(給ImportNew加星標,提高Java技能)
編譯:ImportNew/唐尤華
dzone.com/articles/50-best-performance-practices-for-hibernate-5-amp
1. 透過位元組碼增強實現屬性延遲載入
預設情況下,物體的屬性是立即載入的,即一次載入所有屬性。你確定這是你想要的嗎?
“描述:”即使目前沒有這樣的需求,瞭解可以延遲載入屬性也很重要。透過 Hibernate 位元組碼插裝或者 subentities 也可以實現。該特性對於儲存了大量 `CLOB`、`BLOB`、`VARBINARY` 型別資料時非常有用。
> 譯註:位元組碼增強(Bytecode enhancement)與位元組碼插裝(Bytecode instrumentation)的區別。位元組碼增強分線上、離線兩種樣式。線上樣式指在執行時執行,持久化類在載入時得到增強;離線樣式指在編譯後的步驟中進行增強。位元組碼插裝,指在“執行時”向 Java 類加入位元組碼。實際上不是在執行時,而是在 Java 類的“載入”過程中完成。
技術要點
- 在 Maven `pom.xml` 中啟用 Hibernate 位元組碼插裝(像下麵這樣使用 Maven 位元組碼增強外掛)
- 為需要延遲載入的列標記 `@Basic(fetch = FetchType.LAZY)`
- 在 View 中禁用 Open Session
[示例程式碼][1]
[1]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootAttributeLazyLoadingBasic
2. 透過 Log4J 2 檢視系結引數
開發中,如果不能監測呼叫的SQL陳述句系結的引數,很有可能造成潛在的效能損失(例如 N+1 問題)。
> 譯註:“N+1 問題”即執行一次查詢 N 條主資料後,由於關聯引起的 N 次從資料查詢,因此會帶來了效能問題。一般來說,透過延遲載入可以部分緩解 N+1 帶來的效能問題。
“更新:”如果專案中”已經”配置了 Log4J 2,可以採用以下方案。如果沒有配置,建議使用 `TRACE`(感謝 Peter Wippermann 的建議)或 `log4jdbc`(感謝 Sergei Poznanski 的建議以及 [SO][2] 的答案)。這兩種方案不需要取消預設 Spring Boot 日誌功能。使用 `TRACE` 的例子參見[這裡][3],`log4jdbc` 的示例參見[這裡][4]。
[2]:https://stackoverflow.com/questions/45346905/how-to-log-sql-queries-their-parameters-and-results-with-log4jdbc-in-spring-boo/45346996#45346996
[3]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootLogTraceViewBindingParameters
[4]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootLog4JdbcViewBindingParameters
“基於 Log4J 2 方案:”最好的辦法還是監視SQL陳述句系結的引數,可以透過 Log4J 2 logger 設定。
技術要點
- 在 Maven `pom.xml` 中移除預設 Spring Boot 日誌依賴(參考上面的更新說明)
- 在 Maven `pom.xml` 中加入 Log4j 2 依賴
- 在 `log4j2.xml` 中新增以下配置:
```xml
"org.hibernate.type.descriptor.sql"level=“trace”/>
“`
示例輸出

[示例程式碼][5]
[5]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootLog4j2ViewBindingParameters
3.如何透過 datasource-proxy 監視查詢細節
如果無法保證批處理正常工作,很容易會遇到嚴重的效能損失。即使已經配置了批處理並且認為會在後臺執行,還是有一些情況會造成批處理被禁用。為了確保這一點,可以使用 `hibernate.generate_statistics` 顯示詳細資訊(包括批處理細節),也可以使用 datasource-proxy。
“描述:”透過 [datasource-proxy][6] 檢視查詢細節(包括查詢型別、系結引數、批處理大小等)。
[6]:https://github.com/ttddyy/datasource-proxy
技術要點
- 在 Maven `pom.xml` 中加入 `datasource-proxy` 依賴
- 為 `DataSource` bean 建立 Post Processor 進行攔截
- 用 `ProxyFactory` 和 `MethodInterceptor` 實現包裝 `DataSource` bean
示例輸出

[示例程式碼] [here][7]
[7]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootDataSourceProxy
4. 透過 saveAll(Iterable entities) 在 MySQL(或其他 RDBMS)中執行批次插入
預設情況下,100次插入會生成100個 `INSERT` 陳述句,帶來100個資料庫行程開銷。
“描述:”批處理機制對 `INSERT`、`UPDATE` 和 `DELETE` 進行分組,能夠顯著降低資料庫行程數。批處理插入可以呼叫 `SimpleJpaRepository#saveAll(Iterable entities)` 方法,下麵是在 MySQL 中的應用步驟。
技術要點
- 在 `application.properties` 中設定 `spring.jpa.properties.hibernate.jdbc.batch_size`
- 在 `application.properties`中設定 `spring.jpa.properties.hibernate.generate_statistics`:檢查批處理是否正常工作
- 在 `application.properties` JDBC URL 中設定 `rewriteBatchedStatements=true`:針對 MySQL 最佳化
- 在 `application.properties` JDBC URL 中設定 `cachePrepStmts=true`:啟用快取。啟用 prepStmtCacheSize、prepStmtCacheSqlLimit 等引數前必須設定此引數
- In `application.properties` JDBC URL 中設定 `useServerPrepStmts=true`:切換到服務端生成預處理陳述句,可能會帶來顯著效能提升
- 在物體類中使用 [assigned generator][8]:MySQL `IDENTITY` 會禁用批處理
- 在物體類中為 `Long` 屬性新增 `@Version` 註解:不僅可以避免批處理生成額外的 `SELECT`,還能減少多個請求事務中丟失 update。使用 `merge()` 替代 `persist()` 時會生成額外的 `SELECT`。`saveAll()` 實際呼叫 `save()`,如果物體物件ID非空會被看作已有物件。這時呼叫 `merge()` 觸發 Hibernate 生成 `SELECT` 檢查資料庫中是否存在相同標識
- 註意:傳入 `saveAll()` 的物件數量不要“改寫“持久化背景關係。通常情況下,`EntityManager` 會定期執行 flush 和 clear,但是 `saveAll()` 執行過程中不會。因此,如果 `saveAll()` 傳入了大量資料,所有資料都會命中持久化背景關係(1級快取),並一直保持直到執行 flush 操作。這裡的配置適用於規模較小的資料,對於大資料的情況請參考例5
[8]:https://vladmihalcea.com/how-to-combine-the-hibernate-assigned-generator-with-a-sequence-or-an-identity-column/
示例輸出
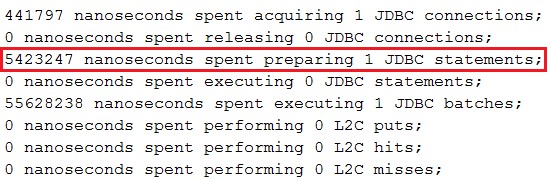
[示例程式碼][9]
[9]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootBatchInsertsJpaRepository
5. 透過 EntityManager 在 MySQL(或其他 RDBMS)中執行批次插入
批處理可以提高效能,但是在執行 flush 前需要關註持久化背景關係中的資料量。在記憶體中儲存大量資料會導致效能下降,例4中的方法只適合資料量相對較少的情況。
“描述:”透過 `EntityManager` 在 MySQL(或其他 RDBMS)中執行批次插入。這種方法可以更好地控制持久化背景關係(1級快取) `flush()` 和 `clear()` 操作。Spring Boot 中 `saveAll(Iterableentities)` 做不到這點。其它好處,可以呼叫 `persist()` 而不是 `merge()` 方法,Spring Boot `saveAll(Iterable< S>entities)` 與 `save(S entity)` 預設呼叫前者。
技術要點
- 在 `application.properties` 中設定 `spring.jpa.properties.hibernate.jdbc.batch_size`
- 在 `application.properties` 中設定 `spring.jpa.properties.hibernate.generate_statistics`:檢查批處理是否正常工作
- 在 `application.properties` JDBC URL 中設定 `rewriteBatchedStatements=true`:針對 MySQL 最佳化
- 在 `application.properties` JDBC URL 中設定 `withcachePrepStmts=true`:啟用快取。啟用 prepStmtCacheSize、prepStmtCacheSqlLimit 等引數前必須設定此引數
- 在 `application.properties` JDBC URL 中設定 `withuseServerPrepStmts=true`:切換到服務端生成預處理陳述句,可能會帶來顯著效能提升
- 在物體類中使用 [assigned generator][8]:MySQL `IDENTITY` 會禁用批處理
- 在 DAO 中定期對持久化背景關係執行 flush 和 clear,避免“改寫“持久化背景關係
示例輸出

[示例程式碼][10]
[10]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootBatchInsertsEntityManager
你可能也會對下麵內容感興趣
- [6. 如何在 MySQL 中透過 JpaContext/EntityManager 執行批次插入][11]”
- [7. 在 MySQL 中實現 Session 級批處理(Hibernate 5.2 或更高版本)][12]”
[11]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootBatchInsertsEntityManagerViaJpaContext
[12]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootBatchInsertsViaSession
8. 透過 Spring Data/EntityManager/Session 直接獲取結果
從資料庫獲取資料的方式決定了應用的執行效率,要最佳化查詢必須瞭解每種獲取資料方法的特點。在瞭解物體類’主鍵’的情況下,*直接獲取*是最簡單且實用的辦法。
“描述:”下麵是使用 Spring Data、`EntityManager` 和 Hibernate `Session` 直接獲取資料的示例:
技術要點
- 透過 Spring Data 直接獲取資料,呼叫 `findById()`
- 透過 `EntityManager#find()` 直接獲取資料
- 透過 Hibernate `Session#get()` 直接獲取資料
[示例程式碼][13]
[13]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootDirectFetching
9. 透過 Spring Data Projection 實現 DTO
獲取超出需要的資料是導致效能下降的常見問題之一。不僅如此,得到物體後不做修改也是一樣。
“描述:”透過 Spring Data Projection(DTO)從資料庫只獲取必須的資料。也可以檢視例子25至32。
技術要點
- 編寫介面(projection),包含資料庫所需資料表指定列的 getter 方法
- 編寫傳回 `List` 的查詢
- 可能的話,要限制傳回的行數(例如,透過 `LIMIT`)。這個例子中,使用了 Spring Data repository 的內建 query builder 機制
示例輸出(選擇前2列,只獲取 “name” 和 “age”)

[示例程式碼][14]
[14]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootDtoViaProjections
10. 如何在 MySQL 中儲存 UTC 時區
在資料庫中儲存不同格式或指定格式的日期、時間和時間戳會帶來日期轉換問題。
“描述:” 這個例子展示瞭如何在 MySQL 中以 UTC 時區儲存日期、時間和時間戳。對其他 RDBMS(例如 PostgreSQL),只要移除 `useLegacyDatetimeCode=false` 對應調整 JDBC URL 即可。
技術要點
- `spring.jpa.properties.hibernate.jdbc.time_zone=UTC`
- `spring.datasource.url=jdbc:mysql://localhost:3306/db_screenshot?useLegacyDatetimeCode=false`
[示例程式碼] [here][15]
> 譯註:執行時修改示例 url 為 jdbc:mysql://localhost:3306/db_screenshot?createDatabaseIfNotExist=true&useLegacyDatetimeCode;=false,設定引數 spring.jpa.hibernate.ddl-auto=create
[15]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootUTCTimezone
11. 透過 Proxy 得到父物體
執行的 SQL 越多,效能損失越大。盡可能減少執行的 SQL 數量非常重要,透過 Reference 是最易於使用的最佳化方法。
“描述:”`Proxy` 在子物體可以透過指向父物體的一個持久化取用表示時非常有用。這種情況下,執行`SELECT` 陳述句從資料庫獲得父物體會帶來效能損失且沒有意義。Hibernate 能夠對未初始化的 `Proxy` 設定基礎外來鍵值。
技術要點
- 底層依賴 `EntityManager#getReference()`
- 在 Spring 中呼叫 `JpaRepository#getOne()`
- 在這個示例中,使用了 Hibernate `load()` 方法
- 示例中有 `Tournament` 和 `TennisPlayer` 兩個實體,一個 tournament 包含多個 player(`@OneToMany`)
- 透過 `Proxy` 獲取 tournament 物件(不會觸發 `SELECT`),接著建立一個 TennisPlayer 物件,把 `Proxy` 設為 player 的 tournament,最後儲存 player(觸發 `INSERT` 操作,在 tennis player 中插入 `tennis_player`)
示例輸出
命令列只輸出一條 `INSERT`,沒有 `SELECT` 陳述句。
[示例程式碼][16]
[16]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootPopulatingChildViaProxy
12. N+1 問題
“N+1問題”可能造成嚴重的效能損失。減少損失的首要任務是定位問題。
N+1 本質上是一個延遲載入問題(預先載入也不例外)。缺乏對實際執行SQL進行監測,很可能會造成 N+1 問題,最好的解決辦法是 JOIN+DTO(例36至例42)。
技術要點
- 定義 `Category` 和 `Product` 兩類物體,關係為 `@OneToMany`
- 延遲載入 `Product`,不主動載入 `Category`(只生成1條查詢)
- 迴圈讀取 `Product` 集合, 對每個產品獲取 `Category`(生成N條查詢)
示例輸出
[示例程式碼][17]
[17]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootSimulateNPlus1
13. 透過 HINT_PASS_DISTINCT_THROUGH 最佳化 Distinct SELECT
把 `SELECT DISTINCT` 傳遞給 RDBMS 會[影響效能][18]。
[18]:http://in.relation.to/2016/08/04/introducing-distinct-pass-through-query-hint/
“描述:” Hibernate 5.2.2 開始,可以透過 `HINT_PASS_DISTINCT_THROUGH` 最佳化 `SELECT DISTINCT`。不會把 `DISTINCT` 關鍵字傳給 RDBMS,而是由 Hibernate 刪除重覆資料。
技術要點
- 使用 `@QueryHints(value = @QueryHint(name = HINT_PASS_DISTINCT_THROUGH, value = “false”))`
示例輸出

[示例程式碼][19]
[19]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootHintPassDistinctThrough
14. 啟用臟資料跟蹤
Java 反射執行速度慢,通常被看作效能損失。
“描述:”Hibernate 5 之前,臟資料檢查機制基於 Java Reflection API。自 Hibernate 5 開始,轉而採用了**位元組碼增強**技術。後者的效能更好,物體數量較多時效果尤其明顯。
技術要點
- 在 `pom.xml` 中增加外掛配置(例如,使用 Maven bytecode enhancement 外掛)
示例輸出
- 位元組碼增強效果可以在 `User.class` 上[看到][20]
[示例程式碼][21]
[20]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/blob/master/HibernateSpringBootEnableDirtyTracking/Bytecode%20Enhancement%20User.class/User.java
[21]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootEnableDirtyTracking
15. 在物體和查詢上使用 Java 8 Optional
把 Java 8 `Optional` 作為處理 `null` 的“銀彈”可能弊大於利,最好的方式還是按照設計的意圖使用。
“描述:”下麵的示例展示瞭如何在物體和查詢中正確使用 Java 8 `Optional`。
技術要點
- 使用 Spring Data 內建查詢方法傳回 `Optional`(例如 `findById()`)
- 自己編寫查詢方法傳回 `Optional`
- 在物體 getter 方法中使用 `Optional`
- 可以使用 `data-mysql.sql` 指令碼驗證不同場景
[示例程式碼][22]
[22]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootEnableDirtyTracking
16. 如何正確建立 @OneToMany 雙向關係
實現 `@OneToMany` 雙向關係有幾個陷阱,相信你也希望一開始就能實現正確。
“描述:”下麵的示例應用展示瞭如何正確實現 `@OneToMany` 雙向關聯。
技術要點
- “總是”建立父子級聯
- 對父親標記 `mappedBy`
- 對父親使用 `orphanRemoval`,移除沒有取用的子物件
- 在父節點上使用 helper 方法實現關聯同步
- “總是”使用延遲載入
- 使用業務主鍵或物體識別符號,參考[這篇介紹][23]覆寫 `equals()` 和 `hashCode()` 方法。
[示例程式碼][24]
[23]:https://vladmihalcea.com/the-best-way-to-implement-equals-hashcode-and-tostring-with-jpa-and-hibernate/
[24]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootOneToManyBidirectional
17. JPQL/HQL 查詢資料
在不具備直接查詢的情況下,可以考慮透過 JPQL/HQL 查詢資料。
“描述:”下麵的示例展示瞭如何透過 `JpaRepository`、`EntityManager` 和 `Session` 進行查詢。
技術要點
- 對 `JpaRepository` 使用 `@Query` 註解或者建立 Spring Data Query
- 對 `EntityManager` 與 `Session` 使用 `createQuery()` 方法
[示例程式碼][25]
[25]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootQueryFetching
18. 避免在 MySQL 與 Hibernate 5 中使用 AUTO Generator 型別
在 MySQL 開發過程中,儘量避免使用 `TABLE` 生成器,最好[永遠不要使用][26]。
[26]:https://vladmihalcea.com/why-you-should-never-use-the-table-identifier-generator-with-jpa-and-hibernate/
“描述:” 在使用 MySQL 和 Hibernate 5 開發時,`GenerationType.AUTO` 型別的生成器會呼叫 `TABLE` 生成器,造成嚴重的效能損失。可以透過 `GenerationType.IDENTITY` 呼叫 `IDENTITY` 生成器或者使用 *native* 生成器。
技術要點
- 使用 `GenerationType.IDENTITY` 取代 `GenerationType.AUTO`
- 使用[示例程式碼][27],呼叫 *native* 生成器
[27]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootAutoGeneratorType
示例輸出

[示例程式碼][28]
[28]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootAutoGeneratorType
19. 多餘的 save() 呼叫
大家都喜歡使用 `save()`。由於 Hibernate 採用了臟資料檢查機制避免多餘呼叫,`save()` 對於託管物體並不適用。
“描述:” 下麵的示例展示了對於託管物體呼叫 `save()` 方法是多餘的。
技術要點
- Hibernate 會為每個託管物體呼叫 `UPDATE` 陳述句,不需要顯示呼叫 `save()` 方法
- 多餘的呼叫意味著效能損失(參見[這篇文章][29])
[示例程式碼][30]
[29]https://vladmihalcea.com/jpa-persist-and-merge/
[30]https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootRedundantSave
20. PostgreSQL (BIG)SERIAL 與批次插入
在 PostgreSQL 中,使用 `GenerationType.IDENTITY` 會禁用批次插入。
“描述:” `(BIG)SERIAL` 與 MySQL 的 `AUTO_INCREMENT` 功能“接近”。在這個示例中,我們透過 `GenerationType.SEQUENCE` 開啟批次插入,同時透過 `hi/lo` 演演算法進行了最佳化。
技術要點
- 使用 `GenerationType.SEQUENCE` 取代 `GenerationType.IDENTITY`
- 透過 `hi/lo` 演演算法在一個資料庫行程中完成多個識別符號讀取(還可以使用 Hibernate `pooled` 和 `pooled-lo` 識別符號生成器,它們是 `hi/lo` 的改進版)
示例輸出

[示例程式碼][31]
[31]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootBatchingAndSerial
> 譯註:示例中 `createDatabaseIfNotExist=true` 引數對 PostgreSQL 無效,需要手動建立 `db_users` 資料庫。
21. JPA 繼承之 Single Table
JPA 支援 `SINGLE_TABLE`、`JOINED` 和 `TABLE_PER_CLASS` 繼承策略,有著各自優缺點。以 `SINGLE_TABLE` 為例,讀寫速度快但不支援對子類中的列設定 `NOT NULL`。
“描述:”下麵的示例展示了 JPA Single Table 繼承策略(`SINGLE_TABLE`)。
技術要點
- 這是 JPA 預設的繼承策略(`@Inheritance(strategy=InheritanceType.SINGLE_TABLE)`)
- 所有繼承結構中的類都會被對映到資料庫中的單個表
示例輸出(下麵是四個物體得到的單個表)

[示例程式碼][32]
[32]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootSingleTableInheritance
22. 如何對 SQL 陳述句統計和斷言
如果不對 SQL 陳述句進行統計和斷言,很容易對後臺執行的 SQL 陳述句失去控制,進而造成效能損失。
“描述:”下麵的示例展示瞭如何對後臺 SQL 陳述句進行統計和斷言。統計 SQL 非常有用,能夠確保不會生成多餘的 SQL(例如,可以對預期的陳述句數量斷言檢測 N+1 問題)。
技術要點
- 在 Maven `pom.xml` 中新增 `datasource-proxy` 依賴和 Vlad Mihalcea 的 `db-util`
- 新建 `ProxyDataSourceBuilderwithcountQuery()`
- `SQLStatementCountValidator.reset()` 重置計數
- 透過 `assertInsert{Update/Delete/Select}Count(long expectedNumberOfSql` 對 `INSERT`、`UPDATE`、`DELETE` 和 `SELECT` 進行斷言
示例輸出(期望的 SQL 陳述句數量與實際生成的數量不一致時丟擲異常)
[示例程式碼][33]
[33]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootCountSQLStatements
23. 如何使用 JPA 回呼
為物體系結事件處理時,記得使用 JPA 內建回呼,不要重新發明輪子。
“描述:”下麵的示例展示瞭如何啟用 JPA 回呼(`Pre/PostPersist`、`Pre/PostUpdate`、`Pre/PostRemove` 和 `PostLoad`)。
技術要點
- 在物體中編寫回呼方法並挑選合適的註解
- Bean Class 中帶註解的回呼方法傳回型別必須為 `void` 且不帶引數
示例輸出
[示例程式碼][34]
[34]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootJpaCallbacks
24. @OneToOne 與 @MapsId
雙向 `@OneToOne` 效率不及單向 `@OneToOne`,後者與父表共享主鍵。
“描述:” 下麵的示例展示了為何建議使用 `@OneToOne` 和 `@MapsId` 取代 `@OneToOne`。
技術要點
- 在子物體上使用 `@MapsId`
- 對於 `@OneToOne` 關聯,基本上會與父表共享主鍵。
[示例程式碼][35]
[35]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootOneToOneMapsId
25. 透過 SqlResultSetMapping 設定 DTO
超出需要獲取資料是不好的習慣。另一種常見的錯誤,沒有打算修改物體物件卻獲取並儲存到持久化背景關係中,同樣會導致效能問題。例25至例32展示瞭如何使用不同方法提取 DTO。
“描述:“下麵的示例展示瞭如何透過 `SqlResultSetMapping` 和 `EntityManager` 使用 DTO 提取需要的資料。
技術要點
- 使用 `SqlResultSetMapping` 和 `EntityManager`
- 使用 Spring Data Projection 時,請檢查例9中的註意事項
[示例程式碼][36]
[36]:https://github.com/AnghelLeonard/Hibernate-SpringBoot/tree/master/HibernateSpringBootDtoSqlResultSetMapping
朋友會在“發現-看一看”看到你“在看”的內容