(點選上方公眾號,可快速關註)
來源: 猴子007,
monkeysayhi.github.io/2017/12/15/String常量池和String-intern/
String是Java基礎的重要考點。可問的點多,而且很多點可以橫向切到其他考點,或縱向深入JVM。
本文略過了String的基本內容,重點在於String#intern()。
String常量池
String常量可能會在兩種時機進入常量池:
-
編譯期:透過雙引號宣告的常量(包括顯示宣告、靜態編譯最佳化後的常量,如”1”+”2”最佳化為常量”12”),在前端編譯期將被靜態的寫入class檔案中的“常量池”。該“常量池”會在類載入後被載入“記憶體中的常量池”,也就是我們平時所說的常量池。同時,JIT最佳化也可能產生類似的常量。
-
執行期:呼叫String#intern()方法,可能將該String物件動態的寫入上述“記憶體中常量池”。
時機1的行為是明確的。原理可閱讀class檔案結構、類載入、編譯期即執行期最佳化等內容。
時機2在jdk6和jdk7中的行為不同,下麵討論。
String#intern()
讀者可直接閱讀參考資料。下述總結僅為了猴子自己複習方便。
宣告
/**
* Returns a canonical representation for the string object.
*
* A pool of strings, initially empty, is maintained privately by the
* class
String.*
* When the intern method is invoked, if the pool already contains a
* string equal to this
Stringobject as determined by* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this
Stringobject is added to the* pool and a reference to this
Stringobject is returned.*
* It follows that for any two strings
sandt,*
s.intern() == t.intern()istrue* if and only if
s.equals(t)istrue.*
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* The Java™ Language Specification.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
String#intern()是一個native方法。根據Javadoc,如果常量池中存在當前字串, 就會直接傳回當前字串. 如果常量池中沒有此字串, 會將此字串放入常量池中後, 再傳回。
實現原理
JNI最後呼叫了c++實現的StringTable::intern()方法:
oop StringTable::intern(Handle string_or_null, jchar* name,
int len, TRAPS) {
unsigned int hashValue = java_lang_String::hash_string(name, len);
int index = the_table()->hash_to_index(hashValue);
oop string = the_table()->lookup(index, name, len, hashValue);
// Found
if (string != NULL) return string;
// Otherwise, add to symbol to table
return the_table()->basic_add(index, string_or_null, name, len,
hashValue, CHECK_NULL);
}
oop StringTable::lookup(int index, jchar* name,
int len, unsigned int hash) {
for (HashtableEntry
* l = bucket(index); l != NULL; l = l->next()) { if (l->hash() == hash) {
if (java_lang_String::equals(l->literal(), name, len)) {
return l->literal();
}
}
}
return NULL;
}
在the_table()傳回的hash表中查詢字串,如果存在就傳回,否則加入表。
StringTable是一個固定大小的Hashtable,預設大小是1009。基本邏輯與Java中HashMap相同,也使用拉鏈法解決碰撞問題。
既然是拉鏈法,那麼如果放進的String非常多,就會加劇碰撞,導致連結串列非常長。最壞情況下,String#intern()的效能由O(1)退化到O(n)。
-
jdk6中StringTable的長度固定為1009。
-
jdk7中,StringTable的長度可以透過一個引數-XX:StringTableSize指定,預設1009。
jdk6和jdk7下String#intern()的區別
引言
相信很多Java程式員都做類似String s = new String(“abc”);這個陳述句建立了幾個物件的題目。這種題目主要是為了考察程式員對字串物件常量池的掌握。上述的陳述句中建立了2個物件:
-
第一個物件,內容”abc”,儲存在常量池中。
-
第二個物件,內容”abc”,儲存在堆中。
問題
來看一段程式碼:
public static void main(String[] args) {
String s = new String(“1”);
s.intern();
String s2 = “1”;
System.out.println(s == s2);
String s3 = new String(“1”) + new String(“1”);
s3.intern();
String s4 = “11”;
System.out.println(s3 == s4);
}
列印結果:
# jdk6下
false false
# jdk7下
false true
具體為什麼稍後再解釋,然後將s3.intern();陳述句下調一行,放到String s4 = “11”;後面。將s.intern();放到String s2 = “1”;後面:
public static void main(String[] args) {
String s = new String(“1”);
String s2 = “1”;
s.intern();
System.out.println(s == s2);
String s3 = new String(“1”) + new String(“1”);
String s4 = “11”;
s3.intern();
System.out.println(s3 == s4);
}
列印結果:
# jdk6下
false false
# jdk7下
false false
jdk6的解釋

註:圖中綠色線條代表String物件的內容指向;黑色線條代表地址指向。
jdk6中,上述的所有列印都是false。
因為jdk6的常量池放在Perm區中,和正常的Heap(指Eden、Surviver、Old區)完全分開。具體來說:使用引號宣告的字串都是透過編譯和類載入直接載入常量池,位於Perm區;new出來的String物件位於Heap(E、S、O)中。拿一個Perm區的物件地址和Heap中的物件地址進行比較,肯定是不相同的。
Perm區主要儲存一些載入類的資訊、靜態變數、方法片段、常量池等。
jdk7的解釋
在jdk6及之前的版本中,字串常量池都是放在Perm區的。Perm區的預設大小隻有4M,如果多放一些大字串,很容易丟擲OutOfMemoryError: PermGen space。
因此,jdk7已經將字串常量池從Perm區移到正常的Heap(E、S、O)中了。
Perm區即永久代。本身用永久代實現方法區就容易遇到記憶體上限溢位;而且方法區存放的內容也很難估計大小,沒必要放在堆中管理。jdk8已經取消了永久代,在堆外新建了一個Metaspace實現方法區。
正是因為字串常量池移到了Heap中,才產生了上述變化。
第一段程式碼
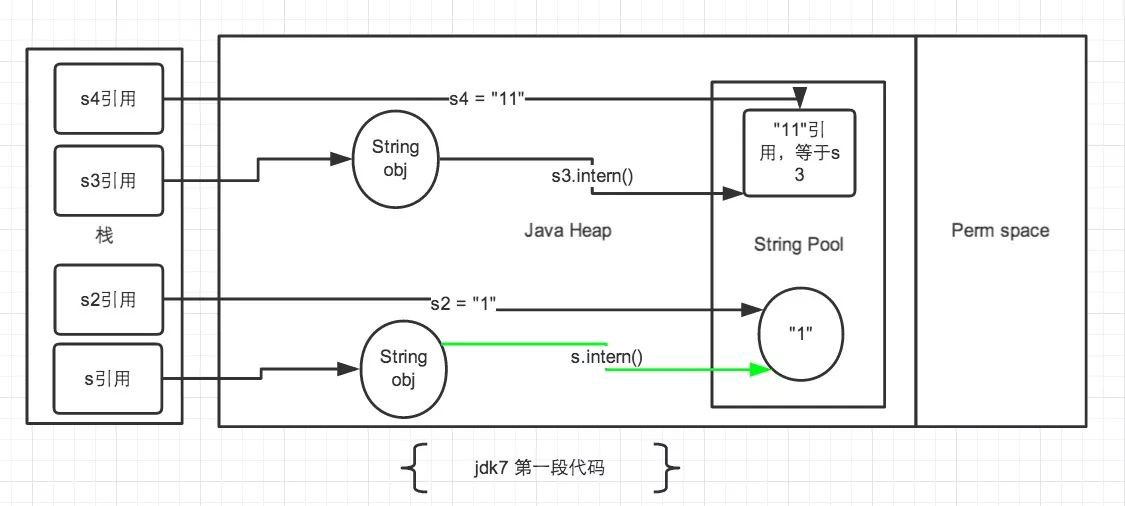
先看s3和s4:
-
首先,String s3 = new String(“1”) + new String(“1”);,生成了多個物件,s3最終指向堆中的”11”。註意,此時常量池中是沒有字串”11”的。
-
然後,s3.intern();,將s3中的字串”11”放入了常量池中,因為此時常量池中不存在字串”11”,因此常規做法與跟jdk6相同,在常量池中生成一個String物件”11”——然而,jdk7中常量池不在Perm區中了,相應做了調整:常量池中不需要再儲存一份物件了,而是直接儲存堆中的取用,也就是s3的取用地址。
-
接下來,String s4 = “11”;,”11”透過雙引號顯示宣告,因此會直接去常量池中查詢,如果沒有再建立。發現已經有這個字串了,也就是剛才透過s3.intern();儲存在常量池中的s3的取用地址。於是,直接傳回s3的取用地址,s4賦值為s3的取用,s4指向堆中的”11”。
-
最後,s3、s4指向的堆中的”11”,常量池中儲存s3的取用,滿足s3 == s4。
再看s和s2:
-
首先,String s = new String(“1”);,生成了2個物件,常量池中的”1”和堆中的”1”,s指向堆中的”1”。
-
然後,s.intern();,上一句已經在常量池中建立了”1”,所以此處什麼都不做。
-
接下來,,String s2 = “1”;,常量池中有”1”,因此,s2直接指向常量池中的”1”。
-
最後,s指向的堆中的”1”,s2指向常量池中的”1”,常量池中儲存字串”1”,不滿足s == s2。
第二段程式碼
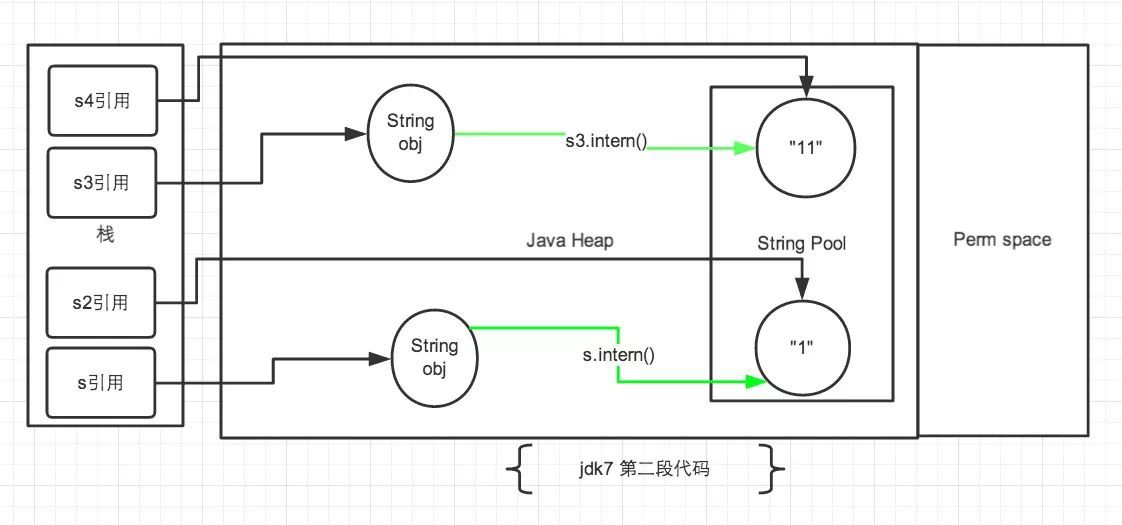
先看s3和s4,將s3.intern();放在了String s4 = “11”;後:
-
先執行String s4 = “11”;,此時,常量池中不存在”11”,因此,將”11”放入常量池,然後s4指向常量池中的”11”。
-
再執行s3.intern();,上一句已經在常量池中建立了”11”,所以此處什麼都不做。
-
最後,s3仍指向的堆中的”11”,s4指向常量池中的”11”,常量池中儲存字串”11”,不再滿足s3 == s4。
再看s和s2,將s.intern();放到String s2 = “1”;後:
-
先執行String s2 = “1”;,之前已透過String s = new String(“1”);在常量池中建立了”1”,因此,s2直接指向常量池中的”1”。
-
再執行s.intern();,常量池中有”1”,所以此處什麼都不做。
-
最後,s指向的堆中的”1”,s2指向常量池中的”1”,常量池中儲存字串”1”,仍不滿足s == s2。
區別小結
jdk7與jdk6相比,對String常量池的位置、String#intern()的語意都做了修改:
-
將String常量池從Perm區移到了Heap區。
-
呼叫String#intern()方法時,堆中有該字串而常量池中沒有,則直接在常量池中儲存堆中物件的取用,而不會在常量池中重新建立物件。
使用姿勢
建議直接閱讀參考資料。
額外的問題
String#intern()的基本用法如下:
String s1 = xxx1.toString().intern();
String s2 = xxx2.toString().intern();
assert s1 == s2;
然而,xxx1.toString()、xxx2.toString()已經建立了兩個匿名String物件,這之後再呼叫String#intern()。那麼,這兩個匿名物件去哪了?
估計猴子對建立物件的過程理解有問題,或許xxx1.toString()傳回時還沒有將物件儲存到堆上?或許String#intern()上做了什麼語法糖?
後面有時間再解決吧。
參考
-
深入解析String#intern
http://tech.meituan.com/in_depth_understanding_string_intern.html
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

