作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
前言
2017 年中,有兩篇類似同時也是筆者非常欣賞的論文,分別是 FaceBook 的 Convolutional Sequence to Sequence Learning 和 Google 的 Attention is All You Need,它們都算是 Seq2Seq 上的創新,本質上來說,都是拋棄了 RNN 結構來做 Seq2Seq 任務。
在本篇文章中,筆者將對 Attention is All You Need 做一點簡單的分析。當然,這兩篇論文字身就比較火,因此網上已經有很多解讀了(不過很多解讀都是直接翻譯論文的,鮮有自己的理解),因此這裡盡可能多自己的文字,儘量不重覆網上各位大佬已經說過的內容。
序列編碼
深度學習做 NLP 的方法,基本上都是先將句子分詞,然後每個詞轉化為對應的詞向量序列。這樣一來,每個句子都對應的是一個矩陣 X=(x1,x2,…,xt),其中 xi 都代表著第 i 個詞的詞向量(行向量),維度為 d 維,故 。這樣的話,問題就變成了編碼這些序列了。
。這樣的話,問題就變成了編碼這些序列了。
第一個基本的思路是 RNN 層,RNN 的方案很簡單,遞迴式進行:

不管是已經被廣泛使用的 LSTM、GRU 還是最近的 SRU,都並未脫離這個遞迴框架。RNN 結構本身比較簡單,也很適合序列建模,但 RNN 的明顯缺點之一就是無法並行,因此速度較慢,這是遞迴的天然缺陷。
另外我個人覺得 RNN 無法很好地學習到全域性的結構資訊,因為它本質是一個馬爾科夫決策過程。
第二個思路是 CNN 層,其實 CNN 的方案也是很自然的,視窗式遍歷,比如尺寸為 3 的摺積,就是:
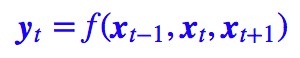
在 FaceBook 的論文中,純粹使用摺積也完成了 Seq2Seq 的學習,是摺積的一個精緻且極致的使用案例,熱衷摺積的讀者必須得好好讀讀這篇文論。
CNN 方便並行,而且容易捕捉到一些全域性的結構資訊,筆者本身是比較偏愛 CNN 的,在目前的工作或競賽模型中,我都已經儘量用 CNN 來代替已有的 RNN 模型了,並形成了自己的一套使用經驗,這部分我們以後再談。
Google的大作提供了第三個思路:純 Attention,單靠註意力就可以。
RNN 要逐步遞迴才能獲得全域性資訊,因此一般要雙向 RNN 才比較好;CNN 事實上只能獲取區域性資訊,是透過層疊來增大感受野;Attention 的思路最為粗暴,它一步到位獲取了全域性資訊,它的解決方案是:

其中 A,B 是另外一個序列(矩陣)。如果都取 A=B=X,那麼就稱為 Self Attention,它的意思是直接將 xt 與原來的每個詞進行比較,最後算出 yt。
Attention 層
Attention 定義
Google 的一般化 Attention 思路也是一個編碼序列的方案,因此我們也可以認為它跟 RNN、CNN 一樣,都是一個序列編碼的層。

前面給出的是一般化的框架形式的描述,事實上 Google 給出的方案是很具體的。首先,它先把 Attention 的定義給了出來:

這裡用的是跟 Google 的論文一致的符號,其中:

於是我們可以認為:這是一個 Attention 層,將 n×dk 的序列 Q 編碼成了一個新的 n×dv 的序列。
那怎麼理解這種結構呢?我們不妨逐個向量來看。

其中 Z 是歸一化因子。事實上 q,k,v 分別是 query,key,value 的簡寫,K,V 是一一對應的,它們就像是 key-value 的關係,那麼上式的意思就是透過 qt 這個 query,透過與各個 ks 內積的並 softmax 的方式,來得到 qt 與各個 vs 的相似度,然後加權求和,得到一個 dv 維的向量。
其中因子![]() 起到調節作用,使得內積不至於太大(太大的話 softmax 後就非 0 即 1 了,不夠“soft”了)。
起到調節作用,使得內積不至於太大(太大的話 softmax 後就非 0 即 1 了,不夠“soft”了)。
事實上這種 Attention 的定義並不新鮮,但由於 Google 的影響力,我們可以認為現在是更加正式地提出了這個定義,並將其視為一個層地看待。
此外這個定義只是註意力的一種形式,還有一些其他選擇,比如 query 跟 key 的運算方式不一定是點乘(還可以是拼接後再內積一個引數向量),甚至權重都不一定要歸一化,等等。
Multi-Head Attention
這個是 Google 提出的新概念,是 Attention 機制的完善。

不過從形式上看,它其實就再簡單不過了,就是把 Q,K,V 透過引數矩陣對映一下,然後再做 Attention,把這個過程重覆做 h 次,結果拼接起來就行了,可謂“大道至簡”了。具體來說:

這裡 ,然後:
,然後:

最後得到一個 n×(hd̃v) 的序列。所謂“多頭”(Multi-Head),就是隻多做幾次同樣的事情(引數不共享),然後把結果拼接。
Self Attention
到目前為止,對 Attention 層的描述都是一般化的,我們可以落實一些應用。比如,如果做閱讀理解的話,Q 可以是篇章的詞向量序列,取 K=V 為問題的詞向量序列,那麼輸出就是所謂的 Aligned Question Embedding。
而在 Google 的論文中,大部分的 Attention 都是 Self Attention,即“自註意力”,或者叫內部註意力。
所謂 Self Attention,其實就是 Attention(X,X,X),X 就是前面說的輸入序列。也就是說,在序列內部做 Attention,尋找序列內部的聯絡。
Google 論文的主要貢獻之一是它表明瞭內部註意力在機器翻譯(甚至是一般的 Seq2Seq 任務)的序列編碼上是相當重要的,而之前關於 Seq2Seq 的研究基本都只是把註意力機制用在解碼端。
類似的事情是,目前 SQUAD 閱讀理解的榜首模型 R-Net 也加入了自註意力機制,這也使得它的模型有所提升。
當然,更準確來說,Google 所用的是 Self Multi-Head Attention:

Position Embedding
然而,只要稍微思考一下就會發現,這樣的模型並不能捕捉序列的順序。換句話說,如果將 K,V 按行打亂順序(相當於句子中的詞序打亂),那麼 Attention 的結果還是一樣的。
這就表明瞭,到目前為止,Attention 模型頂多是一個非常精妙的“詞袋模型”而已。
這問題就比較嚴重了,大家知道,對於時間序列來說,尤其是對於 NLP 中的任務來說,順序是很重要的資訊,它代表著區域性甚至是全域性的結構,學習不到順序資訊,那麼效果將會大打折扣(比如機器翻譯中,有可能只把每個詞都翻譯出來了,但是不能組織成合理的句子)。
於是 Google 再祭出了一招——Position Embedding,也就是“位置向量”,將每個位置編號,然後每個編號對應一個向量,透過結合位置向量和詞向量,就給每個詞都引入了一定的位置資訊,這樣 Attention 就可以分辨出不同位置的詞了。
Position Embedding 並不算新鮮的玩意,在 FaceBook 的 Convolutional Sequence to Sequence Learning 也用到了這個東西。但在 Google 的這個作品中,它的 Position Embedding 有幾點區別:
1. 以前在 RNN、CNN 模型中其實都出現過 Position Embedding,但在那些模型中,Position Embedding 是錦上添花的輔助手段,也就是“有它會更好、沒它也就差一點點”的情況,因為 RNN、CNN 本身就能捕捉到位置資訊。
但是在這個純 Attention 模型中,Position Embedding 是位置資訊的唯一來源,因此它是模型的核心成分之一,並非僅僅是簡單的輔助手段。
2. 在以往的 Position Embedding 中,基本都是根據任務訓練出來的向量。而 Google 直接給出了一個構造 Position Embedding 的公式:
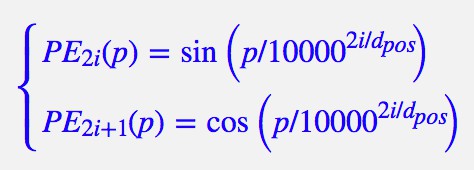
這裡的意思是將 id 為 p 的位置對映為一個 dpos 維的位置向量,這個向量的第 i 個元素的數值就是 PEi(p)。
Google 在論文中說到他們比較過直接訓練出來的位置向量和上述公式計算出來的位置向量,效果是接近的。因此顯然我們更樂意使用公式構造的 Position Embedding 了。
3. Position Embedding 本身是一個絕對位置的資訊,但在語言中,相對位置也很重要,Google 選擇前述的位置向量公式的一個重要原因如下:
由於我們有 sin(α+β)=sinα cosβ+cosα sinβ 以及 cos(α+β)=cosα cosβ−sinα sinβ,這表明位置 p+k 的向量可以表明位置 p 的向量的線性變換,這提供了表達相對位置資訊的可能性。
結合位置向量和詞向量有幾個可選方案,可以把它們拼接起來作為一個新向量,也可以把位置向量定義為跟詞向量一樣大小,然後兩者加起來。
FaceBook 的論文用的是前者,而 Google 論文中用的是後者。直覺上相加會導致資訊損失,似乎不可取,但 Google 的成果說明相加也是很好的方案。看來我理解還不夠深刻。
一些不足之處
到這裡,Attention 機制已經基本介紹完了。Attention 層的好處是能夠一步到位捕捉到全域性的聯絡,因為它直接把序列兩兩比較(代價是計算量變為 ?(n2),當然由於是純矩陣運算,這個計算量相當也不是很嚴重)。
相比之下,RNN 需要一步步遞推才能捕捉到,而 CNN 則需要透過層疊來擴大感受野,這是 Attention 層的明顯優勢。
Google 論文剩下的工作,就是介紹它怎麼用到機器翻譯中,這是個應用和調參的問題,我們這裡不特別關心它。當然,Google 的結果表明將純註意力機制用在機器翻譯中,能取得目前最好的效果,這結果的確是輝煌的。
然而,我還是想談談這篇論文字身和 Attention 層自身的一些不足的地方。
1. 論文標題為 Attention is All You Need,因此論文中刻意避免出現了 RNN、CNN 的字眼,但我覺得這種做法過於刻意了。
事實上,論文還專門命名了一種 Position-wise Feed-Forward Networks,事實上它就是視窗大小為 1 的一維摺積,因此有種為了不提摺積還專門換了個名稱的感覺,有點不厚道。(也有可能是我過於臆測了)。
2. Attention 雖然跟 CNN 沒有直接聯絡,但事實上充分借鑒了 CNN 的思想,比如 Multi-Head Attention 就是 Attention 做多次然後拼接,這跟 CNN 中的多個摺積核的思想是一致的;還有論文用到了殘差結構,這也源於 CNN 網路。
3. 無法對位置資訊進行很好地建模,這是硬傷。儘管可以引入 Position Embedding,但我認為這隻是一個緩解方案,並沒有根本解決問題。
舉個例子,用這種純 Attention 機制訓練一個文字分類模型或者是機器翻譯模型,效果應該都還不錯,但是用來訓練一個序列標註模型(分詞、物體識別等),效果就不怎麼好了。
那為什麼在機器翻譯任務上好?我覺得原因是機器翻譯這個任務並不特別強調語序,因此 Position Embedding 所帶來的位置資訊已經足夠了,此外翻譯任務的評測指標 BLEU 也並不特別強調語序。
4、並非所有問題都需要長程的、全域性的依賴的,也有很多問題只依賴於區域性結構,這時候用純 Attention 也不大好。
事實上,Google 似乎也意識到了這個問題,因此論文中也提到了一個 restricted 版的 Self-Attention(不過論文正文應該沒有用到它)。
它假設當前詞只與前後 r 個詞發生聯絡,因此註意力也只發生在這 2r+1 個詞之間,這樣計算量就是 ?(nr),這樣也能捕捉到序列的區域性結構了。但是很明顯,這就是摺積核中的摺積視窗的概念。
透過以上討論,我們可以體會到,把 Attention 作為一個單獨的層來看,跟 CNN、RNN 等結構混合使用,應該能更充分融合它們各自的優勢,而不必像 Google 論文號稱 Attention is All You Need,那樣實在有點“矯枉過正”了(“口氣”太大),事實上也做不到。
就論文的工作而言,也許降低一下身段,稱為 Attention is All Seq2Seq Need(事實上也這標題的“口氣”也很大),會獲得更多的肯定。
程式碼實現
最後,為了使得本文有點實用價值,筆者試著給出了論文的 Multi-Head Attention 的實現程式碼。有需要的讀者可以直接使用,或者參考著修改。
註意的是,Multi-Head 的意思雖然很簡單——重覆做幾次然後拼接,但事實上不能按照這個思路來寫程式,這樣會非常慢。因為 TensorFlow 是不會自動並行的,比如:
a = tf.zeros((10, 10))
b = a + 1
c = a + 2
其中 b,c 的計算是串聯的,儘管 b,c 沒有相互依賴。因此我們必須把 Multi-Head 的操作合併到一個張量來運算,因為單個張量的乘法內部則會自動並行。
此外,我們要對序列做 Mask 以忽略填充部分的影響。一般的 Mask 是將填充部分置零,但 Attention 中的 Mask 是要在 softmax 之前,把填充部分減去一個大整數(這樣 softmax 之後就非常接近 0 了)。這些內容都在程式碼中有對應的實現。
TensorFlow 版
https://github.com/bojone/attention/blob/master/attention_tf.py
Keras 版
https://github.com/bojone/attention/blob/master/attention_keras.py
程式碼測試
在 Keras 上對 IMDB 進行簡單的測試(不做 Mask):
from __future__ import print_function
from keras.preprocessing import sequence
from keras.datasets import imdb
max_features = 20000
maxlen = 80
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
from keras.models import Model
from keras.layers import *
S_inputs = Input(shape=(None,), dtype='int32')
embeddings = Embedding(max_features, 128)(S_inputs)
#embeddings = Position_Embedding()(embeddings) #增加Position_Embedding能輕微提高準確率
O_seq = Attention(8,16)([embeddings,embeddings,embeddings])
O_seq = GlobalAveragePooling1D()(O_seq)
O_seq = Dropout(0.5)(O_seq)
outputs = Dense(1, activation='sigmoid')(O_seq)
model = Model(inputs=S_inputs, outputs=outputs)
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=5,
validation_data=(x_test, y_test))
無 Position Embedding 的結果:

有 Position Embedding 的結果:

貌似最高準確率比單層的 LSTM 準確率還高一點,另外還可以看到 Position Embedding 能提高準確率、減弱過擬合。
計算量分析
可以看到,事實上 Attention 的計算量並不低。比如 Self Attention 中,首先要對 X 做三次線性對映,這計算量已經相當於摺積核大小為 3 的一維摺積了,不過這部分計算量還只是 ?(n) 的;然後還包含了兩次序列自身的矩陣乘法,這兩次矩陣乘法的計算量都是 ?(n2) 的,要是序列足夠長,這個計算量其實是很難接受的。
這也表明,restricted 版的 Attention 是接下來的研究重點,並且將 Attention 與 CNN、RNN 混合使用,才是比較適中的道路。
結語
感謝 Google 提供的精彩的使用案例,讓我等在大開眼界之餘,還對 Attention 的認識更深一層。Google 的這個成果在某種程度上體現了“大道至簡”的理念,的確是 NLP 中不可多得的精品。
本文圍繞著 Google 的大作,班門弄斧一番,但願能夠幫助有需要的讀者更好的理解 Attention。最後懇請大家建議和批評。
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群