
我們最近在Kubernetes之上開發了一個分散式cron[1]作業排程系統。Kubernetes目前非常流行,是一個非常棒的容器編排平臺,而且有很多新功能,其中一個就是工程師們不需要知道應用執行在哪臺虛機上。
分散式系統其實很複雜,而管理分散式系統則是運維團隊面臨的更複雜問題。在生產環境中引入新軟體並學會如何可靠使用是很嚴肅的問題。例如:為什麼學會操作Kubernetes很重要就是一個例子,這裡有一個由Kubernetes bug引起一個小時系統癱瘓問題的事後總結。

Kubernetes是在叢集內排程應用的分散式系統。如果通知Kubernetes執行某個應用的五個實體,Kubernetes則會動態在工作節點上排程起它們。透過自動化排程容器可以增加硬體裝置的利用率並且節省費用,強大部署能力使得開發者可以細粒度更新程式碼,安全背景關係和網路策略則使得多租戶工作流更加安全執行。
每個專案都會從一個業務需求開始。我們的目的是提高已有的基於cron作業系統的可靠性和安全性。需求如下:
-
需要由小團隊運維(本專案只有兩個全職員工)。
-
需要在20臺裝置內排程大約500個不同作業。
我們選擇Kubernetes作為基礎的原因是:
-
希望採用開源系統
-
Kubernetes有一套內建分散式cron作業排程器,我們不需要重新寫一個
-
Kubernetes很活躍,並且樂於接受程式碼貢獻
-
Kubernetes用Go開發(比較易於學習)。幾乎所有bug修複都是有我們團隊不專業的Go開發者提交的
-
如果我們可以順利操作Kubernetes,我們未來就可以在其上開發(例如,我們現在在Kubernetes之上訓練機器學習模型)。
以前我們使用Chronos作為cron作業排程系統,但是目前不能滿足我們的需求,而且不可維護(活躍度很低)因此我們決定不再採用它。
我們有三種主要標的:
-
99.99%的cron工作需要在被排程後20分鐘之內執行,20分鐘是很寬的視窗,但是客戶並沒有更精確的需求。
-
作業應該佔據99.99%的排程時間片(不被幹擾)
-
遷移到Kubernetes不應引起任何客戶端問題
這意味著:
-
Kubernetes API短期故障時可以容忍的(如果出現十分鐘的故障,只要五分鐘之內恢復就是可以容忍的)。
-
排程bugs(當一個cron作業無法執行)是不可接受的。這是一個很嚴重的問題。
-
需要關註Pod退出和安全停止方式,以便作業不會頻繁被終止。 因此我們需要一個細緻的遷移方案。
建立第一個Kubernetes叢集最基本方法就是從零開始而不是使用例如kubeadm或者kops之類的工具。我們透過Puppet提供配置,這是一個常用的配置管理工具。從零建立有兩個原因:能夠深度整合Kubernetes到既有架構,並且深入理解其內部機制。
從零開始可以幫助我們更好將Kubernetes整合到現存架構。我們想無縫地整合到日誌、認證管理、網路安全、監控、AWS實體管理、部署、資料庫代理、內部DNS服務、配置管理等系統中,看起來需要不少精力,但是整體上看比嘗試使用kubeadm/kops這些工具來實現標的要容易一些。
因為我們對這些現有系統已經很熟悉了,希望繼續在Kubernetes叢集中使用它們。例如,安全認證管理一般是一個難點,總是會有這樣那樣的問題。我們不應該因為採用了Kubernetes而嘗試採用一種全新的CA系統。
剛開始Kubernetes整合時,團隊裡沒有人用過,如何才能從“小白”到“高手”呢?

策略0:與其他公司使用者溝通
我們經常會與其他使用過Kubernetes的公司討論,他們也都會在不同場合下使用Kubernetes(在物理機、或者Google Kubernetes Engine上執行HTTP服務,等等)。與這些有著實際經驗的,執行大型或者複雜系統的公司溝通後,才會認識到自己使用場景的關鍵點,建立自己的經驗,建立使用的信心,最終做決定。不能只是因為讀了這篇部落格就認為“好吧,Stirpe成功使用了Kubernetes,因此對我們應該也適用”。
以下是我們跟一些採用Kubernetes叢集架構的公司溝通後學到的經驗:
-
重點工作要放在etcd叢集可靠性上(etcd是儲存所有Kubernetes叢集狀態的地方)。
-
某些Kubernetes功能並不很完善,因此使用alpha版本功能時要很小心。有些公司會以慢一個或幾個發行版的方式來採用穩定版本的功能。
-
假設使用hosted Kubernetes系統,例如GKE/AKS/EKS專案,從零開始配置一個高可用Kubernetes叢集有大量工作要做,對於這些專案AWS目前還沒有一個成熟Kubernetes服務,因此並不適合我們。
-
另外還需要非常當心overley網路、軟體定義網路帶來的延遲。
當然與其他公司的溝通並不能解決我們自己的問題,但是會給我們更多的啟發,並去關註重要的事情。
策略1:讀程式碼
我們會依賴Kubernetes的cronjob控制器元件,它目前還是alpha狀態,使得我們很擔心,儘管在測試系統上使用了,但是如何能夠保證在生產上不出問題呢?
幸虧cronjob控制器的代買只有區區400行Go語言程式碼,可以快速讀完程式碼,並且可以看出:
-
cronjob控制器是一個無狀態服務(和其它非etcd元件類似)
-
每十秒鐘,控制器呼叫syncAll服務:go wait.Until(jm.syncAll, 10*time.Second, stopCh)
-
syncAll服務從Kubernetes API中獲取所有cronjobs,檢索串列,決定下一個執行那個作業,並啟動它。
核心邏輯很簡單,但是最重要的是我們覺得,如果有什麼bug,我們應該能夠修複。
策略2:壓力測試
開始建立叢集前,我們做了不少壓力測試。我們並不擔心Kubernetes叢集能夠處理多少節點(我們計劃部署大約20個節點),但是我們很關註Kubernetes能處理多少cron作業(我們計劃至少每分鐘50個)。
我們在三節點叢集上測試,建立了1000個每分鐘執行一次的cron作業。這些作業簡單執行bash -c ‘echo hello world’,只是為了測試叢集排程和編排能力,而不是測試計算資源消耗。
策略3:重點在高可用etcd叢集
執行Kubernetes叢集最重要的事情還是執行etcd。etcd是Kubernetes叢集心臟,所有叢集相關資料都存放在這裡,除了etcd之外的都是無狀態量。如果etcd失效,儘管服務還在執行,但是無法對Kubernetes叢集修改。
下圖展示的是etcd如何作為核心部件起效的:API伺服器作為在etcd前端,提供無狀態、認證服務,其他元件都透過API伺服器跟etcd溝通。

執行時,有兩個重要的觀念:
-
為了避免叢集節點故障,必須配置副本replication。目前我們有三個副本。
-
確保有足夠IO頻寬。我們使用的etcd版本有個問題,當某個節點因為fsync造成延遲時會觸發持續的選舉,造成叢集不穩定。透過確保每個節點有足夠的IO頻寬(比etcd些操作要多)解決了這個問題
設定副本並不是一個一蹴而就的事情,我們透過仔細調整此引數最終實現丟失一個節點,叢集可以很穩健地恢復。
以下是我們對etcd所做的操作:
-
設定副本
-
監控etcd服務是否有效
-
寫一個簡單工具可以很容易啟用新etcd節點,並將它們加入叢集
-
改寫etcd使得一個生產系統可以有多套etcd叢集執行
-
測試從etcd備份中恢復
-
測試0時間重建叢集
很高興我們在早期就做了這些測試。某個週五早上,某套生產系統的一個etcd節點停止服務,我們收到預警,停止了此節點,啟動了新節點,加入叢集,k8s並沒因為這個故障影響服務。非常棒!!
遷移過程中需要避免出現服務停止。遷移成功的秘訣不是如何避免犯錯,而是如何設計遷移策略減少錯誤帶來的影響。
幸運的是我們有很多作業要遷移到新叢集上,因此可以先從低優先順序的作業開始,一般它們出現一到兩個錯誤是可以接受的。
以下是我們所採用的遷移策略:
-
對優先順序進行設定
-
將某些作業重覆地遷移到Kubernetes,如果發現問題,就回滾,修複問題,再次嘗試。
專案開始前我們制定了一些準則,如果Kubernetes發現異常,需要查明原因,然後修正問題。
查詢原因非常消耗時間但是很值得。如果只是繞過Kubernetes系統帶來的問題,對未來採用更大規模叢集只能是心懷恐懼。
採用此策略後,我們發現了Kubernetes中一些bug(我們能夠修複)。
-
作業名長於52個字元的Cronjobs自動失敗
-
掛起狀態的Pod有時候會徹底阻塞
-
排程器每三個小時會崩坍一次
-
Flanel維護的hostgw後端並不改寫過期的路由表
修複這些bugs使得我們對Kubernetes專案更加有信心,不只是解決了問題,而且還因為它們接受了我們的補丁以及有一套很好的跟蹤修複流程。
跟其他軟體一樣,Kubernetes肯定有各種bugs。特別地,我們嚴重依賴排程器(因為我們的cron作業會經常建立新Pod),排程器使用的快取會經常出現bugs,回退或者崩坍。快取是個難點,但是因為可以訪問原始碼,因此我們可以自己處理這些問題。
另外一個值得討論的問題是Kubernetes Pod採用的eviction遷移邏輯。Kubernetes有一個模組叫節點控制器,負責當某個節點失效時將其上執行的Pods遷移到其它節點上。有可能所有節點暫時無響應(例如,因為網路或者配置問題),此時Kubernetes會將叢集內所有Pods都終止。我們測試早期就發現了這個問題。
如果執行大規模叢集,就要仔細閱讀節點控制器檔案[4],考慮配置,壓力測試。每次當修改這些配置(例如–pod-eviction-timeout),進行測試時,總是有驚訝的事情發生。所以儘早在測試環境中發現問題總比在凌晨三點生產系統出問題好。
策略6:故意引入Kubernetes叢集問題進行演練
在Stripe會經常舉行演練“game day excises[5]”,現在仍然再繼續。這個想法是設想一個未來會發生的場景(例如,Kubernetes API伺服器失效了),故意在生產系統中造成這種問題,確保能夠處理這種問題。
我們經常做的演練包括:
-
終止某個Kubernetes API伺服器
-
終止所有API伺服器,再恢復它們
-
終止etcd節點
-
從API伺服器端中斷與工作節點的通訊,此節點上所有Pod被遷移到其它節點上去
很高興看到Kubernetes能夠很好處理這些問題,Kubernetes設計思路就是對錯誤提供彈性,有一個etcd叢集儲存所有狀態,一個API伺服器提供簡單REST介面訪問資料庫,以及一系列無狀態控制器協調整個叢集執行。
如果某個元件出問題,重啟後會從etcd中讀取狀態,然後繼續無縫執行。這是一套經驗證沒問題的工作機制。
我們在測試中發現了一些問題:
-
真奇怪,這裡居然沒有通知我。需要看看監控哪裡出了問題
-
當我們重啟API伺服器時,需要人工幹預,需要解決這個問題
-
有時候做etcd切換時,API伺服器會出現超時錯,除非重啟
透過這些實驗,我們解決了這些發現的問題:提高了監控能力,修複了配置上的問題,記錄了Kubernetes中的bugs。
總結一下如何做到這點:
name: job-name-here
kubernetes:
schedule: '15 */2 * * *'
command:
- ruby
- "/path/to/script.rb"
resources:
requests:
cpu: 0.1
memory: 128M
limits:
memory: 1024M
我們並沒有太多創新,只是寫了一個簡單的程式將格式轉化成Kubernetes cron作業的配置檔案,kubectl可以呼叫它而已。
我們也寫了測試包確保作業名不會太長(不能超過52個字元),以及作業名是唯一的。我們現在不用cgroups強制記憶體限制,但是未來可能會嘗試它。
這個簡單的格式易於使用,因為在Chronos和Kubernetes之間採用同樣的定義格式,在他們之間切換非常方便。這也是一個成功的地方。當Kubernetes中出現問題,可以很快使用簡單命令修改並生效。
監控Kubernetes內部狀態是很成功的嘗試。我們使用kube-state-metrics包監控,使用一個很輕的Go程式叫做veneur-prometheus從Prometheus中抓取資料,釋出到我們自己監控系統中。
例如,下圖是叢集中上一個小時掛起的Pods示意圖。掛起意味著等待被排程到某個工作節點上執行。可以看到在11am時有個峰值,因為很多cron作業都是在這個時間執行的。
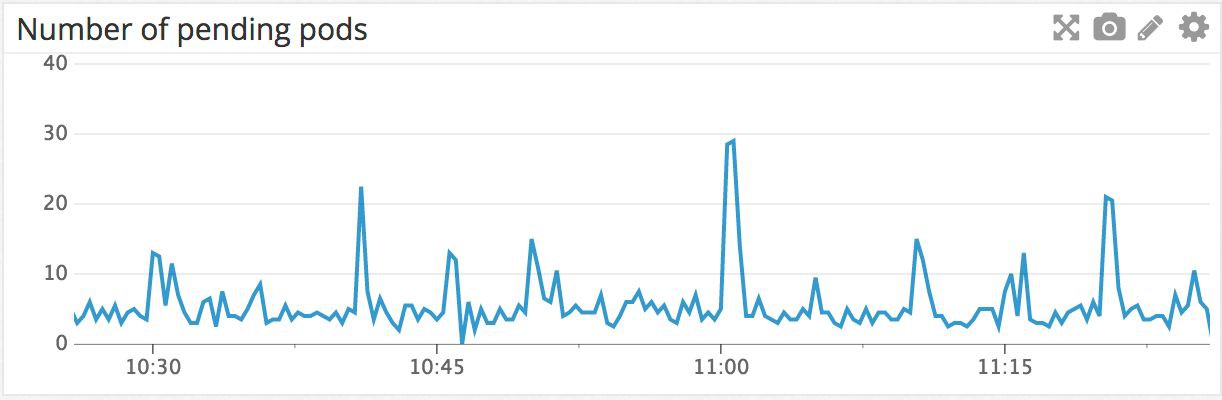
我們也有一個監控工具檢查是否有Pod會在掛起狀態卡死,我們會每五分鐘檢查一次啟動的Pod是否已經在節點上執行,如果有卡死的情況則發出警告。
從決定採用Kubernetes,到我們建立了滿意的生產系統,並將所有cron作業都移到新系統上花費了三個工程師五個月的時間,我們還期望Kubernetes能夠在Stripe內部更多地方派上用場。
以下是我們總結出來的Kubernetes使用寶典:
-
定義清晰的Kubernetes專案業務原因,理解業務會使得專案進展更加容易
-
縮小專案規模。我們會避免使用很多Kubernetes功能,簡化叢集。這使得我們進度更快。
-
花更多的時間在如何更好運轉Kubernetes叢集。
如果能夠遵守這些準則,則可以更加自信在生產中使用Kubernetes。我們會持續使用Kubernetes技術。例如,我們會關註AWS的EKS。我們正在完成一個機器學習模型,希望將HTTP服務部分轉換到Kubernetes上來。隨著我們更多在生產中使用Kubernetes,期望以這種方式更多反饋到開源專案中來。
相關連結:
-
https://en.wikipedia.org/wiki/Cron
-
https://www.youtube.com/watch?v=HlAXp0-M6SY
-
https://vimeo.com/173610242
-
https://kubernetes.io/docs/concepts/architecture/nodes/#node-controller
-
https://stripe.com/blog/game-day-exercises-at-stripe
原文連結:https://stripe.com/blog/operating-kubernetes

本次培訓包含:Kubernetes核心概念;Kubernetes叢集的安裝配置、運維管理、架構規劃;Kubernetes元件、監控、網路;針對於Kubernetes API介面的二次開發;DevOps基本理念;Docker的企業級應用與運維等,點選識別下方二維碼加微信好友瞭解具體培訓內容。
