
作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
這兩天無意間發現一個非常有意義的工作,稱為“相對GAN”,簡稱 RSGAN,來自文章 The relativistic discriminator: a key element missing from standard GAN,據說該文章還得到了 GAN 創始人 Goodfellow 的點贊。這篇文章提出了用相對的判別器來取代標準 GAN 原有的判別器,使得生成器的收斂更為迅速,訓練更為穩定。


可惜的是,這篇文章僅僅從訓練和實驗角度對結果進行了論述,並沒有進行更深入的分析,以至於不少人覺得這隻是 GAN 訓練的一個 trick。但是在筆者看來,RSGAN 具有更為深刻的含義,甚至可以看成它已經開創了一個新的 GAN 流派。所以,筆者決定對 RSGAN 模型及其背後的內涵做一個基本的介紹。不過需要指出的是,除了結果一樣之外,本文的介紹過程跟原論文相比幾乎沒有重合之處。
“圖靈測試”思想
SGAN
SGAN 就是標準的 GAN(Standard GAN)。就算沒有做過 GAN 研究的讀者,相信也從各種渠道瞭解到 GAN 的大概原理:“造假者”不斷地進行造假,試圖愚弄“鑒別者”;“鑒別者”不斷提高鑒別技術,以分辨出真品和贗品。兩者相互競爭,共同進步,直到“鑒別者”無法分辨出真、贗品了,“造假者”就功成身退了。
在建模時,透過交替訓練實現這個過程:固定生成器,訓練一個判別器(二分類模型),將真實樣本輸出 1,將偽造樣本輸出 0;然後固定判別器,訓練生成器讓偽造樣本盡可能輸出 1,後面這一步不需要真實樣本參與。
問題所在
然而,這個建模過程似乎對判別器的要求過於苛刻了,因為判別器是孤立運作的:訓練生成器時,真實樣本沒有參與,所以判別器必須把關於真實樣本的所有屬性記住,這樣才能指導生成器生成更真實的樣本。
在生活實際中,我們並不是這樣做的,所謂“沒有對比就沒有傷害,沒有傷害就沒有進步”,我們很多時候是根據真、贗品的對比來分辨的。比如識別一張假幣,可能需要把它跟一張真幣對比一下;識別山寨手機,只需要將它跟正版手機對比一下就行了;等等。類似地,如果要想把贗品造得更真,那麼需要把真品放在一旁不斷地進行對比改進,而不是單單憑藉“記憶”中的真品來改進。
“對比”能讓我們更容易識別出真、贗品出來,從而更好地製造贗品。而在人工智慧領域,我們知道有非常著名的“圖靈測試”,指的是測試者在無法預知的情況下同時跟機器人和人進行交流,如果測試者無法成功分別出人和機器人,那麼說明這個機器人已經(在某個方面)具有人的智慧了。“圖靈測試”也強調了對比的重要性,如果機器人和人混合起來後就無法分辨了,那麼說明機器人已經成功了。
接下來我們將會看到,RSGAN 就是基於“圖靈測試”的思想的:如果鑒別器無法鑒別出混合的真假圖片,那麼生成器就成功了;而為了生成更好的圖片,生成器也需要直接藉助於真實圖片。
RSGAN基本框架
SGAN分析
首先,我們來回顧一下標準 GAN 的流程。設真實樣本分佈為 p̃(x),偽造樣本分佈為 q(x),那麼固定生成器後,我們來最佳化判別器 T(x):
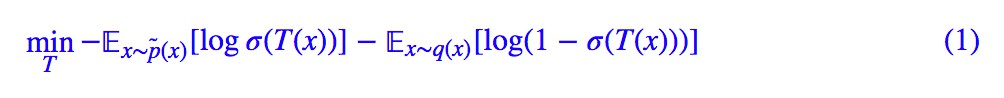
這裡的 σ 就是 sigmoid 啟用函式。然後固定判別器,我們最佳化生成器 G(z):

註意這裡我們有個不確定 h,我們馬上就來分析它。從 (1) 我們可以解出判別器的最優解滿足(後面有補充證明):

代入 (2),可以發現結果為:

寫成最後一個等式,是因為只需要設 f(t)=h(log(t)),就能夠看出它具有 f 散度的形式。也就是說,最小化 (2) 就是在最小化對應的 f 散度。關於 f 散度,可以引數我之前寫的 f-GAN 簡介:GAN 模型的生產車間 [1]。
f 散度中的 f 的本質要求是 f 是一個凸函式,所以只需要選擇 h 使得 h(log(t)) 為凸函式就行。最簡單的情況是 h(t)=−t,對應 h(log(t))=−logt 為凸函式,這時候 (2) 為:

類似的選擇有很多,比如當 h(t)=−logσ(t) 時,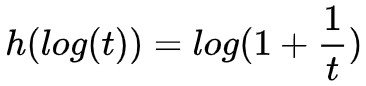 也是凸函式(t>0 時),所以:
也是凸函式(t>0 時),所以:

也是一個合理的選擇,它便是 GAN 常用的生成器 loss 之一。類似地還有 h(t)=log(1−σ(t)),這些選擇就不列舉了。
RSGAN標的
這裡,我們先直接給出 RSGAN 的最佳化標的:固定生成器後,我們來最佳化判別器 T(x):

這裡的 σ 就是 sigmoid 啟用函式。然後固定判別器,我們最佳化生成器 G(z):
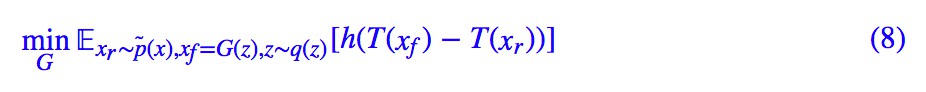
跟 SGAN 一樣,我們這裡保留了一般的 h,h 的要求跟前面的 SGAN 的討論一致。而 RSGAN 原論文的選擇是:
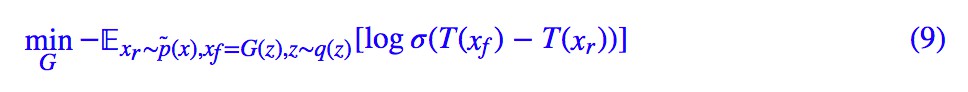
看上去就是把 SGAN 的判別器的兩項換成一個相對判別器了,相關的分析結果有什麼變化呢?
理論結果
透過變分法(後面有補充證明)可以得到,(7) 的最優解為:

代入到 (8),結果是:

這個結果便是整個 RSGAN 的精華所在了,它最佳化的是 p̃(Xr)q(Xf) 與 p̃(Xf)q(Xr) 的 f 散度!
這是什麼意思呢?它就是說,假如我從真實樣本取樣一個 Xr 出來,從偽造樣本取樣一個 Xf 出來,然後將它們交換一下,把假的當成真,真的當成假,那麼還能分辨出來嗎?換言之:p̃(Xf)q(Xr) 有大變化嗎?
假如沒有什麼變化,那就說明真假樣本已經無法分辨了,訓練成功,假如還能分辨出來,說明還需要藉助真實樣本來改善偽造樣本。所以,式 (11) 就是 RSGAN 中的“圖靈測試”思想的體現:打亂了資料,是否還能分辨出來?
模型效果分析
作者在原論文中還提出了一個 RaSGAN,a 是 average 的意思,就是用整個 batch 的平均來代替單一的真/偽樣本。但我覺得這不是一個特別優雅的做法,而且論文也表明 RaSGAN 的效果並非總是比 RSGAN 要好,所以這就不介紹了,有興趣的讀者看看原論文即可。
至於效果,論文中的效果串列顯示,RSGAN 在不少任務上都提升了模型的生成質量,但這並非總是這樣,平均而言有輕微的提升吧。作者特別指出的是 RSGAN 能夠加快生成器的訓練速度,我個人也實驗了一下,比 SGAN、SNGAN 都要快一些。
我的參考程式碼:
https://github.com/bojone/gan/blob/master/keras/rsgan_sn_celeba.py
借用 MingtaoGuo [2] 的一張圖來對比 RSGAN 的收斂速度:

▲ RSGAN收斂速度對比
從直觀來看,RSGAN 更快是因為在訓練生成器時也借用了真實樣本的資訊,而不僅僅透過判別器的“記憶”;從理論上看,透過 T(Xr)、T(Xf) 作差的方式,使得判別器只依賴於它們的相對值,從而簡單地改善了判別器 T 可能存在的偏置情況,使得梯度更加穩定。甚至我覺得,把真實樣本也引入到生成器的訓練中,有可能(沒仔細證明)提升偽造樣本的多樣性,因為有了各種真實樣本來對比,模型如果只生成單一樣本,也很難滿足判別器的對比判別標準。
相關話題討論
簡單總結
總的來說,我覺得 RSGAN 是對 GAN 的改進是從思想上做了改變的,也許 RSGAN 的作者也沒有留意到這一點。
我們經常說,WGAN 是 GAN 之後的一大突破,這沒錯,但這個突破是理論上的,而在思想上還是一樣,都是在減少兩個分佈的距離,只不過以前用 JS 散度可能有各種問題,而 WGAN 換用了 Wasserstein 距離。
我覺得 RSGAN 更像是一種思想上的突破——轉化為真假樣本混淆之後的分辨——儘管效果未必有大的進步。(當然你要是說大家最終的效果都是拉近了分佈距離,那我也沒話說)。
RSGAN 的一些提升是容易重現的,當然由於不是各種任務都有提升,所以也有人詬病這不過是 GAN 訓練的一個 trick。這些評論見仁見智吧,不妨礙我對這篇論文的贊賞和研究。
對了,順便說一下,作者 Alexia Jolicoeur-Martineau [3] 是猶太人總醫院(Jewish General Hospital)的一名女生物統計學家,論文中的結果是她只用一顆 1060 跑出來的 [4]。我突然也為我只有一顆 1060 感到自豪了,然而我有 1060 但我並沒有 paper。
延伸討論
最後胡扯一些延伸的話題。
首先,可以留意到,WGAN 的判別器 loss 本身就是兩項的差的形式,也就是說 WGAN 的判別器就是一個相對判別器,作者認為這是 WGAN 效果好的重要原因。
這樣看上去 WGAN 跟 RSGAN 本身就有一些交集,但我有個更進一步的想法,就是基於 p̃(xr)q(xf) 與p̃(xf)q(xr) 的比較能否完全換用 Wasserstein 距離來進行?我們知道 WGAN 的生成器訓練標的也是跟真實樣本沒關係的,怎麼更好地將真實樣本的資訊引入到 WGAN 的生成器中去?
還有一個問題,就是目前作差僅僅是判別器最後輸出的標量作差,那麼能不能是判別器的某個隱藏層作差,然後算個 mse 或者再接幾層神經網路?總之,我覺得這個模型的事情應該還沒完。
補充證明
(1) 的最優解

變分用 δ 表示,跟微分基本一樣:

極值在變分為 0 時取到,而 δσ(T(x)) 代表任意增量,所以如果上式恆為 0,意味著括號內的部分恆為 0,即:
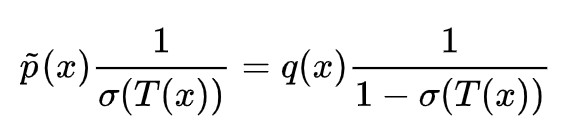
(7) 的最優解

變分上式:

極值在變分為 0 時取到,所以方括號內的部分恆為 0,即:

相關連結
[1]. https://kexue.fm/archives/6016
[2]. https://github.com/MingtaoGuo/DCGAN_WGAN_WGAN-GP_LSGAN_SNGAN_RSGAN_RaSGAN_TensorFlow
[3]. https://scholar.google.com/citations?user=0qytQ1oAAAAJ&hl;=en
[4]. https://www.reddit.com/r/MachineLearning/comments/8vr9am/r_the_relativistic_discriminator_a_key_element/e1ru76p

點選以下標題檢視作者其他文章:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視作者部落格
