原文作者:心萊科技肖鑫
簡單來說機器學習的核心步驟在於“獲取學習資料;選擇機器演演算法;定型模型;評估模型,預測模型結果”,下麵本人就以判斷日報內容是否合格為例為大家簡單的闡述一下C#的機器學習。
第一步:問題分析
根據需求可以得出我們的模型是以日報的內容做為學習的特徵確定的,然後透過模型判斷將該標的物件預測為是否符合標準(合格與不合格),簡單來說就是一種分類場景(此場景結果屬於二元分類,不是A就是B),那麼也就確定了核心演演算法為分類演演算法當然還有其它的分類演演算法有興趣的可以自己去瞭解一下在這裡就不多做說明瞭。
第二步:環境準備
其他的程式碼編譯執行的環境並沒有太多要求,你只需要取用C#機器學習的NuGet 包,名為Microsoft.ML具體的安裝步驟在此就不做詳細介紹了。
第三步:準備資料
這裡會準備兩個資料集 一個定型模型的資料集(可以稱之為學習資料)wikipedia-detox-250-line-data.tsv資料實體部分展示如下(你的資料按照這種排列格式即可該該格式的定義取決於你的輸入資料集類的結構在下麵會講到):
SentimentSentimentText
1 第一天上班 無事
1 完成了領導的安排任務
1 編寫了一些程式碼然後寫了一些雜七雜八的檔案
1 和一般的碼農做了一樣的事情
1 和產品經理一起做了一些專案上的事情
1 早上來的時候就開始討論需求,然後開始寫程式碼,快下班的時候完成了整個過程的檔案分享
0 ***專案的整體編排會議,設計圖的首頁以及我的個人中心製作
0 **專案需求的對接,需求的梳理,物體結構的定義,資料庫的遷移,腦圖的完善
0 1、**專案的模板訊息程式碼編寫,2、**專案管理後臺的模板傳送完善,
定型模型資料集準備好之後還有一個評估模型的測試資料集(可以稱之為標準答案)wikipedia-detox-250-line-test.tsv格式與上面展示的評估資料集一樣
定型資料的資料越豐富演演算法的回歸曲線方程就會越接近理想的模型方程,你的模型預測結果就會越符合你的要求。
第四步:定義特徵類
根據分享的模型確定其分析的特徵項並定義為相關的類並且需要取用機器學習的包using Microsoft.ML.Data;,由此模型定義的資料集類如下(結果可看註釋):
///
/// 輸入資料集類
///
public class SentimentData
{
///
/// 日誌是否合格的值(0:為合格,1:不合格)
///
[Column(ordinal:“0”, name:“Label”)]
public float Sentiment;
///
/// 日報內容
///
[Column(ordinal:“1”)]
public string SentimentText;
}
///
/// 預測結果集類
///
public class SentimentPrediction
{
///
/// 預測值(是否合格)
///
[ColumnName(“PredictedLabel”)]
public bool Prediction {get;set; }
///
/// 或然率(結果分佈機率)
///
[ColumnName(“Probability”)]
public float Probability {get;set; }
}
第一個SentimentData類為輸入資料集類,指的就是根據定型的資料集的特徵項定義的集類,第二個SentimentPrediction類為預測結果集類,也就是你所需要的結果的類定義 該類的結構一般受你所使用的學習演演算法影響,根據你的學習管道輸出的結果以及個人需求的綜合考慮來定義。輸入集類帶的Column屬性標註其在資料集的格式位置的編排以及何為Label值。預測集的PredictedLabel在預測和評估過程中使用。
第五步:程式碼實現
首先定義以指定這些路徑和 _textLoader 變數,用來讀取資料或者是儲存實驗資料,具體如下所示:
_trainDataPath 具有用於定型模型的資料集路徑。
_testDataPath 具有用於評估模型的資料集路徑。
_modelPath 具有在其中儲存定型模型的路徑。
_textLoader 是用於載入和轉換資料集的 TextLoader。

然後定義程式的入口(main函式)以及相應的處理方法:
定義SaveModelAsFile方法將模型儲存為 .zip 檔案程式碼如下所示:
private static void SaveModelAsFile(MLContext mlContext, ITransformer model)
{
using (var fs =new FileStream(_modelPath, FileMode.Create, FileAccess.Write, FileShare.Write))
mlContext.Model.Save(model, fs);
Console.WriteLine(“模型儲存路徑為{0}”, _modelPath);
Console.ReadLine();
}
定義Train方法選擇學習方法並且建立相應的學習管道,輸出定型後的模型model程式碼如下所示:
public static ITransformer Train(MLContext mlContext,string dataPath)
{
IDataView dataView = _textLoader.Read(dataPath);
//資料特徵化(按照管道所需的格式轉換資料)
var pipeline = mlContext.Transforms.Text.FeaturizeText(inputColumnName:“SentimentText”, outputColumnName:“Features”)
//根據學習演演算法新增學習管道
.Append(mlContext.BinaryClassification.Trainers.FastTree(numLeaves: 50, numTrees: 50, minDatapointsInLeaves: 20));
//得到模型
var model = pipeline.Fit(dataView);
Console.WriteLine();
//傳回定型模型
return model;
}
模型定型之後,我們需要建立一個方法(Evaluate)來評測該模型的質量,根據你自己的標準測試資料集與該模型的符合程度來判斷,並且輸出相應的指標,該指標引數根據你所呼叫的評估方法傳回具體的根據你的演演算法方程傳回相應的方程的引數 。程式碼如下所示:
public static void Evaluate(MLContext mlContext, ITransformer model)
{
var dataView = _textLoader.Read(_testDataPath);
Console.WriteLine(“===============用測試資料評估模型的準確性===============”);
var predictions = model.Transform(dataView);
//評測定型模型的質量
var metrics = mlContext.BinaryClassification.Evaluate(predictions,“Label”);
Console.WriteLine();
Console.WriteLine(“模型質量量度評估”);
Console.WriteLine(“——————————–“);
Console.WriteLine($”精度:{metrics.Accuracy:P2}“);
Console.WriteLine($”Auc:{metrics.Auc:P2}“);
Console.WriteLine(“=============== 模型結束評價 ===============”);
Console.ReadLine();
//評測完成之後開始儲存定型的模型
SaveModelAsFile(mlContext, model);
}
定義單個資料的預測方法(Predict)與批處理預測的方法(PredictWithModelLoadedFromFile):
單個資料集的預測程式碼如下所示:
private static void Predict(MLContext mlContext, ITransformer model)
{
//建立包裝器
var predictionFunction = model.CreatePredictionEngine
SentimentData sampleStatement =new SentimentData
{
SentimentText =“愛車新需求開發;麥扣日誌監控部分頁面資料系結;”
};
//預測結果
var resultprediction = predictionFunction.Predict(sampleStatement);
Console.WriteLine();
Console.WriteLine(“===============單個測試資料預測 ===============”);
Console.WriteLine();
Console.WriteLine($”日報內容:{sampleStatement.SentimentText} | 是否合格:{(Convert.ToBoolean(resultprediction.Prediction) ?“合格” :“不合格”)} | 符合率:{resultprediction.Probability} “);
Console.WriteLine(“=============== 預測結束 ===============”);
Console.WriteLine();
Console.ReadLine();
}
批處理資料集預測方法程式碼如下所示:
public static void PredictWithModelLoadedFromFile(MLContext mlContext)
{
IEnumerable
{
new SentimentData
{
SentimentText =“1、完成愛車年卡程式碼編寫 2、與客戶完成需求對接”
},
new SentimentData
{
SentimentText =“沒有工作內容”
}
};
ITransformer loadedModel;
using (var stream =new FileStream(_modelPath, FileMode.Open, FileAccess.Read, FileShare.Read))
{
loadedModel = mlContext.Model.Load(stream);
}
//建立預測(也稱之為建立預測房屋)
var sentimentStreamingDataView = mlContext.Data.ReadFromEnumerable(sentiments);
var predictions = loadedModel.Transform(sentimentStreamingDataView);
//使用模型預測結果值為1(不合格)還是0 (合格)
var predictedResults = mlContext.CreateEnumerable
Console.WriteLine();
Console.WriteLine(“=============== 多樣本載入模型的預測試驗 ===============”);
var sentimentsAndPredictions = sentiments.Zip(predictedResults, (sentiment, prediction) => (sentiment, prediction));
foreach (var itemin sentimentsAndPredictions)
{
Console.WriteLine($”日報內容:{item.sentiment.SentimentText} | 是否合格:{(Convert.ToBoolean(item.prediction.Prediction) ?“合格” :“不合格”)} | 符合率:{item.prediction.Probability} “);
}
Console.WriteLine(“=============== 預測結束 ===============”);
Console.ReadLine();
}
在以上的方法定義完成之後開始進行方法的呼叫:
public static void Main(string[] args)
{
//建立一個MLContext,為ML作業提供一個背景關係
MLContext mlContext =new MLContext(seed: 0);
//初始化_textLoader以將其重覆應用於所需要的資料集
_textLoader = mlContext.Data.CreateTextLoader(
columns:new TextLoader.Column[]
{
new TextLoader.Column(“Label”, DataKind.Bool,0),
new TextLoader.Column(“SentimentText”, DataKind.Text,1)
},
separatorChar:‘\t’,
hasHeader:true
);
//定型模型
var model = Train(mlContext, _trainDataPath);
//評測模型
Evaluate(mlContext, model);
//單個資料預測
Predict(mlContext, model);
//批處理預測資料
PredictWithModelLoadedFromFile(mlContext);
}
準備程式碼之後,你的小小的機器人就要開始學習啦,好吧開始編譯執行吧。。。。。。
執行產生結果為:
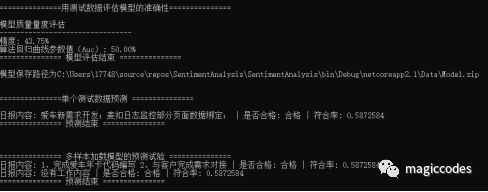
由於訓練的資料集特徵化引數的準確性以及資料的涵蓋廣度不夠導致定義的模型質量非常的不理想因此我們可以看到我們的預測結果也是不夠符合我們的理想狀態,可見我們小機器的學習之路是非常漫長的過程啊。
由此次的機器學習的小小實踐本人也深有體會,機器就像一個小孩一樣首先你得根據他的性格(特徵化引數)確定應該給予他什麼樣的學習環境(學習演演算法建立的學習管道)並提供學習資料(定型機器學習模型資料集),然後為其確定一個發展標的(評估模型資料集),並且不斷的進行考試(單個資料的預測與批次資料的預測),考試需要特定的考試場地(預測所需要呼叫的方法)。透過該種方式讓機器不斷的學習不斷的精進。
原文地址:https://www.cnblogs.com/codelove/p/10493970.html
.NET社群新聞,深度好文,歡迎訪問公眾號文章彙總 http://www.csharpkit.com

