大部分web應用都需要解析URL,無論是提取域名、實現REST API,還是查詢圖片路徑。一個典型的URL路徑如下圖所示:
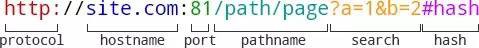
你可以使用正則運算式把URL字串拆分為連續的部分,但是這有點複雜而且沒必要…
服務端URL解析
Node.js(及其分支,比如io.js)提供了URL API:
// Server-side JavaScript
var urlapi = require(‘url’),
url = urlapi.parse(‘http://site.com:81/path/page?a=1&b=2#hash’);
console.log(
url.href + ‘n’ +
// the full URL
url.protocol + ‘n’ +
// http:
url.hostname + ‘n’ +
// site.com
url.port + ‘n’ +
// 81
url.pathname + ‘n’ +
// /path/page
url.search + ‘n’ +
// ?a=1&b=2
url.hash
// #hash
);
你可以從上面的片段中看出,parse()方法傳回一個包含所需資料(比如協議、主機名、埠等)的物件。
客戶端URL解析
瀏覽器端沒有對應的API。但是如果瀏覽器有件事做得好的話,那就是URL解析和DOM中的連結實現了類似的Location介面,例如:
// Client-side JavaScript
// find the first link in the DOM
var url = document.getElementsByTagName(‘a’)[0];
console.log(
url.href + ‘n’ +
// the full URL
url.protocol + ‘n’ +
// http:
url.hostname + ‘n’ +
// site.com
url.port + ‘n’ +
// 81
url.pathname + ‘n’ +
// /path/page
url.search + ‘n’ +
// ?a=1&b=2
url.hash
// #hash
);
如果我們把URL字串放到記憶體的錨點元素(a)中,就可以不依賴正則運算式來解析,例如:
// Client-side JavaScript
// create dummy link
var url = document.createElement(‘a’);
url.href = ‘http://site.com:81/path/page?a=1&b=2#hash’;
console.log(url.hostname);
// site.com
同構URL解析
Aurelio最近討論了同構JavaScript應用。實質上,它是將漸進增強(progressive enhancement)推到了極致:應用可以在客戶端或伺服器上快樂地運行了。使用現代瀏覽器的使用者可以使用單頁應用。老式瀏覽器和搜尋引擎爬蟲將會看到服務端渲染的應用。理論上,應用可以根據裝置的速度和頻寬能力來實現不同等級的客戶端/伺服器處理。
同構JavaScript(Isomorphic JavaScript)已經被討論過很多年,但是太複雜。很少專案能夠在實現共享檢視基礎之上更進一步,而且標準漸進增強不起作用的情況也不多(如果沒有更好地考慮到,大部分沒有客戶端JavaScript的“同構”框架都會失效)。意思是,可以實現環境無關的宏觀庫來試探性地邁出同構概念的第一步。
我們考慮下怎樣在lib.js檔案中編寫一個URL解析庫。首先,我們檢測程式碼執行的位置:
// running on Node.js?
var isNode = ( typeof module === ‘object’ && module.exports);
這個方法不是特別健壯,因為你可能在客戶端定義了module.exports函式,但是我不知道其他更好的方式(歡迎提供建議)。其他開發者的類似方法是檢測window物件是否存在:
// running on Node.js?
var isNode = typeof window === ‘undefined’;
現在我們使用URLparse函式完成lib.js程式碼:
// lib.js library functions
// running on Node.js?
var isNode = ( typeof module === ‘object’ && module.exports);
( function (lib) {
“use strict” ;
// require Node URL API
var url = (isNode ? require(‘url’) : null);
// parse URL
lib.URLparse = function(str) {
if (isNode) {
return url.parse(str);
}
else {
url = document.createElement(‘a’);
url.href = str;
return url;
}
}
})(isNode ? module.exports : this.lib = {});
我在程式碼中使用isNode變數作澄清。但是,你可以直接把檢測程式碼放到程式碼片段的最後一個圓括號內。
伺服器端,URLparse匯出為Common.JS模組。這樣使用:
// include lib.js module
var lib = require(‘./lib.js’);
var url = lib.URLparse(‘http://site.com:81/path/page?a=1&b=2#hash’);
console.log(
url.href + ‘n’ +
// the full URL
url.protocol + ‘n’ +
// http:
url.hostname + ‘n’ +
// site.com
url.port + ‘n’ +
// 81
url.pathname + ‘n’ +
// /path/page
url.search + ‘n’ +
// ?a=1&b=2
url.hash
// #hash
);
客戶端,URLparse作為全域性lib物件的一個方法: