來自:51CTO技術棧(微訊號:blog51cto)
作者:AhmedBesbes,張盛強翻譯
在這篇文章中,我們將展示如何建立一個深度神經網路,能做到以 90% 的精度來對影象進行分類,而在深度神經網路,特別是摺積神經網路興起之前,這還是一個非常困難的問題。
深度學習是目前人工智慧領域裡最讓人興奮的話題之一了,它基於生物學領域的概念發展而來,現如今是一系列演演算法的集合。
事實已經證明深度學習在計算機視覺、自然語言處理、語音識別等很多的領域裡都可以起到非常好的效果。
在過去的 6 年裡,深度學習已經應用到非常廣泛的領域,很多最近的技術突破,都和深度學習相關。
這裡僅舉幾個例子:特斯拉的自動駕駛汽車、Facebook 的照片標註系統、像 Siri 或 Cortana 這樣的虛擬助手、聊天機器人、能進行物體識別的相機,這些技術突破都要歸功於深度學習。
在這麼多的領域裡,深度學習在語言理解、影象分析這種認知任務上的表現已經達到了我們人類的水平。
如何構建一個在影象分類任務上能達到 90% 精度的深度神經網路?
這個問題看似非常簡單,但在深度神經網路特別是摺積神經網路(CNN)興起之前,這是一個被電腦科學家們研究了很多年的棘手問題。
本文分為以下三個部分進行講解:
-
展示資料集和用例,並且解釋這個影象分類任務的複雜度。
-
搭建一個深度學習專用環境,這個環境搭建在 AWS 的基於 GPU 的 EC2 服務上。
-
訓練兩個深度學習模型:第一個模型是使用 Keras 和 TensorFlow 從頭開始端到端的流程,另一個模型使用是已經在大型資料集上預訓練好的神經網路。
一個有趣的實體:給貓和狗的影象分類
有很多的影象資料集是專門用來給深度學習模型進行基準測試的,我在這篇文章中用到的資料集來自 Cat vs Dogs Kaggle competition,這份資料集包含了大量狗和貓的帶有標簽的圖片。
和每一個 Kaggle 比賽一樣,這份資料集也包含兩個檔案夾:
-
訓練檔案夾:它包含了 25000 張貓和狗的圖片,每張圖片都含有標簽,這個標簽是作為檔案名的一部分。我們將用這個檔案夾來訓練和評估我們的模型。
-
測試檔案夾:它包含了 12500 張圖片,每張圖片都以數字來命名。對於這份資料集中的每幅圖片來說,我們的模型都要預測這張圖片上是狗還是貓(1= 狗,0= 貓)。事實上,這些資料也被 Kaggle 用來對模型進行打分,然後在排行榜上排名。

我們觀察一下這些圖片的特點,這些圖片各種各樣,解析度也各不相同。圖片中的貓和狗形狀、所處位置、體表顏色各不一樣。
它們的姿態不同,有的在坐著而有的則不是,它們的情緒可能是開心的也可能是傷心的,貓可能在睡覺,而狗可能在汪汪地叫著。照片可能以任一焦距從任意角度拍下。
這些圖片有著無限種可能,對於我們人類來說在一系列不同種類的照片中識別出一個場景中的寵物自然是毫不費力的事情,然而這對於一臺機器來說可不是一件小事。
實際上,如果要機器實現自動分類,那麼我們需要知道如何強有力地描繪出貓和狗的特徵,也就是說為什麼我們認為這張圖片中的是貓,而那張圖片中的卻是狗。這個需要描繪每個動物的內在特徵。
深度神經網路在影象分類任務上效果很好的原因是,它們有著能夠自動學習多重抽象層的能力,這些抽象層在給定一個分類任務後又可以對每個類別給出更簡單的特徵表示。
深度神經網路可以識別極端變化的樣式,在扭曲的影象和經過簡單的幾何變換的影象上也有著很好的魯棒性。讓我們來看看深度神經網路如何來處理這個問題的。
配置深度學習環境
深度學習的計算量非常大,當你在自己的電腦上跑一個深度學習模型時,你就能深刻地體會到這一點。
但是如果你使用 GPUs,訓練速度將會大幅加快,因為 GPUs 在處理像矩陣乘法這樣的平行計算任務時非常高效,而神經網路又幾乎充斥著矩陣乘法運算,所以計算效能會得到令人難以置信的提升。
我自己的電腦上並沒有一個強勁的 GPU,因此我選擇使用一個亞馬遜雲服務 (AWS) 上的虛擬機器,這個虛擬機器名為 p2.xlarge,它是亞馬遜 EC2 的一部分。
這個虛擬機器的配置包含一個 12GB 視訊記憶體的英偉達GPU、一個 61GB 的 RAM、4 個 vCPU 和 2496 個 CUDA 核。
可以看到這是一臺效能巨獸,讓人高興的是,我們每小時僅需花費 0.9 美元就可以使用它。當然,你還可以選擇其他配置更好的虛擬機器,但對於我們現在將要處理的任務來說,一臺 p2.xlarge 虛擬機器已經綽綽有餘了。
我的虛擬機器工作在 Deep Learning AMI CUDA 8 Ubuntu Version 系統上,現在讓我們對這個系統有一個更清楚的瞭解吧。
這個系統基於一個 Ubuntu 16.04 伺服器,已經包裝好了所有的我們需要的深度學習框架(TensorFlow,Theano,Caffe,Keras),並且安裝好了 GPU 驅動(聽說自己安裝驅動是噩夢般的體驗)。
如果你對 AWS 不熟悉的話,你可以參考下麵的兩篇文章:
-
https://blog.keras.io/running-jupyter-notebooks-on-gpu-on-aws-a-starter-guide.html
-
https://hackernoon.com/keras-with-gpu-on-amazon-ec2-a-step-by-step-instruction-4f90364e49ac
這兩篇文章可以讓你知道兩點:
-
建立並連線到一個 EC2 虛擬機器。
-
配置網路以便遠端訪問 jupyter notebook。
用 TensorFlow 和 Keras 建立一個貓/狗圖片分類器
環境配置好後,我們開始著手建立一個可以將貓狗圖片分類的摺積神經網路,並使用到深度學習框架 TensorFlow 和 Keras。
先介紹下 Keras:Keras 是一個高層神經網路 API,它由純 Python 編寫而成並基於Tensorflow、Theano 以及 CNTK 後端,Keras 為支援快速實驗而生,能夠把你的 idea 迅速轉換為結果。
從頭開始搭建一個摺積神經網路
首先,我們設定一個端到端的 pipeline 訓練 CNN,將經歷如下幾步:資料準備和增強、架構設計、訓練和評估。
我們將繪製訓練集和測試集上的損失和準確度指標圖表,這將使我們能夠更直觀地評估模型在訓練中的改進變化。
資料準備
在開始之前要做的第一件事是從 Kaggle 上下載並解壓訓練資料集。

我們必須重新組織資料以便讓 Keras 更容易地處理它們。我們建立一個 data 檔案夾,併在其中建立兩個子檔案夾:
-
train
-
validation
在上面的兩個檔案夾之下,每個檔案夾依然包含兩個子檔案夾:
-
cats
-
dogs
最後我們得到下麵的檔案結構:
data/
train/
dogs/
dog001.jpg
dog002.jpg
…
cats/
cat001.jpg
cat002.jpg
…
validation/
dogs/
dog001.jpg
dog002.jpg
…
cats/
cat001.jpg
cat002.jpg
這個檔案結構讓我們的模型知道從哪個檔案夾中獲取到影象和訓練或測試用的標簽。這裡提供了一個函式允許你來重新構建這個檔案樹,它有 2 個引數:影象的總數目、測試集 r 的比重。


我使用了:
-
n:25000(整個資料集的大小)
-
r:0.2
-
ratio = 0.2
-
n = 25000
-
organize_datasets(path_to_data=’./train/’,n=n, ratio=ratio)
現在讓我們裝載 Keras 和它的依賴包吧:

影象生成器和資料增強
在訓練模型時,我們不會將整個資料集裝載進記憶體,因為這種做法並不高效,特別是你使用的還是你自己本地的機器。
我們將用到 ImageDataGenerator 類,這個類可以無限制地從訓練集和測試集中批次地引入影象流。在ImageDataGenerator 類中,我們將在每個批次引入隨機修改。
這個過程我們稱之為資料增強(dataaugmentation)。它可以生成更多的圖片使得我們的模型不會看見兩張完全相同的圖片。這種方法可以防止過擬合,也有助於模型保持更好的泛化性。
我們要建立兩個 ImageDataGenerator 物件。train_datagen 對應訓練集,val_datagen 對應測試集,兩者都會對影象進行縮放,train_datagen 還將做一些其他的修改。

基於前面的兩個物件,我們接著建立兩個檔案生成器:
-
train_generator
-
validation_generator
每個生成器在實時資料增強的作用下,在目錄處可以生成批次的影象資料。這樣,資料將會無限制地迴圈生成。

模型結構
我將使用擁有 3 個摺積/池化層和 2 個全連線層的 CNN。3 個摺積層將分別使用 32,32,64 的 3 * 3的濾波器(fiter)。在兩個全連線層,我使用了 dropout 來避免過擬合。

我使用隨機梯度下降法進行最佳化,引數 learning rate 為 0.01,momentum 為 0.9。

Keras 提供了一個非常方便的方法來展示模型的全貌。對每一層,我們可以看到輸出的形狀和可訓練引數的個數。在開始擬合模型前,檢查一下是個明智的選擇。
model.summary()

下麵讓我們看一下網路的結構。
結構視覺化

在訓練模型前,我定義了兩個將在訓練時呼叫的回呼函式 (callback function):
-
一個用於在損失函式無法改進在測試資料的效果時,提前停止訓練。
-
一個用於儲存每個時期的損失和精確度指標:這可以用來繪製訓練錯誤圖表。

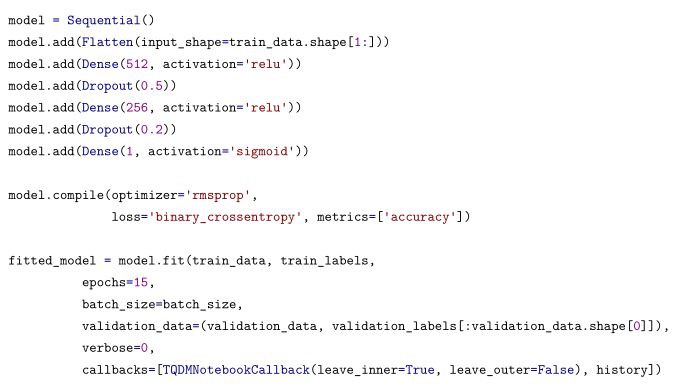
我還使用了 keras-tqdm,這是一個和 keras 完美整合的非常棒的進度條。它可以讓我們非常容易地監視模型的訓練過程。
要想使用它,你僅需要從 keras_tqdm 中載入 TQDMNotebookCallback 類,然後將它作為第三個回呼函式傳遞進去。
下麵的圖在一個簡單的樣例上展示了 keras-tqdm 的效果。

關於訓練過程,還有幾點要說的:
-
我們使用 fit_generator 方法,它是一個將生成器作為輸入的變體(標準擬合方法)。
-
我們訓練模型的時間超過 50 個 epoch。

這個模型執行時的計算量非常大:
-
如果你在自己的電腦上跑,每個 epoch 會花費 15 分鐘的時間。
-
如果你和我一樣在 EC2 上的 p2.xlarge 虛擬機器上跑,每個 epoch 需要花費 2 分鐘的時間。
分類結果
我們在模型執行 34 個 epoch 後達到了 89.4% 的準確率(下文展示訓練/測試錯誤和準確率),考慮到我沒有花費很多時間來設計網路結構,這已經是一個很好的結果了。現在我們可以將模型儲存,以備以後使用。
model.save(`./models/model4.h5)
下麵我們在同一張圖上繪製訓練和測試中的損失指標值:


當在兩個連續的 epoch 中,測試損失值沒有改善時,我們就中止訓練過程。
下麵繪製訓練集和測試集上的準確度。


這兩個指標一直是增長的,直到模型即將開始過擬合的平穩期。
裝載預訓練的模型
我們在自己設計的 CNN 上取得了不錯的結果,但還有一種方法能讓我們取得更高的分數:直接載入一個在大型資料集上預訓練過的摺積神經網路的權重,這個大型資料集包含 1000 個種類的貓和狗的圖片。
這樣的網路會學習到與我們分類任務相關的特徵。
我將載入 VGG16 網路的權重,具體來說,我要將網路權重載入到所有的摺積層。這個網路部分將作為一個特徵檢測器來檢測我們將要新增到全連線層的特徵。
與 LeNet5 相比,VGG16 是一個非常大的網路,它有 16 個可以訓練權重的層和 1.4 億個引數。要瞭解有關 VGG16 的資訊,請參閱此篇 pdf 連結:https://arxiv.org/pdf/1409.1556.pdf

現在我們將影象傳進網路來得到特徵表示,這些特徵表示將會作為神經網路分類器的輸入。

影象在傳遞到網路中時是有序傳遞的,所以我們可以很容易地為每張圖片關聯上標簽。

現在我們設計了一個小型的全連線神經網路,附加上從 VGG16 中抽取到的特徵,我們將它作為 CNN 的分類部分。
在 15 個 epoch 後,模型就達到了 90.7% 的準確度。這個結果已經很好了,註意現在每個 epoch 在我自己的電腦上跑也僅需 1 分鐘。



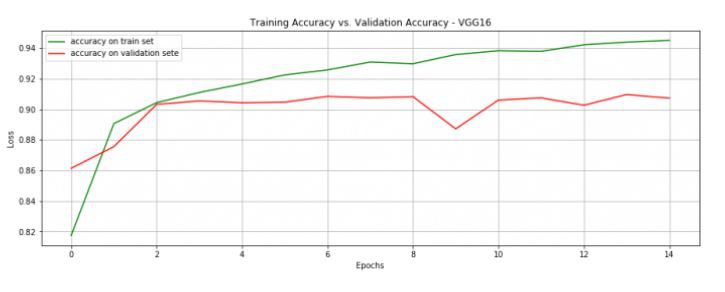
許多深度學習領域的大牛人物都鼓勵大家在做分類任務時使用預訓練網路,實際上,預訓練網路通常使用的是在一個非常大的資料集上生成的非常大的網路。
而 Keras 可以讓我們很輕易地下載像 VGG16、GoogleNet、ResNet 這樣的預訓練網路。想要瞭解更多關於這方面的資訊,請參考這裡:https://keras.io/applications/
有一句很棒的格言是:不要成為英雄!不要重覆發明輪子!使用預訓練網路吧!
接下來還可以做什麼?
如果你對改進一個傳統 CNN 感興趣的話,你可以:
-
在資料集層面上,引入更多增強資料。
-
研究一下網路超引數(network hyperparameter):摺積層的個數、濾波器的個數和大小,在每種組合後要測試一下效果。
-
改變最佳化方法。
-
嘗試不同的損失函式。
-
使用更多的全連線層。
-
引入更多的 aggressive dropout。
如果你對使用預訓練網路獲得更好的分類結果感興趣的話,你可以嘗試:
-
使用不同的網路結構。
-
使用更多包含更多隱藏單元的全連線層。
如果你想知道 CNN 這個深度學習模型到底學習到了什麼東西,你可以:
-
將 feature maps 視覺化。
-
可以參考:https://arxiv.org/pdf/1311.2901.pdf
如果你想使用訓練過的模型:
-
可以將模型放到 Web APP 上,使用新的貓和狗的影象來進行測試。這也是一個很好地測試模型泛化性的好方法。
總結
這是一篇手把手教你在 AWS 上搭建深度學習環境的教程,並且教你怎樣從頭開始建立一個端到端的模型,另外本文也教了你怎樣基於一個預訓練的網路來搭建一個 CNN 模型。
用 Python 來做深度學習是讓人愉悅的事情,而 Keras 讓資料的預處理和網路層的搭建變得更加簡單。
如果有一天你需要按自己的想法來搭建一個神經網路,你可能需要用到其他的深度學習框架。
現在在自然語言處理領域,也有很多人開始使用摺積神經網路了,下麵是一些基於此的工作:
-
使用了 CNN 的文字分類:
https://chara.cs.illinois.edu/sites/sp16-cs591txt/files/0226-presentation.pdf
-
自動為影象生成標題:
https://cs.stanford.edu/people/karpathy/sfmltalk.pdf
-
字級別的文字分類:
https://papers.nips.cc/paper/5782-character-level-convolutional-networks-fortext-classification.pdf
●本文編號332,以後想閱讀這篇文章直接輸入332即可
●輸入m獲取文章目錄

大資料與人工智慧
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
