(點選上方公眾號,可快速關註)
轉自:melonstreet
http://www.cnblogs.com/QG-whz/p/5175485.html
哈夫曼編碼簡介
哈夫曼編碼(Huffman Coding)是一種編碼方式,也稱為“赫夫曼編碼”,是David A. Huffman1952年發明的一種構建極小多餘編碼的方法。
在計算機資料處理中,霍夫曼編碼使用變長編碼表對源符號進行編碼,出現頻率較高的源符號採用較短的編碼,出現頻率較低的符號採用較長的編碼,使編碼之後的字串字串的平均長度 、期望值降低,以達到無失真壓縮資料的目的。
舉個例子,現在我們有一字串:
this is an example of a huffman tree
這串字串有36個字元,如果按普通方式儲存這串字串,每個字元佔據1個位元組,則共需要36 * 1 * 8 = 288bit。
經過分析我們發現,這串字串中各字母出現的頻率不同,如果我們能夠按如下編碼:
| 字母 | 頻率 | 編碼 | — | 字母 | 頻率 | 編碼 |
|---|---|---|---|---|---|---|
| space | 7 | 111 | s | 2 | 1011 | |
| a | 4 | 010 | t | 2 | 0110 | |
| e | 4 | 000 | l | 1 | 11001 | |
| f | 3 | 1101 | o | 1 | 00110 | |
| h | 2 | 1010 | p | 1 | 10011 | |
| i | 2 | 1000 | r | 1 | 11000 | |
| m | 2 | 0111 | u | 1 | 00111 | |
| n | 2 | 0010 | x | 1 | 10010 |
編碼這串字串,只需要:
(7+4+4)x3 + (3+2+2+2+2+2+2)x4 + (1+1+1+1+1+1)x 5 = 45+60+30 = 135bit
編碼這串字串只需要135bit!單單這串字串,就壓縮了288-135 = 153bit。
那麼,我們如何獲取每個字串的編碼呢?這就需要哈夫曼樹了。
源字元編碼的長短取決於其出現的頻率,我們把源字元出現的頻率定義為該字元的權值。
哈夫曼樹簡介
哈夫曼又稱最優二叉樹。是一種帶權路徑長度最短的二叉樹。它的定義如下。
哈夫曼樹的定義
假設有n個權值{w1,w2,w3,w4…,wn},構造一棵有n個節點的二叉樹,若樹的帶權路徑最小,則這顆樹稱作哈夫曼樹。這裡面涉及到幾個概念,我們由一棵哈夫曼樹來解釋

1、路徑與路徑長度:從樹中一個節點到另一個節點之間的分支構成了兩個節點之間的路徑,路徑上的分支數目稱作路徑長度。若規定根節點位於第一層,則根節點到第H層的節點的路徑長度為H-1.如樹b:100到60 的路徑長度為1;100到30的路徑長度為2;100到20的路徑長度為3。
2、樹的路徑長度:從根節點到每一節點的路徑長度之和。樹a的路徑長度為1+1+2+2+2+2 = 10;樹b的路徑長度為1+1+2+2+3+3 = 12.
3、節點的權:將樹中的節點賦予一個某種含義的數值作為該節點的權值,該值稱為節點的權;
4、帶權路徑長度:從根節點到某個節點之間的路徑長度與該節點的權的乘積。例如樹b中,節點10的路徑長度為3,它的帶權路徑長度為10 * 3 = 30;
5、樹的帶權路徑長度:樹的帶權路徑長度為所有葉子節點的帶權路徑長度之和,稱為WPL。樹a的WPL = 2*(10+20+30+40) = 200 ;樹b的WPL = 1×40+2×30+3×10+3×20 = 190.而哈夫曼樹就是樹的帶權路徑最小的二叉樹。
構造哈夫曼樹
哈夫曼樹的節點結構
/*哈夫曼樹的節點定義*/
template <typename T>
struct HuffmanNode
{
HuffmanNode(T k,HuffmanNode<T>*l=nullptr,HuffmanNode<T>* r=nullptr)
:key(k),lchild(l), rchild(r){}
~HuffmanNode(){};
T key; //節點的權值
HuffmanNode<T>* lchild; //節點左孩
HuffmanNode<T>* rchild; //節點右孩
};
1、value: 節點的權值
2、lchild:節點左孩子
3、rchild:節點右孩子
哈夫曼樹的抽象資料型別
template <typename T>
class Huffman
{
public:
void preOrder(); //前序遍歷哈夫曼樹
void inOrder(); //中序遍歷哈夫曼樹
void postOrder(); //後序遍歷哈夫曼樹
void creat(T a[], int size); //建立哈夫曼樹
void destory(); //銷毀哈夫曼樹
void print(); //列印哈夫曼樹
Huffman();
~Huffman(){};
private:
void preOrder(HuffmanNode<T>* pnode);
void inOrder(HuffmanNode<T>* pnode);
void postOrder(HuffmanNode<T>*pnode);
void print(HuffmanNode<T>*pnode);
void destroy(HuffmanNode<T>*pnode);
private:
HuffmanNode<T>* root; //哈夫曼樹根節點
deque<HuffmanNode<T>*> forest;//森林
};
1、root:哈夫曼樹的根結點。
2、forset : 森林,這裡使用deque來儲存森林中樹的根節點。
哈夫曼樹的構造步驟
假設有n個權值,則構造出的哈夫曼樹有n個葉子節點.n個權值記為{w1,w2,w3…wn},哈夫曼樹的構造過程為:
1、將w1,w2,w3…wn看成具有n棵樹的森林,每棵樹僅有一個節點。
2、從森林中,選取兩棵根節點權值最小的樹,兩棵樹分別作為左子樹與右子樹,構建一棵新樹。新樹的權值等於左右子樹權值之和。
3、從森林中刪除兩棵權值最小的樹,將構建完成後的新樹加入森林中。
4、重覆2、3步驟,直到森林只剩一棵樹為止。這棵樹便是哈夫曼樹。
圖一的樹b為一棵哈夫曼樹,它的葉子節點為{10,20,30,40},以這4個權值構建樹b的過程為:
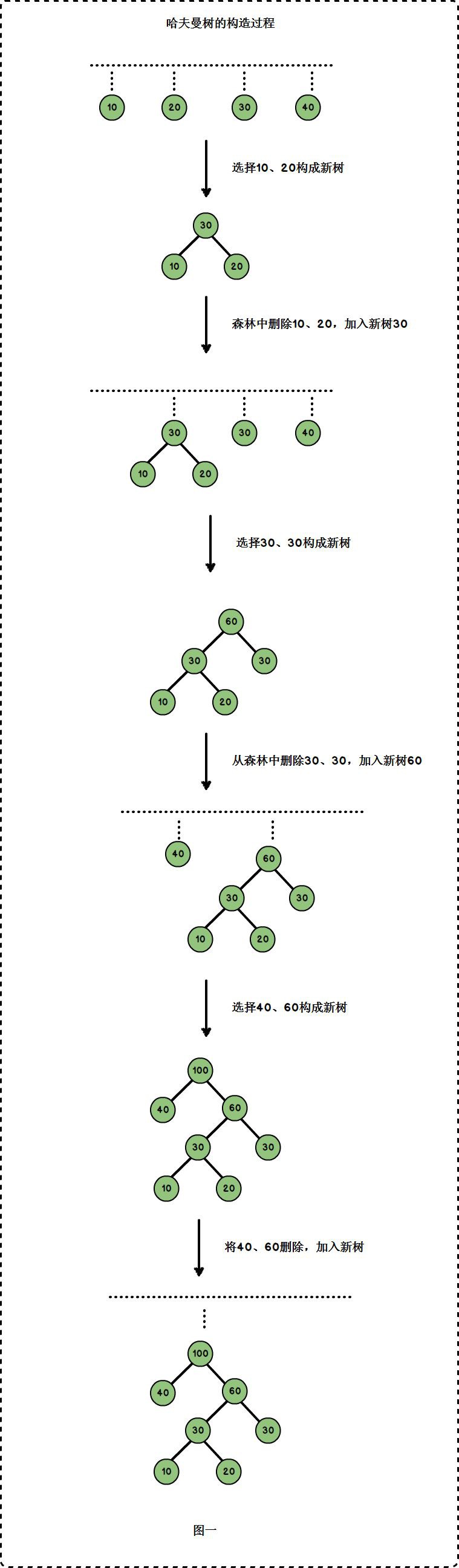
這個過程很編碼實現為:
/*建立哈夫曼樹*/
template<typename T>
void Huffman<T>::creat(T a[],int size)
{
for (int i = 0; i < size; i++) //每個節點都作為一個森林
{
//為初始序列的元素構建節點。每個節點作為一棵樹加入森林中。
HuffmanNode<T>* ptr = new HuffmanNode<T>(a[i],nullptr,nullptr);
forest.push_back(ptr);
}
for (int i = 0; i < size – 1; i++)
{
//排序,以選出根節點權值最小兩棵樹
sort(forest.begin(), forest.end(), [](HuffmanNode<T>* a, HuffmanNode<T>*b){return a->key< b->key; });
HuffmanNode<T>*node = new HuffmanNode<T>(forest[0]->key + forest[1]->key, forest[0], forest[1]); //構建新節點
forest.push_back(node); //新節點加入森林中
forest.pop_front(); //刪除兩棵權值最小的樹
forest.pop_front();
}
root = forest.front();
forest.clear();
};
1、這裡僅僅示範構建哈夫曼樹的過程,沒有經過效能上的最佳化和完善的異常處理。
2、這裡使用deque雙端佇列來儲存森林中樹根節點,使用庫函式sort來對根節點依權值排序。這裡也可以使用我們之前介紹的小頂堆來完成工作。
哈夫曼樹的其他操作
其他操作在前幾篇博文中都有介紹過,這裡就不再囉嗦,可以在文章底部連結取得完整的工程原始碼。
這裡貼出測試時需要的程式碼:
/*列印哈夫曼樹*/
template<typename T>
void Huffman<T>::print(HuffmanNode<T>* pnode)
{
if (pnode != nullptr)
{
cout << “當前結點:” << pnode->key<<“.”;
if (pnode->lchild != nullptr)
cout << “它的左孩子節點為:” << pnode->lchild->key << “.”;
else cout << “它沒有左孩子.”;
if (pnode->rchild != nullptr)
cout << “它的右孩子節點為:” << pnode->rchild->key << “.”;
else cout << “它沒有右孩子.”;
cout << endl;
print(pnode->lchild);
print(pnode->rchild);
}
};
哈夫曼樹程式碼測試
我們構建上圖中的哈夫曼樹,它的四個權值分別為{10,20,30,40}:
測試程式碼:
int _tmain(int argc, _TCHAR* argv[])
{
Huffman<int> huff;
int a[] = { 10,20,30,40 };
huff.creat(a, 4); //構建一棵哈夫曼樹
huff.print(); //列印節點間關係
getchar();
return 0;
}
測試結果:
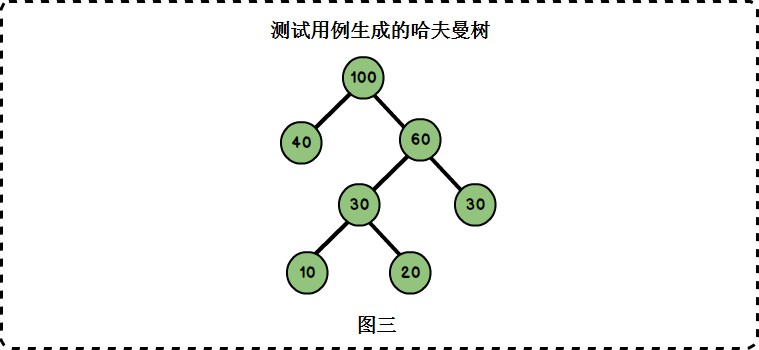
當前結點:100.它的左孩子節點為:40.它的右孩子節點為:60.
當前結點:40.它沒有左孩子.它沒有右孩子.
當前結點:60.它的左孩子節點為:30.它的右孩子節點為:30.
當前結點:30.它沒有左孩子.它沒有右孩子.
當前結點:30.它的左孩子節點為:10.它的右孩子節點為:20.
當前結點:10.它沒有左孩子.它沒有右孩子.
當前結點:20.它沒有左孩子.它沒有右孩子.
根據節點關係可以畫出如下二叉樹,正是上面我們構建的哈夫曼樹。
再看哈夫曼編碼
為{10,20,30,40}這四個權值構建了哈夫曼編碼後,我們可以由如下規則獲得它們的哈夫曼編碼:
1、從根節點到每一個葉子節點的路徑上,左分支記為0,右分支記為1,將這些0與1連起來即為葉子節點的哈夫曼編碼。如下圖:
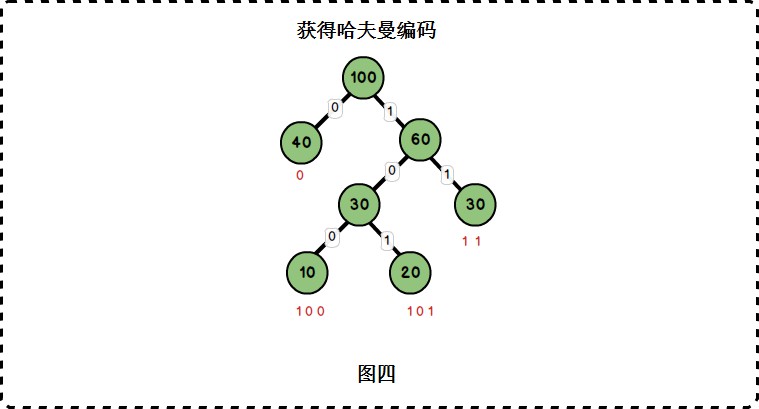
| (字母)權值 | 編碼 |
|---|---|
| 10 | 100 |
| 20 | 101 |
| 30 | 11 |
| 40 | 0 |
由此可見,出現頻率越高的字母(也即權值越大),其編碼越短。這便使編碼之後的字串的平均長度、期望值降低,從而達到無失真壓縮資料的目的。
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功
