來自:開源中國
www.oschina.net/translate/a-look-at-ten-new-database-systems-released-in-2017
作為 Database Weekly 的編輯(Database Weekly 是一份關於資料庫和資料儲存世界新內容的每週時事資訊),我喜歡在新的資料庫系統中閑逛,看看在未來的幾十年裡,哪些想法可能會影響到日常的開發人員。
資料庫世界並不是每週都有讓人不可思議的新聞,但在一年的時間裡,我還是驚訝地發現,我們看到了很多新事物,以及該領域堅持不懈地發展。2017 年也不例外,所以我想回顧一下一些有趣的新發行版,包括一個事務性圖表資料庫,一個可複製的地理多模型資料庫,以及一個新的高效能鍵/值儲存資料庫。
TimescaleDB — 一款基於 Postgres 的能自動分割槽的時間序列資料庫
其中一個令人興奮的新擴充套件源於 PostgreSQL,Timescale 基於 Apache 2.0 的許可,它是由一個名為 PhD-packed 的機構支援啟動的。
Timescale 透過自動分割槽為 Postgres 新增時間序列儲存功能,但是卻包含在尋常的 Postgres 介面和工具中。 查詢是使用常規的 SQL 對“提供與時間序列資料的介面” 的 “hypertable” 進行的。

Microsoft Azure Cosmos DB — 微軟的多樣式資料庫
Cosmos DB 本質上是 Azure 的舊的 DocumentDB 的品牌重塑和重新構建,但是它很容易實現將全球分散式資料跟 Azure 的多樣資料中心交叉。全球分佈是 Cosmos DB 的殺手鐧,並且它可以將資料庫請求路由到包含資料的最近區域,而不需要更改配置。
“多樣式”的部分也很重要。雖然一切都在無樣式的 JSON 的引擎蓋下,但依然有一個 SQL 查詢 API ,以及 MongoDB API、Cassandra API,甚至一個圖形資料庫 API(基於 Gremlin )。
學習更多關於 Cosmos 的較好的方式之一是這個微軟的第9頻道的 15 分鐘影片介紹。
Cloud Spanner — Google 全球分散式關係資料庫
Google 的 Cloud Spanner 已經工作了很長一段時間了,起初是在 2012 年一篇非常有趣的學術論文中公開闡釋的(雖然開發始於 2007 年)。最初的開發是因為 Google 需要一個全球化分散式的高可用性儲存系統,但其現在也向公眾開放。
谷歌認識到,使 Cloud Spanner 適合其自身用途的功能對企業也很有吸引力,因此它承諾 99.999% 的可用性、無計劃停機時間和“企業級”安全性。
Cloud Spanner 支援 ANSI 2011 SQL ,為已熟悉關係資料庫概念的開發人員提供了經過戰鬥級測試的高可用性水平擴充套件的關係資料庫。
Neptune — Amazon 的全面管理圖形資料庫服務
Microsoft 和 Google 我們都已經講到了, 所以怎麼能漏了 Amazon 呢? 這是另外一個受限於特定雲服務的資料庫, Amazon 在最近召開的 re:Invent 大會上展示了 Neptune 的預覽。
Neptune 承諾會是一個快速且可靠的圖形資料庫服務,其目的是能迅速地為開發者提供圖形資料庫服務,並且不會讓他們感到麻煩,當然這些是要付費的。
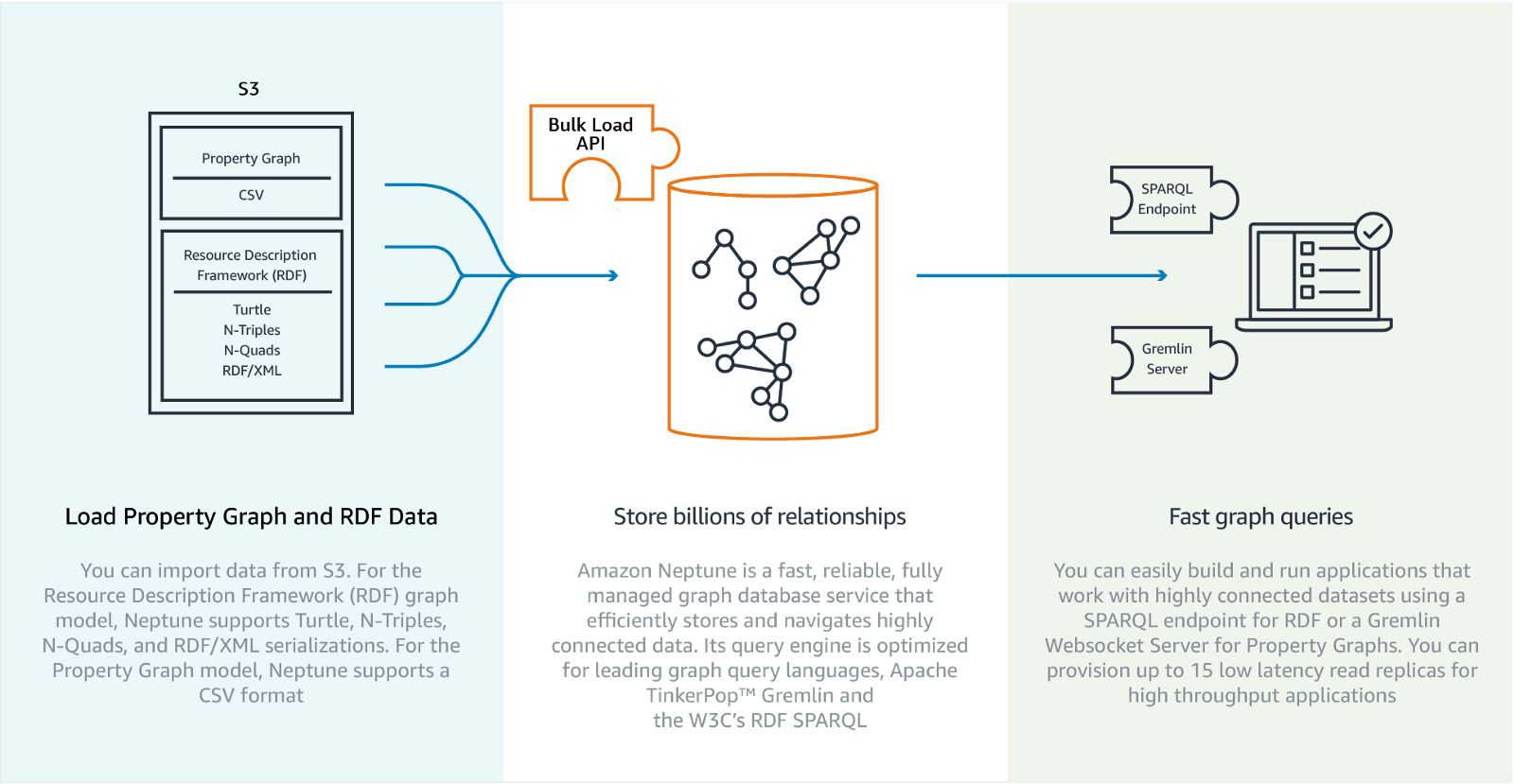
Neptune 支援用兩種標準來對你的圖形庫進行查詢, 一個是得到越來越多的支援的 Gremlin 的“黃金”標準,還有就是 SPARQL (你的圖形會被當作是一個 RDF )。
YugaByte — 一個開源的雲原生資料庫
YugaByte 今年因其“隱形樣式”脫穎而出,它提供了一個支援 SQL 和 NoSQL 操作樣式的資料庫。目的是在雲中直接使用,充當對容器的有狀態補充。
YugaByte 使用 C ++ 構建並開源,支援 Cassandra 查詢語言(CQL)以及 Redis 協議。 對 PostgreSQL 協議的支援正在進行中,Spark 應用可在上面執行。

YugaByte 是另一個啟動後才受到支援的專案(由擴充套件了 Apache HBase 平臺的一位 Facebook 工程師建立),其業務樣式初定是會有一個“企業版”,在開源社群版的基礎上增加多雲叢集協調 ,監視和警報,分層儲存和支援等特性。
Peloton — 一個自驅動的 SQL DBMS
Peloton 探索了一些有趣的想法,特別是在使用 AI 來自動最佳化資料庫的領域。它還支援位元組定址 NVM 儲存技術,並且是使用 Apache 許可開源的。
“自驅動”資料庫背後的想法是,DBMS 可以自主操作和調整自身。它可以預測工作負載的趨勢,並據此做好準備,而無需 DBA 或操作員掌控。
也許毫不奇怪的是,Peloton 源於一個學術專案(特別是來自卡內基梅隆大學),其建立者之一寫了一篇關於為什麼它被建立的系列文章。它已經開發好幾年了,但在 2017 年變得更加開放。
JanusGraph — 一個基於 Java 的分散式圖形資料庫
JanusGraph 是一個實用的、隨時可用的資料庫,其中包含大量的整合,並且建立在 TitanDB 的堅實基礎之上。它針對可擴充套件性、儲存及查詢巨大圖形資料庫做了最佳化,同時支援事務和大量併發使用者。
它可以使用 Cassandra、HBase、Google Cloud Bigtable 和 BerkeleyDB 作為儲存後端,並且可以與 Spark、Giraph 和 Hadoop 直接整合。它甚至支援與 ElasticSearch、Solr 或 Lucene 整合的全文和地理位置檢索。
Aurora Serverless — AWS 上即時可伸縮,“即付即用”的關係型資料庫
另一個來自 Amazo re:Invent 會議的公告是他們成功的 Aurora 資料庫服務的無伺服器版本,Aurora Serverless。
隨著整合到“無伺服器”平臺的最新趨勢,這個平臺將永遠消除你在擴充套件和操作上的難題,Aurora Serverless背後的理念是許多資料庫用例不需要一致的效能或使用水平,相反,你可以“隨時付費”(逐秒付費),以便按需調整資料庫的大小。

它目前僅是預覽版,但承諾在 2018 年會有重大進展。
TileDB — 用於儲存大密度及稀疏矩陣陣列
TileDB 是起源自麻省理工學院和英特爾的資料庫,用於儲存多維陣列資料,這是類似基因科學、醫學成像和金融時間序列等領域常見的要求。
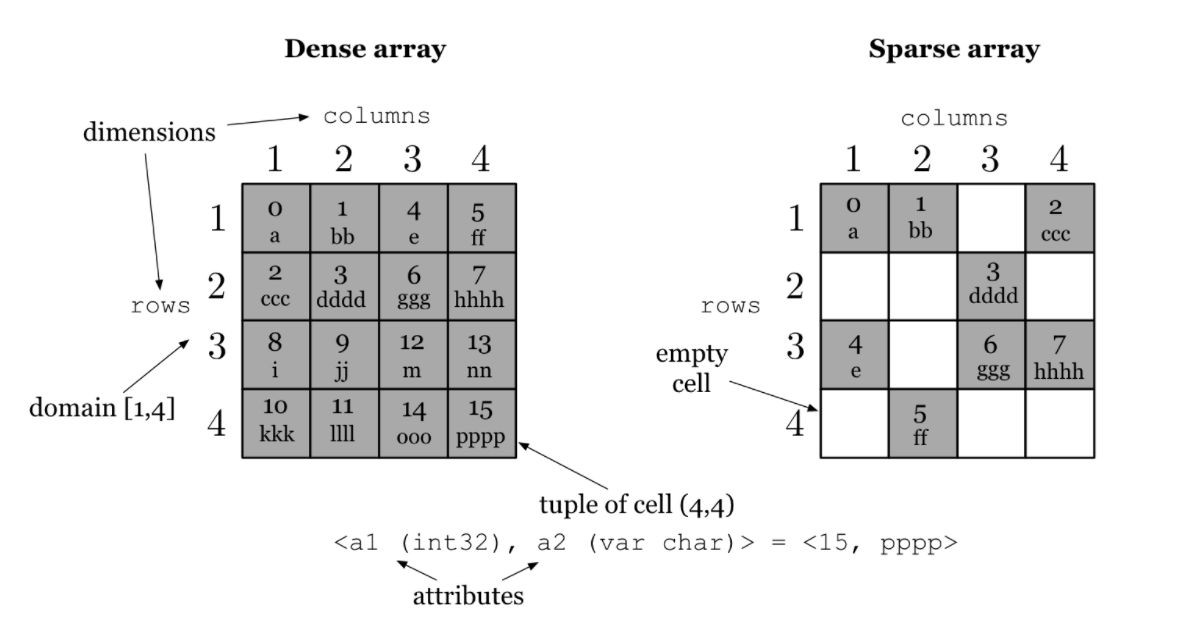
它支援許多壓縮機制(如 gzip、lz4、Blosc 和 RLE )和儲存後端(如 GFS、S3 和 HDFS )。
Memgraph — 一個高效能、可記憶體駐留的圖形資料庫
Memgraph 背後的驅動力是為快速分析和使用來自人造和機器智慧的資料以及裝置和物聯網不斷增長的互聯性提供工具。因此,優先事項是“速度、可伸縮和簡單性”。
在 Memgraph 的生命週期中,它還處於早期階段,它不是開源的,但可以透過 request 下載。它支援 openCypher 圖形查詢語言,支援記憶體中的 ACID 事務,並具有基於磁碟的持久化機制。
●本文編號276,以後想閱讀這篇文章直接輸入276即可
●輸入m獲取到文章目錄

Web開發
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
