

使用requests庫和BeautifulSoup庫
標的網站:妹子圖
今天是對於單個圖集的爬取,就選擇一個進行爬取,我選擇的連結為:http://www.mzitu.com/123114
首先網站的分析,該網站有一定的反爬蟲策略,所以應對就是加入essay-headers(目前是小白,目前不知道具體為毛這樣做)
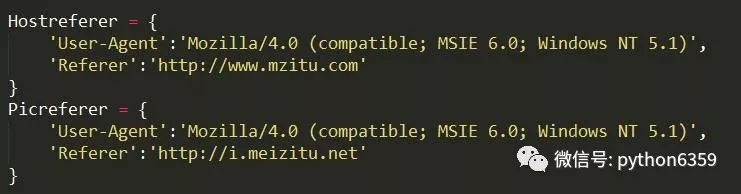
前一個頭作為請求網站,後一個頭作為破解盜鏈使用
獲取頁面HTML程式碼
用requests庫的get方法,加上Hostreferer

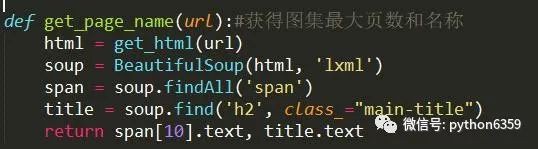
獲得圖集名稱以及圖集最大頁數
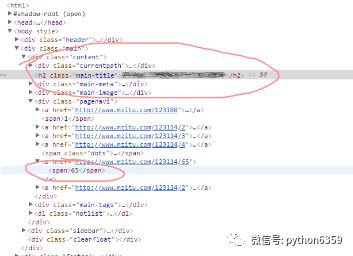
分析網頁構成如圖所示,圖集名稱包含在h2標簽內,且該標簽在整個HTML程式碼裡有唯一的class=”main-title”
而最大頁數只是被span標簽包含,無法透過屬性來提取。所以提取圖集名稱採取標簽名+屬性名一起提取,而最大頁數就採取將span標簽全部找出,最大頁數在span標簽中第11位
獲取圖片url連結
分析頁面內容,含有圖片連結的img標簽中有一個alt屬性的值是跟圖集名稱相同,可以用這個來直接找到這個標簽,當然也可以先找到div標簽中的class屬性是main-inage,再找到img的src屬性,這裡我就採用第一種方法。


將圖片存入本地
得到圖片url連結之後要講圖片存到本地,在請求圖片url的時候要加入Picreferer,否則網站會認為你是一個爬蟲,會返還給你一個盜鏈圖
該方法傳入的引數有3個,第一個是圖片url,第二個當前圖片的頁數,用作建立檔案,第三個是圖集名稱,在儲存之前先建立了一個名稱是圖集名稱的檔案夾,這樣就能將圖片存入指定檔案夾

程式碼

在main方法中先請求到圖集的名稱和最大頁數,並且使用名稱建立一個檔案夾來儲存圖片。再從1到最大頁數做一個for迴圈,
然後圖片的每一頁是 圖集首頁 + / + 當前頁數,得到含有圖片內容的url連結,後面就可以將得到圖片存入本地。
爬取結果



作者:風過殺戮
源自:www.cnblogs.com/forever-snow/p/8506746.html
宣告:文章著作權歸作者所有,如有侵權,請聯絡小編刪除
