本文作者,紀勇,花名竹箐,螞蟻金服技術專家。
2014 年加入螞蟻金服,前期主要負責快取中介軟體,多次參與保障雙十一大促穩定性。近一年主要負責 Light 鏈路的建設,構建準確、高效、實時的 DB 資料採集鏈路。
本文根據《2019 新春支付寶紅包技術大揭秘》線上峰會分享整理,關於本次分享更多主題,可以詳見文末回顧連結。

前言
五福走到今年已經是第四年了,有 1 億人從第一年就開始集五福,連續三年都參加。今年超過 4.5 億人參與,每 3 個中國人就有 1 個在集福送福。
新春紅包極速核對資料傳輸之戰,其實想和大家談談資料傳輸鏈路做了哪些最佳化和改進來滿足新船紅包的極速核對需求的。
首先一個問題:

相信大部分人今年都集齊了五福。在 2016 年支付寶紅包首次推出新春紅包的時候,敬業福發放的較少,最終只有不到 80W 人集齊了五福,當時還有很多關於敬業福的段子,最終這些幸運兒平分了 2.15 億的獎金。紅包活動的玩法在最近幾年也發生了比較大的改變,2019 年參與五福的人數達到了 4.5 億人左右,同時獎金也是用拼手氣的方式進行發放的。
五福紅包從大驚喜向小確幸的轉變,同時帶來了五福紅包對技術的挑戰:
-
第一資料量增加了上百倍。從 80W 到 4.5 億。
-
第二計算金額的邏輯也相對比較複雜。從均分紅包到現在的隨機發放。
活動複雜度的增加讓核對變得更加關鍵了。核對就像是業務的保護傘一樣,在業務發生前以及業務發生後都保護著業務:在業務發生前防止異常業務的推進;在業務發生後及時報告異常業務,儘快止血。
背景
我們首先瞭解一下核對的基本實現,一般來說核對主要有兩個依賴:
-
資料鏈路
-
計算能力
即核對系統首先透過資料鏈路獲取核對業務所需的資料,然後透過計算(批處理或者流式計算)來確認一筆業務是否異常。
資料鏈路一般包含幾種:
-
業務主動發起服務呼叫告知核對系統。
-
核對系統採集業務日誌。
-
核對系統採集業務資料庫的增量資料(例如 MySQL binlog)。
無疑,資料庫的增量資料是真實業務落地的體現,本文主要講的是資料庫增量鏈路的改造和最佳化。涉及的概念列舉如下:
-
物理表:對應具體資料源裡的某張表。
-
邏輯表:可以包含一個或者多個相同結構的物理表,在業務上看是一個檢視。
-
分庫分表:可以認為是一個邏輯表對應多個物理表的體現。
-
邏輯表拓撲:指是一張邏輯表關聯了哪些物理表,拓撲在某些場景下是會變化的(例如資料庫拆分、資料庫遷移等)。
-
全量資料:指一張表現存的所有資料。
-
增量資料:廣義上來說某個時間點後發生變更的資料就是增量資料,是相對於全量資料的一個概念。本文主要指透過資料庫 binlog 採集的資料。
-
安全位點:和流計算裡的 watermark 比較像。一條資料的安全位點表示當接收到這條資料時,這條流上安全位點之前的資料都已到達。
這裡簡單介紹一個核對場景,A 轉賬 100 元給 B,整個核對業務的處理邏輯如下(此處只是舉例,實際核對場景遠比例子複雜):
-
透過資料鏈路接收到 B 的一條入賬記錄,來源是資料庫 binlog 的一條轉賬記錄,包含的資訊有:轉出方 A、轉入方 B、轉賬金額 100 元、發生時間 2019-03-07 12:00:00。
-
等待賬務記錄的增量資料流安全位點抵達 2019-03-07 12:00:00(即 2019-03-07 12:00:00 之前的賬務變更都已全部到達)。
-
校驗 A 的賬務變更是否存在,並校驗變更後的金額是否比變更前減少 100 元。
-
校驗 B 的賬務變更是否存在,並校驗變更後的金額是否比變更前增加 100 元。
其中 1、2 兩步是前文所說的資料鏈路,3、4 是前文所說的計算能力。如果 3、4 的計算都透過則認為這筆轉賬記錄核對透過,否則為業務異常。
對於新春紅包核對,我們的標的主要有三個:
-
五福卡和合成卡之間的核對,保證發卡邏輯的正確性。
-
領獎金額和發獎金額之間的核對,保證算獎邏輯的正確性。
-
發獎金額和賬務流水之間的核對,保證發獎邏輯的正確性。
只有保證上述三個業務邏輯的正確,才能保證春節紅包的獎金不多發、不少發、不錯發。
同時新春紅包活動也給核對提出了一些要求:
-
時效性,要求整個核對在 15 分鐘內完成,增量資料 2 分鐘內全部抵達核對系統,否則會影響發獎時間。
-
準確性,要求到達核對系統的資料必須和資料庫產生的增量資料完全一致,否則核對結果不可信。
-
吞吐上,要求在 2 分鐘內完成上百億資料的傳輸,TPS 達到了上千萬。
老架構

解決的問題
老架構是以 Store 為核心的,Store 可以理解是一個資料庫 binlog 備份,給下游系統提供訂閱資料庫增量資料的能力,那麼為什麼不讓業務直接拉取資料庫 binlog,有以下三方面的考慮:
-
連線數上,如果所有需要增量資料的系統都來連線資料庫,勢必給資料庫帶來比較大的壓力,影響線上業務的穩定性。
-
過濾資料,下游所需的增量資料往往以邏輯表為單位,而資料庫 binlog 不具備資料過濾的能力,如果下游拉取所有資料在客戶端過濾則對網路頻寬非常不友好。
-
資料格式,螞蟻內部存在多種資料庫型別(OceanBase、MySQL、Oracle),每種資料庫的增量資料的獲取方式以及資料格式上都存在差異,如果讓下游業務直接面對多種資料庫型別,將大大增加下游系統的複雜性。
因此我們構建 Store 作為資料庫增量資料的備份為下游提供資料訂閱服務,Store 的能力列舉如下:
-
使用單連線消費資料庫的增量資料供下游消費,大大減少了資料庫上的 binlog 連線數,增強了線上資料庫的穩定性。
-
拉取到的資料建立庫表維度的索引,方便下游只消費部分庫表的資料,Store 完成過濾傳送給下游,節省網路頻寬。
-
遮蔽了各個資料增量資料格式的差異,拉取到的增量資料統一轉換為 Store 自定義的資料格式,為下游提供無差別的資料庫增量資料訂閱服務。
存在的問題
這套 Store 的架構在螞蟻內部已經服務多年,給下游提供穩定的增量資料訂閱服務。在螞蟻業務及系統架構逐步發展的情況下,今年這個資料架構已無法滿足下游訂閱資料的要求,尤其是新春紅包這種大規模的業務。
隨著螞蟻的業務發展,架構上主要有以下幾個特點:
-
分庫分表多,螞蟻現有的日常業務體量已經非常大了,核心系統的分庫分表數極多。在雙十一、雙十二、618 等大促活動的時候更是要把大量的業務彈到雲上,使用雲上的資源節省成本;三地五中心的容災架構也增加了部分同城、異地災備庫。這些都大大增加了螞蟻的分庫分表數量。螞蟻最核心的一張業務邏輯表會關聯上千個物理表。
-
消費下游多,在大資料時代,資料的使用方式非常多,各類資料會被各種下游業務訂閱計算。
-
重覆消費多,同一張邏輯表可能被數倉、核對、搜尋、業務訂閱多次,造成了邏輯表消費的膨脹。
-
資料傾斜多,我們前面提到,螞蟻核心業務有彈性庫、災備庫等,但是這些庫平常是沒有業務流量的,這就導致下游資料消費傾斜的比較厲害,就是說某些平時沒有流量的庫由於彈性、容災等原因突增大流量,對下游的負載均衡是一個挑戰。另外分庫分表數和資料量往往不是正比關係(為了做事務導致一些資料量小的表需要和大表一樣的拆分數),導致下游的資源更加不好調配。
這些原因導致了大流量在老的架構下會出現一些問題,例如:
-
由於分庫分表多,下游即使訂閱的邏輯表資料量不大,仍然需要大量的資源。
-
連線數過多導致 Store 過濾資料觸發 CPU 瓶頸,吞吐變低導致下游延遲。
-
資料傾斜導致下游系統需要頻繁的做負載調整,一定程度上影響了資料時效性。
這些問題都導致老架構無法滿足新春紅包所需的低延遲、高吞吐的需求,因此架構亟需改進以滿足新春紅包對核對的需要。
新架構(DWS)

DWS:Database and Data Warehouse Synchronization ,即數據(倉)同步服務。
解決的問題
透過對老架構及螞蟻架構特點的解讀,我們發現老架構上需要解決的問題如下:
-
減少整體連線數以節省資源。
-
減少資料過濾消除 Store 的 CPU 瓶頸。
-
重新定義分割槽,併在分割槽間平衡資料以提升下游的吞吐。
問題的根源我們認為是 Store 的資料儲存方式不適合現有大多數下游的消費方式。前文說過 Store 可以認為是資料庫 binlog 的備份,它是按照資料庫事務的方式來組織資料的,而九成以上的下游消費資料都是邏輯表的維度,正是這種資料組織上的差異導致了架構問題。按照邏輯表的維度組織資料我們想到了訊息的 Topic,因此我們引入了訊息佇列作為我們資料的儲存,同時 Topic 上的佇列概念也有助於我們對資料重新定義分割槽。
在新架構下我們以訊息佇列為中心,提供了以下能力:
-
資料按照邏輯表的維度組織,一個邏輯表的增量資料對應一個訊息 Topic。
-
資料在 Topic 上重新分割槽,按照主鍵 hash 投遞到不同的 queue 上,保證了同一主鍵順序的正確性,同時各個 queue 之間的資料均衡。
-
邏輯表的分割槽數不由分庫分表數決定,而是按照資料量、TPS 重新定義 queue 數,節約下游消費資源。
架構的升級實際上是將下游對邏輯表維度的消費需求和老架構下 Store 事務維度儲存資料進行瞭解耦,方法是在中間增加了一層訊息佇列。
存在的問題
一般來說非劃時代的架構變更都會在解決老問題的同時,帶來一些新的問題(tradeoff),那麼新架構實際上也存在以下幾個問題:
-
安全位點問題,由於 Store 是作為 binlog 的備份,Store 中的資料順序就是資料庫事務順序,因此在 Store 上消費資料可以認為是時間序列遞增的,拿到資料之後根據資料時間就知道資料的安全位點。但是新架構下訊息佇列上的資料實際上來自多條 Store 資料流,資料時間是亂序的,資料時間無法再作為安全位點使用。
-
成本問題,老的架構下 Store 是儲存和計算一體的,新的架構下我們保留了 Store 的同時,又增加了 Dispatcher(計算節點)以及訊息佇列(輕計算和重儲存),這些成本的增加如何消除。
由於時間問題,我們以安全位點為例看看新架構產生的問題我們如何解決。
安全位點問題
增量資料鏈路對安全位點都有較強的需求,如對賬系統、核對系統,另外還包括很多天級的資料任務,因此新架構下的必須解決安全位點的問題。

一個訊息佇列 queue 的資料來源於多個 Store,我們需要協調多個 Store 的安全位點才能知道這條資料的安全位點,也就是說當 Dispatcher 傳送一條資料到訊息佇列時,此條資料的安全位點就是所有可能發往此訊息佇列的 Dispatcher 裡位點最小的一個。
例如,假設我們有 4 個 Dispatcher 往 queue2 發資料,Dispatcher 1、2、3 都已經傳送到 10:00,Dispatcher 4 傳送到 09:59,此時所有發往 queue2 的資料的安全位點都只能是 09:59。具體計算方法是當資料要傳送到下游佇列的時候,呼叫管控系統,由管控獲取所有相關 Dispatcher 的位點並計算最小位點傳回給 Dispatcher,作為此 Dispatcher 傳送資料的安全位點。
這裡依舊存在不小的難點:
-
支付寶內部有大量的 Store,也就意味著有大量的 Dispatcher(10000+ Store)。
-
每個 Dispatcher 內部有大量的邏輯表(平均 30+)。
-
每個邏輯表關聯大量的 Dispatcher(平均 30+)。
-
Dispatcher 位點儲存在管控系統的 DB 中,用於行程重啟時做斷點重連,獲取相關聯 Dispatcher 的位點需兩次資料查詢。
查詢到資料之後還要做計算才能獲取安全位點,計算也是不可忽視的環節,因此我們分為兩方面來做最佳化:資料查詢和計算。
資料查詢
按照上面提到的資料,查詢一輪所有邏輯表的位點需要 30 * 30 * 10000 * 2 = 1800W 次查詢。當然我們可以降低查詢頻率,在 Dispatcher 本地快取安全位點,在接下來的一段時間內使用快取的安全位點,但是這樣勢必會降低安全位點準確度,造成下游資料延遲(下游的計算需要執行,需要確認資料已到達)。因此這裡需要在計算頻度和準確度之間做一個權衡,我們的期望是將安全位點的計算延遲降低到 10s 以內,因此資料查詢就是 180W 次/s。
此處的最佳化策略也是比較簡單的,大量使用快取,減少資料查詢成本,增加資料查詢速度。此處我們使用內部分散式快取增加查詢速度,最終快取承擔了大量的資料訪問,將 DB 查詢控制在可以接受的範圍內。
快取訪問次數: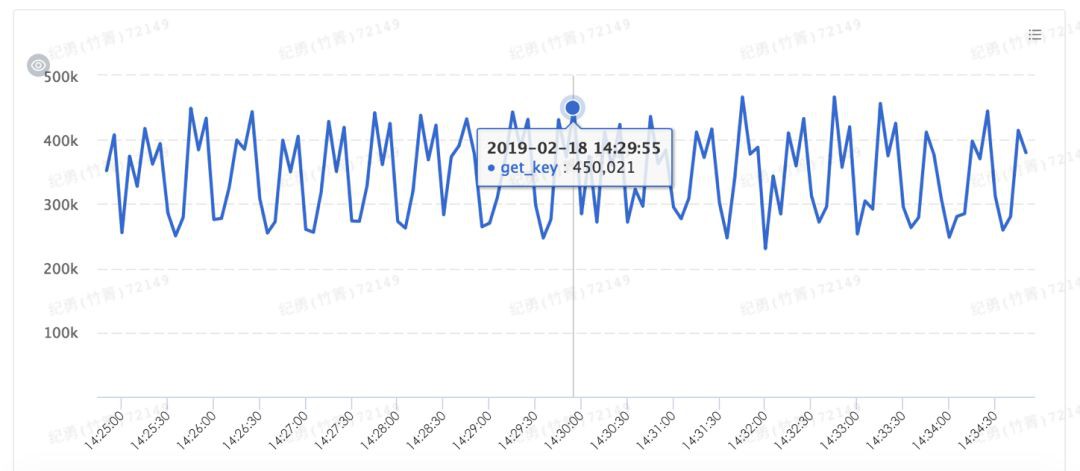
計算
要減少計算就要結合實際場景看是否有些計算是沒有必要的,我們分析了邏輯表的組合可以看到單個 Dispatcher 上的邏輯表拓撲大致相同,這是因為一個資料庫實體往往服務於一個或者多個業務,這些業務使用的多張表的分庫分表基本一致(主要是考慮需要在物理庫內部做事務,否則會牽涉到分散式事務,加大系統複雜度)。也就是說大多數的邏輯表安全位點是不需要重新計算的,基於這種業務場景,我們將一個 Dispatcher 內部的多個邏輯表按照拓撲歸類,計算安全位點只需要按照類別維度計算即可,這樣可以將計算維度降低一個數量級(同時也減少了資料訪問)。
透過對資料查詢、計算的最佳化最終將安全位點的延遲降低到 10s 以內,為 2 分鐘完成資料同步的標的做了較大的貢獻。
資料校驗
上一小節中我們主要講了新的鏈路是如何滿足新春紅包核對業務對資料鏈路的時效要求的,在此小節中我們主要關註資料準確性方面。如果說資料鏈路的時效性、高吞吐是 0 的話,資料質量則是眾多 0 前面的 1,如果無法保證資料的質量,高時效性、高吞吐量是沒有人買單的。
在資料質量上,考慮到下游消費方非常多,想要提供多種下游的資料校驗是非常困難的,而且下游消費方對他們自己的業務更加理解。因此我們決定不提供具體的產品,只提供資料查詢的服務,把具體的校驗交給各個下游來做。
和全量資料的校驗對比,增量資料的校驗有其獨特的特點:
-
時效性高,資料產出立即被使用,核對需要非常及時。
-
有效期短,增量校驗往往只需要對比最近一小段時間的資料。
基於以上兩個特點我們決定在記憶體中構建增量資料的索引,並提供給下游做多種維度的資料查詢,由於整體資料量較大,因此我們在記憶體構建的是索引 + 時間 + checksum 的資料,提供給下游快速的基於已有索引的分時段資料查詢服務,下游使用此服務得到的資料和自身的資料做對比即可校驗資料正確性。此外,我們分時段的資料採用時間分割槽作為分庫分表鍵,過期資料直接刪除物理表即可。

我們使用 DWS-Connector 將 DWS 中的資料從訊息佇列傳輸到記憶體索引系統,DWS-Connector 以框架 + 外掛化的方式提供 DWS 到多種資料源的連線,這也給整個 DWS 後續生態的拓展提供了基礎。
總結
從以上的分析我們可以看到實時資料鏈路透過各種改造支撐新春紅包極速核對的需要,總結來看主要有以下幾點:
-
在資料傳輸上,將資料從 OLTP 友好改造為 OLAP 友好的組織方式,更加符合大多數下游消費資料的需要。
-
在資料質量上,構建 DWS 資料的分時段快速查詢服務,供下游做實時的資料準確性校驗。
-
在後續拓展上,開發 DWS-Connector 框架,連線多種下游資料源,給使用者提供更加全面的資料傳輸服務。
彩蛋
另外 DWS 除了服務於新春紅包極速核對之外,在螞蟻內外部也有廣泛的使用場景,這裡簡單舉幾個例子說明。
資料庫同步

DWS 支援同構、異構資料庫的同步,在內部服務於 MySQL/Oracle -> OceanBase 的遷移服務,已穩定執行五年時間。近一年也幫助很多外部客戶完成傳統資料到分散式資料庫 OceanBase 的遷移服務。
其他儲存的複製服務

DWS 能夠將資料庫的資料複製到多種異構儲存,如 ElasticSearch、Redis、HDFS 等。幫助使用者輕鬆的在資料庫資料之上構建檢索、快取、分析等服務。
訂閱

DWS 同時提供資料庫增量資料訂閱服務,使用者可以透過 DWS 客戶端獲取資料庫增量變更後自定義處理邏輯,例如觸發一個 RPC 服務、傳送一條訊息等,任何需要感知資料庫資料變更的場景都可以使用 DWS 的服務。
資料(倉)同步服務 DWS(Database and Data Warehouse Synchronization) 將在3月底進行公測,敬請期待,詳細進度請關註本公眾號。
關於《2019 新春支付寶紅包技術大揭秘》更多主題,可以點選連結進行檢視:
https://tech.antfin.com/activities/216

長按關註,獲取分散式架構乾貨
歡迎大家共同打造 SOFAStack https://github.com/alipay

