在上一篇文章你真的瞭解字典嗎?一文中我介紹了Hash Function和字典的工作的基本原理.
有網友在文章底部評論,說我的Remove和Add方法沒有考慮執行緒安全問題.
https://docs.microsoft.com/en-us/dotnet/api/system.collections.generic.dictionary-2?redirectedfrom=MSDN&view;=netframework-4.7.2
查閱相關資料後,發現字典.net中Dictionary本身時不支援執行緒安全的,如果要想使用支援執行緒安全的字典,那麼我們就要使用ConcurrentDictionary了.
在研究ConcurrentDictionary的原始碼後,我覺得在ConcurrentDictionary的執行緒安全的解決思路很有意思,其對執行緒安全的處理對對我們專案中的其他高併發場景也有一定的參考價值,在這裡再次分享我的一些學習心得和體會,希望對大家有所幫助.
ConcurrentDictionary是Dictionary的執行緒安全版本,位於System.Collections.Concurrent的名稱空間下,該名稱空間下除了有ConcurrentDictionary,還有以下Class都是我們常用的那些類庫的執行緒安全版本.
BlockingCollection:為實現 IProducerConsumerCollection 的執行緒安全集合提供阻塞和限制功能。
ConcurrentBag:表示物件的執行緒安全的無序集合.
ConcurrentQueue:表示執行緒安全的先進先出 (FIFO) 集合。
如果讀過我上一篇文章你真的瞭解字典嗎?的小夥伴,對這個ConcurrentDictionary的工作原理應該也不難理解,它是簡簡單單地在讀寫方法加個lock嗎?
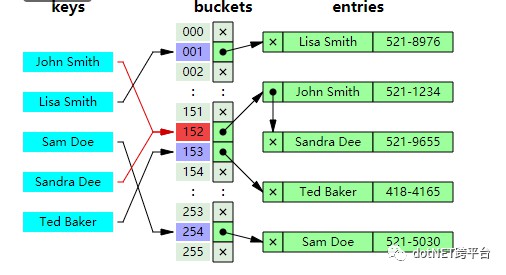
Dictionary
如下圖所示,在字典中,陣列entries用來儲存資料,buckets作為橋梁,每次透過hash function獲取了key的雜湊值後,對這個雜湊值進行取餘,即hashResult%bucketsLength=bucketIndex,餘數作為buckets的index,而buckets的value就是這個key對應的entry所在entries中的索引,所以最終我們就可以透過這個索引在entries中拿到我們想要的資料,整個過程不需要對所有資料進行遍歷,的時間複雜度為1.
ConcurrentDictionary
ConcurrentDictionary的資料儲存類似,只是buckets有個更多的職責,它除了有dictionary中的buckets的橋梁的作用外,負責了資料儲存.
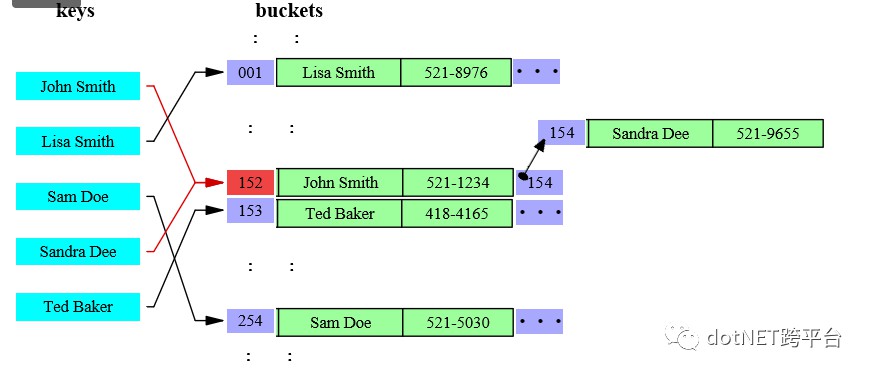
key的雜湊值與buckets的length取餘後hashResult%bucketsLength=bucketIndex,餘數作為buckets的索引就能找到我們要的資料所儲存的塊,當出現兩個key指向同一個塊時,即上圖中的John Smith和Sandra Dee他同時指向152怎麼辦呢?儲存節點Node具有Next屬性執行下個Node,上圖中,node 152的Next為154,即我們從152開始找Sandra Dee,發現不是我們想要的,再到154找,即可取到所需資料.
由於官方原版的原始碼較為複雜,理解起來有所難度,我對官方原始碼做了一些精簡,下文將圍繞這個精簡版的ConcurrentDictionary展開敘述.
https://github.com/liuzhenyulive/DictionaryMini
資料結構
Node
ConcurrentDictionary中的每個資料儲存在一個Node中,它除了儲存value資訊,還儲存key資訊,以及key對應的hashcode
private class Node
{
internal TKey m_key;
internal TValue m_value;
internal volatile Node m_next;
internal int m_hashcode;
internal Node(TKey key, TValue value, int hashcode, Node next)
{
m_key = key;
m_value = value;
m_next = next;
m_hashcode = hashcode;
}
}
Table
而整個ConcurrentDictionary的資料儲存在這樣的一個Table中,其中m_buckets的Index負責對映key,m_locks是執行緒鎖,下文中會有詳細介紹,m_countPerLock儲存每個lock鎖負責的node數量.
private class Tables
{
internal readonly Node[] m_buckets;
internal readonly object[] m_locks;
internal volatile int[] m_countPerLock;
internal readonly IEqualityComparer m_comparer;
internal Tables(Node[] buckets, object[] locks, int[] countPerlock, IEqualityComparer comparer)
{
m_buckets = buckets;
m_locks = locks;
m_countPerLock = countPerlock;
m_comparer = comparer;
}
}
ConcurrentDictionary會在建構式中建立Table,這裡我對原有的建構式進行了簡化,透過預設值進行建立,其中DefaultConcurrencyLevel預設併發級別為當前計算機處理器的執行緒數.
public ConcurrentDictionaryMini() : this(DefaultConcurrencyLevel, DEFAULT_CAPACITY, true,
EqualityComparer.Default)
{
}
internal ConcurrentDictionaryMini(int concurrencyLevel, int capacity, bool growLockArray, IEqualityComparer comparer)
{
if (concurrencyLevel < 1)
{
throw new Exception("concurrencyLevel 必須為正數");
}
if (capacity < 0)
{
throw new Exception("capacity 不能為負數.");
}
if (capacity < concurrencyLevel)
{
capacity = concurrencyLevel;
}
object[] locks = new object[concurrencyLevel];
for (int i = 0; i < locks.Length; i++)
{
locks[i] = new object();
}
int[] countPerLock = new int[locks.Length];
Node[] buckets = new Node[capacity];
m_tables = new Tables(buckets, locks, countPerLock, comparer);
m_growLockArray = growLockArray;
m_budget = buckets.Length / locks.Length;
}
方法
ConcurrentDictionary中較為基礎重點的方法分別位Add,Get,Remove,Grow Table方法,其他方法基本上是建立在這四個方法的基礎上進行的擴充.
Add
向Table中新增元素有以下亮點值得我們關註.
-
開始操作前會宣告一個tables變數來儲存操作開始前的m_tables,在正式開始操作後(進入lock)的時候,會檢查tables在準備工作階段是否別的執行緒改變,如果改變了,則重新開始準備工作並從新開始.
-
透過GetBucketAndLockNo方法獲取bucket索引以及lock索引,其內部就是取餘操作.
private void GetBucketAndLockNo(
int hashcode, out int bucketNo, out int lockNo, int bucketCount, int lockCount)
{
bucketNo = (hashcode & 0x7fffffff) % bucketCount;
lockNo = bucketNo % lockCount;
}
-
對資料進行操作前會從m_locks取出第lockNo個物件最為lock,操作完成後釋放該lock.多個lock一定程度上減少了阻塞的可能性.
-
在對資料進行更新時,如果該Value的Type為允許原子性寫入的,則直接更新該Value,否則建立一個新的node進行改寫.
private static bool IsValueWriteAtomic()
{
Type valueType = typeof(TValue);
if (valueType.IsClass)
{
return true;
}
switch (Type.GetTypeCode(valueType))
{
case TypeCode.Boolean:
case TypeCode.Byte:
case TypeCode.Char:
case TypeCode.Int16:
case TypeCode.Int32:
case TypeCode.SByte:
case TypeCode.Single:
case TypeCode.UInt16:
case TypeCode.UInt32:
return true;
case TypeCode.Int64:
case TypeCode.Double:
case TypeCode.UInt64:
return IntPtr.Size == 8;
default:
return false;
}
}
該方法依據CLI規範進行編寫,簡單來說,32位的計算機,對32位元組以下的資料型別寫入時可以一次寫入的而不需要移動記憶體指標,64位計算機對64位以下的資料可一次性寫入,不需要移動記憶體指標.保證了寫入的安全.
詳見12.6.6 http://www.ecma-international.org/publications/files/ECMA-ST/ECMA-335.pdf
private bool TryAddInternal(TKey key, TValue value, bool updateIfExists, bool acquireLock, out TValue resultingValue)
{
while (true)
{
int bucketNo, lockNo;
int hashcode;
Tables tables = m_tables;
IEqualityComparer comparer = tables.m_comparer;
hashcode = comparer.GetHashCode(key);
GetBucketAndLockNo(hashcode, out bucketNo, out lockNo, tables.m_buckets.Length, tables.m_locks.Length);
bool resizeDesired = false;
bool lockTaken = false;
try
{
if (acquireLock)
Monitor.Enter(tables.m_locks[lockNo], ref lockTaken);
if (tables != m_tables)
continue;
Node prev = null;
for (Node node = tables.m_buckets[bucketNo]; node != null; node = node.m_next)
{
if (comparer.Equals(node.m_key, key))
{
if (updateIfExists)
{
if (s_isValueWriteAtomic)
{
node.m_value = value;
}
else
{
Node newNode = new Node(node.m_key, value, hashcode, node.m_next);
if (prev == null)
{
tables.m_buckets[bucketNo] = newNode;
}
else
{
prev.m_next = newNode;
}
}
resultingValue = value;
}
else
{
resultingValue = node.m_value;
}
return false;
}
prev = node;
}
Volatile.Write(ref tables.m_buckets[bucketNo], new Node(key, value, hashcode, tables.m_buckets[bucketNo]));
checked
{
tables.m_countPerLock[lockNo]++;
}
if (tables.m_countPerLock[lockNo] > m_budget)
{
resizeDesired = true;
}
}
finally
{
if (lockTaken)
Monitor.Exit(tables.m_locks[lockNo]);
}
if (resizeDesired)
{
GrowTable(tables, tables.m_comparer, false, m_keyRehashCount);
}
resultingValue = value;
return true;
}
}
Get
從Table中獲取元素的的流程與前文介紹ConcurrentDictionary工作原理時一致,但有以下亮點值得關註.
- 讀取bucket[i]在Volatile.Read()方法中進行,該方法會自動對讀取出來的資料加鎖,避免在讀取的過程中,資料被其他執行緒remove了.
- Volatile讀取指定欄位時,在讀取的記憶體中插入一個記憶體屏障,阻止處理器重新排序記憶體操作,如果在程式碼中此方法之後出現讀取或寫入,則處理器無法在此方法之前移動它。
public bool TryGetValue(TKey key, out TValue value)
{
if (key == null) throw new ArgumentNullException("key");
Tables tables = m_tables;
IEqualityComparer comparer = tables.m_comparer;
GetBucketAndLockNo(comparer.GetHashCode(key), out var bucketNo, out _, tables.m_buckets.Length, tables.m_locks.Length);
Node n = Volatile.Read(ref tables.m_buckets[bucketNo]);
while (n != null)
{
if (comparer.Equals(n.m_key, key))
{
value = n.m_value;
return true;
}
n = n.m_next;
}
value = default(TValue);
return false;
}
Remove
Remove方法實現其實也並不複雜,類似我們連結串列操作中移除某個Node.移除節點的同時,還要對前後節點進行連結,相信一塊小夥伴們肯定很好理解.
private bool TryRemoveInternal(TKey key, out TValue value, bool matchValue, TValue oldValue)
{
while (true)
{
Tables tables = m_tables;
IEqualityComparer comparer = tables.m_comparer;
int bucketNo, lockNo;
GetBucketAndLockNo(comparer.GetHashCode(key), out bucketNo, out lockNo, tables.m_buckets.Length, tables.m_locks.Length);
lock (tables.m_locks[lockNo])
{
if (tables != m_tables)
continue;
Node prev = null;
for (Node curr = tables.m_buckets[bucketNo]; curr != null; curr = curr.m_next)
{
if (comparer.Equals(curr.m_key, key))
{
if (matchValue)
{
bool valuesMatch = EqualityComparer.Default.Equals(oldValue, curr.m_value);
if (!valuesMatch)
{
value = default(TValue);
return false;
}
}
if (prev == null)
Volatile.Write(ref tables.m_buckets[bucketNo], curr.m_next);
else
{
prev.m_next = curr.m_next;
}
value = curr.m_value;
tables.m_countPerLock[lockNo]--;
return true;
}
prev = curr;
}
}
value = default(TValue);
return false;
}
}
Grow table
當table中任何一個m_countPerLock的數量超過了設定的閾值後,會觸發此操作對Table進行擴容.
private void GrowTable(Tables tables, IEqualityComparer newComparer, bool regenerateHashKeys,
int rehashCount)
{
int locksAcquired = 0;
try
{
AcquireLocks(0, 1, ref locksAcquired);
if (regenerateHashKeys && rehashCount == m_keyRehashCount)
{
tables = m_tables;
}
else
{
if (tables != m_tables)
return;
long approxCount = 0;
for (int i = 0; i < tables.m_countPerLock.Length; i++)
{
approxCount += tables.m_countPerLock[i];
}
if (approxCount < tables.m_buckets.Length / 4)
{
m_budget = 2 * m_budget;
if (m_budget < 0)
{
m_budget = int.MaxValue;
}
return;
}
}
int newLength = 0;
bool maximizeTableSize = false;
try
{
checked
{
newLength = tables.m_buckets.Length * 2 + 1;
while (newLength % 3 == 0 || newLength % 5 == 0 || newLength % 7 == 0)
{
newLength += 2;
}
}
}
catch (OverflowException)
{
maximizeTableSize = true;
}
if (maximizeTableSize)
{
newLength = int.MaxValue;
m_budget = int.MaxValue;
}
AcquireLocks(1, tables.m_locks.Length, ref locksAcquired);
object[] newLocks = tables.m_locks;
if (m_growLockArray && tables.m_locks.Length < MAX_LOCK_NUMBER)
{
newLocks = new object[tables.m_locks.Length * 2];
Array.Copy(tables.m_locks, newLocks, tables.m_locks.Length);
for (int i = tables.m_locks.Length; i < newLocks.Length; i++)
{
newLocks[i] = new object();
}
}
Node[] newBuckets = new Node[newLength];
int[] newCountPerLock = new int[newLocks.Length];
for (int i = 0; i < tables.m_buckets.Length; i++)
{
Node current = tables.m_buckets[i];
while (current != null)
{
Node next = current.m_next;
int newBucketNo, newLockNo;
int nodeHashCode = current.m_hashcode;
if (regenerateHashKeys)
{
nodeHashCode = newComparer.GetHashCode(current.m_key);
}
GetBucketAndLockNo(nodeHashCode, out newBucketNo, out newLockNo, newBuckets.Length,
newLocks.Length);
newBuckets[newBucketNo] = new Node(current.m_key, current.m_value, nodeHashCode,
newBuckets[newBucketNo]);
checked
{
newCountPerLock[newLockNo]++;
}
current = next;
}
}
if (regenerateHashKeys)
{
unchecked
{
m_keyRehashCount++;
}
}
m_budget = Math.Max(1, newBuckets.Length / newLocks.Length);
m_tables = new Tables(newBuckets, newLocks, newCountPerLock, newComparer);
}
finally
{
ReleaseLocks(0, locksAcquired);
}
}
-
lock[]:在以往的執行緒安全上,我們對資料的保護往往是對資料的修改寫入等地方加上lock,這個lock經常上整個背景關係中唯一的,這樣的設計下就可能會出現多個執行緒,寫入的根本不是一塊資料,卻要等待前一個執行緒寫入完成下一個執行緒才能繼續操作.在ConcurrentDictionary中,透過雜湊演演算法,從陣列lock[]中找出key的準確lock,如果不同的key,使用的不是同一個lock,那麼這多個執行緒的寫入時互不影響的. -
寫入要考慮執行緒安全,讀取呢?不可否認,在大部分場景下,讀取不必去考慮執行緒安全,但是在我們這樣的鏈式讀取中,需要自上而下地查詢,是不是有種可能在查詢個過程中,鏈路被修改了呢?所以ConcurrentDictionary中使用Volatile.Read來讀取出資料,該方法從指定欄位讀取物件取用,在需要它的系統上,插入一個記憶體屏障,阻止處理器重新排序記憶體操作,如果在程式碼中此方法之後出現讀取或寫入,則處理器無法在此方法之前移動它。
-
在ConcurrentDictionary的更新方法中,對資料進行更新時,會判斷該資料是否可以原子寫入,如果時可以原子寫入的,那麼就直接更新資料,如果不是,那麼會建立一個新的node改寫原有node,起初看到這裡時候,我百思不得其解,不知道這麼操作的目的,後面在jeo duffy的部落格中Thread-safety, torn reads, and the like中找到了答案,這樣操作時為了防止torn reads(撕裂讀取),什麼叫撕裂讀取呢?通俗地說,就是有的資料型別寫入時,要分多次寫入,寫一次,移動一次指標,那麼就有可能寫了一半,這個結果被另外一個執行緒讀取走了.比如說我把
劉振宇三個字改成周傑倫的過程中,我先改把劉改成周了,正在我準備去把振改成傑的時候,另外一個執行緒過來讀取結果了,讀到的資料是周振宇,這顯然是不對的.所以對這種,更安全的做法是先把周傑倫三個字寫好在一張紙條上,然後直接替換掉劉振宇.更多資訊在CLI規範12.6.6有詳細介紹. -
checked和unckecked關鍵字.非常量的運算(non-constant)運算在編譯階段和執行時下不會做上限溢位檢查,如下這樣的程式碼時不會丟擲異常的,算錯了也不會報錯。
int ten = 10;
int i2 = 2147483647 + ten;
但是我們知道,int的最大值是2147483647,如果我們將上面這樣的程式碼巢狀在checked就會做上限溢位檢查了.
checked
{
int ten = 10;
int i2 = 2147483647 + ten;
}
相反,對於常量,編譯時是會做上限溢位檢查的,下麵這樣的程式碼在編譯時就會報錯的,如果我們使用unckeck標簽進行標記,則在編譯階段不會做移除檢查.
int a = int.MaxValue * 2;
那麼問題來了,我們當然知道checked很有用,那麼uncheck呢?如果我們只是需要那麼一個數而已,至於上限溢位不上限溢位的關係不大,比如說生成一個物件的HashCode,比如說根據一個演演算法計算出一個相對隨機數,這都是不需要準確結果的,ConcurrentDictionary中對於m_keyRehashCount++這個運算就使用了unchecked,就是因為m_keyRehashCount是用來生成雜湊值的,我們並不關心它有沒有上限溢位.
volatile關鍵字,表示一個欄位可能是由在同一時間執行多個執行緒進行修改。出於效能原因,編譯器\執行時系統甚至硬體可以重新排列對儲存器位置的讀取和寫入。宣告的欄位volatile不受這些最佳化的約束。新增volatile修飾符可確保所有執行緒都能按照執行順序由任何其他執行緒執行的易失性寫入,易失性寫入是一件瘋狂的事情的事情:普通玩家慎用.
本部落格鎖涉及的程式碼都儲存在github中,Take it easy to enjoy it!
https://github.com/liuzhenyulive/DictionaryMini/blob/master/DictionaryMini/DictionaryMini/ConcurrentDictionaryMini.cs
原文地址:https://www.cnblogs.com/CoderAyu/p/10549409.html
