):pad+j*(20+pad)+20] = (imgData[sum,:].reshape(20,20,order=”F”)) # order=F指定以列優先,在matlab中是這樣的,python中需要指定,預設以行
sum += 1
plt.imshow(display_array,cmap=’gray’) #顯示灰度影象
plt.axis(‘off’)
plt.show()
2、OneVsAll
如何利用邏輯回歸解決多分類的問題,OneVsAll就是把當前某一類看成一類,其他所有類別看作一類,這樣有成了二分類的問題了
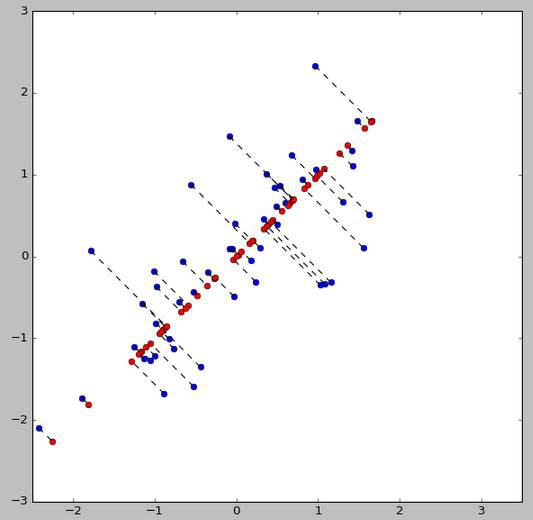
如下圖,把途中的資料分成三類,先把紅色的看成一類,把其他的看作另外一類,進行邏輯回歸,然後把藍色的看成一類,其他的再看成一類,以此類推…

可以看出大於2類的情況下,有多少類就要進行多少次的邏輯回歸分類
3、手寫數字識別
共有0-9,10個數字,需要10次分類
由於資料集y給出的是0,1,2…9的數字,而進行邏輯回歸需要0/1的label標記,所以需要對y處理
說一下資料集,前500個是0,500-1000是1,…,所以如下圖,處理後的y,前500行的第一列是1,其餘都是0,500-1000行第二列是1,其餘都是0….
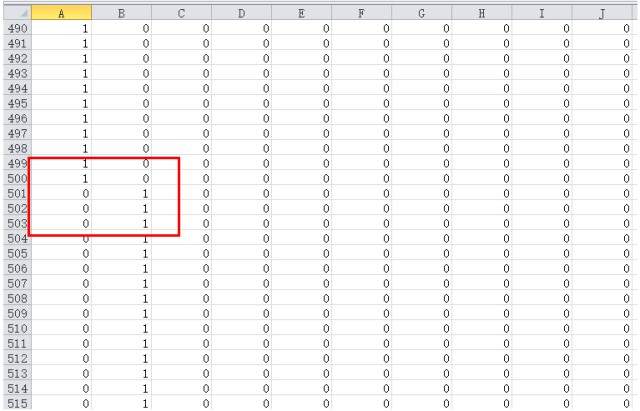
然後呼叫梯度下降演演算法求解theta
實現程式碼:
# 求每個分類的theta,最後傳回所有的all_theta
def oneVsAll(X,y,num_labels,Lambda):
# 初始化變數
m,n = X.shape
all_theta = np.zeros((n+1,num_labels)) # 每一列對應相應分類的theta,共10列
X = np.hstack((np.ones((m,1)),X)) # X前補上一列1的偏置bias
class_y = np.zeros((m,num_labels)) # 資料的y對應0-9,需要對映為0/1的關係
initial_theta = np.zeros((n+1,1)) # 初始化一個分類的theta
# 對映y
for i in range(num_labels):
class_y[:,i] = np.int32(y==i).reshape(1,-1) # 註意reshape(1,-1)才可以賦值
#np.savetxt(“class_y.csv”, class_y[0:600,:], delimiter=’,’)
”’遍歷每個分類,計算對應的theta值”’
for i in range(num_labels):
result = optimize.fmin_bfgs(costFunction, initial_theta, fprime=gradient, args=(X,class_y[:,i],Lambda)) # 呼叫梯度下降的最佳化方法
all_theta[:,i] = result.reshape(1,-1) # 放入all_theta中
all_theta = np.transpose(all_theta)
return all_theta
4、預測
之前說過,預測的結果是一個機率值,利用學習出來的theta代入預測的S型函式中,每行的最大值就是是某個數字的最大機率,所在的列號就是預測的數字的真實值,因為在分類時,所有為0的將y對映在第一列,為1的對映在第二列,依次類推
實現程式碼:
# 預測
def predict_oneVsAll(all_theta,X):
m = X.shape[0]
num_labels = all_theta.shape[0]
p = np.zeros((m,1))
X = np.hstack((np.ones((m,1)),X)) #在X最前面加一列1
h = sigmoid(np.dot(X,np.transpose(all_theta))) #預測
”’
傳回h中每一行最大值所在的列號
– np.max(h, axis=1)傳回h中每一行的最大值(是某個數字的最大機率)
– 最後where找到的最大機率所在的列號(列號即是對應的數字)
”’
p = np.array(np.where(h[0,:] == np.max(h, axis=1)[0]))
for i in np.arange(1, m):
t = np.array(np.where(h[i,:] == np.max(h, axis=1)[i]))
p = np.vstack((p,t))
return p
5、執行結果
10次分類,在訓練集上的準確度:

6、使用scikit-learn庫中的邏輯回歸模型實現
https://github.com/lawlite19/MachineLearning_Python/blob/master/LogisticRegression/LogisticRegression_OneVsAll_scikit-learn.py
1、匯入包
from scipy import io as spio
import numpy as np
from sklearn import svm
from sklearn.linear_model import LogisticRegression
2、載入資料
data = loadmat_data(“data_digits.mat”)
X = data[‘X’] # 獲取X資料,每一行對應一個數字20x20px
y = data[‘y’] # 這裡讀取mat檔案y的shape=(5000, 1)
y = np.ravel(y) # 呼叫sklearn需要轉化成一維的(5000,)
3、擬合模型
model = LogisticRegression()
model.fit(X, y) # 擬合
4、預測
predict = model.predict(X) #預測
print u”預測準確度為:%f%%”%np.mean(np.float64(predict == y)*100)
5、輸出結果(在訓練集上的準確度)

三、BP神經網路
全部程式碼
https://github.com/lawlite19/MachineLearning_Python/blob/master/NeuralNetwok/NeuralNetwork.py
1、神經網路model
先介紹個三層的神經網路,如下圖所示
輸入層(input layer)有三個units( 為補上的bias,通常設為1)
為補上的bias,通常設為1)
 表示第j層的第i個激勵,也稱為為單元unit
表示第j層的第i個激勵,也稱為為單元unit
 為第j層到第j+1層對映的權重矩陣,就是每條邊的權重
為第j層到第j+1層對映的權重矩陣,就是每條邊的權重
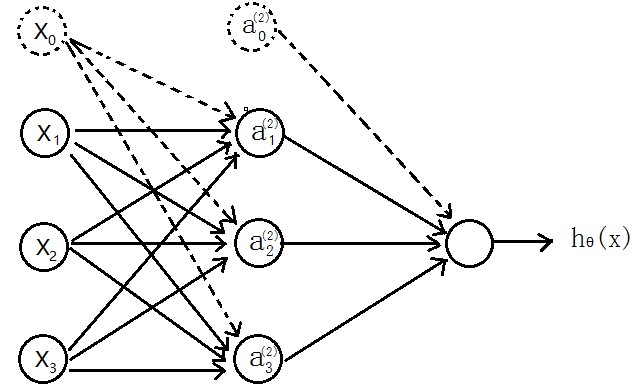
所以可以得到:
隱含層:



輸出層 ,
,
其中,S型函式 ,也成為激勵函式
,也成為激勵函式
可以看出 為3×4的矩陣,
為3×4的矩陣, 為1×4的矩陣
為1×4的矩陣
==》j+1的單元數x(j層的單元數+1)
2、代價函式
假設最後輸出的 ,即代表輸出層有K個單元
,即代表輸出層有K個單元
 ,
,
其中, 代表第i個單元輸出與邏輯回歸的代價函式
代表第i個單元輸出與邏輯回歸的代價函式
差不多,就是累加上每個輸出(共有K個輸出)
3、正則化
L–>所有層的個數
 –>第l層unit的個數
–>第l層unit的個數
正則化後的代價函式為
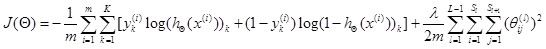
 共有L-1層,然後是累加對應每一層的theta矩陣,註意不包含加上偏置項對應的theta(0)
共有L-1層,然後是累加對應每一層的theta矩陣,註意不包含加上偏置項對應的theta(0)
正則化後的代價函式實現程式碼:
# 代價函式
def nnCostFunction(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda):
length = nn_params.shape[0] # theta的中長度
# 還原theta1和theta2
Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1)
Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1)
# np.savetxt(“Theta1.csv”,Theta1,delimiter=’,’)
m = X.shape[0]
class_y = np.zeros((m,num_labels)) # 資料的y對應0-9,需要對映為0/1的關係
# 對映y
for i in range(num_labels):
class_y[:,i] = np.int32(y==i).reshape(1,-1) # 註意reshape(1,-1)才可以賦值
”’去掉theta1和theta2的第一列,因為正則化時從1開始”’
Theta1_colCount = Theta1.shape[1]
Theta1_x = Theta1[:,1:Theta1_colCount]
Theta2_colCount = Theta2.shape[1]
Theta2_x = Theta2[:,1:Theta2_colCount]
# 正則化向theta^2
term = np.dot(np.transpose(np.vstack((Theta1_x.reshape(-1,1),Theta2_x.reshape(-1,1)))),np.vstack((Theta1_x.reshape(-1,1),Theta2_x.reshape(-1,1))))
”’正向傳播,每次需要補上一列1的偏置bias”’
a1 = np.hstack((np.ones((m,1)),X))
z2 = np.dot(a1,np.transpose(Theta1))
a2 = sigmoid(z2)
a2 = np.hstack((np.ones((m,1)),a2))
z3 = np.dot(a2,np.transpose(Theta2))
h = sigmoid(z3)
”’代價”’
J = -(np.dot(np.transpose(class_y.reshape(-1,1)),np.log(h.reshape(-1,1)))+np.dot(np.transpose(1-class_y.reshape(-1,1)),np.log(1-h.reshape(-1,1)))-Lambda*term/2)/m
return np.ravel(J)
4、反向傳播BP
上面正向傳播可以計算得到J(θ),使用梯度下降法還需要求它的梯度
BP反向傳播的目的就是求代價函式的梯度
假設4層的神經網路, 記為–>l層第j個單元的誤差
記為–>l層第j個單元的誤差
 《===》
《===》 (向量化)
(向量化)


沒有 ,因為對於輸入沒有誤差
,因為對於輸入沒有誤差
因為S型函式 的倒數為:
的倒數為:
 ,
,
所以上面的 和
和 可以在前向傳播中計算出來
可以在前向傳播中計算出來
反向傳播計算梯度的過程為:
 (
( 是大寫的
是大寫的 )
)
for i=1-m:-

-正向傳播計算 (l=2,3,4…L)
(l=2,3,4…L)
-反向計算 、
、 …
… ;
;
–
–

最後 ,即得到代價函式的梯度
,即得到代價函式的梯度
實現程式碼:
# 梯度
def nnGradient(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda):
length = nn_params.shape[0]
Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1)
Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1)
m = X.shape[0]
class_y = np.zeros((m,num_labels)) # 資料的y對應0-9,需要對映為0/1的關係
# 對映y
for i in range(num_labels):
class_y[:,i] = np.int32(y==i).reshape(1,-1) # 註意reshape(1,-1)才可以賦值
”’去掉theta1和theta2的第一列,因為正則化時從1開始”’
Theta1_colCount = Theta1.shape[1]
Theta1_x = Theta1[:,1:Theta1_colCount]
Theta2_colCount = Theta2.shape[1]
Theta2_x = Theta2[:,1:Theta2_colCount]
Theta1_grad = np.zeros((Theta1.shape)) #第一層到第二層的權重
Theta2_grad = np.zeros((Theta2.shape)) #第二層到第三層的權重
Theta1[:,0] = 0;
Theta2[:,0] = 0;
”’正向傳播,每次需要補上一列1的偏置bias”’
a1 = np.hstack((np.ones((m,1)),X))
z2 = np.dot(a1,np.transpose(Theta1))
a2 = sigmoid(z2)
a2 = np.hstack((np.ones((m,1)),a2))
z3 = np.dot(a2,np.transpose(Theta2))
h = sigmoid(z3)
”’反向傳播,delta為誤差,”’
delta3 = np.zeros((m,num_labels))
delta2 = np.zeros((m,hidden_layer_size))
for i in range(m):
delta3[i,:] = h[i,:]-class_y[i,:]
Theta2_grad = Theta2_grad+np.dot(np.transpose(delta3[i,:].reshape(1,-1)),a2[i,:].reshape(1,-1))
delta2[i,:] = np.dot(delta3[i,:].reshape(1,-1),Theta2_x)*sigmoidGradient(z2[i,:])
Theta1_grad = Theta1_grad+np.dot(np.transpose(delta2[i,:].reshape(1,-1)),a1[i,:].reshape(1,-1))
”’梯度”’
grad = (np.vstack((Theta1_grad.reshape(-1,1),Theta2_grad.reshape(-1,1)))+Lambda*np.vstack((Theta1.reshape(-1,1),Theta2.reshape(-1,1))))/m
return np.ravel(grad)
5、BP可以求梯度的原因
實際是利用了鏈式求導法則
因為下一層的單元利用上一層的單元作為輸入進行計算
大體的推導過程如下,最終我們是想預測函式與已知的y非常接近,求均方差的梯度沿著此梯度方向可使代價函式最小化。可對照上面求梯度的過程。

求誤差更詳細的推導過程:

6、梯度檢查
檢查利用BP求的梯度是否正確
利用導數的定義驗證: 
求出來的數值梯度應該與BP求出的梯度非常接近
驗證BP正確後就不需要再執行驗證梯度的演演算法了
實現程式碼:
# 檢驗梯度是否計算正確
# 檢驗梯度是否計算正確
def checkGradient(Lambda = 0):
”’構造一個小型的神經網路驗證,因為數值法計算梯度很浪費時間,而且驗證正確後之後就不再需要驗證了”’
input_layer_size = 3
hidden_layer_size = 5
num_labels = 3
m = 5
initial_Theta1 = debugInitializeWeights(input_layer_size,hidden_layer_size);
initial_Theta2 = debugInitializeWeights(hidden_layer_size,num_labels)
X = debugInitializeWeights(input_layer_size-1,m)
y = 1+np.transpose(np.mod(np.arange(1,m+1), num_labels))# 初始化y
y = y.reshape(-1,1)
nn_params = np.vstack((initial_Theta1.reshape(-1,1),initial_Theta2.reshape(-1,1))) #展開theta
”’BP求出梯度”’
grad = nnGradient(nn_params, input_layer_size, hidden_layer_size,
num_labels, X, y, Lambda)
”’使用數值法計算梯度”’
num_grad = np.zeros((nn_params.shape[0]))
step = np.zeros((nn_params.shape[0]))
e = 1e-4
for i in range(nn_params.shape[0]):
step[i] = e
loss1 = nnCostFunction(nn_params-step.reshape(-1,1), input_layer_size, hidden_layer_size,
num_labels, X, y,
Lambda)
loss2 = nnCostFunction(nn_params+step.reshape(-1,1), input_layer_size, hidden_layer_size,
num_labels, X, y,
Lambda)
num_grad[i] = (loss2-loss1)/(2*e)
step[i]=0
# 顯示兩列比較
res = np.hstack((num_grad.reshape(-1,1),grad.reshape(-1,1)))
print res
7、權重的隨機初始化
神經網路不能像邏輯回歸那樣初始化theta為0,因為若是每條邊的權重都為0,每個神經元都是相同的輸出,在反向傳播中也會得到同樣的梯度,最終只會預測一種結果。
所以應該初始化為接近0的數
實現程式碼
# 隨機初始化權重theta
def randInitializeWeights(L_in,L_out):
W = np.zeros((L_out,1+L_in)) # 對應theta的權重
epsilon_init = (6.0/(L_out+L_in))**0.5
W = np.random.rand(L_out,1+L_in)*2*epsilon_init-epsilon_init # np.random.rand(L_out,1+L_in)產生L_out*(1+L_in)大小的隨機矩陣
return W
8、預測
正向傳播預測結果
實現程式碼
# 預測
def predict(Theta1,Theta2,X):
m = X.shape[0]
num_labels = Theta2.shape[0]
#p = np.zeros((m,1))
”’正向傳播,預測結果”’
X = np.hstack((np.ones((m,1)),X))
h1 = sigmoid(np.dot(X,np.transpose(Theta1)))
h1 = np.hstack((np.ones((m,1)),h1))
h2 = sigmoid(np.dot(h1,np.transpose(Theta2)))
”’
傳回h中每一行最大值所在的列號
– np.max(h, axis=1)傳回h中每一行的最大值(是某個數字的最大機率)
– 最後where找到的最大機率所在的列號(列號即是對應的數字)
”’
#np.savetxt(“h2.csv”,h2,delimiter=’,’)
p = np.array(np.where(h2[0,:] == np.max(h2, axis=1)[0]))
for i in np.arange(1, m):
t = np.array(np.where(h2[i,:] == np.max(h2, axis=1)[i]))
p = np.vstack((p,t))
return p
9、輸出結果
梯度檢查:

隨機顯示100個手寫數字

顯示theta1權重
訓練集預測準確度

歸一化後訓練集預測準確度

四、SVM支援向量機
1、代價函式
在邏輯回歸中,我們的代價為:
 ,
,
其中:
 ,
,
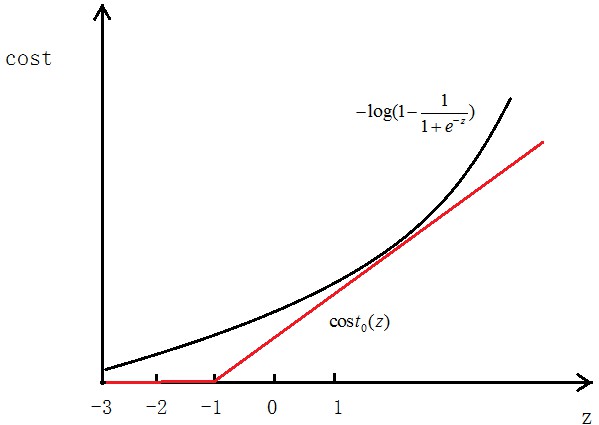
如圖所示,如果y=1,cost代價函式如圖所示

我們想讓 ,即z>>0,這樣的話cost代價函式才會趨於最小(這是我們想要的),所以用途中紅色的函式
,即z>>0,這樣的話cost代價函式才會趨於最小(這是我們想要的),所以用途中紅色的函式 代替邏輯回歸中的cost
代替邏輯回歸中的cost
當y=0時同樣,用 代替
代替
最終得到的代價函式為:

最後我們想要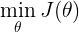
之前我們邏輯回歸中的代價函式為:
可以認為這裡的 ,只是表達形式問題,這裡C的值越大,SVM的決策邊界的margin也越大,下麵會說明
,只是表達形式問題,這裡C的值越大,SVM的決策邊界的margin也越大,下麵會說明
2、Large Margin
如下圖所示,SVM分類會使用最大的margin將其分開

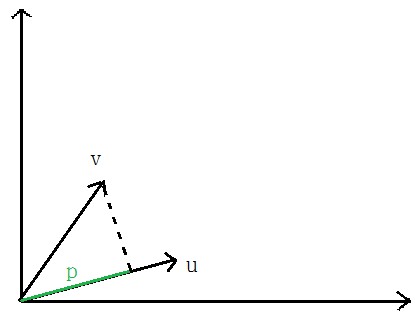
先說一下向量內積
 ,
,
 表示u的歐幾裡得範數(歐式範數),
表示u的歐幾裡得範數(歐式範數),
向量V在向量u上的投影的長度記為p,則:向量內積:

根據向量夾角公式推導一下即可,
前面說過,當C越大時,margin也就越大,我們的目的是最小化代價函式J(θ),當margin最大時,C的乘積項

要很小,所以近似為:
 ,
,
我們最後的目的就是求使代價最小的θ
由

可以得到:
 ,
,
p即為x在θ上的投影
如下圖所示,假設決策邊界如圖,找其中的一個點,到θ上的投影為p,則 或者
或者 ,若是p很小,則需要
,若是p很小,則需要 很大,這與我們要求的θ使
很大,這與我們要求的θ使 最小相違背,所以最後求的是large margin
最小相違背,所以最後求的是large margin
3、SVM Kernel(核函式)
對於線性可分的問題,使用線性核函式即可
對於線性不可分的問題,在邏輯回歸中,我們是將feature對映為使用多項式的形式,SVM中也有多項式核函式,但是更常用的是高斯核函式,也稱為RBF核
高斯核函式為:
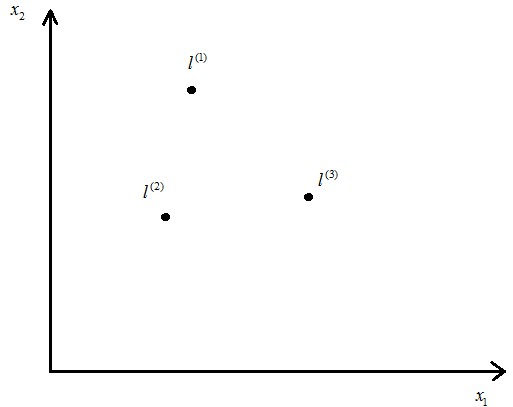
假設如圖幾個點,
令:
 ,
,
. . .
可以看出,若是x與 距離較近,==》
距離較近,==》 ,(即相似度較大),若是x與距離較遠,==》
,(即相似度較大),若是x與距離較遠,==》 ,(即相似度較低)
,(即相似度較低)
高斯核函式的σ越小,f下降的越快
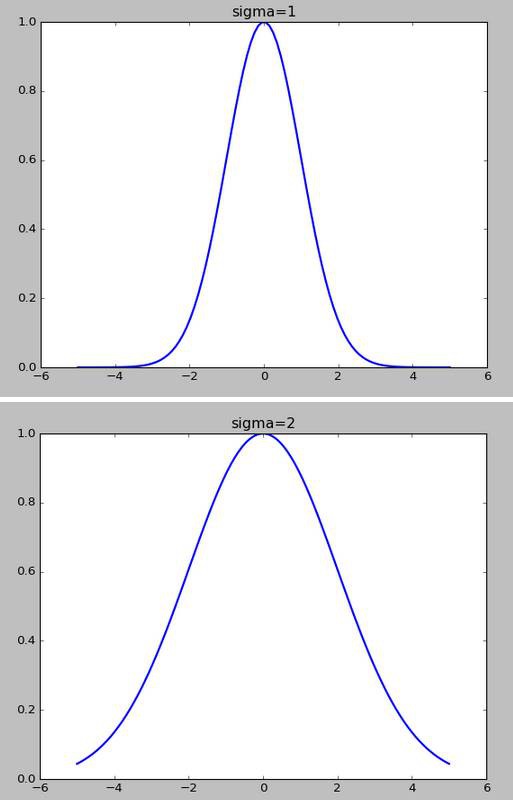
如何選擇初始的
訓練集:
選擇:
對於給出的x,計算f,令: ,
,
所以:
最小化J求出θ,

如果 ,==》預測y=1
,==》預測y=1
4、使用scikit-learn中的SVM模型程式碼
全部程式碼
https://github.com/lawlite19/MachineLearning_Python/blob/master/SVM/SVM_scikit-learn.py
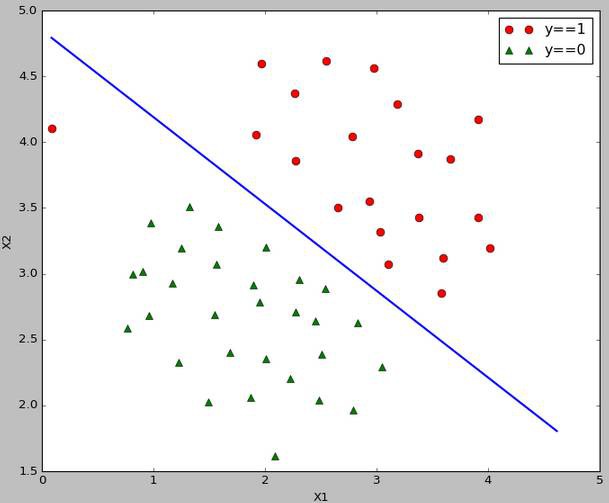
線性可分的,指定核函式為linear:
”’data1——線性分類”’
data1 = spio.loadmat(‘data1.mat’)
X = data1[‘X’]
y = data1[‘y’]
y = np.ravel(y)
plot_data(X,y)
model = svm.SVC(C=1.0,kernel=’linear’).fit(X,y) # 指定核函式為線性核函式
非線性可分的,預設核函式為rbf
”’data2——非線性分類”’
data2 = spio.loadmat(‘data2.mat’)
X = data2[‘X’]
y = data2[‘y’]
y = np.ravel(y)
plt = plot_data(X,y)
plt.show()
model = svm.SVC(gamma=100).fit(X,y) # gamma為核函式的繫數,值越大擬合的越好
5、執行結果
線性可分的決策邊界:
線性不可分的決策邊界:

五、K-Means聚類演演算法
全部程式碼
https://github.com/lawlite19/MachineLearning_Python/blob/master/K-Means/K-Menas.py
1、聚類過程
聚類屬於無監督學習,不知道y的標記分為K類
K-Means演演算法分為兩個步驟
第一步:簇分配,隨機選K個點作為中心,計算到這K個點的距離,分為K個簇
第二步:移動聚類中心:重新計算每個簇的中心,移動中心,重覆以上步驟。
如下圖所示:
隨機分配的聚類中心

重新計算聚類中心,移動一次
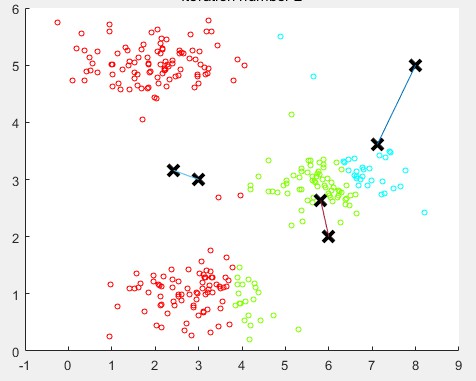
最後10步之後的聚類中心

計算每條資料到哪個中心最近實現程式碼:
# 找到每條資料距離哪個類中心最近
def findClosestCentroids(X,initial_centroids):
m = X.shape[0] # 資料條數
K = initial_centroids.shape[0] # 類的總數
dis = np.zeros((m,K)) # 儲存計算每個點分別到K個類的距離
idx = np.zeros((m,1)) # 要傳回的每條資料屬於哪個類
”’計算每個點到每個類中心的距離”’
for i in range(m):
for j in range(K):
dis[i,j] = np.dot((X[i,:]-initial_centroids[j,:]).reshape(1,-1),(X[i,:]-initial_centroids[j,:]).reshape(-1,1))
”’傳回dis每一行的最小值對應的列號,即為對應的類別
– np.min(dis, axis=1)傳回每一行的最小值
– np.where(dis == np.min(dis, axis=1).reshape(-1,1)) 傳回對應最小值的坐標
– 註意:可能最小值對應的坐標有多個,where都會找出來,所以傳回時傳回前m個需要的即可(因為對於多個最小值,屬於哪個類別都可以)
”’
dummy,idx = np.where(dis == np.min(dis, axis=1).reshape(-1,1))
return idx[0:dis.shape[0]] # 註意擷取一下
計算類中心實現程式碼:
# 計算類中心
def computerCentroids(X,idx,K):
n = X.shape[1]
centroids = np.zeros((K,n))
for i in range(K):
centroids[i,:] = np.mean(X[np.ravel(idx==i),:], axis=0).reshape(1,-1) # 索引要是一維的,axis=0為每一列,idx==i一次找出屬於哪一類的,然後計算均值
return centroids
2、標的函式
也叫做失真代價函式

最後我們想得到: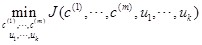
其中 表示第i條資料距離哪個類中心最近,其中
表示第i條資料距離哪個類中心最近,其中 即為聚類的中心
即為聚類的中心
3、聚類中心的選擇
隨機初始化,從給定的資料中隨機抽取K個作為聚類中心
隨機一次的結果可能不好,可以隨機多次,最後取使代價函式最小的作為中心
實現程式碼:(這裡隨機一次)
# 初始化類中心–隨機取K個點作為聚類中心
def kMeansInitCentroids(X,K):
m = X.shape[0]
m_arr = np.arange(0,m) # 生成0-m-1
centroids = np.zeros((K,X.shape[1]))
np.random.shuffle(m_arr) # 打亂m_arr順序
rand_indices = m_arr[:K] # 取前K個
centroids = X[rand_indices,:]
return centroids
4、聚類個數K的選擇
聚類是不知道y的label的,所以不知道真正的聚類個數
肘部法則(Elbow method)
作代價函式J和K的圖,若是出現一個拐點,如下圖所示,K就取拐點處的值,下圖此時K=3

若是很平滑就不明確,人為選擇。
第二種就是人為觀察選擇
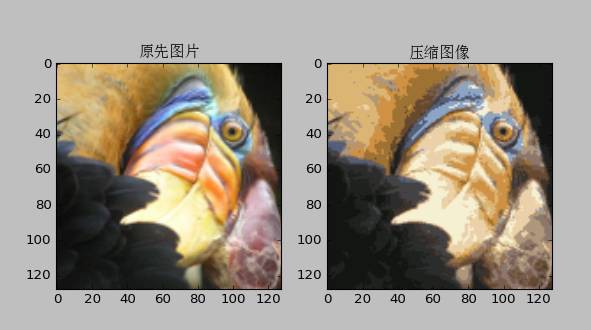
5、應用——圖片壓縮
將圖片的畫素分為若干類,然後用這個類代替原來的畫素值
執行聚類的演演算法程式碼:
# 聚類演演算法
def runKMeans(X,initial_centroids,max_iters,plot_process):
m,n = X.shape # 資料條數和維度
K = initial_centroids.shape[0] # 類數
centroids = initial_centroids # 記錄當前類中心
previous_centroids = centroids # 記錄上一次類中心
idx = np.zeros((m,1)) # 每條資料屬於哪個類
for i in range(max_iters): # 迭代次數
print u’迭代計算次數:%d’%(i+1)
idx = findClosestCentroids(X, centroids)
if plot_process: # 如果繪製影象
plt = plotProcessKMeans(X,centroids,previous_centroids) # 畫聚類中心的移動過程
previous_centroids = centroids # 重置
centroids = computerCentroids(X, idx, K) # 重新計算類中心
if plot_process: # 顯示最終的繪製結果
plt.show()
return centroids,idx # 傳回聚類中心和資料屬於哪個類
6、使用scikit-learn庫中的線性模型實現聚類
https://github.com/lawlite19/MachineLearning_Python/blob/master/K-Means/K-Means_scikit-learn.py
匯入包
from sklearn.cluster import KMeans
使用模型擬合資料
model = KMeans(n_clusters=3).fit(X) # n_clusters指定3類,擬合資料
聚類中心
centroids = model.cluster_centers_ # 聚類中心
7、執行結果
二維資料類中心的移動

圖片壓縮
六、PCA主成分分析(降維)
全部程式碼
https://github.com/lawlite19/MachineLearning_Python/blob/master/PCA/PCA.py
1、用處
資料壓縮(Data Compression),使程式執行更快
視覺化資料,例如3D–>2D等
……
2、2D–>1D,nD–>kD
如下圖所示,所有資料點可以投影到一條直線,是投影距離的平方和(投影誤差)最小

註意資料需要歸一化處理
思路是找1個向量u,所有資料投影到上面使投影距離最小
那麼nD–>kD就是找k個向量 ,
,
所有資料投影到上面使投影誤差最小
eg:3D–>2D,2個向量
就代表一個平面了,所有點投影到這個平面的投影誤差最小即可
3、主成分分析PCA與線性回歸的區別
線性回歸是找x與y的關係,然後用於預測y
PCA是找一個投影面,最小化data到這個投影面的投影誤差
4、PCA降維過程
資料預處理(均值歸一化)
公式:
就是減去對應feature的均值,然後除以對應特徵的標準差(也可以是最大值-最小值)
實現程式碼:
# 歸一化資料
def featureNormalize(X):
”’(每一個資料-當前列的均值)/當前列的標準差”’
n = X.shape[1]
mu = np.zeros((1,n));
sigma = np.zeros((1,n))
mu = np.mean(X,axis=0)
sigma = np.std(X,axis=0)
for i in range(n):
X[:,i] = (X[:,i]-mu[i])/sigma[i]
return X,mu,sigma
計算協方差矩陣Σ(Covariance Matrix):
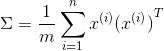
註意這裡的Σ和求和符號不同
協方差矩陣對稱正定(不理解正定的看看線代)
大小為nxn,n為feature的維度
實現程式碼:
Sigma = np.dot(np.transpose(X_norm),X_norm)/m # 求Sigma
計算Σ的特徵值和特徵向量
可以是用svd奇異值分解函式:U,S,V = svd(Σ)
傳回的是與Σ同樣大小的對角陣S(由Σ的特徵值組成)[註意:matlab中函式傳回的是對角陣,在python中傳回的是一個向量,節省空間]
還有兩個酉矩陣U和V,且

註意:svd函式求出的S是按特徵值降序排列的,若不是使用svd,需要按特徵值大小重新排列U
降維
選取U中的前K列(假設要降為K維)

Z就是對應降維之後的資料
實現程式碼:
# 對映資料
def projectData(X_norm,U,K):
Z = np.zeros((X_norm.shape[0],K))
U_reduce = U[:,0:K] # 取前K個
Z = np.dot(X_norm,U_reduce)
return Z
過程總結:
Sigma = X’*X/m
U,S,V = svd(Sigma)
Ureduce = U[:,0:k]
Z = Ureduce’*x
5、資料恢復
因為: ,
,
所以: (註意這裡是X的近似值)
(註意這裡是X的近似值)
又因為Ureduce為正定矩陣,【正定矩陣滿足: ,所以:
,所以: 】,
】,
所以這裡:
實現程式碼:
# 恢復資料
def recoverData(Z,U,K):
X_rec = np.zeros((Z.shape[0],U.shape[0]))
U_recude = U[:,0:K]
X_rec = np.dot(Z,np.transpose(U_recude)) # 還原資料(近似)
return X_rec
6、主成分個數的選擇(即要降的維度)
如何選擇
投影誤差(project error):
總變差(total variation):
若誤差率(error ratio): ,則稱99%保留差異性
,則稱99%保留差異性
誤差率一般取1%,5%,10%等
如何實現
若是一個個試的話代價太大
之前U,S,V = svd(Sigma),我們得到了S,這裡誤差率error ratio:
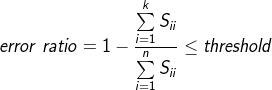
可以一點點增加K嘗試。
7、使用建議
不要使用PCA去解決過擬合問題Overfitting,還是使用正則化的方法(如果保留了很高的差異性還是可以的)
只有在原資料上有好的結果,但是執行很慢,才考慮使用PCA
8、執行結果
2維資料降為1維
要投影的方向

2D降為1D及對應關係
人臉資料降維
原始資料

視覺化部分U矩陣資訊

恢復資料

9、使用scikit-learn庫中的PCA實現降維
https://github.com/lawlite19/MachineLearning_Python/blob/master/PCA/PCA.py_scikit-learn.py
匯入需要的包:
#-*- coding: utf-8 -*-
# Author:bob
# Date:2016.12.22
import numpy as np
from matplotlib import pyplot as plt
from scipy import io as spio
from sklearn.decomposition import pca
from sklearn.preprocessing import StandardScaler
歸一化資料
”’歸一化資料並作圖”’
scaler = StandardScaler()
scaler.fit(X)
x_train = scaler.transform(X)
使用PCA模型擬合資料,並降維
n_components對應要將的維度
”’擬合資料”’
K=1 # 要降的維度
model = pca.PCA(n_components=K).fit(x_train) # 擬合資料,n_components定義要降的維度
Z = model.transform(x_train) # transform就會執行降維操作
資料恢復
model.components_會得到降維使用的U矩陣
”’資料恢復並作圖”’
Ureduce = model.components_ # 得到降維用的Ureduce
x_rec = np.dot(Z,Ureduce) # 資料恢復
七、異常檢測 Anomaly Detection
全部程式碼
https://github.com/lawlite19/MachineLearning_Python/blob/master/AnomalyDetection/AnomalyDetection.py
1、高斯分佈(正態分佈)Gaussian distribution
分佈函式: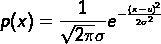
其中,u為資料的均值,σ為資料的標準差
σ越小,對應的影象越尖
引數估計(parameter estimation)


2、異常檢測演演算法
例子
訓練集: ,其中
,其中
假設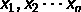
相互獨立,建立model模型:
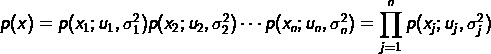
過程
選擇具有代表異常的feature:xi
引數估計:
計算p(x),若是P(x)
這裡只是單元高斯分佈,假設了feature之間是獨立的,下麵會講到多元高斯分佈,會自動捕捉到feature之間的關係
引數估計實現程式碼
# 引數估計函式(就是求均值和方差)
def estimateGaussian(X):
m,n = X.shape
mu = np.zeros((n,1))
sigma2 = np.zeros((n,1))
mu = np.mean(X, axis=0) # axis=0表示列,每列的均值
sigma2 = np.var(X,axis=0) # 求每列的方差
return mu,sigma2
3、評價p(x)的好壞,以及ε的選取
對偏斜資料的錯誤度量
因為資料可能是非常偏斜的(就是y=1的個數非常少,(y=1表示異常)),所以可以使用Precision/Recall,計算F1Score(在CV交叉驗證集上)
例如:預測癌症,假設模型可以得到99%能夠預測正確,1%的錯誤率,但是實際癌症的機率很小,只有0.5%,那麼我們始終預測沒有癌症y=0反而可以得到更小的錯誤率。使用error rate來評估就不科學了。
如下圖記錄:

 ,即:正確預測正樣本/所有預測正樣本
,即:正確預測正樣本/所有預測正樣本
 ,即:正確預測正樣本/真實值為正樣本
,即:正確預測正樣本/真實值為正樣本
總是讓y=1(較少的類),計算Precision和Recall

還是以癌症預測為例,假設預測都是no-cancer,TN=199,FN=1,TP=0,FP=0,所以:Precision=0/0,Recall=0/1=0,儘管accuracy=199/200=99.5%,但是不可信。
ε的選取
嘗試多個ε值,使F1Score的值高
實現程式碼
# 選擇最優的epsilon,即:使F1Score最大
def selectThreshold(yval,pval):
”’初始化所需變數”’
bestEpsilon = 0.
bestF1 = 0.
F1 = 0.
step = (np.max(pval)-np.min(pval))/1000
”’計算”’
for epsilon in np.arange(np.min(pval),np.max(pval),step):
cvPrecision = pval
tp = np.sum((cvPrecision == 1) & (yval == 1)).astype(float) # sum求和是int型的,需要轉為float
fp = np.sum((cvPrecision == 1) & (yval == 0)).astype(float)
fn = np.sum((cvPrecision == 1) & (yval == 0)).astype(float)
precision = tp/(tp+fp) # 精準度
recision = tp/(tp+fn) # 召回率
F1 = (2*precision*recision)/(precision+recision) # F1Score計算公式
if F1 > bestF1: # 修改最優的F1 Score
bestF1 = F1
bestEpsilon = epsilon
return bestEpsilon,bestF1
4、選擇使用什麼樣的feature(單元高斯分佈)
如果一些資料不是滿足高斯分佈的,可以變化一下資料,例如log(x+C),x^(1/2)等
如果p(x)的值無論異常與否都很大,可以嘗試組合多個feature,(因為feature之間可能是有關係的)
5、多元高斯分佈
單元高斯分佈存在的問題
如下圖,紅色的點為異常點,其他的都是正常點(比如CPU和memory的變化)

x1對應的高斯分佈如下:

x2對應的高斯分佈如下:
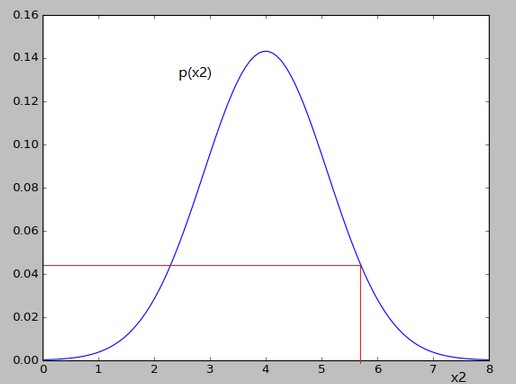
可以看出對應的p(x1)和p(x2)的值變化並不大,就不會認為異常
因為我們認為feature之間是相互獨立的,所以如上圖是以正圓的方式擴充套件
多元高斯分佈
,並不是建立p(x1),p(x2)…p(xn),而是統一建立p(x)
其中引數: ,Σ為協方差矩陣
,Σ為協方差矩陣
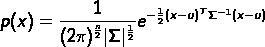
同樣,|Σ|越小,p(x)越尖
例如:
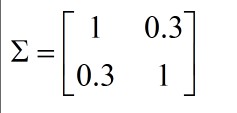 ,
,
表示x1,x2正相關,即x1越大,x2也就越大,如下圖,也就可以將紅色的異常點檢查出了

若:

表示x1,x2負相關
實現程式碼:
# 多元高斯分佈函式
def multivariateGaussian(X,mu,Sigma2):
k = len(mu)
if (Sigma2.shape[0]>1):
Sigma2 = np.diag(Sigma2)
”’多元高斯分佈函式”’
X = X-mu
argu = (2*np.pi)**(-k/2)*np.linalg.det(Sigma2)**(-0.5)
p = argu*np.exp(-0.5*np.sum(np.dot(X,np.linalg.inv(Sigma2))*X,axis=1)) # axis表示每行
return p
6、單元和多元高斯分佈特點
單元高斯分佈
人為可以捕捉到feature之間的關係時可以使用
計算量小
多元高斯分佈
自動捕捉到相關的feature
計算量大,因為:
m>n或Σ可逆時可以使用。(若不可逆,可能有冗餘的x,因為線性相關,不可逆,或者就是m
7、程式執行結果
顯示資料
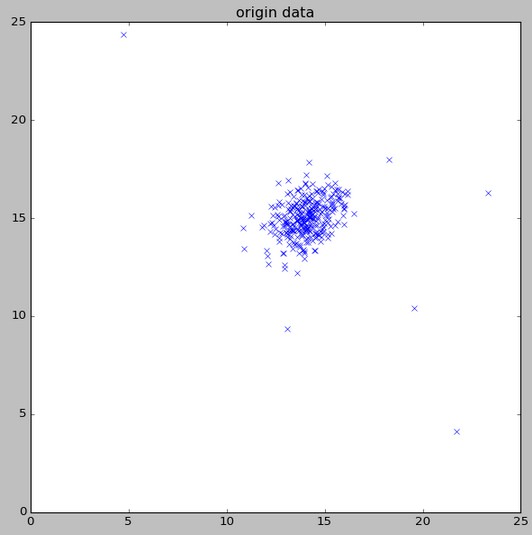
等高線

異常點標註

原文地址
https://github.com/lawlite19/MachineLearning_Python#
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
