
本文將具體介紹如何利用Python的影象處理模組pillow和OCR模組pytesseract來識別上述驗證碼(數字加字母)。
我們識別上述驗證碼的演演算法過程如下:
這裡還有小編準備的一份python學習資料,加小編QQ群:696541369即可獲取!

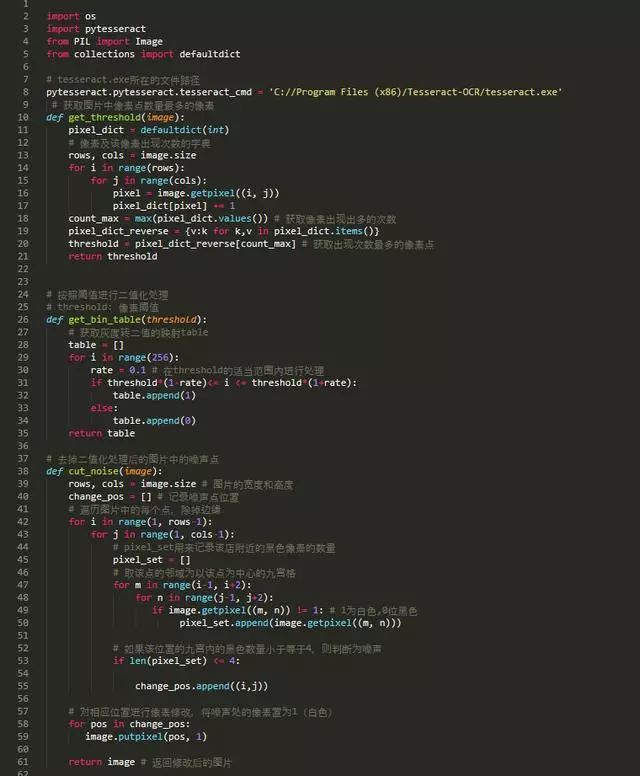
將原影象進行灰度處理,轉化為灰度影象;
獲取圖片中畫素點數量最多的畫素(此為圖片背景),將該畫素作為閾值進行二值化處理,將灰度影象轉化為黑白影象(用來提高識別的準確率);
去掉黑白影象中的噪聲,噪聲定義為:以該點為中心的九宮格的黑點的數量小於等於4;
利用pytesseract模組識別,去掉識別結果中的特殊字元,獲得識別結果。
我們的圖片如下(共66張圖片):

完整的Python程式碼如下:
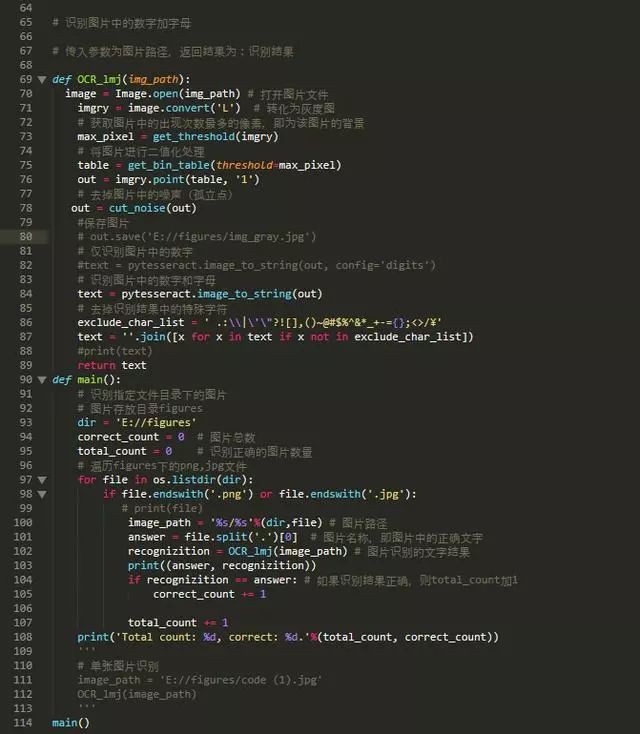
執行結果如下:



我們可以看到圖片識別的正確率為80%以上,其中數字類圖片的識別正確率為100%.
我們可以在圖片識別方面的演演算法再加改進,以提高圖片識別的正確率。當然,以上演演算法並不是對所有驗證碼都適用,不同的驗證碼需要用不同的圖片處理演演算法。

