作者:天空的湛藍 連結:https://www.cnblogs.com/zhan520g/p/11018163.html
LINQ(Language Integrated Query,語言整合查詢)提供了類似於SQL的語法,能對集合進行遍歷、篩選和投影。一旦掌握了LINQ,你就會發現在開發中再也離不開它。
前言
C#中的集合表現為陣列和若干集合類。不管是陣列還是集合類,它們都有各自的優缺點。如何使用好集合是我們在開發過程中必須掌握的技巧。
不要小看這些技巧,一旦在開發中使用了錯誤的集合或針對集合的方法,應用程式將會背離你的預想而執行。
1、元素數量可變的情況下不應使用陣列
在C#中,陣列一旦被建立,長度就不能改變。如果我們需要一個動態且可變長度的集合,就應該使用ArrayList或List<T>來建立。而陣列本身,尤其是一維陣列,在遇到要求高效率的演演算法時,則會專門被最佳化以提升其效率。
一維陣列也稱為向量,其效能是最佳的,在IL中使用了專門的指令來處理它們(如newarr、ldelem、ldelema、ldlen和stelem)。
從記憶體使用的角度來講,陣列在建立時被分配了一段固定長度的記憶體。如果陣列的元素是值型別,則每個元素的長度等於相應的值型別的長度;如果陣列的元素是取用型別,則每個元素的長度為該取用型別的IntPtr.Size。
陣列的儲存結構一旦被分配,就不能再變化。而ArrayList是陣列結構,可以動態地增減記憶體空間,如果ArrayList儲存的是值型別,則會為每個元素增加12位元組的空間,其中4位元組用於物件取用,8位元組是元素裝箱時引入的物件頭。
List<T>是ArrayList的泛型實現,它省去了拆箱和裝箱帶來的開銷。
註意
由於陣列本身在記憶體上的特點,因此在使用陣列的過程中還應該註意大物件的問題。所謂“大物件”,是指那些佔用記憶體超過85 000位元組的物件,它們被分配在大物件堆裡。大物件的分配和回收與小物件相比,都不太一樣,尤其是回收,大物件在回收過程中會帶來效率很低的問題。所以,不能肆意對陣列指定過大的長度,這會讓陣列成為一個大物件。
-
如果一定要動態改變陣列的長度,一種方法是將陣列轉換為ArrayList或List<T>,需要擴容時,內部陣列將自動翻倍擴容
-
還有一種方法是用陣列的複製功能。陣列繼承自System.Array,抽象類System.Array提供了一些有用的實現方法,其中就包含了方法,它負責將一個陣列的內容複製到另外一個陣列中。無論是哪種方法,改變陣列長度就相當於重新建立了一個陣列物件。
2、多數情況下使用foreach進行迴圈遍歷
採用foreach最大限度地簡化了程式碼。
它用於遍歷一個繼承了IEmuerable或IEmuerable<T>介面的集合元素。藉助於IL程式碼可以看到foreach還是本質就是利用了迭代器來進行集合遍歷。如下:
List
除了程式碼簡潔之外,foreach還有兩個優勢
-
自動將程式碼置入try-finally塊
-
若型別實現了IDispose介面,它會在迴圈結束後自動呼叫Dispose方法。
3、foreach不能代替for
foreach存在的一個問題是:它不支援迴圈時對集合進行增刪操作。取而代之的方法是使用for迴圈。
不支援原因:
-
foreach迴圈使用了迭代器進行集合的遍歷,它在FCL提供的迭代器內部維護了一個對集合版本的控制。那麼什麼是集合版本?簡單來說,其實它就是一個整型的變數,任何對集合的增刪操作都會使版本號加1。foreach迴圈會呼叫MoveNext方法來遍歷元素,在MoveNext方法內部會進行版本號的檢測,一旦檢測到版本號有變動,就會丟擲InvalidOperationException異常。
-
如果使用for迴圈就不會帶來這樣的問題。for直接使用索引器,它不對集合版本號進行判斷,所以不存在因為集合的變動而帶來的異常(當然,超出索引長度這種情況除外)。
public bool MoveNext()
{
Listlist=this.list;
if((this.version==list._version)&&(this.index<list._size))
{
this.current=list._items[this.index];
this.index++;
return true;
}
return this.MoveNextRare();
}
無論是for迴圈還是foreach迴圈,內部都是對該陣列的訪問,而迭代器僅僅是多進行了一次版本檢測。事實上,在迴圈內部,兩者生成的IL程式碼也是差不多的。
4、使用更有效的物件和集合初始化
舉例:
class Program {
static void Main(string[]args)
{
Person person=new Person(){Name="Mike",Age=20};
}
}
class Person
{
public string Name{get;set;}
public int Age{get;set;}
}
物件初始化設定項支援在大括號中對自動實現的屬性進行賦值。以往只能依靠構造方法傳值進去,或者在物件構造完畢後對屬性進行賦值。現在這些步驟簡化了,初始化設定項實際相當於編譯器在物件生成後對屬性進行了賦值。
集合初始化也同樣進行了簡化:
ListpersonList=new List( )
{
new Person() {Name="Rose",Age=19},
mike,
null
};
重點:初始化設定項絕不僅僅是為了物件和集合初始化的方便,它更重要的作用是為LINQ查詢中的匿名型別進行屬性的初始化。由於LINQ查詢傳回的集合中匿名型別的屬性都是隻讀的,如果需要為匿名型別屬性賦值,或者增加屬性,只能透過初始化設定項來進行。初始化設定項還能為屬性使用運算式。
舉例
ListpersonList2=new List()
{
new Person(){Name="Rose",Age=19},
new Person(){Name="Steve",Age=45},
new Person(){Name="Jessica",Age=20}
};
var pTemp=from p in personList2
select new {p.Name, AgeScope=p.Age>20?"Old":"Young"};
foreach(var item in pTemp)
{
Console.WriteLine(string.Format("{0}:
{1}",item.Name,item.AgeScope));
}
5、使用泛型集合代替非泛型集合
註意,非泛型集合在System.Collections名稱空間下,對應的泛型集合則在System.Collections.Generic名稱空間下。
泛型的好處不言而喻,,如果對大型集合進行迴圈訪問、轉型或拆箱和裝箱操作,使用ArrayList這樣的傳統集合對效率的影響會非常大。鑒於此,微軟提供了對泛型的支援。泛型使用一對<>括號將實際的型別括起來,然後編譯器和執行時會完成剩餘的工作。
6、選擇正確的集合
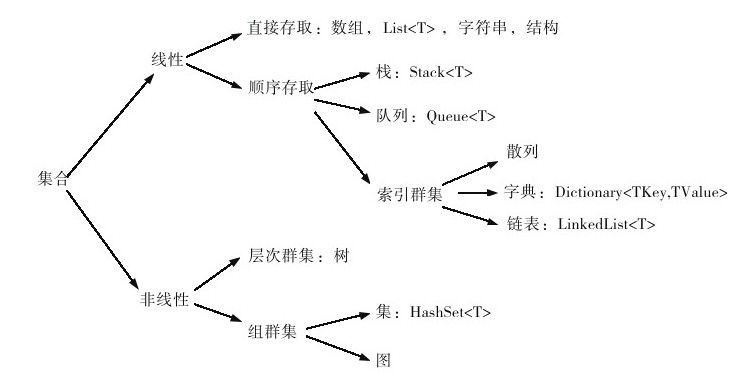
要選擇正確的集合,首先需要瞭解一些資料結構的知識。所謂資料結構,就是相互之間存在一種或多種特定關係的資料元素的集合
說明
-
直接儲存結構的優點是:向資料結構中新增元素是很高效的,直接放在資料末尾的第一個空位上就可以了。它的缺點是:向集合插入元素將會變得低效,它需要給插入的元素騰出位置並順序移動後面的元素。
如果集合的數目固定並且不涉及轉型,使用陣列效率高,否則就使用List<T>(該使用陣列的時候,還是要使用陣列)
-
順序儲存結構,即線性表。線性表可動態地擴大和縮小,它在一片連續的區域中儲存資料元素。線性表不能按照索引進行查詢,它是透過對地址的取用來搜尋元素的,為了找到某個元素,它必須遍歷所有元素,直到找到對應的元素為止。所以,線性表的優點是插入和刪除資料效率高,缺點是查詢的效率相對來說低一些。
-
佇列Queue<T>遵循的是先入先出的樣式,它在集合末尾新增元素,在集合的起始位置刪除元素。
-
棧Stack<T>遵循的是後入先出的樣式,它在集合末尾新增元素,同時也在集合末尾刪除元素。
-
字典Dictionary<TKey, TValue>儲存的是鍵值對,值在基於鍵的雜湊碼的基礎上進行儲存。字典類物件由包含集合元素的儲存桶組成,每一個儲存桶與基於該元素的鍵的雜湊值關聯。如果需要根據鍵進行值的查詢,使用Dictionary<TKey, TValue>將會使搜尋和檢索更快捷。
-
雙向連結串列LinkedList<T>是一個型別為LinkedListNode的元素物件的集合。當我們覺得在集合中插入和刪除資料很慢時,就可以考慮使用連結串列。如果使用LinkedList<T>,我們會發現此型別並沒有其他集合普遍具有的Add方法,取而代之的是AddAfter、AddBefore、AddFirst、AddLast等方法。雙向連結串列中的每個節點都向前指向Previous節點,向後指向Next節點。
-
在FCL中,非線性集合實現得不多。非線性集合分為層次集合和組集合。層次集合(如樹)在FCL中沒有實現。組集合又分為集和圖,集在FCL中實現為HashSet<T>,而圖在FCL中也沒有對應的實現。
集的概念本意是指存放在集合中的元素是無序的且不能重覆的。
-
除了上面提到的集合型別外,還有其他幾個要掌握的集合型別,它們是在實際應用中發展而來的對以上基礎型別的擴充套件:SortedList<T>、SortedDictionary<TKey, TValue>、Sorted-Set<T>。它們所擴充套件的對應類分別為List<T>、Dictionary<TKey, TValue>、HashSet<T>,作用是將原本無序排列的元素變為有序排列。
-
除了排序上的需求增加了上面3個集合類外,在名稱空間System.Collections.Concurrent下,還涉及幾個多執行緒集合類。它們主要是:
-
ConcurrentBag<T>對應List<T>
-
ConcurrentDictionary<TKey, TValue>對應Dictionary<TKey, TValue>
-
ConcurrentQueue<T>對應Queue<T>
-
ConcurrentStack<T>對應Stack<T>
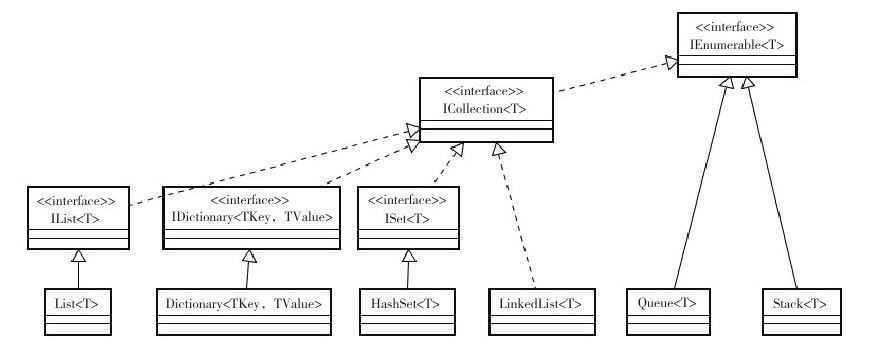
FCL集合圖如下:
7、確保集合的執行緒安全
集合執行緒安全是指在多個執行緒上新增或刪除元素時,執行緒之間必須保持同步。
泛型集合一般透過加鎖來進行安全鎖定,如下:
static object sycObj=new object();
static void Main(string[]args)
{
//object sycObj=new object();
Thread t1=new Thread(()=>{
//確保等待t2開始之後才執行下麵的程式碼
autoSet.WaitOne();
lock(sycObj)
{
foreach(Person item in list)
{
Console.WriteLine("t1:"+item.Name);
Thread.Sleep(1000);
}
}
}
8、避免將List<T>作為自定義集合類的基類
如果要實現一個自定義的集合類,不應該以一個FCL集合類為基類,而應該擴充套件相應的泛型介面。FCL集合類應該以組合的形式包含至自定義的集合類,需擴充套件的泛型介面通常是IEnumer-able<T>和ICollection<T>(或ICollection<T>的子介面,如IList<T>),前者規範了集合類的迭代功能,後者則規範了一個集合通常會有的操作。
List<T>基本上沒有提供可供子類使用的protected成員(從object中繼承來的Finalize方法和Member-wiseClone方法除外),也就是說,實際上,繼承List<T>並沒有帶來任何繼承上的優勢,反而喪失了面向介面程式設計帶來的靈活性。而且,稍加不註意,隱含的Bug就會接踵而至。
9、迭代器應該是隻讀的
FCL中的迭代器只有GetEnumerator方法,沒有SetEnumerator方法。所有的集合類也沒有一個可寫的迭代器屬性。
原因有二
-
這違背了設計樣式中的開閉原則。被設定到集合中的迭代器可能會直接導致集合的行為發生異常或變動。一旦確實需要新的迭代需求,完全可以建立一個新的迭代器來滿足需求,而不是為集合設定該迭代器,因為這樣做會直接導致使用到該集合物件的其他迭代場景發生不可知的行為。
-
現在,我們有了LINQ。使用LINQ可以不用建立任何新的型別就能滿足任何的迭代需求。
10、謹慎集合屬性的可寫操作
如果型別的屬性中有集合屬性,那麼應該保證屬性物件是由型別本身產生的。如果將屬性設定為可寫,則會增加丟擲異常的機率。一般情況下,如果集合屬性沒有值,則它傳回的Count等於0,而不是集合屬性的值為null。
11、使用匿名型別儲存LINQ查詢結果(最佳搭檔)
從.NET 3.0開始,C開始支援一個新特性:匿名型別。匿名型別由var、賦值運運算元和一個非空初始值(或以new開頭的初始化項)組成。匿名型別有如下的基本特性:
-
既支援簡單型別也支援複雜型別。簡單型別必須是一個非空初始值,複雜型別則是一個以new開頭的初始化項;
-
匿名型別的屬性是隻讀的,沒有屬性設定器,它一旦被初始化就不可更改;
-
如果兩個匿名型別的屬性值相同,那麼就認為兩個匿名型別相等;
-
匿名型別可以在迴圈中用作初始化器;
-
匿名型別支援智慧感知;
-
還有一點,雖然不常用,但是匿名型別確實也可以擁有方法。
12、在查詢中使用Lambda運算式
LINQ實際上是基於擴充套件方法和Lambda運算式的,理解了這一點就不難理解LINQ。任何LINQ查詢都能透過呼叫擴充套件方法的方式來替代,如下麵的程式碼所示:
foreach(var item in personList.Select(person=>new{PersonName= person.Name,CompanyName=person.CompanyID==0?"Micro":"Sun"}))
{
Console.WriteLine(string.Format("{0} :{1}",item.PersonName, item.CompanyName));
}
針對LINQ設計的擴充套件方法大多應用了泛型委託。System名稱空間定義了泛型委託Action、Func和Predicate。
可以這樣理解這三個委託:Action用於執行一個操作,所以它沒有傳回值;Func用於執行一個操作並傳回一個值;Predicate用於定義一組條件並判斷引數是否符合條件。
Select擴充套件方法接收的就是一個Func委託,而Lambda運算式其實就是一個簡潔的委託,運運算元“=>”左邊代表的是方法的引數,右邊的是方法體。
13、理解延遲求值和主動求值之間的區別
樣例如下:
List<int>list=new List<int>(){0,1,2,3,4,5,6,7,8,9};
var temp1=from c in list where c>5 select c;
var temp2=(from c in list where c>5 select c).ToList<int>();
在使用LINQ to SQL時,延遲求值能夠帶來顯著的效能提升。舉個例子:如果定義了兩個查詢,而且採用延遲求值,CLR則會合併兩次查詢並生成一個最終的查詢。
14、區別LINQ查詢中的IEnumerable<T>和IQueryable<T>
LINQ查詢方法一共提供了兩類擴充套件方法,在System.Linq名稱空間下,有兩個靜態類:Enumerable類,它針對繼承了IEnumerable<T>介面的集合類進行擴充套件;Queryable類,它針對繼承了IQueryable<T>介面的集合類進行擴充套件。
稍加觀察我們會發現,介面IQueryable<T>實際也是繼承了IEnumerable<T>介面的,所以,致使這兩個介面的方法在很大程度上是一致的。那麼,微軟為什麼要設計出兩套擴充套件方法呢?
我們知道,LINQ查詢從功能上來講實際上可分為三類:LINQ to OBJECTS、LINQ to SQL、LINQ to XML(本建議不討論)。設計兩套介面的原因正是為了區別對待LINQ to OBJECTS、LINQ to SQL,兩者對於查詢的處理在內部使用的是完全不同的機制。針對LINQ to OBJECTS時,使用Enumerable中的擴充套件方法對本地集合進行排序和查詢等操作,查詢引數接受的是Func<>。Func<>叫做謂語運算式,相當於一個委託。針對LINQ toSQL時,則使用Queryable中的擴充套件方法,它接受的引數是Ex-pression<>。Expression<>用於包裝Func<>。LINQ to SQL引擎最終會將運算式樹轉化成為相應的SQL陳述句,然後在資料庫中執行。
那麼,到底什麼時候使用IQueryable<T>,什麼時候使用IEnumerable<T>呢?簡單表述就是:本地資料源用IEnumer-able<T>,遠端資料源用IQueryable<T>。
註意
在使用IQueryable<T>和IEnumerable<T>的時候還需要註意一點,IEnumerable<T>查詢的邏輯可以直接用我們自己所定義的方法,而IQueryable<T>則不能使用自定義的方法,它必須先生成運算式樹,查詢由LINQ to SQL引擎處理。在使用IQueryable<T>查詢的時候,如果使用自定義的方法,則會丟擲異常。
15、使用LINQ取代集合中的比較器和迭代器
LINQ提供了類似於SQL的語法來實現遍歷、篩選與投影集合的功能。藉助於LINQ的強大功能,我們透過兩條陳述句就能實現上述的排序要求。
var orderByBonus=from s in companySalary orderby s.Bonus select s;
foreach實際會隱含呼叫的是集合物件的迭代器。以往,如果我們要繞開集合的Sort方法對集合元素按照一定的順序進行迭代,則需要讓型別繼承IEnumerable介面(泛型集合是IEnumerable<T>介面),實現一個或多個迭代器。現在從LINQ查詢生成匿名型別來看,相當於可以無限為集合增加迭代需求。
有了LINQ之後,我們是否就不再需要比較器和迭代器了呢?答案是否定的。我們可以利用LINQ的強大功能簡化自己的編碼,但是LINQ功能的實現本身就是藉助於FCL泛型集合的比較器、迭代器、索引器的。LINQ相當於封裝了這些功能,讓我們使用起來更加方便。在名稱空間Sys-tem.Linq下存在很多靜態類,這些靜態類存在的意義就是為FCL的泛型集合提供擴充套件方法
-
強烈建議你利用LINQ所帶來的便捷性,但我們仍需掌握比較器、迭代器、索引器的原理,以便更好地理解LINQ的思想,寫出更高質量的程式碼。最好是能看懂Linq原始碼。
public static IOrderedEnumerableOrderBy(this IEnumerablesource,FunckeySelector){ //省略}
16、在LINQ查詢中避免不必要的迭代
-
比如常使用First()方法,First方法實際完成的工作是:搜尋到滿足條件的第一個元素,就從集合中傳回。如果沒有符合條件的元素,它也會遍歷整個集合。
-
與First方法類似的還有Take方法,Take方法接收一個整型引數,然後為我們傳回該引數指定的元素個數。與First一樣,它在滿足條件以後,會從當前的迭代過程直接傳回,而不是等到整個迭代過程完畢再傳回。如果一個集合包含了很多的元素,那麼這種查詢會為我們帶來可觀的時間效率。
會運用First和Take等方法,都會讓我們避免全集掃描,大大提高效率。
總結
如有需要, 上一篇的《C#規範整理·語言要素》也可以看看!
朋友會在“發現-看一看”看到你“在看”的內容